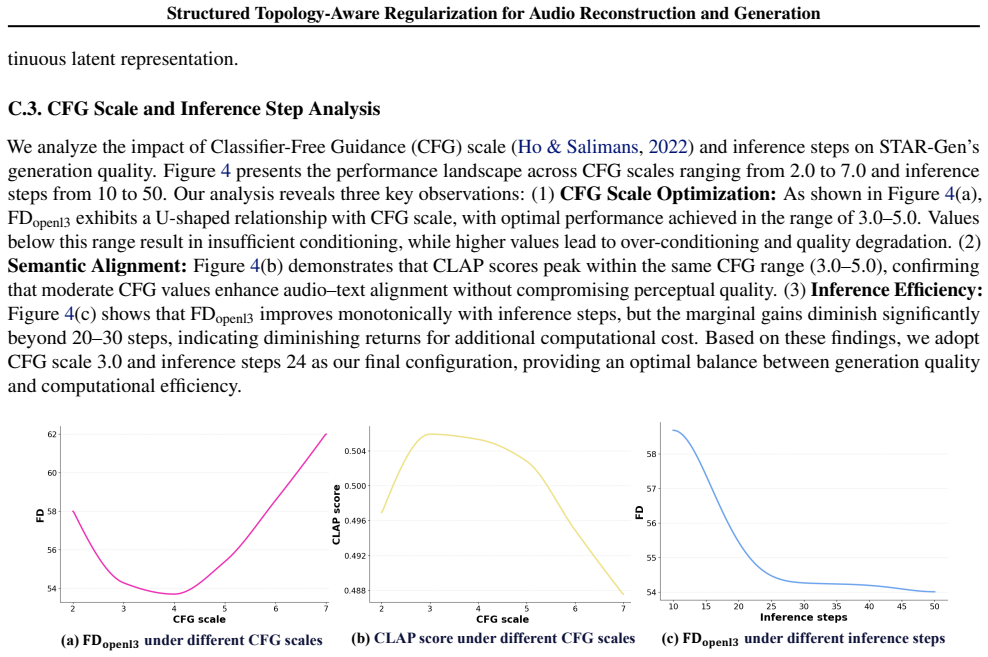
STAR-VAE: Structured Topology-Aware Regularization for Audio Reconstruction and Generation
Pith reviewed 2026-06-26 07:24 UTC · model grok-4.3
The pith
STAR resolves the Rate-Distortion-Regularity Trilemma in audio VAEs by imposing a growth-based constraint field that routes structural and textural information into capacity-matched channel subspaces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
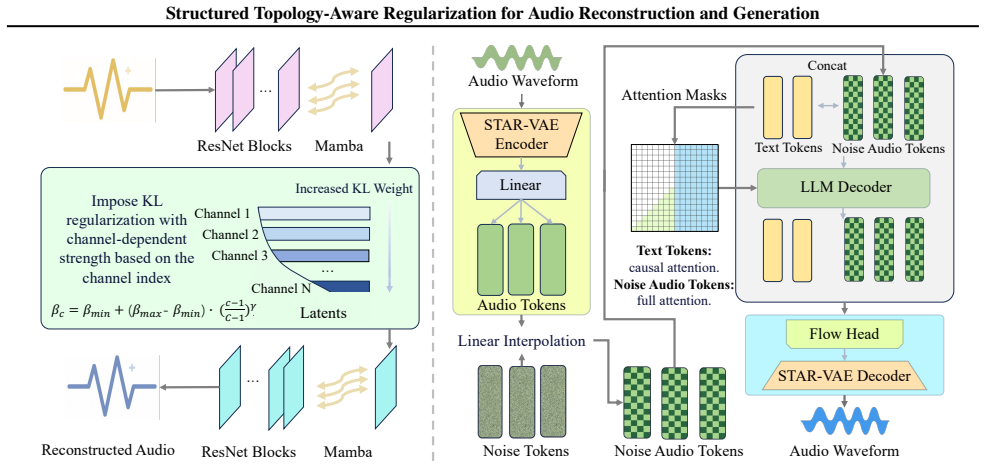
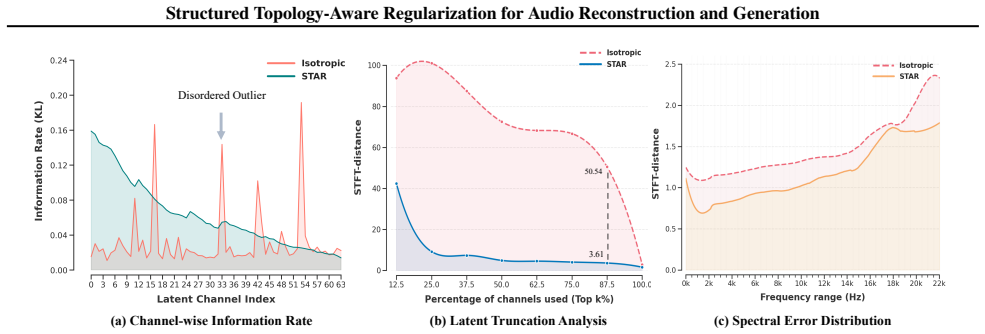
STAR is a general training strategy that reshapes latent space geometry in continuous VAEs by imposing a growth-based constraint field, routing structural and textural information into channel subspaces with matching capacities, thereby resolving the Rate-Distortion-Regularity Trilemma that arises from the topological mismatch between the isotropic Gaussian prior and audio's hierarchical frequency structure.
What carries the argument
The growth-based constraint field, which enforces topology-aware regularization by separating structural from textural information across channel subspaces according to their compressible versus stochastic character.
If this is right
- STAR-VAE with hybrid CNN-Mamba backbone reaches state-of-the-art reconstruction fidelity across multiple audio domains.
- The resulting latent space preserves semantic information more effectively than standard VAEs.
- The structured latent space improves both conventional diffusion models and the STAR-Gen Flow Matching framework for text-to-audio generation without vector-quantization artifacts.
- STAR applies to any VAE architecture, not only the CNN-Mamba hybrid shown.
Where Pith is reading between the lines
- The same constraint mechanism could be tested on other hierarchical signals such as images or video to check whether the trilemma appears outside audio.
- If the growth-based field reliably separates compressible from stochastic content, it may reduce reliance on vector quantization in downstream generative pipelines.
- The approach suggests a path toward latent spaces whose geometry matches signal statistics more closely, potentially lowering the compute needed for high-fidelity real-time audio coding.
Load-bearing premise
The root problem is a topological mismatch between the isotropic Gaussian prior and audio's hierarchical frequency structure, and a growth-based constraint field can separate structural from textural information without introducing new artifacts or needing architecture-specific tuning.
What would settle it
A controlled experiment in which the growth-based constraint field is applied to a standard VAE on audio data yet produces no measurable gain in reconstruction fidelity or semantic feature preservation compared with the unconstrained baseline.
