CoughPhase-CLR: Designing an acoustics-informed foundation model for coughing sound classification
Pith reviewed 2026-06-26 12:54 UTC · model grok-4.3
The pith
CoughPhase-CLR pairs audio segments from the same cough phase for contrastive pre-training, outperforming random cropping on health classification tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
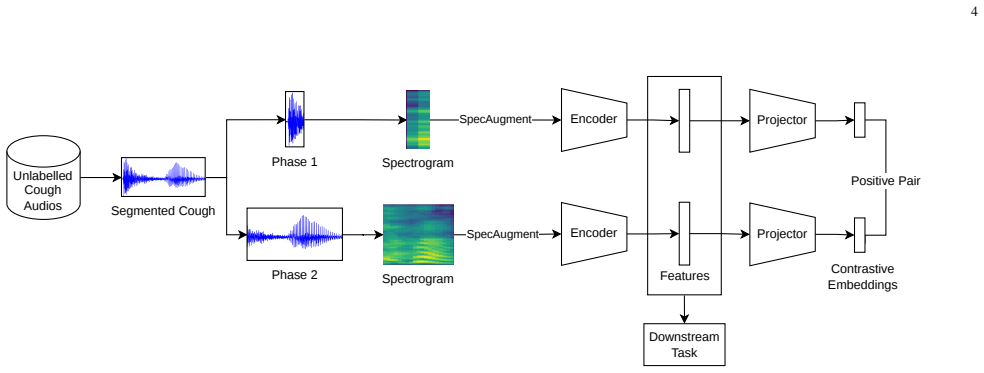
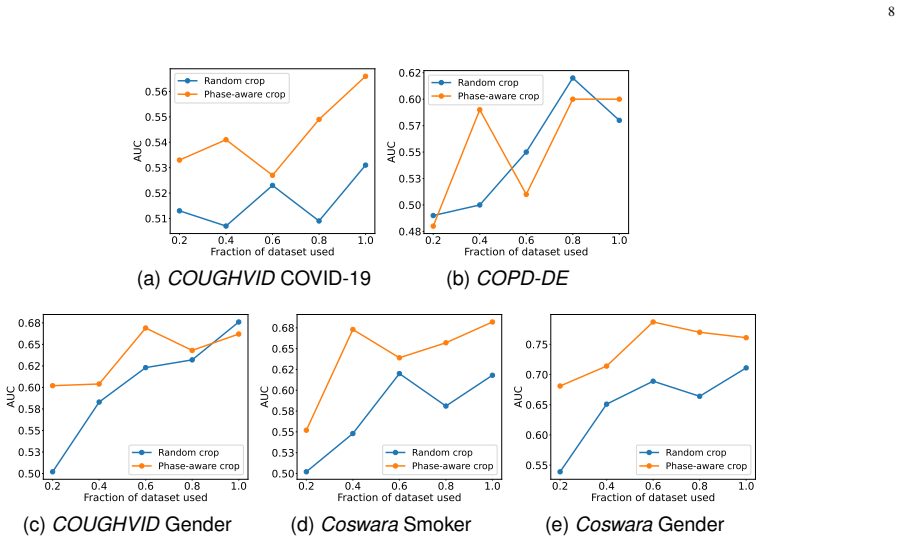
CoughPhase-CLR is a contrastive learning method that forms positive pairs by selecting segments from the same acoustic phase within a cough recording. Pre-training with this phase-informed pairing on cough audio produces representations that improve accuracy on multiple respiratory health classification tasks relative to models trained with random cropping or generic audio pre-training.
What carries the argument
CoughPhase-CLR contrastive framework, which constructs positive pairs based on the physiological phases of cough acoustics rather than random temporal crops.
If this is right
- Cough-specific phase pairing can raise classification accuracy for conditions such as COVID-19 when only cough recordings are available.
- The method allows more effective use of unlabeled cough data for training diagnostic models.
- COPD state classification stays difficult, with the best tested models limited to 57 percent UAR.
- Respiratory-sound pre-training offers an alternative path to speech-based analysis for certain cough-related tasks.
Where Pith is reading between the lines
- Similar phase-aware pairing could be tested on other repetitive physiological sounds such as breathing cycles to improve related models.
- The technique might reduce the volume of labeled data needed to reach usable accuracy in cough-based health screening.
- Combining phase-informed cough pre-training with large general audio models remains an open direction that could compound gains.
