Efficient Cumulative Incidence Estimation in Biobank Studies Using All Prevalent and Incident Events
Pith reviewed 2026-06-26 19:56 UTC · model grok-4.3
The pith
Biobank studies can estimate cumulative disease incidence by incorporating both prevalent and incident cases without regard to later survival.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a novel cumulative incidence function estimator, by incorporating all disease cases both prevalent and incident irrespective of their subsequent life course, permits consistent estimation of incidence under the biobank recruitment structure with entry ages between R_L and R_U, even when disease onset occurs at young ages followed by long survival.
What carries the argument
The novel cumulative incidence function (CIF) estimator that incorporates all prevalent and incident cases.
If this is right
- The estimator remains consistent for diseases that occur early with long subsequent survival.
- Asymptotic properties are derived, supporting large-sample inference.
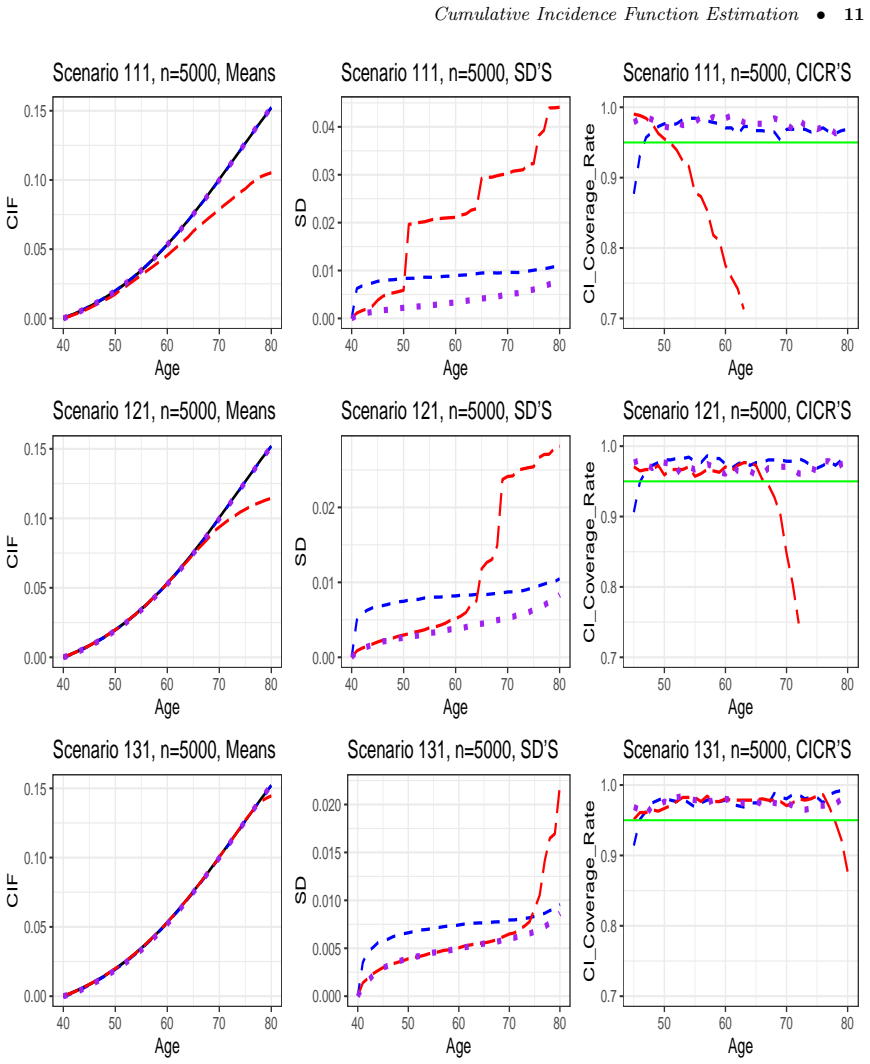
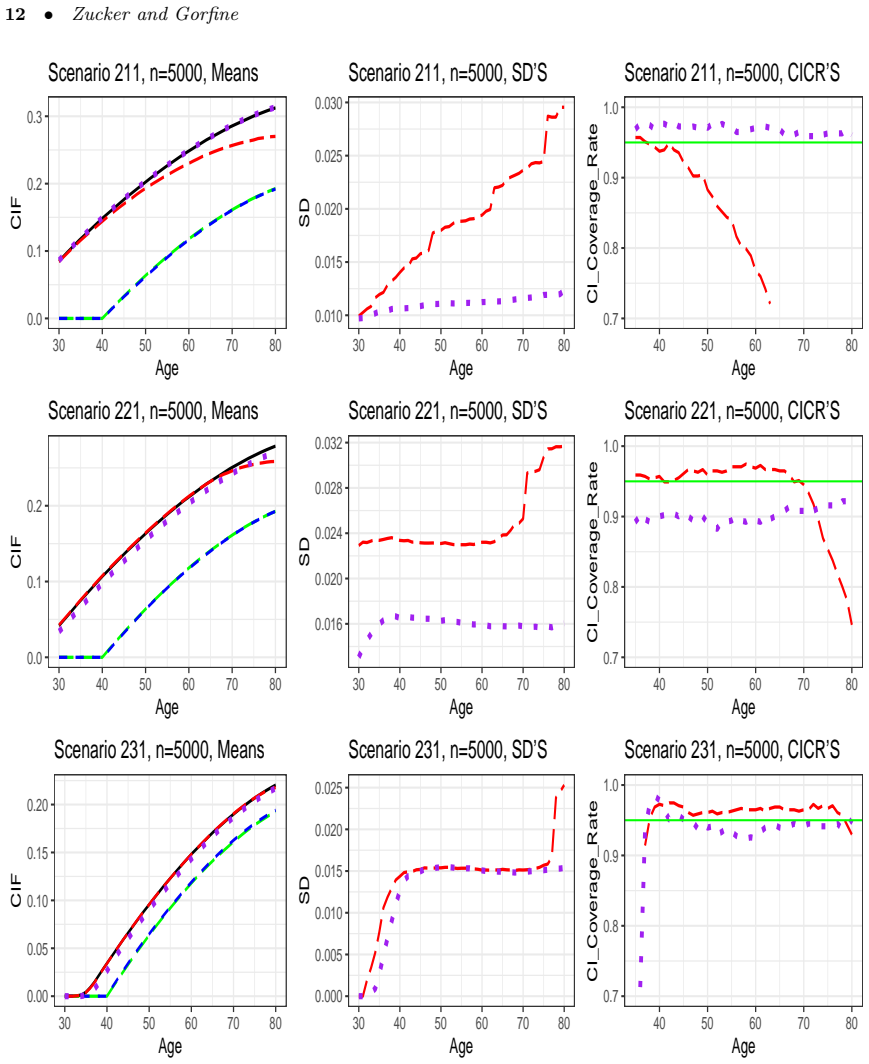
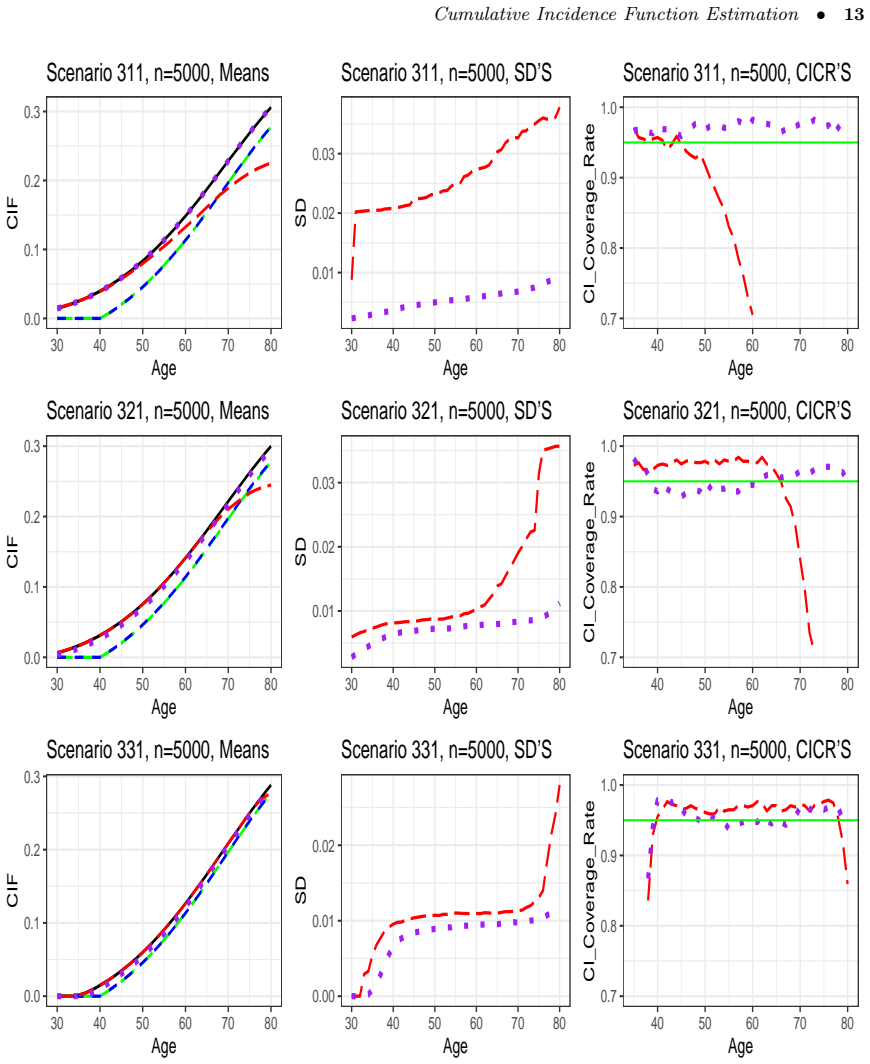
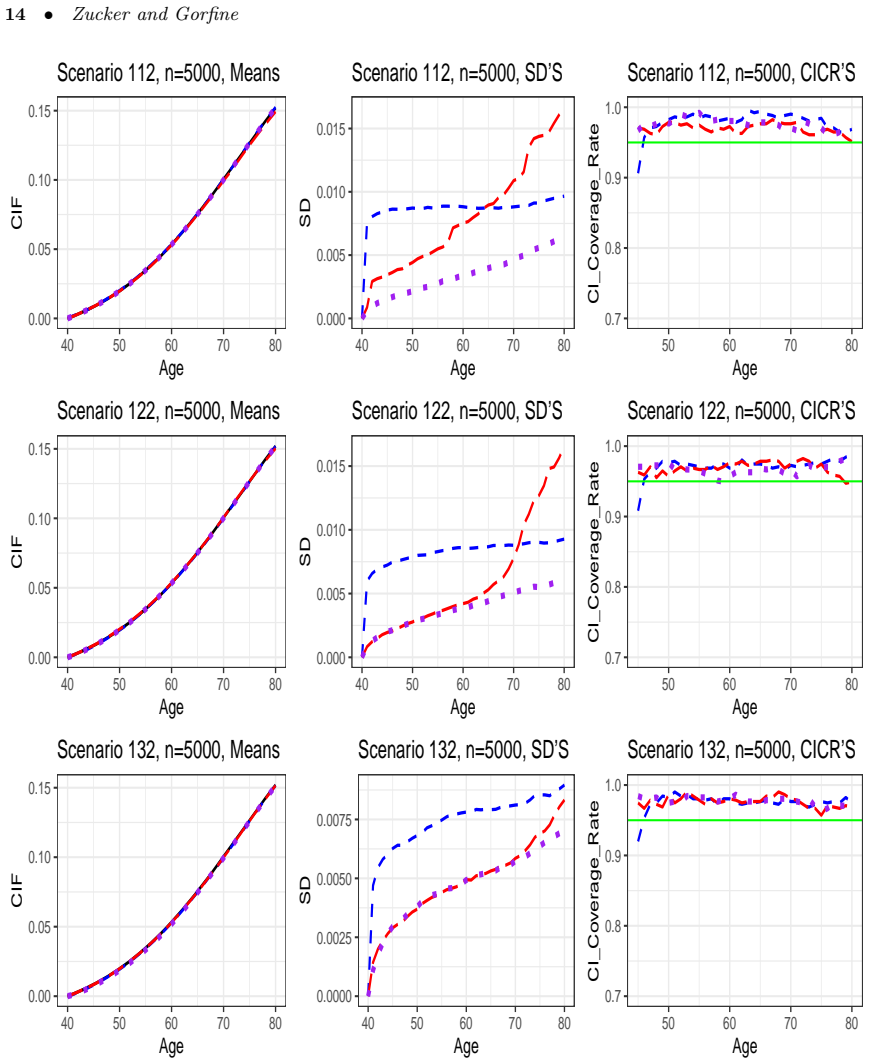
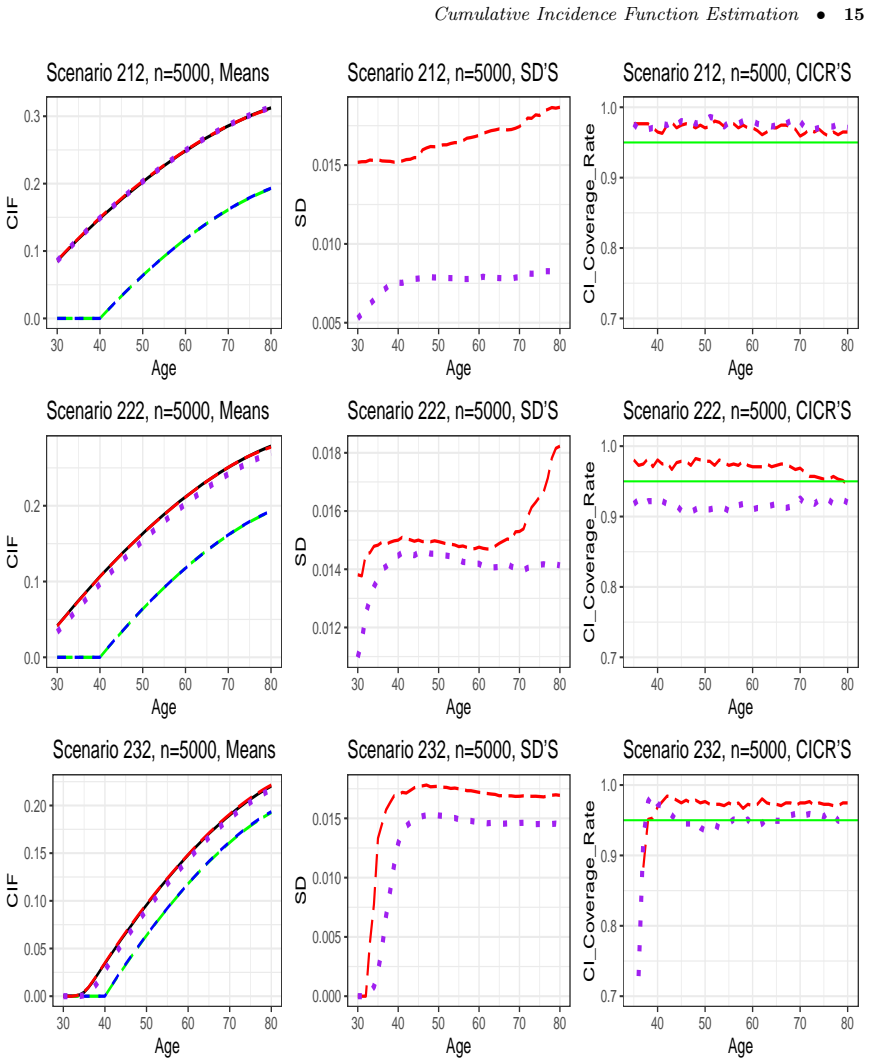
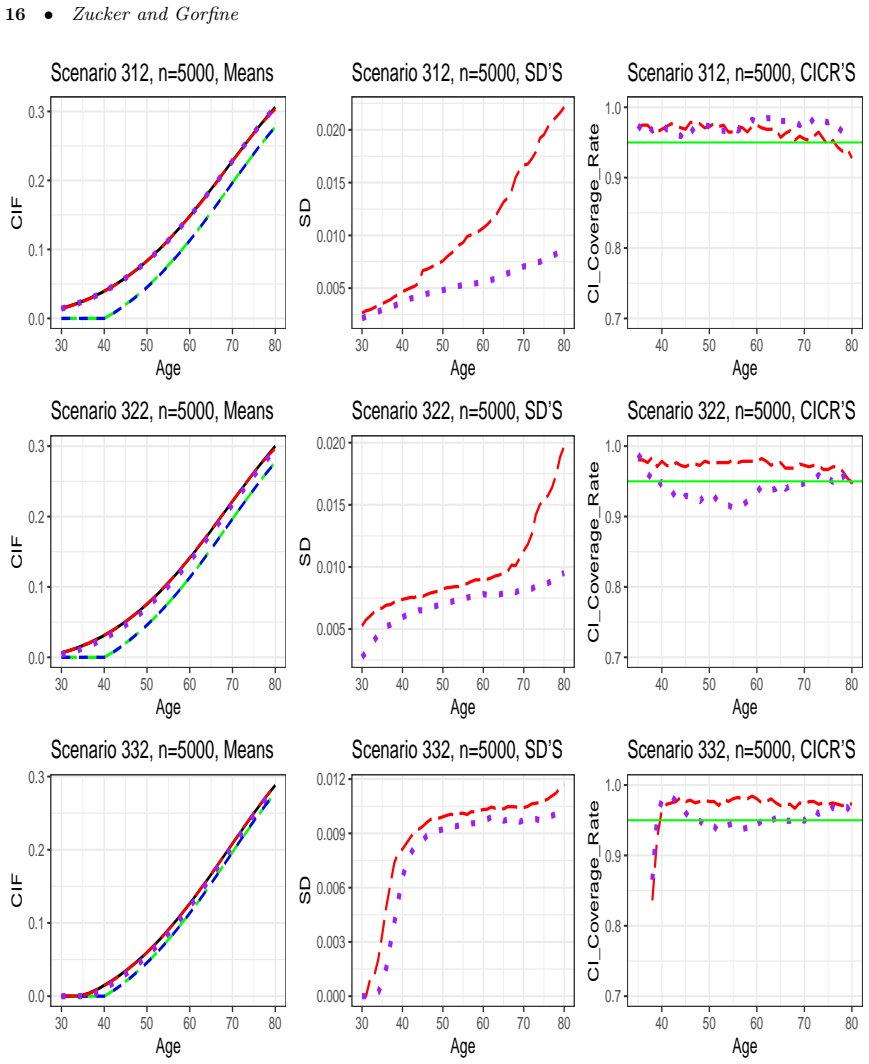
- Simulation studies show improved performance relative to methods that ignore prevalent cases.
