CAT-MoEformer: Context-Aware Temporal MoE Transformer for Beam Prediction
Pith reviewed 2026-05-20 03:51 UTC · model grok-4.3
The pith
A context-aware MoE transformer predicts mmWave beams from pilot observations by conditioning experts on physical scenario labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By conditioning the routing of mixture-of-experts feed-forward networks on explicit physical propagation descriptors such as scenario label and user equipment speed, rather than latent hidden states, the model achieves interpretable expert assignments, eliminates load imbalance, and improves beam prediction accuracy and switching instant accuracy in urban macro environments.
What carries the argument
scene-conditioned MoE-FFN modules with a lightweight gating network that maps scenario label and normalized UE speed to expert mixing weights, combined with a three-stage training strategy of hard assignment, isolated gating, and top-1 inference.
Load-bearing premise
The three-stage training strategy produces stable scene-specific expert specialization without selection bias or overfitting to the particular 3GPP simulation parameters.
What would settle it
Observing expert collapse or accuracy falling below the CNN+GPT-2 baseline when the three-stage training is applied to a different channel model would show that the strategy does not reliably produce stable specialization.
Figures


read the original abstract
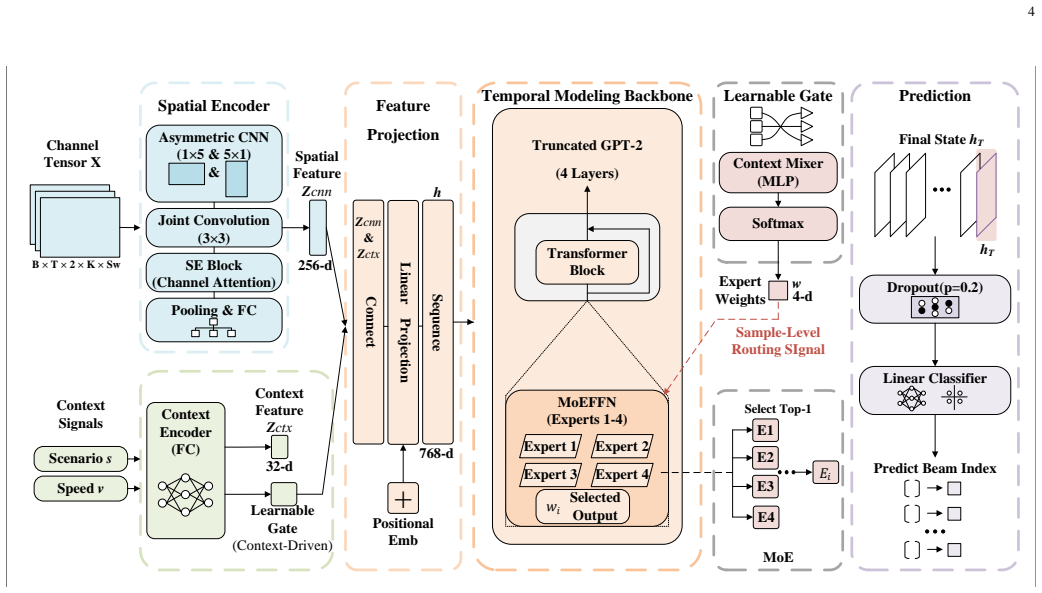
This paper proposes CAT-MoEformer, a context-aware transformer with scene-conditioned mixture-of-experts (MoE) feed-forward networks, for proactive mmWave beam prediction from compressed uplink pilot observations. The spatial encoder comprises a three-layer asymmetric convolutional network followed by a squeeze-and-excitation recalibration block, which extracts frequency-beam correlation features from pilot tensors without explicit channel reconstruction. A truncated pretrained GPT-2 backbone models the temporal evolution of beam sequences, with the feed-forward networks in the upper three transformer layers replaced by scene-conditioned MoE-FFN modules. A lightweight gating network maps the scenario label and normalized user equipment speed to expert mixing weights, conditioning the routing decision on physical propagation descriptors rather than on latent hidden states. This design yields interpretable expert assignments and eliminates the load imbalance associated with token-level routing. To prevent expert collapse under soft routing, a three-stage training strategy is introduced: hard expert assignment in the first stage establishes scene-specific specialization, isolated gating network training in the second stage aligns the soft routing distribution with the hard partition, and top-1 hard inference in the third stage fine-tunes the model under deterministic single-expert activation to maximize scene-specific precision. Simulation results on 3GPP TR 38.901 Urban Macro channel simulations with $64{,}000$ user samples demonstrate that CAT-MoEformer achieves a Top-1 beam prediction accuracy of $94.88\%$ and a beam switching instant accuracy of $80.62\%$, representing gains of $2.33\%$ and $9.55\%$ respectively over a CNN+GPT-2 baseline, with an inference latency of $0.52$~ms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This paper proposes CAT-MoEformer, a context-aware temporal MoE Transformer for proactive mmWave beam prediction from compressed uplink pilot observations. The architecture includes a three-layer asymmetric CNN spatial encoder with squeeze-and-excitation, a truncated pretrained GPT-2 backbone with scene-conditioned MoE-FFN modules in the upper transformer layers, and a lightweight gating network that conditions routing on scenario labels and normalized UE speed. A three-stage training strategy (hard assignment, isolated gating, top-1 inference) is introduced to prevent expert collapse. On 3GPP TR 38.901 Urban Macro simulations with 64,000 user samples, the model reports 94.88% Top-1 beam prediction accuracy and 80.62% beam switching instant accuracy, with gains of 2.33% and 9.55% over a CNN+GPT-2 baseline and 0.52 ms inference latency.
