DLO-Lab: Benchmarking Deformable Linear Object Manipulations with Differentiable Physics
Pith reviewed 2026-06-28 09:37 UTC · model grok-4.3
The pith
A differentiable simulator models diverse DLO material behaviors to support learning of general manipulation policies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
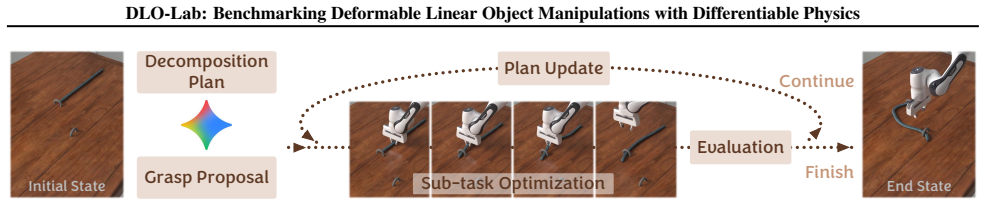
We introduce a differentiable simulator explicitly designed for versatile DLO manipulation. Our simulator models a wide range of material properties—including (in)extensibility, elasticity, bending plasticity, and complex interactions with other objects—providing a robust foundation for learning and evaluating manipulation skills. Building on this simulator, we propose a benchmark suite of representative tasks that highlight the unique challenges of DLO manipulation. The successful execution of these tasks is often hindered by the topological complexity and grasp sensitivity inherent to DLOs. Therefore, we introduce a specialized DLO agent that explicitly manages these challenges by proposin
What carries the argument
Differentiable simulator for DLOs that encodes (in)extensibility, elasticity, bending plasticity, and multi-object interactions, which supports both the benchmark tasks and the grasping-point agent.
If this is right
- Policy-learning algorithms can be trained and compared directly on the provided benchmark tasks.
- The specialized agent enables decomposition of long-horizon DLO tasks into grasp-controlled segments.
- Sim-to-real transfer becomes feasible for DLO manipulation once the simulator captures the listed material properties.
- Tasks in the suite expose how grasp choice and topology changes affect success rates.
Where Pith is reading between the lines
- The same simulator could be extended to test whether the agent generalizes to DLOs with time-varying properties such as temperature-dependent stiffness.
- Benchmark results might guide the design of new observation spaces that explicitly encode DLO topology for reinforcement learning.
- If the grasping-point proposal works, it could be combined with vision-based methods to reduce the need for full-state simulation during deployment.
Load-bearing premise
The introduced simulator and specialized DLO agent will overcome the topological complexity and grasp sensitivity that hinder task execution.
What would settle it
A sim-to-real experiment in which policies trained inside the simulator produce repeated failures on the same physical DLO tasks would show the platform does not deliver the claimed foundation.
Figures










read the original abstract
We address the challenge of enabling robots to manipulate deformable linear objects (DLOs), such as ropes, cables, and rubber bands. Prior work has primarily focused on narrow, task-specific problems, often relying on real-world demonstrations or handcrafted heuristics. Such approaches, however, struggle to scale to the wide variety of materials and tasks encountered in practice, and collecting sufficiently diverse real-world data is often impractical. Additionally, existing simulation environments offer limited support for the broad spectrum of material behaviors necessary for generalizable DLO manipulation. To overcome these limitations, we introduce a differentiable simulator explicitly designed for versatile DLO manipulation. Our simulator models a wide range of material properties-including (in)extensibility, elasticity, bending plasticity, and complex interactions with other objects-providing a robust foundation for learning and evaluating manipulation skills. Building on this simulator, we propose a benchmark suite of representative tasks that highlight the unique challenges of DLO manipulation. The successful execution of these tasks is often hindered by the topological complexity and grasp sensitivity inherent to DLOs. Therefore, we introduce a specialized DLO agent that explicitly manages these challenges by proposing strategic grasping points and decomposing long-horizon tasks to maximize control authority. Finally, we evaluate various policy-learning algorithms using our framework, alongside sim-to-real transfer experiments, demonstrating our platform's potential to advance DLO manipulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DLO-Lab, a benchmark and differentiable physics simulator for deformable linear object (DLO) manipulation tasks such as those involving ropes, cables, and rubber bands. The simulator is claimed to model (in)extensibility, elasticity, bending plasticity, and complex object interactions. The work also presents a suite of representative benchmark tasks, a specialized DLO agent that proposes strategic grasping points and decomposes long-horizon tasks to address topological complexity and grasp sensitivity, and evaluations of policy-learning algorithms together with sim-to-real transfer experiments.
