Residual GPU Cache State on Apple M4 Pro
Pith reviewed 2026-06-26 01:55 UTC · model grok-4.3
The pith
GPU kernels on the M4 Pro leave residual displacement in the shared cache, slowing the first subsequent CPU traversal until a second pass recovers most performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
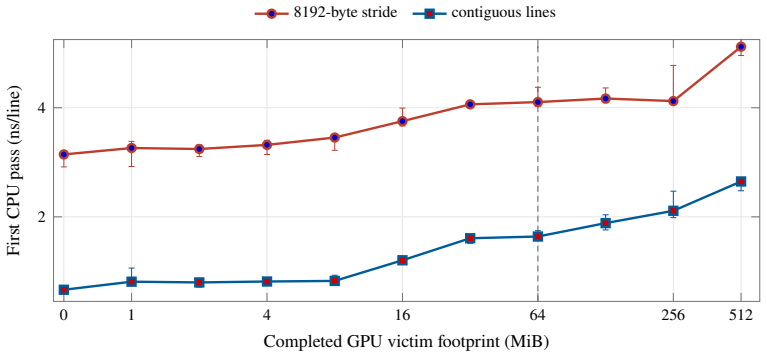
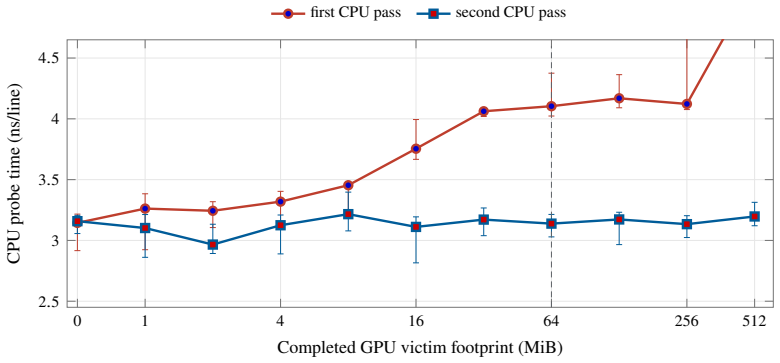
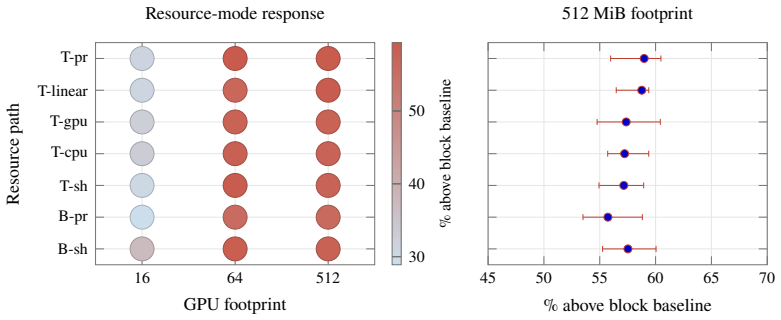
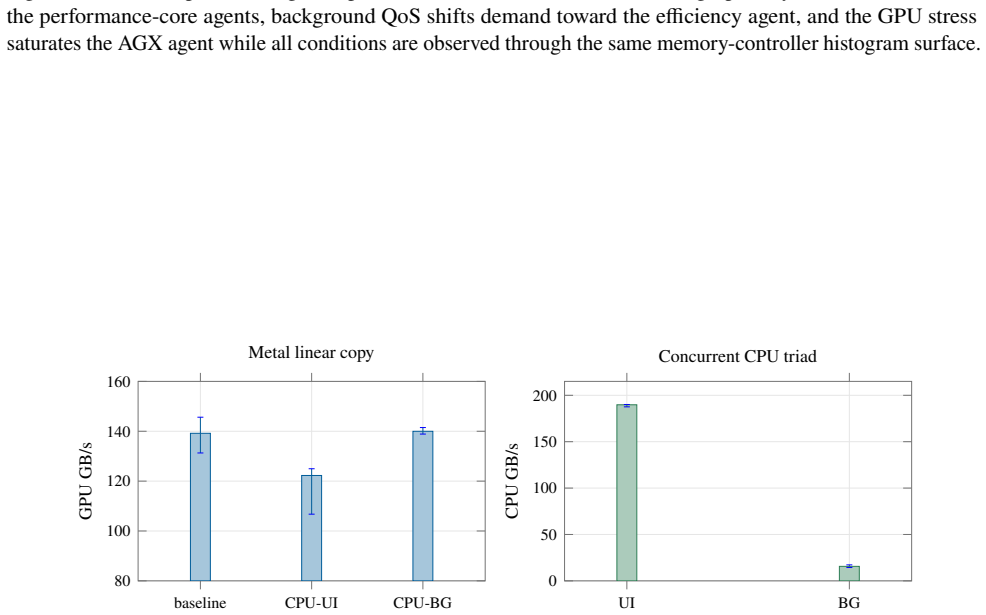
The paper establishes that a GPU kernel that touches between 0 and 512 MiB and then finishes creates a measurable post-GPU cache-displacement window on the M4 Pro. The first CPU traversal after the GPU command is slower for larger footprints, while a second traversal largely eliminates the slowdown, demonstrating that the effect is residual