Figures

read the original abstract
Continuous Variational Autoencoders (VAEs) serve as the fundamental continuous tokenizer for modern neural audio generation systems, enabling high-fidelity reconstruction while providing a compact, smooth latent space for downstream generative priors. However, continuous VAEs face a fundamental conflict among compression rate, reconstruction fidelity, and latent space topology, which we formalize as the Rate-Distortion-Regularity Trilemma. This trilemma stems from a topological mismatch: the isotropic Gaussian prior in standard VAEs imposes a flat latent geometry that fails to accommodate audio's hierarchical nature, where low-frequency components are structured and compressible while high-frequency components are stochastic and incompressible, leading to disordered information packing in which crucial semantic features are interleaved with high-entropy noise. To address this challenge, we propose Structured Topology-Aware Regularization (STAR), a general training strategy that reshapes latent space geometry by imposing a growth-based constraint field, routing structural and textural information into channel subspaces with matching capacities. STAR is applicable to any VAE architecture and effectively resolves the trilemma, as demonstrated in CNN-based VAEs. We further present STAR-VAE, which combines STAR with a hybrid CNN-Mamba architecture for local feature extraction and linear-complexity global context modeling, and STAR-Gen, an LLM-based Flow Matching framework that leverages STAR-VAE's structured latent space for high-fidelity generation without vector quantization artifacts. Experiments across diverse audio domains show that STAR-VAE achieves state-of-the-art reconstruction fidelity and enhanced semantic information preservation, while the structured latent space improves both traditional diffusion models and STAR-Gen for text-to-audio generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that continuous VAEs for audio suffer from a Rate-Distortion-Regularity Trilemma caused by a topological mismatch between the isotropic Gaussian prior and audio's hierarchical frequency structure (structured low frequencies vs. stochastic high frequencies), leading to disordered latent packing. It proposes STAR, a general regularization strategy that imposes a growth-based constraint field to route structural and textural information into channel subspaces of matching capacity, thereby resolving the trilemma. The work further introduces STAR-VAE (hybrid CNN-Mamba) and STAR-Gen (LLM-based flow matching on the structured latents), reporting SOTA reconstruction fidelity, semantic preservation, and improved text-to-audio generation across domains.
