Structural Under-Representation of Women in News: Nonparametric Bayesian Mixtures Capture Time-Dependent Dynamics
Pith reviewed 2026-06-27 10:57 UTC · model grok-4.3
The pith
A time-dependent Bayesian mixture model on Canadian news data shows persistent structural under-representation of women as sources across all identified clusters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
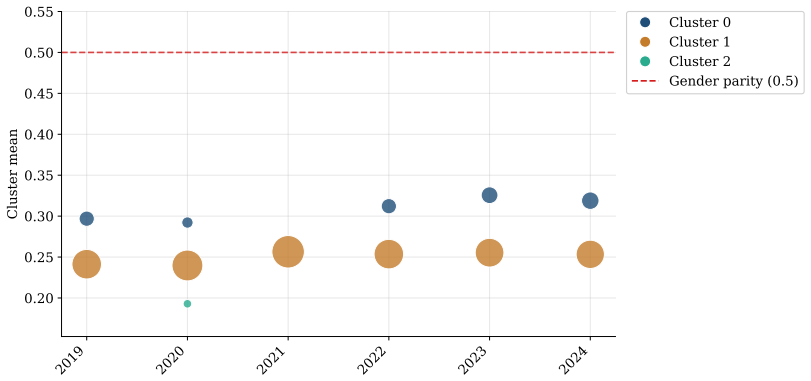
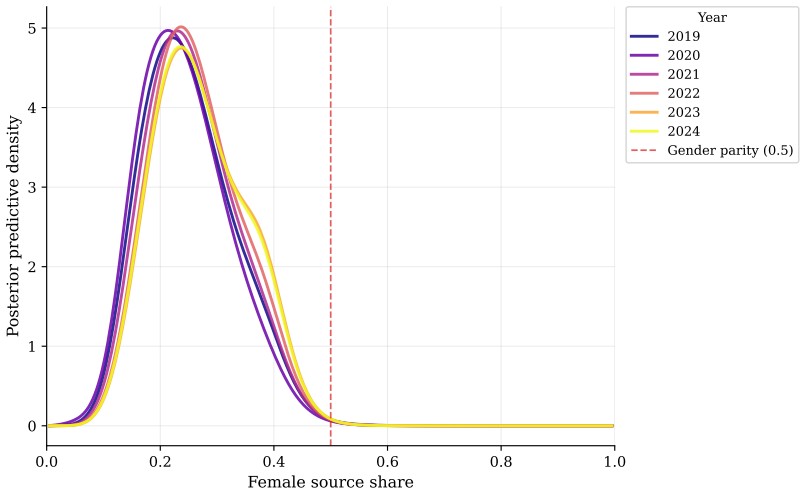
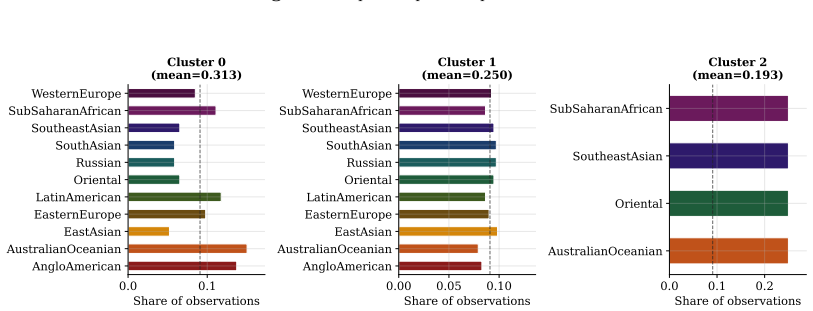
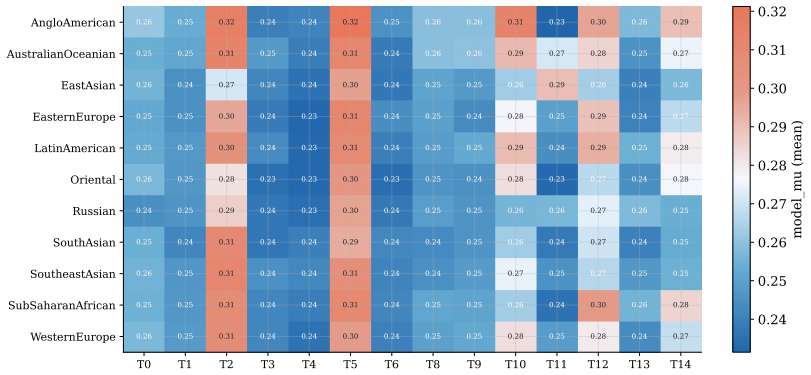
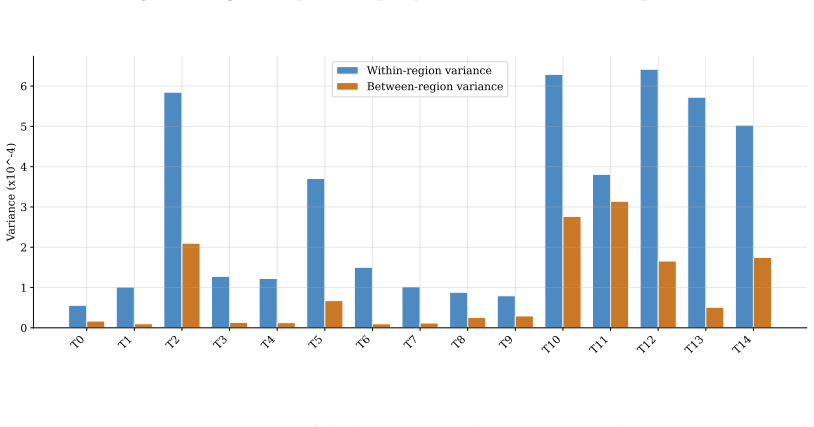
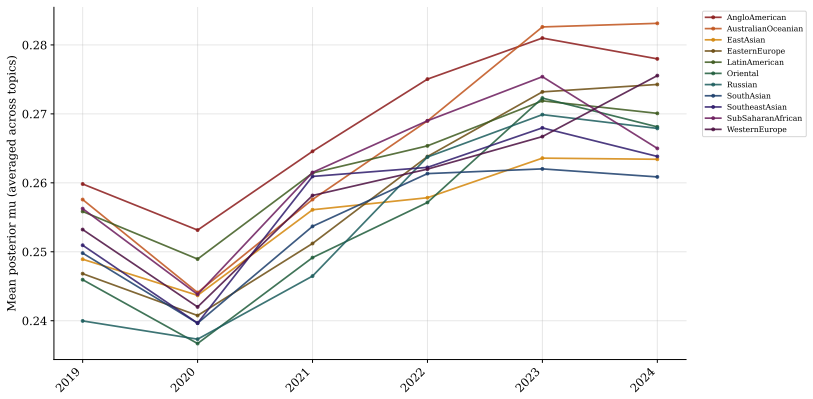
Fitted on Canadian news articles from 2019 to 2024, the model reveals structural under-representation of women across all clusters, with news topic driving differences in female quote shares more strongly than the reported-on region. More than 85% of topic-region time series show no improvement toward gender parity over the observation period. Dynamic density estimation confirms that the aggregate distribution of female quote shares remains stable between 2019 and 2024.
What carries the argument
Time-dependent Bayesian mixture model with Beta mixture kernel for bounded proportions, used to recover latent clusters and track their evolution.
Load-bearing premise
The time-dependent Bayesian mixture model with Beta kernel accurately recovers true latent cluster structures and temporal dynamics without substantial distortion from model assumptions, sampling, or unmeasured factors.
What would settle it
Re-fitting an alternative clustering method to the same data or extending the series past 2024 and finding different cluster assignments or a clear rise in female quote shares would contradict the reported stability and structure.