shared-cache displacement separable from simultaneous DRAM contention. Matched-block experiments further show that high-priority CPU traffic causes only baseline-level slowdown on the GPU.
What carries the argument
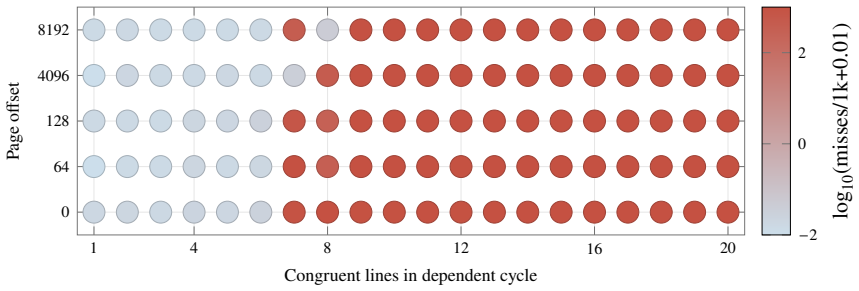
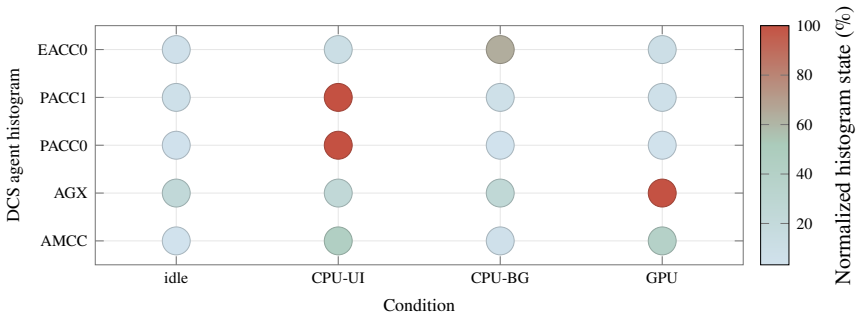
The synchronized Metal experiment paired with an 8192-byte system-level-cache occupancy pattern and a 16 MiB CPU probe that starts after the GPU kernel finishes, used to measure traversal slowdowns as evidence of residual displacement.
If this is right
- Software can apply a one-pass recovery traversal to clear most of the post-GPU cache cost.
- The displacement effect scales with GPU memory footprint size up to 512 MiB.
- GPU performance under background CPU traffic stays close to baseline when QoS is managed.