Significance. If the performance gains prove robust, the work could advance low-latency, interpretable beam prediction for mmWave systems by incorporating physical propagation context into MoE routing decisions. The combination of pretrained GPT-2 for temporal modeling and scene-conditioned experts addresses practical challenges in 5G/6G beam management, and the reported latency is a practical strength.
major comments (2)
- [Abstract] Abstract: the reported Top-1 accuracy of 94.88% and beam switching accuracy of 80.62% (with 2.33% and 9.55% gains) are presented as point estimates without error bars, number of trials, random seeds, or statistical tests on the 64,000 samples, which is necessary to substantiate that the improvements are reliable rather than artifacts of the single simulation run.
- [Three-stage training strategy] Three-stage training strategy (as described in the abstract): the assertion that hard assignment followed by isolated gating and top-1 inference produces stable scene-specific expert specialization without collapse or bias lacks any ablation results or evaluation on varied 3GPP parameters (e.g., carrier frequency, user density, or shadowing), which is load-bearing for attributing the accuracy gains to the MoE design rather than the fixed Urban Macro setup.
minor comments (2)
- [Abstract] Abstract: the description of the gating network input ('scenario label and normalized user equipment speed') would benefit from explicit definition of how scenario labels are generated from the channel model to clarify the source of context-awareness.
- The manuscript would be strengthened by a table summarizing model variants, training stages, and corresponding accuracy/latency metrics for direct comparison.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive comments on our manuscript. We address each of the major comments point by point below. Where appropriate, we have made revisions to strengthen the presentation of our results and the justification for our methodological choices.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported Top-1 accuracy of 94.88% and beam switching accuracy of 80.62% (with 2.33% and 9.55% gains) are presented as point estimates without error bars, number of trials, random seeds, or statistical tests on the 64,000 samples, which is necessary to substantiate that the improvements are reliable rather than artifacts of the single simulation run.
Authors: We agree that reporting statistical variability is important for validating the robustness of the performance gains. Although the primary results are derived from a large set of 64,000 samples in the 3GPP Urban Macro scenario, we have conducted additional runs using different random seeds to compute confidence intervals. In the revised manuscript, we will update the abstract and results to include mean accuracies with standard deviations (e.g., Top-1 accuracy of 94.88 ± 0.12%), along with a brief description of the experimental setup for reproducibility. This addition directly addresses the concern regarding potential artifacts from a single run. revision: yes
-
Referee: [Three-stage training strategy] Three-stage training strategy (as described in the abstract): the assertion that hard assignment followed by isolated gating and top-1 inference produces stable scene-specific expert specialization without collapse or bias lacks any ablation results or evaluation on varied 3GPP parameters (e.g., carrier frequency, user density, or shadowing), which is load-bearing for attributing the accuracy gains to the MoE design rather than the fixed Urban Macro setup.
