SMC-ITA: Sequential Monte Carlo Inference-Time Alignment for Video-to-Audio Generation
Pith reviewed 2026-06-27 18:18 UTC · model grok-4.3
The pith
Sequential Monte Carlo resampling with lookahead rewards aligns video-to-audio generation more effectively than single-trajectory sampling or beam search.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
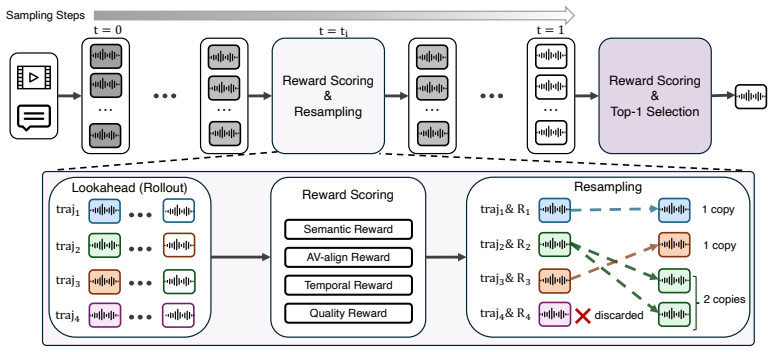
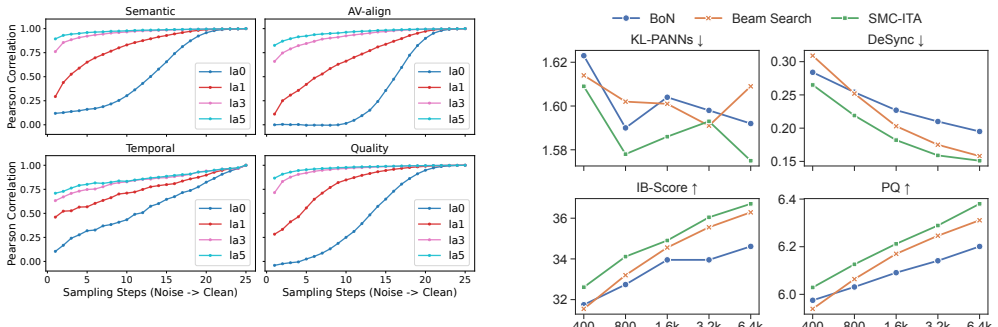
SMC-ITA combines lookahead-based reward estimation and sequential Monte Carlo resampling to reallocate computation adaptively using multi-dimensional cross-modal rewards. It improves over naive single-trajectory sampling with a 55.67 percent relative reduction in DeSync, a 20.23 percent improvement in IB-score, and a 15.44 percent improvement in Audio Quality. Under matched NFE budgets it also achieves the best overall trade-off among compared search baselines.
What carries the argument
Sequential Monte Carlo resampling guided by lookahead-estimated multi-dimensional cross-modal rewards
If this is right
- Computation budget is spent more on trajectories that satisfy audiovisual alignment, temporal synchronization, and perceptual quality simultaneously.
- Systematic resampling serves as a strong practical default for video-to-audio inference-time alignment.
- Lookahead estimation increases the reliability of intermediate reward signals used for resampling decisions.
- The method outperforms both Best-of-N and Beam Search under identical NFE constraints.
Where Pith is reading between the lines
- The same resampling logic could be tested on other flow-matching or diffusion-based multimodal generators where cross-modal rewards are available.
- If reward models improve, the relative gain from SMC-ITA would likely increase because better guidance amplifies the benefit of adaptive allocation.
- A natural extension is to vary the number of particles or the lookahead horizon as functions of remaining compute to further optimize the quality-compute curve.
Load-bearing premise
Multi-dimensional cross-modal rewards can be estimated reliably enough via lookahead to guide resampling without systematic bias or excessive sensitivity to reward weighting choices.
What would settle it
Running SMC-ITA and naive single-trajectory sampling on the same set of input videos with identical total function evaluations and observing no reduction in DeSync or no gains in IB-score and Audio Quality would falsify the central performance claim.