Load-bearing premise
Constructing positive pairs from segments of the same physiological cough phase produces more useful representations for downstream health classification than random cropping does.
What would settle it
An experiment in which random-cropping pre-training achieves equal or higher accuracy than CoughPhase-CLR across the reported downstream tasks on cough data would falsify the claimed advantage.
Figures
read the original abstract
In this work, we introduce CoughPhase-CLR, a self-supervised learning framework designed to leverage the physiological phases of a cough for robust representation learning. Unlike generic contrastive frameworks, CoughPhase-CLR constructs positive pairs based on these specific acoustic phases. We pre-trained our model on approximately 40 hours of public cough audio and evaluated it across five downstream tasks, including COVID-19 detection, chronic obstructive pulmonary disease (COPD) state classification, and smoker status prediction. Our results demonstrate that cough-specific pre-training consistently outperforms standard random-cropping techniques when training on cough recordings. Additionally, we benchmarked a diverse set of state-of-the-art models on COPD state classification, highlighting the difficulty of this task. The best-performing models, pretrained on either general audio or respiratory sounds, achieved a UAR of 57\%, failing to outperform the state-of-the-art performance of 84\% UAR achieved using speech analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CoughPhase-CLR, a self-supervised contrastive learning framework that constructs positive pairs from physiological phases of cough sounds rather than random crops. It pre-trains on ~40 hours of public cough audio and evaluates on five downstream tasks including COVID-19 detection, COPD state classification, and smoker status prediction. The central claim is that phase-informed pre-training consistently outperforms random-cropping baselines; the paper also benchmarks multiple SOTA audio models on COPD classification, reporting a best UAR of 57% that falls short of 84% UAR obtained via speech analysis.
Significance. If the reported gains hold under rigorous validation, the work shows that domain-specific acoustic structure (cough phases) can be leveraged to improve self-supervised representations for respiratory audio, offering a practical route toward specialized foundation models for health diagnostics. The COPD benchmarking usefully documents the difficulty of the task when restricted to cough recordings and may steer future efforts toward multi-modal or speech-augmented approaches. Public-data pre-training supports reproducibility.
minor comments (3)
- Abstract: the summary of results would be strengthened by inclusion of at least one or two key quantitative metrics (e.g., UAR deltas or absolute scores) with brief mention of statistical testing.
- Abstract / Results: the 84% UAR figure from speech analysis should be accompanied by an explicit citation or reference to the source method.
- Methods: provide clearer details on the exact construction of positive pairs from cough phases (e.g., how phase boundaries are detected or annotated) to allow replication.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. The report correctly captures the core contribution of CoughPhase-CLR and the benchmarking results. No major comments were provided in the report, so we have no points to rebut or revise on that basis. We will address any minor issues identified during the revision process.
Circularity Check
No significant circularity; purely empirical claims
full rationale
The manuscript introduces CoughPhase-CLR as a contrastive pre-training framework that constructs positive pairs from cough phases and reports empirical gains over random cropping on five downstream classification tasks. No equations, derivations, fitted parameters renamed as predictions, or uniqueness theorems appear in the provided text. All central claims rest on reported UAR metrics and benchmark comparisons rather than any self-referential reduction. Self-citations, if present, are not load-bearing for any mathematical step. The work is therefore self-contained as an empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
This is caused by the sudden release of pressure as the glottis opens [7, 9]
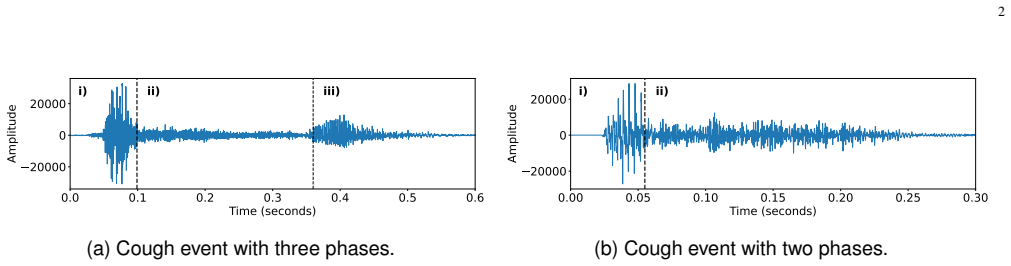
Theexplosive phaseis characterized by an explosive burst with a very sharp, high-amplitude increase in the sound energy envelope. This is caused by the sudden release of pressure as the glottis opens [7, 9]
-
[2]
The energy during this phase is typically lower than the initial burst and gradually decays as airflow decreases [10, 11]
Theintermediate phasefollows this initial burst and is characterized by a more sustained, high-frequency “noisy” sound generated by the sustained turbulent air- flow through the airways. The energy during this phase is typically lower than the initial burst and gradually decays as airflow decreases [10, 11]
-
[3]
the acoustic information in all phases of a cough is equally important for the purposes of TB classification
Thevoiced phaseis the final phase and is not present in all coughs. It includes a pitch frequency induced by the partial closure of the vocal cords, introducing a periodic, tonal quality to the signal [10]. Coughing sounds are also indicative of an underlying pathology. For instance, coughs from COPD patients typically have a longer duration, a later-occu...