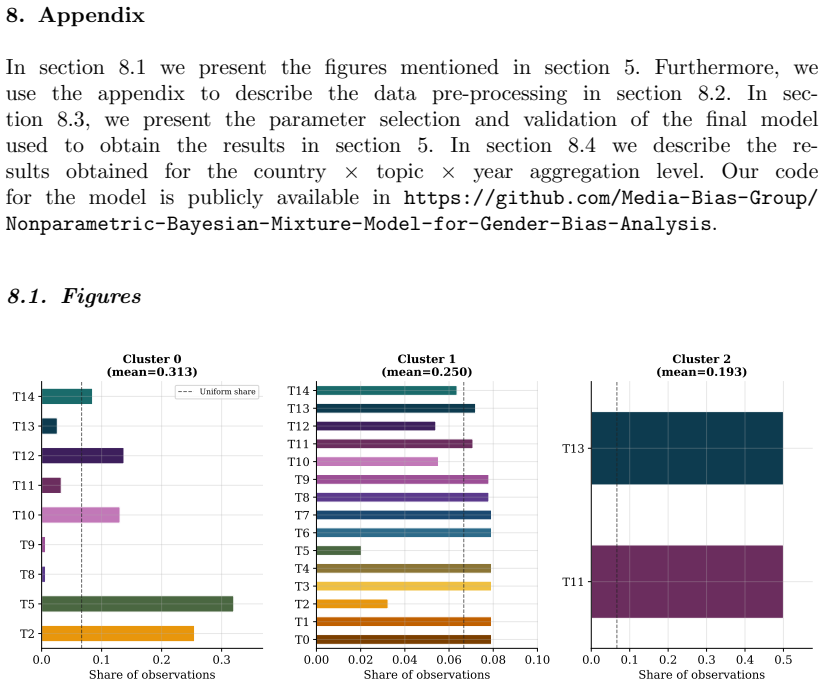
Figures
read the original abstract
The under-representation of women as sources cited in news media is one prominent representation of gender bias. Understanding where gender bias concentrates and how it evolves is essential for targeted mitigation. Because gender representation varies across topics, time, and reported-on regions, creating complex dependencies that are difficult to capture parametrically, we employ a nonparametric model to uncover latent cluster structures and temporal dynamics. We combine time-dependent Bayesian mixture modeling techniques with a Beta mixture kernel tailored to female quote shares, bounded between 0 and 1. Fitted on Canadian news articles from 2019 to 2024, the model reveals structural under-representation of women across all clusters, with news topic driving differences in female quote shares more strongly than the reported-on region. More than 85% of topic-region time series show no improvement toward gender parity over the observation period. Dynamic density estimation confirms that the aggregate distribution of female quote shares remains stable between 2019 and 2024. Our application demonstrates that advanced probabilistic models not only reproduce findings in gender bias research but also reveal latent dependencies and structural patterns that simpler approaches miss, encouraging future adoption of model-based frameworks for studying media bias.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper fits a nonparametric time-dependent Bayesian mixture model with Beta kernel to female quote shares extracted from Canadian news articles (2019–2024). It reports structural under-representation of women in all recovered clusters, stronger influence of news topic than reported-on region, that >85% of topic-region time series exhibit no improvement toward parity, and that the aggregate density of female quote shares remains stable over the period. The work positions the model as revealing latent dependencies missed by simpler approaches.
Significance. If the recovery properties of the time-dependent Beta mixture hold, the results would supply quantitative evidence of persistent, topic-driven gender bias in Canadian media and illustrate the added value of nonparametric dynamic mixtures for media-bias studies. The stability finding and topic-versus-region comparison would be directly usable for targeted interventions.
major comments (2)
- [§3] §3 (Model specification and fitting): the central claims (structural under-representation across clusters, topic dominance, >85% non-improving series, stable aggregate density) rest on the time-dependent Beta mixture correctly recovering latent cluster assignments and temporal trends. No simulation recovery experiment is described that injects known cluster labels, known improving vs. stable trajectories, and known topic/region effects and then verifies that the fitted model returns the reported proportions and ordering. Without this check, misspecification in the time-dependence mechanism or nonparametric prior could produce the observed stability and topic dominance as artifacts.
- [§4] §4 (Results): data collection and quote-extraction details (article sampling frame, quote attribution rules, handling of multiple quotes per article) are not accompanied by sensitivity checks or bias diagnostics under the model. These steps are load-bearing for the claim that topic drives differences more strongly than region.
minor comments (2)
- [§2] Notation for the time-dependent mixing weights and the Beta kernel parameters should be introduced with explicit equations rather than prose descriptions only.
- [Figure 3] Figure captions for the dynamic density plots should state the exact time windows compared and the bandwidth or smoothing parameter used.