Significance. If the central claims hold with rigorous validation, the work would offer a topology-aware regularization mechanism that structurally mitigates a known limitation of standard VAEs in audio, potentially improving both reconstruction and downstream generative modeling without relying on vector quantization. The generality claim (applicable to any VAE architecture) and the hybrid architecture components would be notable strengths if supported by controlled ablations.
major comments (3)
- [Abstract, §1] Abstract and §1: The claim that the growth-based constraint field 'resolves the trilemma' by routing structural vs. textural information is load-bearing, yet no derivation is supplied showing that the field preserves the ELBO, avoids introducing new high-entropy modes, or remains architecture-agnostic. The skeptic note correctly identifies this as the weakest assumption; without an explicit proof or bound, the resolution reduces to an empirical trade-off rather than a structural fix.
- [Abstract] Abstract: The assertion of 'state-of-the-art reconstruction fidelity and enhanced semantic information preservation' is presented without any experimental details, baselines, metrics, error bars, or statistical tests. This prevents assessment of whether the reported gains are attributable to STAR, the CNN-Mamba backbone, or the flow-matching components.
- [Abstract] Abstract: The trilemma is formalized as stemming from topological mismatch, but it is unclear whether this formalization is derived independently of the proposed solution or defined circularly in terms of the growth-based constraint; the manuscript must supply an independent definition and a concrete test (e.g., latent-space topology metrics before/after STAR) to establish the causal link.
minor comments (2)
- Notation for the growth-based constraint field and channel subspaces should be introduced with explicit equations rather than descriptive prose.
- The manuscript should clarify whether STAR requires architecture-specific hyperparameter tuning or remains effective when the base encoder/decoder is replaced (e.g., pure transformer or diffusion-based VAEs).
Simulated Author's Rebuttal
Thank you for the opportunity to respond to the referee's comments. We appreciate the detailed feedback and address each major comment point by point below. Where revisions are needed, we indicate them accordingly.
read point-by-point responses
-
Referee: [Abstract, §1] Abstract and §1: The claim that the growth-based constraint field 'resolves the trilemma' by routing structural vs. textural information is load-bearing, yet no derivation is supplied showing that the field preserves the ELBO, avoids introducing new high-entropy modes, or remains architecture-agnostic. The skeptic note correctly identifies this as the weakest assumption; without an explicit proof or bound, the resolution reduces to an empirical trade-off rather than a structural fix.
Authors: We acknowledge that the manuscript does not provide a formal mathematical derivation proving that the growth-based constraint field preserves the ELBO or is strictly architecture-agnostic. The claims are supported by empirical evidence from experiments on CNN-based VAEs. We will revise the text to emphasize that STAR provides an empirical resolution to the trilemma and include additional discussion on the underlying assumptions and potential limitations. revision: yes
-
Referee: [Abstract] Abstract: The assertion of 'state-of-the-art reconstruction fidelity and enhanced semantic information preservation' is presented without any experimental details, baselines, metrics, error bars, or statistical tests. This prevents assessment of whether the reported gains are attributable to STAR, the CNN-Mamba backbone, or the flow-matching components.