2021
-
[4]
No pre-training eGeMAPS[20]51[50−52] CNN14(scratch) [33]54[52−57] EfficientNet-B0(scratch) [27]51[48−54]
-
[5]
Pre-trained on image data EfficientNet-B0(ImageNet) [27]53[50−56] VGG-16-BN[34]51[47−56]
-
[6]
Pre-trained on general audio data CNN14(AudioSet) [33]57[52−61] wav2vec2.0[35]50[48−52] HuBERT[36]50[48−51]
-
[7]
Pre-trained on respiratory audio HeAR[6]51[50−53] OPERA-CE[2]56[54−57] OPERA-CT[2]57[53−60] OPERA-GT[2]50[47−54]
-
[8]
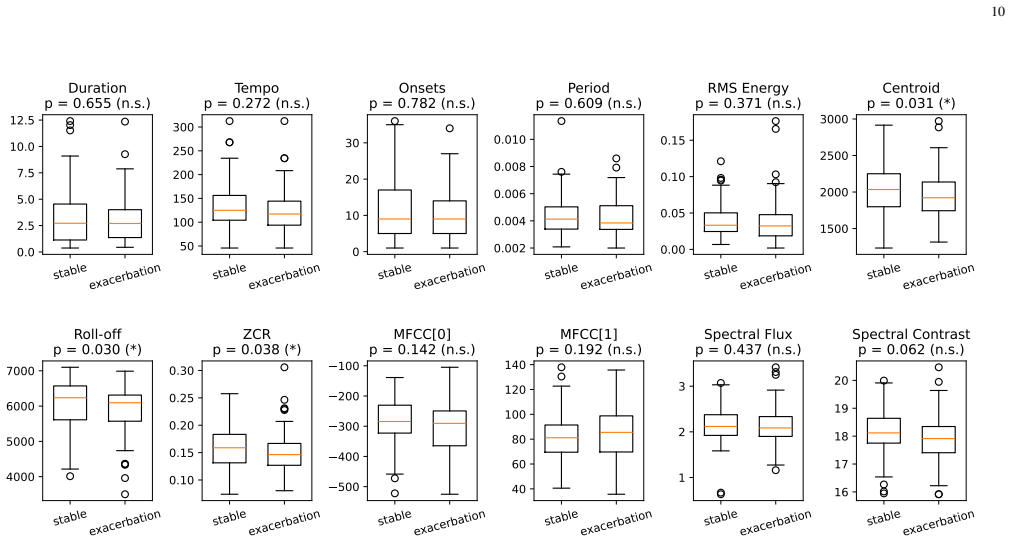
The distributions overlap substantially between the two states, with the majority of features showing no statistically significant difference atα= 0.05
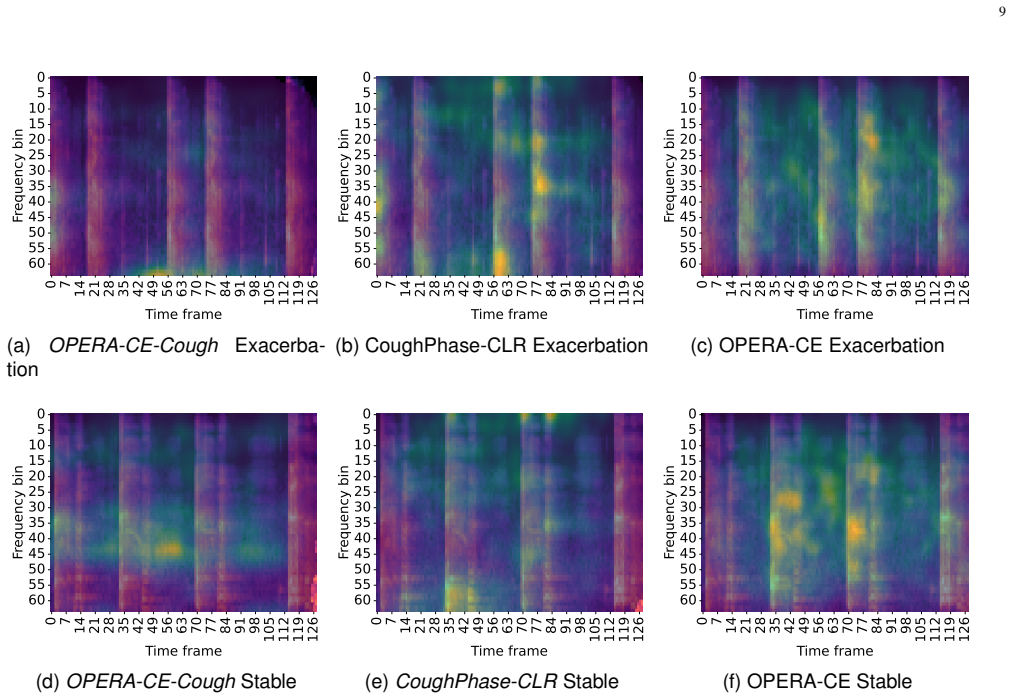
Pre-trained on cough audio CoughPhase-CLR(ours)53[51−55] these features for the stable and exacerbation states, annotated with p-values from two-sided Mann–Whitney U tests. The distributions overlap substantially between the two states, with the majority of features showing no statistically significant difference atα= 0.05. This suggests that handcrafted ...
2000
-
[9]
Hear4health: A blueprint for making computer audition a staple of modern healthcare,