Significance. If the simulator accurately captures the stated material behaviors and the benchmark tasks plus agent design demonstrably improve learning and transfer, the platform could address gaps in existing DLO simulation environments and provide a standardized testbed for generalizable manipulation skills. The differentiable aspect may enable more efficient policy optimization, and the explicit handling of DLO-specific challenges could reduce reliance on real-world data or heuristics.
major comments (1)
- [Abstract] Abstract: the central claims that the simulator provides a 'robust foundation' and that the DLO agent 'maximizes control authority' rest on unshown experiments; no quantitative results, error metrics, or validation details are supplied to support the modeling of material properties or the agent's effectiveness against topological complexity.
Simulated Author's Rebuttal
We thank the referee for their feedback on the manuscript. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims that the simulator provides a 'robust foundation' and that the DLO agent 'maximizes control authority' rest on unshown experiments; no quantitative results, error metrics, or validation details are supplied to support the modeling of material properties or the agent's effectiveness against topological complexity.
Authors: The abstract is a high-level summary of the contributions. Quantitative validation of the simulator (error metrics for (in)extensibility, elasticity, bending plasticity, and complex interactions) and of the DLO agent (success rates on tasks involving topological complexity, grasp sensitivity, strategic grasping, and long-horizon decomposition) appears in Sections 4 and 5, which report policy-learning evaluations and sim-to-real transfer results. These sections supply the supporting experiments and metrics referenced in the abstract claims. We can revise the abstract to include one or two representative quantitative highlights if the referee recommends it. revision: partial
Circularity Check
No significant circularity identified
full rationale
The paper introduces a new differentiable simulator for DLOs, a benchmark suite, and a specialized agent without any mathematical derivations, equations, or first-principles predictions. No load-bearing steps reduce to fitted inputs, self-citations, or self-definitional constructs. Claims rest on the novelty and capabilities of the introduced components, which are self-contained and externally evaluable via the described experiments and sim-to-real transfers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Self-supervised learning of state estimation for manipulating deformable linear objects , author=
-
[2]
Robotic manipulation of deformable rope-like objects using differentiable compliant position-based dynamics , author=
-
[3]
Offline-online learning of deformation model for cable manipulation with graph neural networks , author=
-
[4]
Learning-based
Tang, Yunxi and Chu, Xiangyu and Huang, Jing and Au, KW Samuel , journal=RAL, volume=. Learning-based
-
[5]
Differentiable Discrete Elastic Rods for Real-Time Modeling of Deformable Linear Objects , author=
-
[6]
Extreme Mechanics Letters , volume=
A fully implicit method for robust frictional contact handling in elastic rods , author=. Extreme Mechanics Letters , volume=
-
[7]
Siwei Chen and Yiqing Xu and Cunjun Yu and Linfeng Li and Xiao Ma and Zhongwen Xu and David Hsu , year=
-
[8]
Codimensional incremental potential contact , author=
-
[9]
Zheng, Shaokun and Zhou, Zhiqian and Chen, Xin and Yan, Difei and Zhang, Chuyan and Geng, Yuefeng and Gu, Yan and Xu, Kun , journal=TOG, volume=
-
[10]
Robotic manipulation of deformable linear objects for assembly operations , author=
-
[11]
Laezza, Rita and Gieselmann, Robert and Pokorny, Florian T and Karayiannidis, Yiannis , booktitle=ICRA, year=
-
[12]
Vision-based robotic grasping and manipulation of
Li, Xiang and Su, Xing and Gao, Yuan and Liu, Yun-Hui , booktitle=ICRA, year=. Vision-based robotic grasping and manipulation of
-
[13]
IEEE Transactions on Robotics , volume=
Multistage cable routing through hierarchical imitation learning , author=. IEEE Transactions on Robotics , volume=
-
[14]
Motion planning for robotic manipulation of deformable linear objects , author=
-
[15]
Taichi: A language for high-performance computation on spatially sparse data structures , author=
-
[16]