Figures

read the original abstract
Video-to-audio (V2A) generation must jointly satisfy audiovisual alignment, semantic consistency, temporal synchronization, and perceptual quality. While prior work has mainly focused on model architecture, multimodal conditioning, and training objectives, inference-time alignment for V2A remains underexplored. In this paper, we study inference-time alignment for flow-matching-based V2A generation and formulate it as a search problem. We propose Sequential Monte Carlo Inference-Time Alignment (SMC-ITA), which combines lookahead-based reward estimation and sequential Monte Carlo resampling to reallocate computation adaptively using multi-dimensional cross-modal rewards. SMC-ITA improves over naive single-trajectory sampling, achieving a 55.67% relative reduction in DeSync, a 20.23% improvement in IB-score, and a 15.44% improvement in Audio Quality. Under matched NFE budgets, it also achieves the best overall trade-off among the compared search baselines, outperforming Best-of-N and Beam Search. Ablation studies further show that lookahead improves the reliability of intermediate reward estimates and that systematic resampling is a strong practical default for V2A inference-time alignment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SMC-ITA, a Sequential Monte Carlo approach to inference-time alignment for flow-matching-based video-to-audio generation. It formulates alignment as a search problem and employs lookahead-based estimation of multi-dimensional cross-modal rewards (alignment, semantic consistency, synchronization, quality) to drive adaptive resampling of particles. The central empirical claims are a 55.67% relative reduction in DeSync, 20.23% improvement in IB-score, and 15.44% improvement in Audio Quality versus naive single-trajectory sampling, plus the best overall trade-off under matched NFE budgets versus Best-of-N and Beam Search, with ablations supporting the value of lookahead and systematic resampling.
Significance. If the reported gains and the reliability of the lookahead rewards are substantiated, the work would provide a concrete, adaptive inference-time method for jointly optimizing multiple cross-modal objectives in V2A generation without retraining. The explicit percentage improvements and ablation results on lookahead versus resampling constitute falsifiable, quantitative evidence that could inform search-based inference techniques in other multimodal generative settings.
major comments (3)
- [Abstract] Abstract: the headline claims of 55.67% DeSync reduction, 20.23% IB-score gain, and 15.44% Audio Quality gain are presented without absolute baseline values, standard deviations, dataset identity, or number of evaluation samples, which are required to determine whether the improvements are robust or sensitive to evaluation protocol.
- [Abstract] Abstract (ablation paragraph): the statement that 'lookahead improves the reliability of intermediate reward estimates' is load-bearing for the resampling mechanism, yet no quantitative correlation between partial-trajectory scalarized rewards and final metrics is supplied; without this, it remains possible that resampling reallocates particles on the basis of biased or poorly predictive signals.
- [Abstract] Abstract: the claim of 'best overall trade-off among the compared search baselines' under matched NFE budgets requires an explicit accounting of how NFE is tallied for SMC-ITA (including the cost of lookahead rollouts) versus Best-of-N and Beam Search; absent this accounting the matched-budget comparison cannot be verified.
minor comments (1)
- [Abstract] The abstract would be clearer if it named the specific flow-matching backbone and the exact scalarization weights used for the multi-dimensional reward.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment point-by-point below and will revise the manuscript to improve transparency and verifiability.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claims of 55.67% DeSync reduction, 20.23% IB-score gain, and 15.44% Audio Quality gain are presented without absolute baseline values, standard deviations, dataset identity, or number of evaluation samples, which are required to determine whether the improvements are robust or sensitive to evaluation protocol.
Authors: We agree that the abstract would be strengthened by including absolute baseline values, standard deviations, dataset identity, and sample counts. The experimental section of the manuscript contains these details in tables and text. We will revise the abstract to incorporate the key absolute values, dataset name, and evaluation sample size for better context. revision: yes
-
Referee: [Abstract] Abstract (ablation paragraph): the statement that 'lookahead improves the reliability of intermediate reward estimates' is load-bearing for the resampling mechanism, yet no quantitative correlation between partial-trajectory scalarized rewards and final metrics is supplied; without this, it remains possible that resampling reallocates particles on the basis of biased or poorly predictive signals.
Authors: The referee correctly notes that the abstract claim would be more convincing with explicit quantitative correlation data between intermediate rewards and final metrics. While the manuscript includes ablations on lookahead, we acknowledge the absence of this specific correlation analysis. We will add such an analysis (e.g., a table or plot) in the revised version to support the reliability of the lookahead estimates. revision: yes
-
Referee: [Abstract] Abstract: the claim of 'best overall trade-off among the compared search baselines' under matched NFE budgets requires an explicit accounting of how NFE is tallied for SMC-ITA (including the cost of lookahead rollouts) versus Best-of-N and Beam Search; absent this accounting the matched-budget comparison cannot be verified.