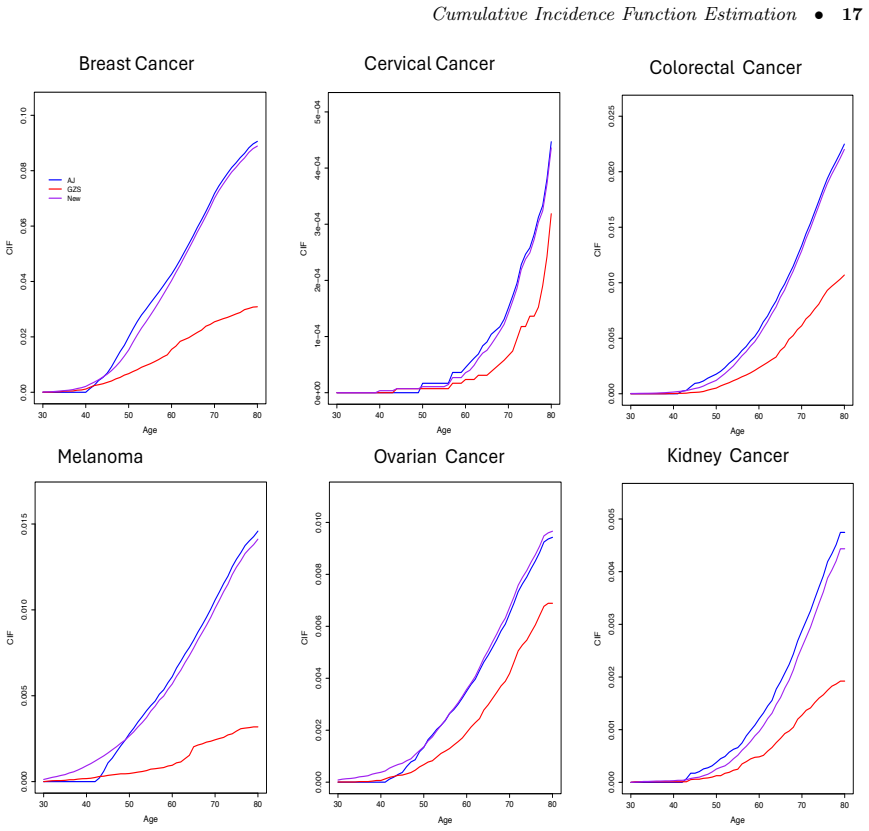
- Application to UK Biobank cancer data illustrates practical advantages in real cohorts.
- The method can be used directly on existing biobank data without additional assumptions on post-onset survival.
Where Pith is reading between the lines
- Revised incidence curves from this estimator could alter projected disease burdens used in public-health planning.
- The approach might extend naturally to settings with competing risks if the same recruitment structure holds.
- Genetic or environmental association studies that rely on accurate incidence denominators could gain precision by adopting the estimator.
Load-bearing premise
The recruitment structure with entry ages between R_L and R_U plus observation of both prevalent and incident cases is enough to produce consistent estimates even when onset is early and survival after onset is long.
What would settle it
In a simulation with known early-onset long-survival disease and fixed recruitment ages, compute the new estimator on data that include prevalent cases and check whether its value at a fixed time point deviates systematically from the true cumulative incidence while standard incident-only estimators do not.
Figures
read the original abstract
Population-based biobanks, now established in many countries, offer opportunities for large-scale studies investigating the incidence of various diseases. Biobank data is typically collected from a study cohort recruited over a defined calendar period, with subjects entering the study at various ages falling between $R_L$ and $R_U$. This work focuses on biobank data that includes individuals in whom onset of the disease of interest occurred before recruitment, termed prevalent cases, along with individuals initially recruited as disease-free in whom disease onset occurred during the follow-up period. We propose a novel cumulative incidence function (CIF) estimator that goes beyond existing methods in that it incorporates all disease cases, both prevalent and incident, irrespective of their subsequent life course. In particular, the new method can handle situations involving diseases that can occur at young ages with long survival after disease onset. Asymptotic properties of the new method are established and a simulation study is presented examining the performance of the method. We illustrate the use of the method and highlight its advantages over existing methods with an application to cancer data from the UK biobank.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a novel cumulative incidence function (CIF) estimator for biobank studies that incorporates all prevalent and incident disease cases irrespective of subsequent survival, with the goal of handling early-onset diseases with long post-onset survival under recruitment ages in [R_L, R_U]. It claims to establish asymptotic properties of the estimator, presents a simulation study evaluating performance, and illustrates advantages via an application to cancer data from the UK Biobank.
Significance. If the estimator is consistent under the required observation-process assumptions, the approach would improve efficiency by using the full set of observed cases in large biobank cohorts, offering a practical advance over methods that discard prevalent cases or restrict to incident-only data.
major comments (1)
- [Abstract / Methods] The abstract states that asymptotic properties are established and that the method permits consistent estimation for early-onset disease with long survival, yet the required censoring and observation-process assumptions (e.g., on the recruitment interval and loss to follow-up) are not made explicit; this is load-bearing for the central consistency claim and must be formalized with precise conditions in the methods section.
minor comments (1)
- [Simulation study] The simulation study description should include explicit data-exclusion rules and parameter settings to allow replication of the reported performance metrics.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address the single major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract / Methods] The abstract states that asymptotic properties are established and that the method permits consistent estimation for early-onset disease with long survival, yet the required censoring and observation-process assumptions (e.g., on the recruitment interval and loss to follow-up) are not made explicit; this is load-bearing for the central consistency claim and must be formalized with precise conditions in the methods section.