Simulated Author's Rebuttal
We thank the referee for their constructive report and for highlighting areas where additional validation would strengthen the manuscript. We address each major comment below and commit to revisions that directly respond to the concerns about model recovery and data sensitivity.
read point-by-point responses
-
Referee: [§3] §3 (Model specification and fitting): the central claims (structural under-representation across clusters, topic dominance, >85% non-improving series, stable aggregate density) rest on the time-dependent Beta mixture correctly recovering latent cluster assignments and temporal trends. No simulation recovery experiment is described that injects known cluster labels, known improving vs. stable trajectories, and known topic/region effects and then verifies that the fitted model returns the reported proportions and ordering. Without this check, misspecification in the time-dependence mechanism or nonparametric prior could produce the observed stability and topic dominance as artifacts.
Authors: We agree that a simulation-based recovery study is a valuable addition to substantiate the model's ability to recover the reported structures. In the revised manuscript we will insert a new subsection (likely in §3) that generates synthetic datasets with known cluster labels, known improving versus stable trajectories, and known topic/region effects. We will then fit the time-dependent Beta mixture and report quantitative recovery metrics, including adjusted Rand index for cluster assignments, mean absolute error on trend slopes, and whether the model recovers the >85% non-improving proportion and the topic-over-region dominance ordering. This will directly test whether the observed stability and topic dominance can arise as artifacts. revision: yes
-
Referee: [§4] §4 (Results): data collection and quote-extraction details (article sampling frame, quote attribution rules, handling of multiple quotes per article) are not accompanied by sensitivity checks or bias diagnostics under the model. These steps are load-bearing for the claim that topic drives differences more strongly than region.
Authors: We acknowledge that the current manuscript provides limited sensitivity diagnostics for the quote-extraction pipeline. In the revision we will expand the data section with explicit descriptions of the sampling frame, attribution rules, and multiple-quote handling. We will also add a sensitivity subsection that re-runs the full pipeline under alternative attribution thresholds, article subsampling schemes, and quote-count weightings, then quantifies the stability of the topic-versus-region dominance result (e.g., via changes in posterior topic coefficients and the proportion of non-improving series). Any material shifts will be reported transparently. revision: yes
Circularity Check
Empirical model fitting on observed quote shares; no reduction of claims to fitted inputs by construction
full rationale
The paper applies a nonparametric time-dependent Bayesian mixture model with Beta kernel to Canadian news article data (2019-2024) on female quote shares. Reported results (under-representation across clusters, topic > region effects, >85% of topic-region series showing no improvement, stable aggregate density) are direct empirical summaries of the posterior from fitting the model to the data. No equations or claims in the provided text reduce these quantities to quantities defined solely by the model parameters themselves, nor do any self-citations serve as load-bearing justifications for uniqueness or ansatz choices. The derivation is a standard application of existing mixture modeling techniques to new data and is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- mixture hyperparameters and effective number of clusters
axioms (1)
- domain assumption Female quote shares arise from a mixture of Beta distributions whose parameters evolve over time according to the nonparametric model.
Reference graph
Works this paper leans on
-
[1]
Particle markov chain monte carlo methods.Journal of the Royal Statistical Society Series B: Statistical Methodology, 72(3):269–342, 2010
Christophe Andrieu, Arnaud Doucet, and Roman Holenstein. Particle markov chain monte carlo methods.Journal of the Royal Statistical Society Series B: Statistical Methodology, 72(3):269–342, 2010