Authors: We agree that an explicit breakdown of NFE accounting, including the cost of lookahead rollouts in SMC-ITA, is required to verify the matched-budget comparisons. The manuscript discusses NFE in the experiments but lacks this level of detail. We will expand the relevant section and update the abstract to provide a clear accounting of NFE across all methods. revision: yes
Circularity Check
No circularity: empirical comparisons to external baselines
full rationale
The paper introduces SMC-ITA as an inference-time search method combining lookahead reward estimation with sequential Monte Carlo resampling for flow-matching V2A generation. All central claims consist of measured improvements (55.67% DeSync reduction, 20.23% IB-score gain, 15.44% Audio Quality gain) and trade-off rankings against independent external baselines (Best-of-N, Beam Search) under matched NFE budgets. No equations, performance metrics, or ablations reduce by construction to quantities defined inside the method itself, nor do they rest on self-citation chains or renamed known results. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Diff-Foley: Synchronized video-to-audio synthesis with latent diffusion models,
S. Luo, C. Yan, C. Hu, and H. Zhao, “Diff-Foley: Synchronized video-to-audio synthesis with latent diffusion models,” inThirty-seventh Conference on Neural Information Processing Systems, 2023
2023
-
[2]
FoleyCrafter: Bring silent videos to life with lifelike and synchronized sounds,
Y . Zhang, Y . Gu, Y . Zeng, Z. Xing, Y . Wang, Z. Wu, B. Liu, and K. Chen, “FoleyCrafter: Bring silent videos to life with lifelike and synchronized sounds,”International Journal of Computer Vision, vol. 134, no. 1, p. 46, 2026
2026
-
[3]
Tell what you hear from what you see - video to audio generation through text,
X. Liu, K. Su, and E. Shlizerman, “Tell what you hear from what you see - video to audio generation through text,” inThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[4]
MMAudio: Taming multimodal joint training for high- quality video-to-audio synthesis,
H. K. Cheng, M. Ishii, A. Hayakawa, T. Shibuya, A. Schwing, and Y . Mitsufuji, “MMAudio: Taming multimodal joint training for high- quality video-to-audio synthesis,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
2025
-
[5]
PrismAudio: Decomposed chain-of-thought and multi- dimensional rewards for video-to-audio generation,
H. Liu, K. Luo, W. Wang, Q. Chen, P. Sun, R. Huang, X. Li, J. Ye, and W. Xue, “PrismAudio: Decomposed chain-of-thought and multi- dimensional rewards for video-to-audio generation,” inThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[6]
Echoes over time: Unlocking length generalization in video-to-audio generation models,
C. Simon, M. Ishii, W.-Y . Wang, K. Saito, A. Hayakawa, D. Shim, Z. Zhong, S. Cui, S. Takahashi, T. Shibuya, and Y . Mitsufuji, “Echoes over time: Unlocking length generalization in video-to-audio generation models,”arXiv preprint arXiv:2602.20981, 2026
Pith/arXiv arXiv 2026
-
[7]
AC- Foley: Reference-audio-guided video-to-audio synthesis with acoustic transfer,
P. Fang, Y . He, Y . Xing, Q. Chen, S.-N. Lim, and H. Yang, “AC- Foley: Reference-audio-guided video-to-audio synthesis with acoustic transfer,” inThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[8]
Aligning text-to-image models using human feedback,
K. Lee, H. Liu, M. Ryu, O. Watkins, Y . Du, C. Boutilier, P. Abbeel, M. Ghavamzadeh, and S. S. Gu, “Aligning text-to-image models using human feedback,”arXiv preprint arXiv:2302.12192, 2023
Pith/arXiv arXiv 2023
-
[9]
Test-time alignment of diffusion mod- els without reward over-optimization,
S. Kim, M. Kim, and D. Park, “Test-time alignment of diffusion mod- els without reward over-optimization,” inThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[10]
Symbolic music generation with non-differentiable rule guided diffusion,
Y . Huang, A. Ghatare, Y . Liu, Z. Hu, Q. Zhang, C. S. Sastry, S. Gururani, S. Oore, and Y . Yue, “Symbolic music generation with non-differentiable rule guided diffusion,” inForty-first International Conference on Ma- chine Learning, 2024
2024
-
[11]
Inference-time text- to-video alignment with diffusion latent beam search,
Y . Oshima, M. Suzuki, Y . Matsuo, and H. Furuta, “Inference-time text- to-video alignment with diffusion latent beam search,” inThe Thirty- ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[12]
SCORE: Scaling au- dio generation using standardized composite rewards,
J. Jung, J. Kim, I. Shin, and J. S. Chung, “SCORE: Scaling au- dio generation using standardized composite rewards,”arXiv preprint arXiv:2509.19831, 2025
arXiv 2025
-
[13]
Sequential monte carlo samplers,