Authors: The abstract serves as a high-level overview of the contributions and results. Comprehensive experimental details, including baselines, metrics, error bars, and comparisons to isolate the contributions of STAR, the hybrid architecture, and other components, are presented in the Experiments and Results sections of the full manuscript. We can update the abstract to include pointers to these sections for clarity. revision: partial
-
Referee: [Abstract] Abstract: The trilemma is formalized as stemming from topological mismatch, but it is unclear whether this formalization is derived independently of the proposed solution or defined circularly in terms of the growth-based constraint; the manuscript must supply an independent definition and a concrete test (e.g., latent-space topology metrics before/after STAR) to establish the causal link.
Authors: The formalization of the Rate-Distortion-Regularity Trilemma is derived from the inherent properties of audio signals—specifically their hierarchical frequency structure with structured low frequencies and stochastic high frequencies—and the limitations of the isotropic Gaussian prior in standard VAEs. This is independent of the STAR method. To strengthen the causal link, we will add an independent definition in the revised manuscript and include concrete evaluations using latent-space topology metrics before and after applying STAR. revision: yes
Circularity Check
No circularity; trilemma and solution presented as independent
full rationale
The provided abstract and text formalize the Rate-Distortion-Regularity Trilemma from the established mismatch between isotropic Gaussian priors and audio's frequency hierarchy, then introduce STAR as an external regularization strategy without any quoted equations, self-citations, or definitions that reduce the trilemma or its resolution to the method itself by construction. No fitted inputs are relabeled as predictions, no uniqueness theorems are imported from the authors' prior work, and no ansatz is smuggled via citation. The derivation chain remains self-contained against external VAE and audio modeling benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Audio signals have a hierarchical structure where low-frequency components are structured and compressible while high-frequency components are stochastic and incompressible.
invented entities (1)
-
growth-based constraint field
no independent evidence
Reference graph
Works this paper leans on
-
[1]
L., Wu, H.-H., Salamon, J., and Bello, J
Cramer, A. L., Wu, H.-H., Salamon, J., and Bello, J. P. Look, listen, and learn more: Design choices for deep audio embeddings. InICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 3852–3856. IEEE,
2019
-
[2]
FMA: A Dataset For Music Analysis
Defferrard, M., Benzi, K., Vandergheynst, P., and Bresson, X. Fma: A dataset for music analysis.arXiv preprint arXiv:1612.01840,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
High Fidelity Neural Audio Compression
D´efossez, A., Copet, J., Synnaeve, G., and Adi, Y . High fidelity neural audio compression.arXiv preprint arXiv:2210.13438,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
D., Carr, C., Zukowski, Z., Taylor, J., and Pons, J
Evans, Z., Parker, J. D., Carr, C., Zukowski, Z., Taylor, J., and Pons, J. Stable audio open. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1–5. IEEE,
2025
-
[5]
Efficiently Modeling Long Sequences with Structured State Spaces
Gu, A., Goel, K., and R ´e, C. Efficiently modeling long sequences with structured state spaces.arXiv preprint arXiv:2111.00396,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Classifier-Free Diffusion Guidance
Ho, J. and Salimans, T. Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Make-an-audio 2: Temporal-enhanced text-to-audio generation.arXiv preprint arXiv:2305.18474,
Huang, J., Ren, Y ., Huang, R., Yang, D., Ye, Z., Zhang, C., Liu, J., Yin, X., Ma, Z., and Zhao, Z. Make-an-audio 2: Temporal-enhanced text-to-audio generation.arXiv preprint arXiv:2305.18474,
-
[8]
Hung, C.-Y ., Majumder, N., Kong, Z., Mehrish, A., Bagherzadeh, A. A., Li, C., Valle, R., Catanzaro, B., and Poria, S. Tangoflux: Super fast and faithful text to au- dio generation with flow matching and clap-ranked pref- erence optimization.arXiv preprint arXiv:2412.21037,
-
[9]
Fr\'echet Audio Distance: A Metric for Evaluating Music Enhancement Algorithms
Kilgour, K., Zuluaga, M., Roblek, D., and Sharifi, M. Fr \’echet audio distance: A metric for evaluat- ing music enhancement algorithms.arXiv preprint arXiv:1812.08466,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
D., Kim, B., Lee, H., and Kim, G
9 Structured Topology-Aware Regularization for Audio Reconstruction and Generation Kim, C. D., Kim, B., Lee, H., and Kim, G. Audiocaps: Gen- erating captions for audios in the wild. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Hu- man Language Technologies, Volume 1 (Long and Short Pa...