Hu, Yuanming and Anderson, Luke and Li, Tzu Mao and Sun, Qi and Carr, Nathan and Ragan-Kelley, Jonathan and Durand, Fr
-
[17]
2024 , url =
Genesis Authors , title =. 2024 , url =
2024
-
[18]
Discrete elastic rods , author=
-
[19]
Discrete viscous threads , author=
-
[20]
, author=
Incremental Potential Contact: Intersection-and Inversion-free, Large-deformation Dynamics. , author=
-
[21]
Journal of Visual Communication and Image Representation , volume=
Position Based Dynamics , author=. Journal of Visual Communication and Image Representation , volume=
-
[22]
arXiv preprint arXiv:1412.6980 , year=
Adam: A method for stochastic optimization , author=. arXiv preprint arXiv:1412.6980 , year=
-
[23]
Huang, Zhiao and Hu, Yuanming and Du, Tao and Zhou, Siyuan and Su, Hao and Tenenbaum, Joshua B and Gan, Chuang , booktitle=ICLR, year=
-
[24]
Xian, Zhou and Zhu, Bo and Xu, Zhenjia and Tung, Hsiao-Yu and Torralba, Antonio and Fragkiadaki, Katerina and Gan, Chuang , booktitle=ICLR, year=
-
[25]
Thin-Shell Object Manipulations With Differentiable Physics Simulations , author=
-
[26]
Li, Xuan and Qiao, Yi-Ling and Chen, Peter Yichen and Jatavallabhula, Krishna Murthy and Lin, Ming and Jiang, Chenfanfu and Gan, Chuang , booktitle=ICLR, year=
-
[27]
Learning neural constitutive laws from motion observations for generalizable
Ma, Pingchuan and Chen, Peter Yichen and Deng, Bolei and Tenenbaum, Joshua B and Du, Tao and Gan, Chuang and Matusik, Wojciech , booktitle=ICML, year=. Learning neural constitutive laws from motion observations for generalizable
-
[28]
Cao, Junyi and Guan, Shanyan and Ge, Yanhao and Li, Wei and Yang, Xiaokang and Ma, Chao , title =
-
[29]
Warp: A High-performance Python Framework for
Miles Macklin , month =. Warp: A High-performance Python Framework for. 2022 , note =
2022
-
[30]
, title =
Qiao, Yi-Ling and Liang, Junbang and Koltun, Vladlen and Lin, Ming C. , title =
-
[31]
Li, Yifei and Du, Tao and Wu, Kui and Xu, Jie and Matusik, Wojciech , journal=TOG, volume=
-
[32]
Xue, Haotian and Torralba, Antonio and Tenenbaum, Josh and Yamins, Dan and Li, Yunzhu and Tung, Hsiao-Yu , booktitle=NIPS, year=
-
[33]
Learning to simulate complex physics with graph networks , author=
-
[34]
Learning mesh-based simulation with graph networks , author=
-
[35]
IEEE Transactions on Industrial Informatics , volume=
Ariadne+: Deep Learning--Based Augmented Framework for the Instance Segmentation of Wires , author=. IEEE Transactions on Industrial Informatics , volume=. 2022 , publisher=
2022
-
[36]
Deformable linear objects manipulation with online model parameters estimation , author=
-
[37]
Shape control of deformable linear objects with offline and online learning of local linear deformation models , author=
-
[38]
arXiv preprint arXiv:2302.13694 , year=
DLOFTBs--Fast Tracking of Deformable Linear Objects with B-splines , author=. arXiv preprint arXiv:2302.13694 , year=
-
[39]
Shivakumar, Kaushik and Viswanath, Vainavi and Gu, Anrui and Avigal, Yahav and Kerr, Justin and Ichnowski, Jeffrey and Cheng, Richard and Kollar, Thomas and Goldberg, Ken , journal=
-
[40]
Learning shape control of elastoplastic deformable linear objects , author=
-
[41]
Handloom: Learned tracing of one-dimensional objects for inspection and manipulation , author=
-
[42]
IROS , year=
Disentangling dense multi-cable knots , author=. IROS , year=
-
[43]
arXiv preprint arXiv:2011.04999 , year=
Untangling dense knots by learning task-relevant keypoints , author=. arXiv preprint arXiv:2011.04999 , year=
arXiv 2011
-
[44]
arXiv preprint arXiv:2107.08942 , year=
Untangling dense non-planar knots by learning manipulation features and recovery policies , author=. arXiv preprint arXiv:2107.08942 , year=
-
[45]
Lin, Xingyu and Wang, Yufei and Olkin, Jake and Held, David , booktitle=CORL, year=
-
[46]
Elastica: A compliant mechanics environment for soft robotic control , author=
-
[47]
Archive for History of Exact Sciences , pages=
Kirchhoff's theory of rods , author=. Archive for History of Exact Sciences , pages=
-
[48]
Modeling Nonlinear Problems in the Mechanics of Strings and Rods: The Role of the Balance Laws , pages=
Kirchhoff’s rod theory , author=. Modeling Nonlinear Problems in the Mechanics of Strings and Rods: The Role of the Balance Laws , pages=. 2017 , publisher=
2017
-
[49]
Sample-efficient learning of deformable linear object manipulation in the real world through self-supervision , author=
-
[50]
IEEE Transactions on Robotics , volume=