Authors: We agree that the observation-process assumptions are central to the consistency result and should be stated explicitly rather than left implicit in the technical development. In the revised manuscript we will insert a dedicated subsection (new Section 2.3) that lists the precise conditions: (i) the recruitment ages are supported on the fixed interval [R_L, R_U] with positive density; (ii) the observation process (including loss to follow-up) is independent of the disease process conditional on covariates; (iii) right-censoring is independent and non-informative; and (iv) the usual regularity conditions for the martingale representation used in the asymptotic proof. These assumptions will be cross-referenced to the statements of Theorems 1 and 2. revision: yes
Circularity Check
No significant circularity
full rationale
The paper derives a novel CIF estimator that incorporates both prevalent and incident cases under biobank recruitment constraints. Asymptotic properties are stated to be established independently, with a simulation study and external data application provided for validation. No equations, fitted parameters, or self-citations in the abstract reduce the estimator to a tautological re-expression of its inputs; the central claim remains a distinct statistical construction checked against external benchmarks rather than defined by them.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Standard regularity conditions sufficient for asymptotic normality and consistency of the proposed CIF estimator
- domain assumption Biobank recruitment produces entry ages uniformly distributed between R_L and R_U with observable prevalent cases at entry
Reference graph
Works this paper leans on
-
[1]
Scandinavian Journal of Statistics , volume=
Non-parametric regression with censored survival time data , author=. Scandinavian Journal of Statistics , volume=. 1987 , publisher=
1987
-
[2]
Emprical processes indexed by
Gin\'. Emprical processes indexed by. Annals of Probability , volume=. 1986 , publisher=
1986
-
[3]
Electronic Journal of Statistics , volume=
Fully nonparametric estimation of the marginal survival function based on case-control clustered data , author=. Electronic Journal of Statistics , volume=. 2019 , publisher=
2019
-
[4]
Gorfine, Malka and Zucker, David M and Shoham, Shoval , title =. Biometrics , volume =. 2025 , month =. doi:10.1093/biomtc/ujaf049 , url =
-
[5]
2021 , note =
tranSurv: Transformation Model Based Estimation of Survival and Regression Under Dependent Truncation and Independent Censoring , author =. 2021 , note =
2021
-
[6]
Biometrika , volume=
A note on the product-limit estimator under right censoring and left truncation , author=. Biometrika , volume=. 1987 , publisher=
1987
-
[7]
Biometrika , volume=
Martingale-based residuals for survival models , author=. Biometrika , volume=. 1990 , publisher=
1990
-
[8]
Testing quasi-independence of failure and truncation times via conditional
Martin, Emily C and Betensky, Rebecca A , journal=. Testing quasi-independence of failure and truncation times via conditional. 2005 , publisher=
2005
-
[9]
Biometrika , volume=
Confidence bands for survival curves under the proportional hazards model , author=. Biometrika , volume=. 1994 , publisher=
1994
-
[10]
Technometrics , volume=
Confidence bands for survival functions with censored data: a comparative study , author=. Technometrics , volume=. 1984 , publisher=
1984
-
[11]
Biometrika , volume=
Checking the Cox model with cumulative sums of martingale-based residuals , author=. Biometrika , volume=. 1993 , publisher=
1993
-
[12]
Biometrika , volume=
Testing the assumption of independence of truncation time and failure time , author=. Biometrika , volume=. 1990 , publisher=
1990
-
[13]
A note on variance estimation of the
Allignol, Arthur and Schumacher, Martin and Beyersmann, Jan , journal=. A note on variance estimation of the. 2010 , publisher=
2010
-
[14]
Statistics in Medicine , volume=
Sampling-based estimation for massive survival data with additive hazards model , author=. Statistics in Medicine , volume=. 2020 , publisher=
2020
-
[15]
An empirical transition matrix for non-homogeneous
Aalen, Odd O and Johansen, S. An empirical transition matrix for non-homogeneous. Scandinavian Journal of Statistics , volume=. 1978 , publisher=
1978
-
[16]
Biometrika , volume=
Longitudinal data analysis using generalized linear models , author=. Biometrika , volume=. 1986 , publisher=
1986
-
[17]
Lifetime
Product-limit survival functions with correlated survival times , author=. Lifetime. 1995 , publisher=
1995
-
[18]
Ying, Z and Wei, LJ , journal=. The. 1994 , publisher=
1994
-
[19]
The Journal of Machine Learning Research , volume=
A statistical perspective on algorithmic leveraging , author=. The Journal of Machine Learning Research , volume=. 2015 , publisher=
2015
-
[20]
Biometrika , volume=
A case-cohort design for epidemiologic cohort studies and disease prevention trials , author=. Biometrika , volume=. 1986 , publisher=
1986
-
[21]
Biometrika , volume=
A psudolikelihood approach to analysis of nested case-control studies , author=. Biometrika , volume=. 1997 , publisher=
1997
-
[22]
High-dimensional, massive sample-size