2019
-
[11]
Efficient training of audio transformers with patchout
Koutini, K., Schl ¨uter, J., Eghbal-Zadeh, H., and Widmer, G. Efficient training of audio transformers with patchout. arXiv preprint arXiv:2110.05069,
-
[12]
Audiogen: Textually guided audio generation.arXiv preprint arXiv:2209.15352,
Kreuk, F., Synnaeve, G., Polyak, A., Singer, U., D´efossez, A., Copet, J., Parikh, D., Taigman, Y ., and Adi, Y . Audio- gen: Textually guided audio generation.arXiv preprint arXiv:2209.15352,
-
[13]
Le Roux, J., Wisdom, S., Erdogan, H., and Hershey, J. R. Sdr–half-baked or well done? InICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 626–630. IEEE,
2019
-
[14]
Flow Matching for Generative Modeling
Lipman, Y ., Chen, R. T., Ben-Hamu, H., Nickel, M., and Le, M. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Liu, H., Chen, Z., Yuan, Y ., Mei, X., Liu, X., Mandic, D., Wang, W., and Plumbley, M. D. Audioldm: Text-to-audio generation with latent diffusion models.arXiv preprint arXiv:2301.12503, 2023a. Liu, H., Huang, R., Lin, X., Xu, W., Zheng, M., Chen, H., He, J., and Zhao, Z. Vit-tts: visual text-to-speech with scalable diffusion transformer. InProceedings of...
-
[16]
Manco, I., Weck, B., Doh, S., Won, M., Zhang, Y ., Bog- danov, D., Wu, Y ., Chen, K., Tovstogan, P., Benetos, E., et al. The song describer dataset: a corpus of audio cap- tions for music-and-language evaluation.arXiv preprint arXiv:2311.10057,
-
[17]
An Introduction to Convolutional Neural Networks
O’shea, K. and Nash, R. An introduction to convolutional neural networks.arXiv preprint arXiv:1511.08458,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., M ¨uller, J., Penna, J., and Rombach, R. Sdxl: Im- proving latent diffusion models for high-resolution image synthesis.arXiv preprint arXiv:2307.01952,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Latent diffusion model without variational autoencoder.arXiv preprint arXiv:2510.15301,
Shi, M., Wang, H., Zheng, W., Yuan, Z., Wu, X., Wang, X., Wan, P., Zhou, J., and Lu, J. Latent diffusion model without variational autoencoder.arXiv preprint arXiv:2510.15301,
-
[20]
Back to ear: Perceptually driven high fidelity music reconstruction,
Wang, K., Wu, Z., Zhou, D., Lin, R., Dai, J., and Jiang, T. Back to ear: Perceptually driven high fidelity music reconstruction.arXiv preprint arXiv:2509.14912,
-
[21]
Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation
Wu, Y ., Chen, K., Zhang, T., Hui, Y ., Berg-Kirkpatrick, T., and Dubnov, S. Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1–5. IEEE,
2023
-
[22]
Parallel wavegan: A fast waveform generation model based on generative adversarial networks with multi-resolution spectrogram
Yamamoto, R., Song, E., and Kim, J.-M. Parallel wavegan: A fast waveform generation model based on generative adversarial networks with multi-resolution spectrogram. InICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 6199–6203. IEEE,
2020
-
[23]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Diffusion Transformers with Representation Autoencoders
Zheng, B., Ma, N., Tong, S., and Xie, S. Diffusion trans- formers with representation autoencoders.arXiv preprint arXiv:2510.11690,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
While effective, these methods often face a trade-off between quantization artifacts and excessive sequence lengths
andMusicGen(Copet et al., 2023), early approaches treated audio synthesis as a sequence modeling task over discrete tokens derived from VQ-V AEs (Van Den Oord et al., 2017). While effective, these methods often face a trade-off between quantization artifacts and excessive sequence lengths. Conse- quently, the paradigm has shifted towards continuous latent...
2023
-
[26]
extends capabilities to high-fidelity long-form audio generation. However, despite the diversity of these generative backbones, their ultimate fidelity is strictly upper-bounded by the representational capacity of the underlying Variational Autoencoder. STAR-V AE addresses this foundational bottleneck, proposing a topologically structured V AE that serves...