A. Triantafyllopoulos, A. Kathan, A. Baird, L. Christ, A. Gebhard, M. Gerczuk, V . Karas, T. H¨ubner, X. Jing, S. Liu, et al., “Hear4health: A blueprint for making computer audition a staple of modern healthcare,” Frontiers in digital health, vol. 5, p. 1 196 079, 2023
2023
- [10]
-
[11]
M. Pahar, M. Klopper, B. Reeve, R. Warren, G. Theron, and T. Niesler, “Automatic cough classification for tuberculosis screening in a real- world environment,”Physiological Measurement, vol. 42, no. 10, p. 105 014, Oct. 2021,ISSN: 1361-6579.DOI: 10.1088/1361- 6579/ ac2fb8 [Online]. Available: http://dx.doi.org/10.1088/1361- 6579/ ac2fb8
-
[12]
Wavelet analysis of voluntary cough sound in patients with respiratory diseases,
J. Knocikova, J. Korpas, M. Vrabec, and M. Javorka, “Wavelet analysis of voluntary cough sound in patients with respiratory diseases,”J Physiol Pharmacol, vol. 59, no. Suppl 6, pp. 331–40, 2008
2008
-
[13]
Cough duration, energy and sound frequency in covid-19 patients: The spectral analysis results,
A. V . Budnevsky, D. Kosanovic, E. S. Ovsyannikov, O. N. Choporov, A. V . Pertsev, S. N. Feigelman, T. A. Chernik, A. V . Maksimov, G. G. Prozorova, S. A. Kozhevnikova, R. E. Tokmachev, A. V . Belyakova, V . R. Drobysheva, and S. N. Avdeev, “Cough duration, energy and sound frequency in covid-19 patients: The spectral analysis results,” BMC Pulmonary Medi...