Mittal, Sushil and Madigan, David and Burd, Randall S and Suchard, Marc A , journal=. High-dimensional, massive sample-size. 2014 , publisher=
2014
-
[23]
Statistics and Computing , volume=
Simple boundary correction for kernel density estimation , author=. Statistics and Computing , volume=. 1993 , publisher=
1993
-
[24]
Biometrika , volume=
Likelihood calculations for matched case-control studies and survival studies with tied death times , author=. Biometrika , volume=. 1981 , publisher=
1981
-
[25]
Annals of Statistics , volume=
A survey of product-integration with a view toward application in survival analysis , author=. Annals of Statistics , volume=. 1990 , publisher=
1990
-
[26]
Annals of Statistics , volume=
Transfer of Tail Information in Censored Regression Models , author=. Annals of Statistics , volume=. 1999 , publisher=
1999
-
[27]
Bendix Carstensen and Martyn Plummer , journal =. Using. 2011 , volume =
2011
-
[28]
2006 , publisher=
Optimal design of experiments , author=. 2006 , publisher=
2006
-
[29]
1998 , publisher=
Asymptotic Statistics , author=. 1998 , publisher=
1998
-
[30]
1997 , publisher=
Bootstrap Methods and Their Application , author=. 1997 , publisher=
1997
-
[31]
1993 , publisher=
Statistical Models Based on Counting Processes , author=. 1993 , publisher=
1993
-
[32]
2008 , publisher=
Introduction to Empirical Processes and Semiparametric Inference , author=. 2008 , publisher=
2008
-
[33]
Breast Cancer Research and Treatment , volume=
Family history and risk of pregnancy-associated breast cancer (PABC) , author=. Breast Cancer Research and Treatment , volume=. 2015 , publisher=
2015
-
[34]
Probability and Related Fields , volume=
The product-limit estimator and the bootstrap: some asymptotic representations , author=. Probability and Related Fields , volume=. 1985 , publisher=
1985
-
[35]
Annals of Probability , volume=
Empirical processes indexed by Lipschitz functions , author=. Annals of Probability , volume=. 1986 , publisher=
1986
-
[36]
Advances in neural information processing systems , pages=
New subsampling algorithms for fast least squares regression , author=. Advances in neural information processing systems , pages=
-
[37]
To appear in Biometrika , year=
Optimal subsampling for quantile regression in big data , author=. To appear in Biometrika , year=
-
[38]
Journal of the American Statistical Association , volume=
Optimal subsampling for large sample logistic regression , author=. Journal of the American Statistical Association , volume=. 2018 , publisher=
2018
-
[39]
Journal of the American Statistical Association , number=
Optimal Distributed Subsampling for Maximum Quasi-Likelihood Estimators with Massive Data , author=. Journal of the American Statistical Association , number=. 2020 , publisher=
2020
-
[40]
Journal of the American Statistical Association , number=
Marginalized Frailty-Based Illness-Death Model: Application to the UK-Biobank Survival Data , author=. Journal of the American Statistical Association , number=. 2020 , publisher=
2020
-
[41]
1993 , publisher=
Statistical models based on counting processes , author=. 1993 , publisher=
1993
-
[42]
2002 , publisher=
The statistical analysis of failure time data , author=. 2002 , publisher=
2002
-
[43]
2011 , publisher=
Competing risks and multistate models with R , author=. 2011 , publisher=
2011
-
[44]
2000 , publisher=
Analysis of multivariate survival data , author=. 2000 , publisher=
2000
-
[45]
2003 , edition =
Survival analysis: techniques for censored and truncated data , author=. 2003 , edition =
2003
-
[46]
and Moeschberger, Melvin L
Klein, John P. and Moeschberger, Melvin L. , biburl =. Survival Analysis Techniques for Censored and Truncated Data , year =
-
[47]
Statistics in medicine , volume=
Likelihood analysis of multi-state models for disease incidence and mortality , author=. Statistics in medicine , volume=. 1988 , publisher=
1988
-
[48]
Lifetime
Nonparametric estimation of sojourn time distributions for truncated serial event data—a weight-adjusted approach , author=. Lifetime. 2006 , publisher=
2006
-
[49]
Biostatistics , volume=
Incorporating retrospective data into an analysis of time to illness , author=. Biostatistics , volume=. 2001 , publisher=
2001
-
[50]
Statistics in medicine , volume=
Accounting for bias due to a non-ignorable tracing mechanism in a retrospective breast cancer cohort study , author=. Statistics in medicine , volume=. 2011 , publisher=
2011
-
[51]
Journal of the Royal Statistical Society: Series C (Applied Statistics) , volume=
Bayesian semiparametric analysis of semicompeting risks data: investigating hospital readmission after a pancreatic cancer diagnosis , author=. Journal of the Royal Statistical Society: Series C (Applied Statistics) , volume=. 2015 , publisher=
2015
-
[52]
Journal of the Royal Statistical Society: Series B (Statistical Methodology) , volume=
Regression analysis based on semicompeting risks data , author=. Journal of the Royal Statistical Society: Series B (Statistical Methodology) , volume=. 2008 , publisher=
2008
-
[53]
Communications in Statistics-Simulation and Computation , volume=
Likelihood-Based Inference for Semi-Competing Risks , author=. Communications in Statistics-Simulation and Computation , volume=. 2014 , publisher=
2014
-
[54]
Biometrics , volume=