2025
-
[27]
Window lengths are set to{2048,1024,512,256,128,64,32}
to match human perception. Window lengths are set to{2048,1024,512,256,128,64,32}. Adversarial Loss (LAdv).We utilize a patch-based hinge loss with a Multi-Scale STFT Discriminator ensemble (window lengths {2048, . . . ,128}). The adversarial loss combines both adversarial and feature matching objectives, where feature matching minimizes theL 1 distance b...
2048
-
[28]
We compare STAR-V AE against the music-oriented sequence-aware baselineϵar-V AE (Wang et al.,
and 30 music clips from the Song Describer Dataset (Manco et al., 2023), enabling a domain-balanced assessment. We compare STAR-V AE against the music-oriented sequence-aware baselineϵar-V AE (Wang et al.,
2023
-
[29]
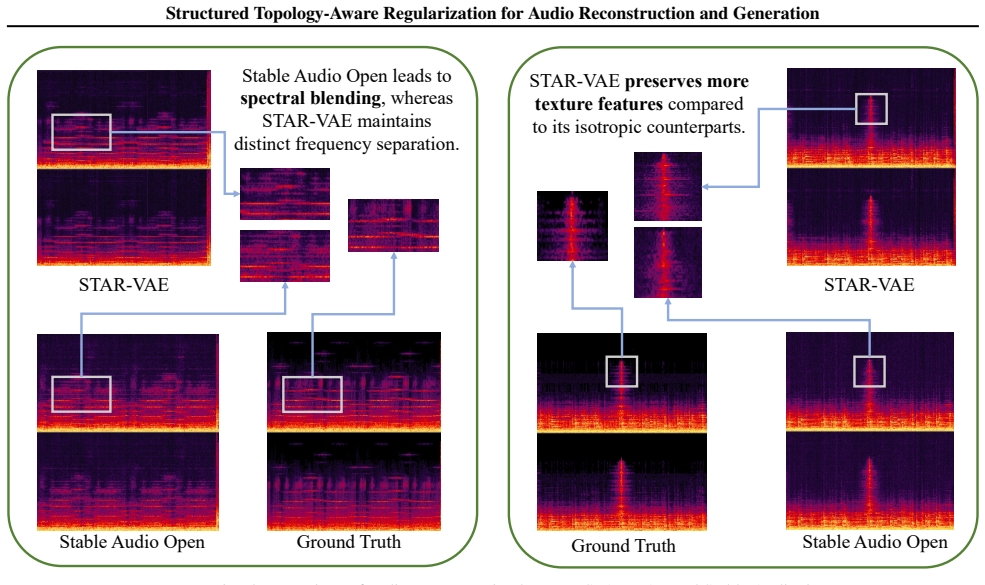
Stable Audio Open leads to spectral blending, whereas STAR-VA E m a i n t a i n s distinct frequency separation
and the high-fidelity convolutional baseline Stable Audio Open (SAO) (Evans et al., 2025), along with Ground Truth as the 14 Structured Topology-Aware Regularization for Audio Reconstruction and Generation Ground Truth STAR-VA E Stable Audio OpenGround Truth STAR-VA E Stable Audio Open STAR-VA E preserves more texture featurescompared to its isotropic cou...
2025
-
[30]
21.5 4.05±0.15 Generation MOS.For text-to-audio generation, we evaluate 60 clips synthesized from prompts in the AudioCaps test set (Kim et al., 2019), comparing STAR-Gen against two strong baselines: TangoFlux (Hung et al.,
2019
-
[31]
Table 8 shows that STAR-Gen attains the highest MOS among all baselines (3.92 ± 0.16), outperforming TangoFlux (3.76± 0.19) and SAO (3.71 ± 0.18)
and SAO (Evans et al., 2025), with Ground Truth recordings included as a reference. Table 8 shows that STAR-Gen attains the highest MOS among all baselines (3.92 ± 0.16), outperforming TangoFlux (3.76± 0.19) and SAO (3.71 ± 0.18). These subjective results corroborate our quantitative findings: STAR-Gen’s improved generation quality stems from operating on...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.