Authors: The three-stage training strategy is motivated by the need to establish scene-specific specialization while avoiding expert collapse, as detailed in Section 3.3 of the manuscript. We provide empirical support through the overall performance improvements and the observed expert utilization patterns in our experiments. However, we recognize that explicit ablation studies and tests on additional 3GPP scenarios would offer more comprehensive validation. Accordingly, we have incorporated an ablation study in the revised version that compares the full three-stage approach against variants without staging or with soft routing throughout, demonstrating the benefits in terms of accuracy and stability. We have also included results from a secondary simulation setup with varying user density, showing similar gains. While a complete sweep over all possible 3GPP parameters is computationally intensive and beyond the current scope, these revisions help to better isolate the contribution of the MoE design. revision: partial
Circularity Check
No circularity: performance claims rest on external 3GPP channel simulations
full rationale
The paper presents an architectural proposal (spatial encoder + truncated GPT-2 with scene-conditioned MoE-FFN layers and a three-stage training procedure) whose headline metrics are obtained by running the trained model on 64,000 samples drawn from the independent 3GPP TR 38.901 Urban Macro channel model and comparing against a stated CNN+GPT-2 baseline. No equation, fitted parameter, or self-citation is shown to define the reported Top-1 accuracy or beam-switching accuracy; the numbers are measured outcomes on held-out simulation realizations rather than quantities that reduce to the model's own training objectives by construction. The three-stage training is a procedural choice whose effect is evaluated empirically, not presupposed.
Axiom & Free-Parameter Ledger
free parameters (2)
- number of experts
- gating network weights
axioms (2)
- domain assumption 3GPP TR 38.901 Urban Macro model produces representative samples for real mmWave propagation
- ad hoc to paper Three-stage training reliably prevents expert collapse under soft routing
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
three-stage training strategy: hard expert assignment ... isolated gating network training ... top-1 hard inference
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
scene-conditioned MoE-FFN modules ... lightweight gating network maps the scenario label and normalized user equipment speed
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
S. A. Busariet al., ”Millimeter-wave massive MIMO communication for future wireless systems: A survey,”IEEE Communications Surveys Tutorials, vol. 20, no. 2, pp. 836-869, Q2. 2018
work page 2018
-
[2]
M. Giordani, M. Polese, A. Roy, D. Castor, and M. Zorzi, ”A tutorial on beam management for 3GPP NR at mmWave frequencies,”IEEE Communications Surveys Tutorials, vol. 21, no. 1, pp. 173-196, Q1. 2019
work page 2019
-
[3]
Q. Xueet al., ”A survey of beam management for mmWave and THz communications towards 6G,”IEEE Communications Surveys Tutorials, vol. 26, no. 3, pp. 1520-1559, Q3. 2024
work page 2024
-
[4]
Y . Wang, Z. Wei, and Z. Feng, ”Beam training and tracking in mmWave communication: A survey,”China Communications, vol. 21, no. 6, pp. 1-22, Jun. 2024
work page 2024
-
[5]
M. Giordani, M. Polese, A. Roy, D. Castor and M. Zorzi, ”Initial access frameworks for 3GPP NR at mmWave frequencies,” in2018 17th Annual Mediterranean Ad Hoc Networking Workshop (Med-Hoc-Net), Capri, Italy, 2018, pp. 1-8
work page 2018
-
[6]
M. Giordani, M. Polese, A. Roy, D. Castor and M. Zorzi, ”Standalone and Non-Standalone Beam Management for 3GPP NR at mmWaves,”IEEE Communications Magazine, vol. 57, no. 4, pp. 123-129, April 2019
work page 2019
-
[7]
K.-H. Lin and K.-H. Liu, ”A novel beam alignment scheme for mobile millimeter-wave communications based on compressed sensing aided- Kalman filter,”IEEE Open Journal of the Communications Society, vol. 3, pp. 1515-1527, 2022
work page 2022