Dynamic modeling and control of deformable linear objects for single-arm and dual-arm robot manipulations , author=. IEEE Transactions on Robotics , volume=
-
[51]
IEEE Transactions on Robotics , volume=
Global model learning for large deformation control of elastic deformable linear objects: An efficient and adaptive approach , author=. IEEE Transactions on Robotics , volume=
-
[52]
IEEE Robotics & Automation Magazine , volume=
Challenges and outlook in robotic manipulation of deformable objects , author=. IEEE Robotics & Automation Magazine , volume=
-
[53]
Mora, Miguel Angel Zamora and Peychev, Momchil and Ha, Sehoon and Vechev, Martin and Coros, Stelian , booktitle=ICML, year=
-
[54]
Accelerated Policy Learning with Parallel Differentiable Simulation , author=
-
[55]
Zhaole, Sun and Zhu, Jihong and Fisher, Robert B , booktitle=ICRA, year=. Dex
-
[56]
Science Robotics , volume=
Modeling, learning, perception, and control methods for deformable object manipulation , author=. Science Robotics , volume=
-
[57]
The International Journal of Robotics Research , volume=
Robotic manipulation and sensing of deformable objects in domestic and industrial applications: A survey , author=. The International Journal of Robotics Research , volume=
-
[58]
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor , author=
-
[59]
arXiv preprint arXiv:1707.06347 , year=
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
-
[60]
Evolutionary computation , volume=
Completely derandomized self-adaptation in evolution strategies , author=. Evolutionary computation , volume=. 2001 , publisher=
2001
-
[61]
Hansen, Nikolaus and Akimoto, Youhei and Baudis, Petr , year=
-
[62]
SIGGRAPH 2016 courses , year=
The material point method for simulating continuum materials , author=. SIGGRAPH 2016 courses , year=
2016
-
[63]
A moving least squares material point method with displacement discontinuity and two-way rigid body coupling , author=
-
[64]
2012 , publisher=
Sifakis, Eftychios and Barbic, Jernej , booktitle=. 2012 , publisher=
2012
-
[65]
Lin, Yuchen and Lin, Chenguo and Xu, Jianjin and MU, Yadong , booktitle=ICLR, year=
-
[66]
Journal of Machine Learning Research , year =
Carlo D'Eramo and Davide Tateo and Andrea Bonarini and Marcello Restelli and Jan Peters , title =. Journal of Machine Learning Research , year =
-
[67]
Geometry-aware
Tai Hoang and Huy Le and Philipp Becker and Vien Anh Ngo and Gerhard Neumann , booktitle=ICLR, year=. Geometry-aware
-
[68]
Do differentiable simulators give better policy gradients? , author=
-
[69]
Stabilizing Reinforcement Learning in Differentiable Multiphysics Simulation , author=
-
[70]
Caron, Stéphane and De Mont-Marin, Yann and Budhiraja, Rohan and Bang, Seung Hyeon and Domrachev, Ivan and Nedelchev, Simeon and Du, Peter and Escande, Adrien and Vaillant, Joris and Wingo, Bruce , license =
-
[71]
Jiang, Hanxiao and Hsu, Hao-Yu and Zhang, Kaifeng and Yu, Hsin-Ni and Wang, Shenlong and Li, Yunzhu , booktitle=ICCV, year=
-
[72]
Luo, Haining and Demiris, Yiannis , journal=
-
[73]
ICRA Workshop , year=
Dinkel, Holly and B. ICRA Workshop , year=
-
[74]
IEEE Transactions on Automation Science and Engineering , year=
Learning graph dynamics with interaction effects propagation for deformable linear objects shape control , author=. IEEE Transactions on Automation Science and Engineering , year=
-
[75]
Pan, Chaoyi and Wang, Changhao and Qi, Haozhi and Liu, Zixi and Bharadhwaj, Homanga and Sharma, Akash and Wu, Tingfan and Shi, Guanya and Malik, Jitendra and Hogan, Francois , journal=
-
[76]
Huang, Mu and Wang, Hui and Ren, Kerui and Xu, Linning and Zhou, Yunsong and Yu, Mulin and Dai, Bo and Pang, Jiangmiao , journal=
-
[77]
IROS , year=
Learning generalizable language-conditioned cloth manipulation from long demonstrations , author=. IROS , year=
-
[78]
Wang, Yuran and Wu, Ruihai and Chen, Yue and Wang, Jiarui and Liang, Jiaqi and Zhu, Ziyu and Geng, Haoran and Malik, Jitendra and Abbeel, Pieter and Dong, Hao , booktitle=NIPS, year=
-
[79]
Li, Zeyi and Yang, Yushi and Xie, Shawn and Xu, Kyle and Chen, Tianxing and Wang, Yuran and Shen, Zhenhao and Shen, Yan and Chen, Yue and Li, Wenjun and others , journal=
-
[80]
Li, Yunfei and Ma, Xiao and Xu, Jiafeng and Cui, Yu and Cui, Zhongren and Han, Zhigang and Huang, Liqun and Kong, Tao and Liu, Yuxiao and Niu, Hao and others , journal=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.