-
[14]
S. Baur, Z. Nabulsi, W.-H. Weng, J. Garrison, L. Blankemeier, S. Fishman, C. Chen, S. Kakarmath, M. Maimbolwa, N. Sanjase, B. Shuma, Y . Matias, G. S. Corrado, S. Patel, S. Shetty, S. Prabhakara, M. Muyoyeta, and D. Ardila,Hear – health acoustic representations, 2024.DOI: 10.48550/ARXIV.2403.02522 [Online]. Available: https: //arxiv.org/abs/2403.02522
-
[15]
Cough detection using a non-contact microphone: A nocturnal cough study,
M. Eni, V . Mordoh, and Y . Zigel, “Cough detection using a non-contact microphone: A nocturnal cough study,”PLOS ONE, vol. 17, no. 1, F. Albu, Ed., e0262240, Jan. 2022,ISSN: 1932-6203.DOI: 10.1371/ journal.pone.0262240 [Online]. Available: http://dx.doi.org/10.1371/ journal.pone.0262240
2022
-
[16]
Acoustic parameters of voluntary cough in healthy non-smoking subjects,
P. M. Olia, P. Sestini, and M. Vagliasindi, “Acoustic parameters of voluntary cough in healthy non-smoking subjects,”Respirology, vol. 5, no. 3, pp. 271–275, Sep. 2000,ISSN: 1440-1843.DOI: 10.1046/j.1440- 1843.2000.00259.x [Online]. Available: http://dx.doi.org/10.1046/j. 1440-1843.2000.00259.x
-
[17]
How to quantify coughing: Correlations with quality of life in chronic cough,
A. Kelsall, S. Decalmer, D. Webster, N. Brown, K. McGuinness, A. Woodcock, and J. Smith, “How to quantify coughing: Correlations with quality of life in chronic cough,”European Respiratory Journal, vol. 32, no. 1, pp. 175–179, Feb. 2008,ISSN: 1399-3003.DOI: 10. 1183/09031936.00101307 [Online]. Available: http://dx.doi.org/10. 1183/09031936.00101307
arXiv 2008
-
[18]
A. Serrurier, C. Neuschaefer-Rube, and R. R ¨ohrig, “Past and trends in cough sound acquisition, automatic detection and automatic classifi- cation: A comparative review,”Sensors, vol. 22, no. 8, p. 2896, Apr. 2022,ISSN: 1424-8220.DOI: 10.3390/s22082896 [Online]. Available: http://dx.doi.org/10.3390/s22082896
-
[19]
The present and future of cough counting tools,
J. I. Hall, M. Lozano, L. Estrada-Petrocelli, S. Birring, and R. Turner, “The present and future of cough counting tools,”Journal of Thoracic Disease, vol. 12, no. 9, pp. 5207–5223, Sep. 2020,ISSN: 2077-6624. DOI: 10.21037/jtd-2020-icc-003 [Online]. Available: http://dx.doi.org/ 10.21037/jtd-2020-icc-003
-
[20]
Cough and its importance in copd,
J. Smith and A. Woodcock, “Cough and its importance in copd,” International Journal of COPD, vol. 1, no. 3, pp. 305–314, Aug. 2006, ISSN: 1176-9106.DOI: 10.2147/copd.2006.1.3.305 [Online]. Available: http://dx.doi.org/10.2147/copd.2006.1.3.305
-
[21]
On the importance of different cough phases for covid-19 detection,
Y . Zhu, M. H. Shaik, and T. H. Falk, “On the importance of different cough phases for covid-19 detection,” inICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, Jun. 2023, pp. 1–5.DOI: 10 . 1109 / icassp49357 . 2023 . 10095820 [Online]. Available: http : / / dx . doi . org / 10 . 1109 / ICASSP49357....
arXiv 2023
-
[22]
L. Orlandic, T. Teijeiro, and D. Atienza, “The coughvid crowdsourcing dataset, a corpus for the study of large-scale cough analysis algo- rithms,”Scientific Data, vol. 8, no. 1, Jun. 2021,ISSN: 2052-4463. DOI: 10.1038/s41597-021-00937-4 [Online]. Available: http://dx.doi. org/10.1038/s41597-021-00937-4
-
[23]
H. Coppock, G. Nicholson, I. Kiskin, V . Koutra, K. Baker, J. Budd, R. Payne, E. Karoune, D. Hurley, A. Titcomb, S. Egglestone, A. T. Ca˜nadas, L. Butler, R. Jersakova, J. Mellor, S. Patel, T. Thornley, P. Diggle, S. Richardson, J. Packham, B. W. Schuller, D. Pigoli, S. Gilmour, S. Roberts, and C. Holmes,Audio-based ai classifiers show no evidence of impr...
arXiv 2022
-
[24]
Coswara: A respiratory sounds and symptoms dataset for remote screening of sars-cov-2 infection,
D. Bhattacharya, N. K. Sharma, D. Dutta, S. R. Chetupalli, P. Mote, S. Ganapathy, C. Chandrakiran, S. Nori, K. K. Suhail, S. Gonuguntla, and M. Alagesan, “Coswara: A respiratory sounds and symptoms dataset for remote screening of sars-cov-2 infection,”Scientific Data, vol. 10, no. 1, Jun. 2023,ISSN: 2052-4463.DOI: 10.1038/s41597-023-02266-0 [Online]. Avai...