2010
-
[2]
Bayesian cluster analysis.Biometrika, 65(1):31–38, 1978
David A Binder. Bayesian cluster analysis.Biometrika, 65(1):31–38, 1978
1978
-
[3]
Latent dirichlet allocation.Journal of machine Learning research, 3(Jan):993–1022, 2003
David M Blei, Andrew Y Ng, and Michael I Jordan. Latent dirichlet allocation.Journal of machine Learning research, 3(Jan):993–1022, 2003
2003
-
[4]
Measuring partisan media bias cross-nationally.Swiss Political Science Review, 27 (2):412–433, 2021
Laia Castro. Measuring partisan media bias cross-nationally.Swiss Political Science Review, 27 (2):412–433, 2021
2021
-
[5]
Costa-juss` a
Marta R. Costa-juss` a. An analysis of gender bias studies in natural language processing.Nature Machine Intelligence, 1:495–496, 2019
2019
-
[6]
Does gender matter in the news? detecting and examining gender bias in news articles
Jamell Dacon and Haochen Liu. Does gender matter in the news? detecting and examining gender bias in news articles. InCompanion Proceedings of the Web Conference 2021, pages 385–392, 2021
2021
-
[7]
Bayesian nonparametric mixture modeling for temporal dynamics of gender stereotypes.The Annals of Applied Statistics, 17(3):2256–2278, 2023
Maria De Iorio, Stefano Favaro, Alessandra Guglielmi, and Lifeng Ye. Bayesian nonparametric mixture modeling for temporal dynamics of gender stereotypes.The Annals of Applied Statistics, 17(3):2256–2278, 2023
2023
-
[8]
Gender hierarchies in reporting genocide: an analysis of the dehumanization of palestinian men in western media.Communication, Culture & Critique, 18(4):310–321, 2025
Noura El Masry, Zina Sawaf, Gretchen King, and Sami Baroudi. Gender hierarchies in reporting genocide: an analysis of the dehumanization of palestinian men in western media.Communication, Culture & Critique, 18(4):310–321, 2025
2025
-
[9]
A bayesian analysis of some non-parametric problems.The Annals of Statistics, 1(2):353–355, 1873
Thomas S Ferguson. A bayesian analysis of some non-parametric problems.The Annals of Statistics, 1(2):353–355, 1873
-
[10]
Israeli media coverage of international male and female politicians: Gender and ethnopolitical aspects.Communications, 48(2):226–248, 2023
Gilad Greenwald. Israeli media coverage of international male and female politicians: Gender and ethnopolitical aspects.Communications, 48(2):226–248, 2023
2023
-
[11]
Stick-breaking autoregressive processes.Journal of economet- rics, 162(2):383–396, 2011
Jim E Griffin and Mark FJ Steel. Stick-breaking autoregressive processes.Journal of economet- rics, 162(2):383–396, 2011
2011
-
[12]
Order-based dependent dirichlet processes.Journal of the American statistical Association, 101(473):179–194, 2006
Jim E Griffin and MF J Steel. Order-based dependent dirichlet processes.Journal of the American statistical Association, 101(473):179–194, 2006
2006
-
[13]
A time dependent bayesian nonparametric model for air quality analysis.Computational Statistics & Data Analysis, 95:161–175, 2016
Luis Guti´ errez, Rams´ es H Mena, and Matteo Ruggiero. A time dependent bayesian nonparametric model for air quality analysis.Computational Statistics & Data Analysis, 95:161–175, 2016
2016
-
[14]
Isabella Habereder, Thomas Kneib, Isao Echizen, and Timo Spinde. A systematic review of spatio-temporal statistical models: Theory, structure, and applications.arXiv preprint arXiv:2511.00422, 2025
arXiv 2025
-
[15]
Marc Hooghe, Laura Jacobs, and Ellen Claes. Enduring gender bias in reporting on political elite positions: Media coverage of female mps in belgian news broadcasts (2003–2011).The International Journal of Press/Politics, 20(4):395–414, 2015
2003
-
[16]
The promises and pitfalls of llm annotations in dataset labeling: A case study on media bias detection
Tom´ aˇ s Horych, Christoph Mandl, Terry Ruas, Andr´ e Greiner-Petter, Bela Gipp, Akiko Aizawa, and Timo Spinde. The promises and pitfalls of llm annotations in dataset labeling: A case study on media bias detection. InFindings of the Association for Computational Linguistics: NAACL 2025, pages 1370–1386, 2025
2025
-
[17]
Women are seen more than heard in online newspapers.PloS one, 11(2):e0148434, 2016
Sen Jia, Thomas Lansdall-Welfare, Saatviga Sudhahar, Cynthia Carter, and Nello Cristianini. Women are seen more than heard in online newspapers.PloS one, 11(2):e0148434, 2016