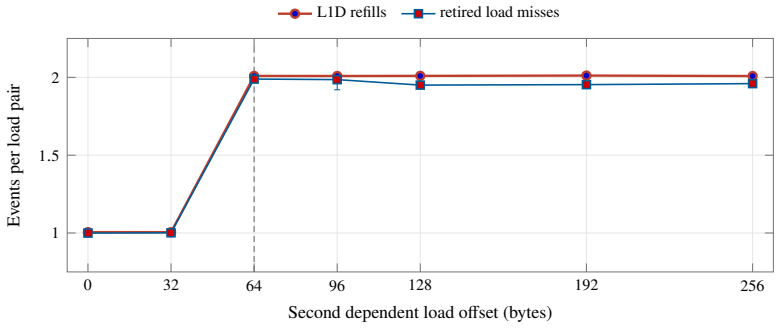
- Root PMU and IOReport data can distinguish L1D refills, page-offset conflicts, and core-type demands in such measurements.
Where Pith is reading between the lines
- Task schedulers on unified-memory Apple silicon could time CPU probes to exploit or avoid this window.
- Similar residual cache effects may appear on other M-series chips with unified CPU-GPU memory.
- Workload designers might interleave small GPU and CPU phases to reduce cross-device cache pollution.
- The measurement pipeline could extend to quantify recovery costs for different probe sizes.
Load-bearing premise
The synchronized Metal timing and CPU probe accurately capture residual shared-cache displacement without being confounded by DRAM contention, OS scheduling, or measurement overhead.
What would settle it
If first and second CPU traversals show identical times regardless of prior GPU footprint size, or if the slowdown remains unchanged after the second pass.
Figures
read the original abstract
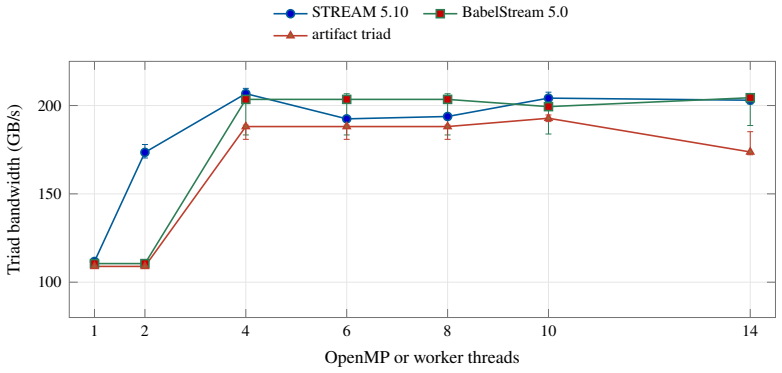
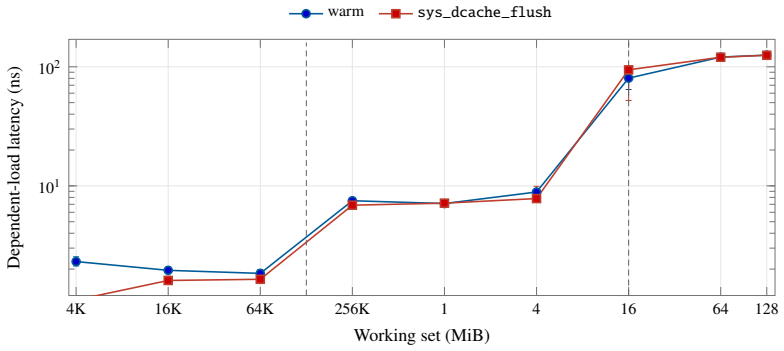
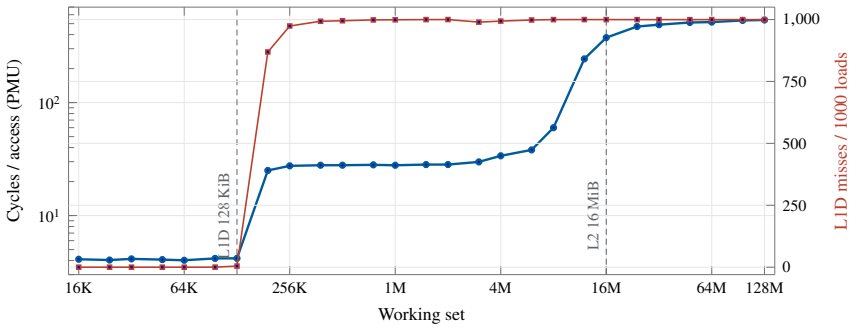
Apple silicon exposes unified CPU-GPU memory, but the cache state left after a completed GPU command is not documented. This paper characterizes that phase boundary on a 14-core Apple M4 Pro. We validate the measurement pipeline against unmodified STREAM 5.10 and BabelStream 5.0, then adapt an 8192-byte system-level-cache occupancy pattern to a synchronized Metal experiment. A GPU kernel touches 0 to 512 MiB and finishes before a 16 MiB CPU probe begins. The first CPU traversal is slower after large GPU footprints, while a second traversal removes most of the cost, showing residual shared-cache displacement rather than simultaneous DRAM contention. A separate matched-block experiment measures GPU slowdown under high-priority CPU traffic and finds background QoS close to baseline. Root PMU measurements and public IOReport histograms provide hardware grounding: they distinguish L1D refill sectors from software cache-line size, expose page-offset-dependent conflict behavior, and separate performance-core, efficiency-core, and AGX demand. The results identify a reproducible post-GPU cache-displacement window on M4 Pro and quantify a simple one-pass software recovery mechanism.