P. Del Moral, A. Doucet, and A. Jasra, “Sequential monte carlo samplers,”Journal of the Royal Statistical Society Series B: Statistical Methodology, vol. 68, no. 3, pp. 411–436, 2006
2006
-
[14]
Synchformer: Efficient synchronization from sparse cues,
V . Iashin, W. Xie, E. Rahtu, and A. Zisserman, “Synchformer: Efficient synchronization from sparse cues,” inIEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP, 2024
2024
-
[15]
Dynamic chunking for end-to- end hierarchical sequence modeling,
S. Hwang, B. Wang, and A. Gu, “Dynamic chunking for end-to- end hierarchical sequence modeling,” inThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[16]
Inference-time scaling for diffusion models beyond scaling denoising steps,
N. Ma, S. Tong, H. Jia, H. Hu, Y .-C. Su, M. Zhang, X. Yang, Y . Li, T. Jaakkola, X. Jiaet al., “Inference-time scaling for diffusion models beyond scaling denoising steps,”arXiv preprint arXiv:2501.09732, 2025
Pith/arXiv arXiv 2025
-
[17]
A general framework for inference-time scaling and steering of diffusion models,
R. Singhal, Z. Horvitz, R. Teehan, M. Ren, Z. Yu, K. McKeown, and R. Ranganath, “A general framework for inference-time scaling and steering of diffusion models,” inForty-second International Conference on Machine Learning, 2025
2025
-
[18]
Diffusion models beat GANs on image synthesis,
P. Dhariwal and A. Q. Nichol, “Diffusion models beat GANs on image synthesis,” inAdvances in Neural Information Processing Systems, 2021
2021
-
[19]
Dynamic search for inference-time alignment in diffusion models,
X. Li, M. Uehara, X. Su, G. Scalia, T. Biancalani, A. Regev, S. Levine, and S. Ji, “Dynamic search for inference-time alignment in diffusion models,”arXiv preprint arXiv:2503.02039, 2025
arXiv 2025
-
[20]
Scaling image and video generation via test-time evolutionary search,
H. He, J. Liang, X. Wang, P. Wan, D. Zhang, K. Gai, and L. Pan, “Scaling image and video generation via test-time evolutionary search,” arXiv preprint arXiv:2505.17618, 2025
arXiv 2025
-
[21]
Flow matching for generative modeling,
Y . Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow matching for generative modeling,” inThe Eleventh International Conference on Learning Representations, 2023
2023
-
[22]
Score-based generative modeling through stochastic differ- ential equations,
Y . Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole, “Score-based generative modeling through stochastic differ- ential equations,”arXiv preprint arXiv:2011.13456, 2020
Pith/arXiv arXiv 2011
-
[23]
HTS-AT: A hierarchical token-semantic audio transformer for sound classification and detection,
K. Chen, X. Du, B. Zhu, Z. Ma, T. Berg-Kirkpatrick, and S. Dubnov, “HTS-AT: A hierarchical token-semantic audio transformer for sound classification and detection,” inIEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP, 2022
2022
-
[24]
Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation,
Y . Wu, K. Chen, T. Zhang, Y . Hui, T. Berg-Kirkpatrick, and S. Dubnov, “Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation,” inIEEE International Confer- ence on Acoustics, Speech and Signal Processing, ICASSP, 2023
2023
-
[25]
ImageBind: One embedding space to bind them all,
R. Girdhar, A. El-Nouby, Z. Liu, M. Singh, K. V . Alwala, A. Joulin, and I. Misra, “ImageBind: One embedding space to bind them all,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023
2023
-
[26]
Meta Audiobox Aesthetics: Unified automatic quality assessment for speech, music, and sound,
A. Tjandra, Y .-C. Wu, B. Guo, J. Hoffman, B. Ellis, A. Vyas, B. Shi, S. Chen, M. Le, N. Zacharovet al., “Meta Audiobox Aesthetics: Unified automatic quality assessment for speech, music, and sound,”arXiv preprint arXiv:2502.05139, 2025
Pith/arXiv arXiv 2025
-
[27]
Improved particle filter for nonlinear problems,
J. Carpenter, P. Clifford, and P. Fearnhead, “Improved particle filter for nonlinear problems,”IEE Proceedings-Radar, Sonar and Navigation, vol. 146, no. 1, pp. 2–7, 1999
1999
-
[28]
Negative association, ordering and convergence of resampling methods,
M. Gerber, N. Chopin, and N. Whiteley, “Negative association, ordering and convergence of resampling methods,”The Annals of Statistics, vol. 47, no. 4, pp. 2236–2260, 2019
2019
-
[29]
VGGSound: A large-scale audio-visual dataset,
H. Chen, W. Xie, A. Vedaldi, and A. Zisserman, “VGGSound: A large-scale audio-visual dataset,” inIEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP, 2020
2020
-
[30]
AGA V-Rater: Adapting large multimodal model for AI-generated audio-visual quality assess- ment,
Y . Cao, X. Min, Y . Gao, W. Sun, and G. Zhai, “AGA V-Rater: Adapting large multimodal model for AI-generated audio-visual quality assess- ment,” inForty-second International Conference on Machine Learning, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.