-
[25]
Covid-19 detection in cough, breath and speech using deep transfer learning and bottleneck features,
M. Pahar, M. Klopper, R. Warren, and T. Niesler, “Covid-19 detection in cough, breath and speech using deep transfer learning and bottleneck features,”Computers in Biology and Medicine, vol. 141, p. 105 153, Feb. 2022,ISSN: 0010-4825.DOI: 10.1016/j.compbiomed.2021.105153 [Online]. Available: http://dx.doi.org/10.1016/j.compbiomed.2021. 105153
-
[26]
Advancing cough classification: Swin transformer vs. 2d cnn with stft and augmentation techniques,
M. Ghourabi, F. Mourad-Chehade, and A. Chkeir, “Advancing cough classification: Swin transformer vs. 2d cnn with stft and augmentation techniques,”Electronics, vol. 13, no. 7, p. 1177, Mar. 2024,ISSN: 2079-9292.DOI: 10 . 3390 / electronics13071177 [Online]. Available: http://dx.doi.org/10.3390/electronics13071177
-
[27]
Exploring automatic diagnosis of covid-19 from crowdsourced respiratory sound data,
C. Brown, J. Chauhan, A. Grammenos, J. Han, A. Hasthanasombat, D. Spathis, T. Xia, P. Cicuta, and C. Mascolo, “Exploring automatic diagnosis of covid-19 from crowdsourced respiratory sound data,” 2020.DOI: 10.48550/ARXIV.2006.05919 [Online]. Available: https: //arxiv.org/abs/2006.05919
-
[28]
The geneva minimalistic acoustic parameter set (gemaps) for voice research and affective computing,
F. Eyben, K. R. Scherer, B. W. Schuller, J. Sundberg, E. Andre, C. Busso, L. Y . Devillers, J. Epps, P. Laukka, S. S. Narayanan, and K. P. Truong,The geneva minimalistic acoustic parameter set (gemaps) for voice research and affective computing, Apr. 2016.DOI: 10.1109/taffc. 2015.2457417 [Online]. Available: http://dx.doi.org/10.1109/TAFFC. 2015.2457417
-
[29]
CNN architectures for large-scale audio clas- sification,
S. Hershey, S. Chaudhuri, D. P. W. Ellis, J. F. Gemmeke, A. Jansen, R. C. Moore, M. Plakal, D. Platt, R. A. Saurous, B. Seybold, M. Slaney, R. J. Weiss, and K. Wilson, “Cnn architectures for large-scale audio classification,” in2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, Mar. 2017, pp. 131– 135.DOI: 10 . 1...
-
[30]
P.-Y . Huang, H. Xu, J. Li, A. Baevski, M. Auli, W. Galuba, F. Metze, and C. Feichtenhofer,Masked autoencoders that listen, 2022.DOI: 10.48550/ARXIV.2207.06405 [Online]. Available: https://arxiv.org/ abs/2207.06405
-
[31]
Y . Wu, K. Chen, T. Zhang, Y . Hui, M. Nezhurina, T. Berg-Kirkpatrick, and S. Dubnov,Large-scale contrastive language-audio pretraining with feature fusion and keyword-to-caption augmentation, 2022.DOI: 10.48550/ARXIV.2211.06687 [Online]. Available: https://arxiv.org/ abs/2211.06687
-
[32]
D. Niizumi, D. Takeuchi, M. Yasuda, B. T. Nguyen, Y . Ohishi, and N. Harada,Towards pre-training an effective respiratory audio foundation model, 2025.DOI: 10.48550/ARXIV.2505.15307 [Online]. Available: https://arxiv.org/abs/2505.15307
-
[33]
Q. Wang, Z. Bu, J. Mao, W. Zhu, J. Zhao, W. Du, G. Shi, M. Zhou, S. Chen, and J. Qu,Towards reliable respiratory disease diagnosis based on cough sounds and vision transformers, 2024.DOI: 10.48550/ ARXIV.2408.15667 [Online]. Available: https://arxiv.org/abs/2408. 15667
arXiv 2024
-
[34]
P. Foret, A. Kleiner, H. Mobahi, and B. Neyshabur,Sharpness-aware minimization for efficiently improving generalization, 2020.DOI: 10. 48550/ARXIV.2010.01412 [Online]. Available: https://arxiv.org/abs/ 2010.01412