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims to empirically characterize undocumented residual shared-cache state after completed GPU commands on the 14-core Apple M4 Pro. Using a synchronized Metal experiment, a GPU kernel touches 0–512 MiB before a 16 MiB CPU probe begins; the first CPU traversal exhibits slowdown after large GPU footprints while a second traversal recovers most performance, indicating cache displacement rather than ongoing DRAM contention. The pipeline is validated against unmodified STREAM 5.10 and BabelStream 5.0; separate QoS tests, root PMU data, and public IOReport histograms distinguish L1D refills, page-offset conflicts, and core/AGX demand. The results identify a reproducible post-GPU cache-displacement window and quantify a one-pass software recovery mechanism.
Significance. If the isolation of cache effects holds, the work supplies the first detailed empirical data on the CPU–GPU phase boundary in Apple unified memory, a previously undocumented aspect of the architecture. The two-traversal design, hardware-counter grounding, and identification of a simple recovery mechanism are strengths that could inform performance tuning for heterogeneous workloads on these platforms. The reproducible measurement approach may also serve as a template for similar studies on other unified-memory SoCs.
major comments (2)
- [Abstract and synchronized Metal experiment description] Abstract and synchronized Metal experiment description: the claim that the second traversal demonstrates residual shared-cache displacement (rather than DRAM contention) is load-bearing, yet the validation against STREAM/BabelStream does not directly test the timing window or rule out OS preemption, TLB/prefetcher state, or probe-induced conflicts with M4 Pro SLC/L2 sizes.
- [PMU/IOReport grounding paragraph] PMU/IOReport grounding paragraph: while the counters distinguish L1D refill sectors from software cache-line size and separate performance/efficiency/AGX demand, the manuscript does not present data showing absence of DRAM traffic correlation specifically during the CPU probe window after Metal command completion.
minor comments (2)
- The manuscript should include quantitative timing histograms or jitter statistics for the interval between GPU command completion and CPU probe start to allow readers to assess scheduling variability.
- Tables or supplementary data files reporting per-run traversal times, standard deviations, and exact GPU footprint sizes would strengthen verifiability of the occupancy results.