2016
-
[18]
Violators, virtuous, or victims? how global newspapers represent the female member of parliament.Feminist Media Studies, 20(5): 692–712, 2020
Devin K Joshi, Meseret F Hailu, and Lauren J Reising. Violators, virtuous, or victims? how global newspapers represent the female member of parliament.Feminist Media Studies, 20(5): 692–712, 2020
2020
-
[19]
Armand Joulin, Edouard Grave, Piotr Bojanowski, Matthijs Douze, H´ erve J´ egou, and Tomas Mikolov. Fasttext. zip: Compressing text classification models.arXiv preprint arXiv:1612.03651, 2016
Pith/arXiv arXiv 2016
-
[20]
Bag of tricks for efficient text classification
Armand Joulin, Edouard Grave, Piotr Bojanowski, and Tom´ aˇ s Mikolov. Bag of tricks for efficient text classification. InProceedings of the 15th conference of the European chapter of the association for computational linguistics: volume 2, short papers, pages 427–431, 2017
2017
-
[21]
Die geographie und die kulturerdteile
Albert Kolb. Die geographie und die kulturerdteile. In A. Leidlmair, editor,Hermann von Wissmann-Festschrift, page 46. Geographisches Institut der Universit¨ at T¨ ubingen, 1962
1962
-
[22]
Dirichlet process mixtures of beta distributions, with applications to density and intensity estimation
Athanasios Kottas. Dirichlet process mixtures of beta distributions, with applications to density and intensity estimation. InWorkshop on Learning with Nonparametric Bayesian Methods, 23rd International Conference on Machine Learning (ICML), volume 47, 2006
2006
-
[23]
Athanasios Kottas and Bruno Sans´ o. Bayesian mixture modeling for spatial poisson process intensities, with applications to extreme value analysis.Journal of Statistical Planning and Inference, 137(10):3151–3163, 2007
2007
-
[24]
Bayesian model-based clustering procedures.Journal of Com- putational and Graphical Statistics, 16(3):526–558, 2007
John W Lau and Peter J Green. Bayesian model-based clustering procedures.Journal of Com- putational and Graphical Statistics, 16(3):526–558, 2007
2007
-
[25]
Logistic-beta processes for dependent random probabilities with beta marginals.Bayesian Analysis, 20(4):1345–1369, 13 2025
Changwoo J Lee, Alessandro Zito, Huiyan Sang, and David B Dunson. Logistic-beta processes for dependent random probabilities with beta marginals.Bayesian Analysis, 20(4):1345–1369, 13 2025
2025
-
[26]
The specific visuality of women of the global south in the media of the global north
Sohyun Lee. The specific visuality of women of the global south in the media of the global north. Humanities and Social Sciences Communications, 11(1):1–10, 2024
2024
-
[27]
On a class of bayesian nonparametric estimates: I
Albert Y Lo. On a class of bayesian nonparametric estimates: I. density estimates.The annals of statistics, pages 351–357, 1984
1984
-
[28]
Santiago Marin, Bronwyn Loong, and Anton H Westveld. Bayesian nonparametric modeling of dynamic pollution clusters through an autoregressive logistic-beta stirling-gamma process.arXiv preprint arXiv:2601.04625, 2026
arXiv 2026
-
[29]
Comparing clusterings—an information based distance.Journal of multivariate analysis, 98(5):873–895, 2007
Marina Meil˘ a. Comparing clusterings—an information based distance.Journal of multivariate analysis, 98(5):873–895, 2007
2007
-
[30]
J. Newig. Das konzept der kulturerdteile, 2014. URLhttp://www.kulturerdteile.de/ kulturerdteile/. Last access on 24.03.2026
2014
-
[31]
Dependent modeling of temporal sequences of random partitions.Journal of Computational and Graphical Statistics, 31(2):614– 627, 2022
Garritt L Page, Fernando A Quintana, and David B Dahl. Dependent modeling of temporal sequences of random partitions.Journal of Computational and Graphical Statistics, 31(2):614– 627, 2022
2022
-
[32]
Women in business media: A critical discourse analysis of representations of women in forbes, fortune and bloomberg businessweek, 2015–2017
Kate Power, Lucy Rak, and Marianne Kim. Women in business media: A critical discourse analysis of representations of women in forbes, fortune and bloomberg businessweek, 2015–2017. Critical Approaches to Discourse Analysis Across Disciplines, 11(2):1–26, 2019
2015
-
[33]
Gender bias in the news: A scalable topic modelling and visualization framework.Frontiers in artificial intelligence, 4:664737, 2021