Regression modeling of semicompeting risks data , author=. Biometrics , volume=. 2007 , publisher=
2007
-
[55]
Biometrika , volume=
Estimating treatment effects with treatment switching via semicompeting risks models: an application to a colorectal cancer study , author=. Biometrika , volume=. 2011 , publisher=
2011
-
[56]
Statistical Modelling , volume=
Bayesian semi parametric multi-state models , author=. Statistical Modelling , volume=. 2008 , publisher=
2008
-
[57]
Statistics in medicine , volume=
Bayesian approach for flexible modeling of semicompeting risks data , author=. Statistics in medicine , volume=. 2014 , publisher=
2014
-
[58]
Lifetime data analysis , volume=
Bayesian gamma frailty models for survival data with semi-competing risks and treatment switching , author=. Lifetime data analysis , volume=. 2014 , publisher=
2014
-
[59]
Nature , volume=
The UK Biobank resource with deep phenotyping and genomic data , author=. Nature , volume=. 2018 , publisher=
2018
-
[60]
Journal of the American Statistical Association , volume=
Hierarchical models for semicompeting risks data with application to quality of end-of-life care for pancreatic cancer , author=. Journal of the American Statistical Association , volume=. 2016 , publisher=
2016
-
[61]
Computer methods and programs in biomedicine , volume=
A simulation procedure based on copulas to generate clustered multi-state survival data , author=. Computer methods and programs in biomedicine , volume=. 2013 , publisher=
2013
-
[62]
Journal of the Royal Statistical Society: Series A (Statistics in Society) , volume=
Age-specific incidence and prevalence: a statistical perspective , author=. Journal of the Royal Statistical Society: Series A (Statistics in Society) , volume=. 1991 , publisher=
1991
-
[63]
Biostatistics , volume=
Joint analysis of prevalence and incidence data using conditional likelihood , author=. Biostatistics , volume=. 2009 , publisher=
2009
-
[64]
Statistics in medicine , volume=
Event history analysis and the cross-section , author=. Statistics in medicine , volume=. 2006 , publisher=
2006
-
[65]
Human Biology , volume=
A simple stochastic model of recovery, relapse, death and loss of patients , author=. Human Biology , volume=. 1951 , publisher=
1951
-
[66]
Statistical methods in medical research , volume=
Multi-state models for event history analysis , author=. Statistical methods in medical research , volume=. 2002 , publisher=
2002
-
[67]
Statistics in medicine , volume=
Multistate models in survival analysis: a study of nephropathy and mortality in diabetes , author=. Statistics in medicine , volume=. 1988 , publisher=
1988
-
[68]
Biometrics , volume=
Sample size/power calculation for case--cohort studies , author=. Biometrics , volume=. 2004 , publisher=
2004
-
[69]
Journal of statistical computation and simulation , volume=
Conditional and marginal estimates in case-control family data--extensions and sensitivity analyses , author=. Journal of statistical computation and simulation , volume=. 2012 , publisher=
2012
-
[70]
Bmj , volume=
Trends in colorectal cancer mortality in Europe: retrospective analysis of the WHO mortality database , author=. Bmj , volume=. 2015 , publisher=
2015
-
[71]
Journal of clinical epidemiology , volume=
Recall bias in epidemiologic studies , author=. Journal of clinical epidemiology , volume=. 1990 , publisher=
1990
-
[72]
Annual review of public health , volume=
Using electronic health records for population health research: a review of methods and applications , author=. Annual review of public health , volume=. 2016 , publisher=
2016
-
[73]
Biometrika , volume=
Prospective survival analysis with a general semiparametric shared frailty model: A pseudo full likelihood approach , author=. Biometrika , volume=. 2006 , publisher=
2006
-
[74]
Biostatistics , volume=
Multivariate survival analysis for case--control family data , author=. Biostatistics , volume=. 2005 , publisher=
2005
-
[75]
Journal of Statistical Planning and Inference , volume=
Pseudo-full likelihood estimation for prospective survival analysis with a general semiparametric shared frailty model: Asymptotic theory , author=. Journal of Statistical Planning and Inference , volume=. 2008 , publisher=
2008
-
[76]
Biometrics , volume=
Frailty-based competing risks model for multivariate survival data , author=. Biometrics , volume=. 2011 , publisher=
2011
-
[77]
Journal of the American Statistical Association , volume=
Frailty models for familial risk with application to breast cancer , author=. Journal of the American Statistical Association , volume=. 2013 , publisher=
2013
-
[78]
Lifetime data analysis , volume=
Calibrated predictions for multivariate competing risks models , author=. Lifetime data analysis , volume=. 2014 , publisher=
2014
-
[79]
Biostatistics , volume=
A fully nonparametric estimator of the marginal survival function based on case--control clustered age-at-onset data , author=. Biostatistics , volume=. 2017 , publisher=
2017
-
[80]
Journal of the American Statistical Association , volume=
Nonparametric Adjustment for Measurement Error in Time-to-Event Data: Application to Risk Prediction Models , author=. Journal of the American Statistical Association , volume=. 2018 , publisher=
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.