Simulated Author's Rebuttal
We appreciate the referee's insightful comments on our work characterizing residual GPU cache state on the Apple M4 Pro. The feedback highlights areas where the evidence distinguishing cache displacement from DRAM contention can be clarified. We respond to each major comment below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Abstract and synchronized Metal experiment description] Abstract and synchronized Metal experiment description: the claim that the second traversal demonstrates residual shared-cache displacement (rather than DRAM contention) is load-bearing, yet the validation against STREAM/BabelStream does not directly test the timing window or rule out OS preemption, TLB/prefetcher state, or probe-induced conflicts with M4 Pro SLC/L2 sizes.
Authors: We agree that the validation with STREAM and BabelStream establishes the reliability of our measurement pipeline for standard workloads but does not specifically address the post-GPU timing window or explicitly rule out the listed confounds. In the revised manuscript, we will add a dedicated paragraph in the experiment description section discussing these points: the tight synchronization via Metal command completion and CPU probe start minimizes preemption opportunities; TLB and prefetcher states are unlikely to explain the differential performance between first and second traversals since the second pass recovers; and the 16 MiB probe size was chosen based on prior SLC size knowledge to avoid boundary conflicts, with supporting sensitivity experiments. These additions will strengthen the claim without altering the core results. revision: partial
-
Referee: [PMU/IOReport grounding paragraph] PMU/IOReport grounding paragraph: while the counters distinguish L1D refill sectors from software cache-line size and separate performance/efficiency/AGX demand, the manuscript does not present data showing absence of DRAM traffic correlation specifically during the CPU probe window after Metal command completion.
Authors: The presented PMU and IOReport data show strong correlation between L1D refills and the first-traversal slowdown, with recovery on the second traversal, which we interpret as evidence of cache state rather than persistent DRAM contention. We acknowledge, however, that direct measurements of DRAM traffic (such as memory controller activity) specifically during the CPU probe window are not included in the manuscript. Our experiments captured L1D and core demand but not DRAM-level counters in that precise interval. We will revise the PMU grounding paragraph to explicitly state the basis of our inference and add a limitations note regarding the absence of direct DRAM correlation data. This will be a partial revision. revision: partial
Circularity Check
No significant circularity: pure empirical measurement study
full rationale
The paper is an empirical characterization of residual GPU cache state on M4 Pro using Metal kernels, CPU probes, STREAM/BabelStream validation, PMU/IOReport data, and QoS tests. No equations, derivations, fitted parameters, or predictions appear in the abstract or described methodology. Central claims rest on direct timing measurements of first vs. second traversals and external hardware counters, not on quantities defined by the experiment itself. No self-citation load-bearing steps, uniqueness theorems, or ansatzes are invoked. The study is self-contained against external benchmarks and reports raw observations rather than any closed-loop reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The adapted 8192-byte system-level-cache occupancy pattern produces measurable and reproducible displacement when transferred to a Metal-synchronized GPU kernel.