Prashanth Rao and Maite Taboada. Gender bias in the news: A scalable topic modelling and visualization framework.Frontiers in artificial intelligence, 4:664737, 2021
2021
-
[34]
i can’t just pull a woman out of a hat
Andreas A Riedl, Tobias Rohrbach, and Christina Krakovsky. “i can’t just pull a woman out of a hat”: A mixed-methods study on journalistic drivers of women’s representation in political news.Journalism & Mass Communication Quarterly, 101(3):679–702, 2024
2024
-
[35]
A stochastic approximation method.The annals of math- ematical statistics, pages 400–407, 1951
Herbert Robbins and Sutton Monro. A stochastic approximation method.The annals of math- ematical statistics, pages 400–407, 1951
1951
-
[36]
Optimal scaling for various metropolis-hastings algorithms.Statistical science, 16(4):351–367, 2001
Gareth O Roberts and Jeffrey S Rosenthal. Optimal scaling for various metropolis-hastings algorithms.Statistical science, 16(4):351–367, 2001
2001
-
[37]
A constructive definition of dirichlet priors.Statistica sinica, pages 639– 650, 1994
Jayaram Sethuraman. A constructive definition of dirichlet priors.Statistica sinica, pages 639– 650, 1994
1994
-
[38]
A paper ceiling: Explaining the persistent underrepresentation of women in printed news.American Sociological Review, 80(5):960–984, 2015
Eran Shor, Arnout Van De Rijt, Alex Miltsov, Vivek Kulkarni, and Steven Skiena. A paper ceiling: Explaining the persistent underrepresentation of women in printed news.American Sociological Review, 80(5):960–984, 2015
2015
-
[39]
A large-scale test of gender bias in the media.Sociological science, 6:526–550, 2019
Eran Shor, Arnout Van De Rijt, and Babak Fotouhi. A large-scale test of gender bias in the media.Sociological science, 6:526–550, 2019
2019
-
[40]
Do women in the newsroom make a difference? coverage sentiment toward women and men as a function of newsroom composition.Sex Roles, 81(1):44–58, 2019
Eran Shor, Arnout Van de Rijt, and Alex Miltsov. Do women in the newsroom make a difference? coverage sentiment toward women and men as a function of newsroom composition.Sex Roles, 81(1):44–58, 2019
2019
-
[41]
A better lemon squeezer? maximum-likelihood regression with beta-distributed dependent variables.Psychological methods, 11(1):54, 2006
Michael Smithson and Jay Verkuilen. A better lemon squeezer? maximum-likelihood regression with beta-distributed dependent variables.Psychological methods, 11(1):54, 2006
2006
-
[42]
Springer Nature, 2025
Timo Spinde.Automated Detection of Media Bias: From the Conceptualization of Media Bias to its Computational Classification. Springer Nature, 2025
2025
-
[43]
Reported speech and gender in the news: Who is quoted, how are they quoted, and why it matters.Discourse & Communication, 19(1):93–113, 2025
Maite Taboada. Reported speech and gender in the news: Who is quoted, how are they quoted, and why it matters.Discourse & Communication, 19(1):93–113, 2025
2025
-
[44]
Gender novelty and personalized news coverage in australia and canada.International Political Science Review, 42(2):164–178, 2021
Linda Trimble, Jennifer Curtin, Angelia Wagner, Meagan Auer, VKG Woodman, and Bethan Owens. Gender novelty and personalized news coverage in australia and canada.International Political Science Review, 42(2):164–178, 2021
2021
-
[45]
Gender differences in political media coverage: A meta-analysis.Journal of Communication, 70(1):114–143, 2020
Daphne Joanna Van der Pas and Loes Aaldering. Gender differences in political media coverage: A meta-analysis.Journal of Communication, 70(1):114–143, 2020
2020
-
[46]
Bayesian cluster analysis: Point estimation and credible balls (with discussion).Bayesian Analysis, 13(2):559–626, 2018
Sara Wade and Zoubin Ghahramani. Bayesian cluster analysis: Point estimation and credible balls (with discussion).Bayesian Analysis, 13(2):559–626, 2018. 14
2018
-
[47]
Furthermore, we use the appendix to describe the data pre-processing in section 8.2
Appendix In section 8.1 we present the figures mentioned in section 5. Furthermore, we use the appendix to describe the data pre-processing in section 8.2. In sec- tion 8.3, we present the parameter selection and validation of the final model used to obtain the results in section 5. In section 8.4 we describe the re- sults obtained for the country×topic×y...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.