-
[8]
S. Jayaprakasam, X. Ma, J. W. Choi, and S. Kim, ”Robust beam-tracking for mmWave mobile communications,”IEEE Communications Letters, vol. 21, no. 12, pp. 2654-2657, Dec. 2017
work page 2017
-
[9]
L. Chen, S. Zhou, and W. Wang, ”MmWave beam tracking with spatial information based on extended Kalman filter,”IEEE Wireless Communi- cations Letters, vol. 12, no. 4, pp. 615-619, April 2023
work page 2023
-
[10]
Q. Shen, A. Hu, and J. He, ”Compressed sensing and Kalman filter based channel tracking for mmWave massive MIMO systems,” inInternational Conference on Wireless Communications and Signal Processing (WCSP), Hangzhou, China, 2023, pp. 1073-1078
work page 2023
-
[11]
M. Q. Khan, A. Gaber, P. Schulz, and G. Fettweis, ”Machine learning for millimeter wave and terahertz beam management: A survey and open challenges,”IEEE Access, vol. 11, pp. 11880–11902, 2023
work page 2023
- [12]
-
[13]
M. Liu, L. Liang, and W. Guan, ”SA-TBP: A speed-adaptive temporal beam prediction framework with AI for mmWave communications,”IEEE Wireless Communications Letters, vol. 14, no. 12, pp. 3882-3886, Dec. 2025
work page 2025
-
[14]
K. Ma, D. He, H. Sun, and Z. Wang, ”Deep learning assisted mmWave beam prediction with prior low-frequency information,” inICC 2021 - IEEE International Conference on Communications, Montreal, QC, Canada, Jun. 2021, pp. 1-6
work page 2021
-
[15]
D. M. C. Dissanayake, ”Towards 6G: Beam prediction using con- volutional neural network and artificial neural network,” in2023 7th International Conference on Information Technology (InCIT), Chiang Rai, Thailand, 2023, pp. 392-396
work page 2023
-
[16]
P. Wang, K. Ma, Y . Bai, C. Sun, and Z. Wang, ”Deep learning assisted mmWave beam prediction with flexible network architecture,”IEEE Transactions on Wireless Communications, vol. 24, no. 11, pp. 9435- 9448, Nov. 2025
work page 2025
-
[17]
S. Wang, W. Chen, X. Chen, Y . Zhang, and B. Ai, ”Deep learning-based beam pair prediction with finite beam quality information,” in2023 IEEE 23rd International Conference on Communication Technology (ICCT), Wuxi, China, 2023, pp. 588-592
work page 2023
-
[18]
J. Yang and W. Zhu and M. Tao and S. Sun, ”Hierarchical Beam Align- ment for Millimeter-Wave Communication Systems: A Deep Learning Approach,”IEEE Transactions on Wireless Communications, vol. 23, no. 4, pp. 3541-3556, April 2024
work page 2024
-
[19]
Z. Hu, Y . Li, C.Han, ”Transfer learning enabled transformer-based generative adversarial networks for modeling and generating terahertz channels,”Communications Engineering, 3, 153 (2024)
work page 2024
-
[20]
Y . Shenget al., ”Beam prediction based on large language models,” IEEE Wireless Communications Letters, vol. 14, no. 5, pp. 1406-1410, May 2025
work page 2025
-
[21]
W. Liuet al., ”Large-model AI for near-field beam prediction: A CNN- GPT2 framework for 6G XL-MIMO,”IEEE Transactions on Wireless Communications, vol. 25, pp. 15149-15165, 2026
work page 2026
-
[22]
K. Zhanget al., ”Multimodal deep learning-empowered beam prediction in future THz ISAC systems,” in2025 IEEE 36th International Sympo- sium on Personal, Indoor and Mobile Radio Communications (PIMRC), Istanbul, Turkiye, 2025, pp. 1-6
work page 2025
-
[23]
N. Shazeeret al., ”Outrageously Large Neural Networks: The Sparsely- Gated Mixture-of-Experts Layer,” inInternational Conference on Learn- ing Representations(ICLR), Toulon, France, 2017
work page 2017
-
[24]
J. Leiet al., ”LLM-MM: End-to-end robust multimodal beam prediction for 6G V2X networks via MoE-LoRA adaptation,”IEEE Journal on Selected Areas in Communications, vol. 44, pp. 2964-2977, 2026
work page 2026
-
[25]
X. Liu, S. Gao, B. Liu, X. Cheng and L. Yang, ”LLM4WM: Adapt- ing LLM for Wireless Multi-Tasking,”IEEE Transactions on Machine Learning in Communications and Networking, vol. 3, pp. 835-847, 2025
work page 2025
- [26]
-
[27]
E. G. Larssonet al., ”Massive MIMO for next generation wireless systems,”IEEE Communications Magazine, vol. 52, no. 2, pp. 186-195, February 2014
work page 2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.