Reference graph
Works this paper leans on
-
[1]
Apple introduces M4 Pro and M4 Max, October 2024
Apple. Apple introduces M4 Pro and M4 Max, October 2024. Accessed 24 June 2026. URL:https: //www.apple.com/newsroom/2024/10/apple-introduces-m4-pro-and-m4-max/
2024
-
[2]
Macbookpro(14-inch,M4ProorM4Max,2024): Technicalspecifications,2024
AppleSupport. Macbookpro(14-inch,M4ProorM4Max,2024): Technicalspecifications,2024. Accessed 24 June 2026. URL:https://support.apple.com/en-us/121553
2024
-
[3]
Meet the FaM1ly.IEEE Micro, 42(3):78–84, 2022.doi:10.1109/MM.2022.3169245
Michael Mattioli. Meet the FaM1ly.IEEE Micro, 42(3):78–84, 2022.doi:10.1109/MM.2022.3169245
-
[4]
Patrick Cronin, Xing Gao, Haining Wang, and Chase Cotton. An exploration of ARM system-level cache and GPU side channels. InProceedings of the 37th Annual Computer Security Applications Conference, pages 784–795, 2021.doi:10.1145/3485832.3485902
-
[5]
Fletcher
Jiyong Yu, Aishani Dutta, Trent Jaeger, David Kohlbrenner, and Christopher W. Fletcher. Synchronization storagechannels(S2C):Timer-lesscacheside-channelattacksontheAppleM1viahardwaresynchronization instructions. In32ndUSENIXSecuritySymposium, pages1973–1990, 2023. URL:https://www.usenix. org/conference/usenixsecurity23/presentation/yu-jiyong
1990
-
[6]
Tianhong Xu, Aidong Adam Ding, and Yunsi Fei. EXAM: Exploiting exclusive system-level cache in Apple M-Series SoCs for enhanced cache occupancy attacks. InProceedings of the 20th ACM Asia Conference on Computer and Communications Security, 2025.doi:10.1145/3708821.3710844
-
[7]
McCalpin
John D. McCalpin. Memory bandwidth and machine balance in current high performance computers.IEEE Computer Society Technical Committee on Computer Architecture Newsletter, pages 19–25, December 1995. URL:https://www.cs.virginia.edu/~mccalpin/papers/balance/
1995
-
[8]
Tom Deakin, James Price, Matt Martineau, and Simon McIntosh-Smith. Evaluating attainable memory bandwidth of parallel programming models via BabelStream.International Journal of Computational Science and Engineering, 17(3):247–262, 2018.doi:10.1504/IJCSE.2018.095847. 15
-
[9]
lmbench: Portable tools for performance analy- sis
Larry McVoy and Carl Staelin. lmbench: Portable tools for performance analy- sis. InProceedings of the 1996 USENIX Annual Technical Conference, pages 279– 294, 1996. URL: https://www.usenix.org/conference/usenix-1996-annual-technical- conference/lmbench-portable-tools-performance-analysis
1996
-
[10]
Starnuma: Mitigating numa challenges with memory pooling,
Pouya Esmaili-Dokht, Francesco Sgherzi, Valeria Soldera Girelli, Isaac Boixaderas, Mariana Carmin, Alireza Monemi, Adria Armejach, Estanislao Mercadal, German Llort, Petar Radojkovic, et al. A mess of memory system benchmarking, simulation and application profiling. In57th IEEE/ACM International Symposium on Microarchitecture, pages 136–152, 2024.doi:10.1...
-
[11]
McCalpin
John D. McCalpin. STREAM version 5.10 reference source, 2013. Artifact commit 6703f7504a38a8da96b353cadafa64d3c2d7a2d3. URL:https://github.com/jeffhammond/STREAM
2013
-
[12]
BabelStream version 5.0 source, 2023
University of Bristol HPC Group. BabelStream version 5.0 source, 2023. Artifact commit f6ae48de899408cf50c24079417dc71a03dbb5a8. URL: https://github.com/UoB-HPC/BabelStream
2023
-
[13]
Apple Developer Documentation Archive, 2006
Apple.sys_dcache_flush(3): Cache Control. Apple Developer Documentation Archive, 2006. Accessed 24 June 2026. URL:https://developer.apple.com/library/archive/documentation/System/ Conceptual/ManPages_iPhoneOS/man3/sys_dcache_flush.3.html
2006
-
[14]
MTLResource: Storage modes and cpu/gpu visibility, 2026
Apple Developer. MTLResource: Storage modes and cpu/gpu visibility, 2026. Accessed 24 June 2026; checkedagainstthemacOS26.3SDKheader. URL: https://developer.apple.com/documentation/ metal/mtlresource
2026
-
[15]
MTLBlitCommandEncoder: Texture access optimization, 2026
Apple Developer. MTLBlitCommandEncoder: Texture access optimization, 2026. Accessed 24 June 2026; checkedagainstthemacOS26.3SDKheader. URL: https://developer.apple.com/documentation/ metal/mtlblitcommandencoder. 16
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.