Pith/arXiv arXiv 2020
-
[35]
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
M. Tan and Q. V . Le, “Efficientnet: Rethinking model scaling for convolutional neural networks,” 2019.DOI: 10.48550/ARXIV.1905. 11946 [Online]. Available: https://arxiv.org/abs/1905.11946
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1905 2019
-
[36]
T. Chen, S. Kornblith, M. Norouzi, and G. Hinton,A simple framework for contrastive learning of visual representations, 2020.DOI: 10.48550/ ARXIV.2002.05709 [Online]. Available: https://arxiv.org/abs/2002. 05709
Pith/arXiv arXiv 2020
-
[37]
Sustained vowels for pre- vs post-treatment copd classification,
A. Triantafyllopoulos, A. Batliner, W. Mayr, M. Fendler, F. Pokorny, M. Gerczuk, S. Amiriparian, T. Berghaus, and B. Schuller, “Sustained vowels for pre- vs post-treatment copd classification,” inInterspeech 2024, ISCA, 2024.DOI: 10 . 21437 / Interspeech . 2024 - 96 [Online]. Available: https://arxiv.org/abs/2406.06355
arXiv 2024
-
[38]
W. Mayr, A. Triantafyllopoulos, A. Batliner, B. Schuller, and T. Berghaus, “Assessing the clinical and functional status of copd patients using speech analysis during and after exacerbation,”International Journal of Chronic Obstructive Pulmonary Disease, vol. V olume 20, pp. 137–147, Jan. 2025,ISSN: 1178-2005.DOI: 10.2147/copd.s480842 [Online]. Available:...
-
[39]
K. R. Kendrick, S. C. Baxi, and R. M. Smith, “Usefulness of the modified 0-10 borg scale in assessing the degree of dyspnea in patients with copd and asthma,”Journal of Emergency Nursing, vol. 26, no. 3, pp. 216–222, Jun. 2000,ISSN: 0099-1767.DOI: 10 . 1016 / s0099 - 1767(00)90093-x [Online]. Available: http://dx.doi.org/10.1016/s0099- 1767(00)90093-x
-
[40]
The copd assessment test: A systematic review,
N. Gupta, L. M. Pinto, A. Morogan, and J. Bourbeau, “The copd assessment test: A systematic review,”European Respiratory Journal, vol. 44, no. 4, pp. 873–884, Jul. 2014,ISSN: 1399-3003.DOI: 10.1183/ 09031936.00025214 [Online]. Available: http://dx.doi.org/10.1183/ 09031936.00025214
arXiv 2014
-
[41]
Q. Kong, Y . Cao, T. Iqbal, Y . Wang, W. Wang, and M. D. Plumbley, Panns: Large-scale pretrained audio neural networks for audio pattern recognition, 2019.DOI: 10 . 48550 / ARXIV. 1912 . 10211 [Online]. Available: https://arxiv.org/abs/1912.10211
arXiv 2019
-
[42]
Very deep convolutional networks for large-scale image recognition,
K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,”arXiv preprint arXiv:1409.1556, 2014
Pith/arXiv arXiv 2014
-
[43]
A. Baevski, H. Zhou, A. Mohamed, and M. Auli,Wav2vec 2.0: A framework for self-supervised learning of speech representations, 2020.DOI: 10.48550/ARXIV.2006.11477 [Online]. Available: https: //arxiv.org/abs/2006.11477
-
[44]
W.-N. Hsu, B. Bolte, Y .-H. H. Tsai, K. Lakhotia, R. Salakhutdinov, and A. Mohamed, “Hubert: Self-supervised speech representation learning by masked prediction of hidden units,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 29, pp. 3451–3460, 2021,ISSN: 2329-9304.DOI: 10.1109/taslp.2021.3122291 [Online]. Available: http://dx.doi.or...
-
[45]
Specaugment: A simple data augmentation method for automatic speech recognition,
D. S. Park, W. Chan, Y . Zhang, C.-C. Chiu, B. Zoph, E. D. Cubuk, and Q. V . Le, “Specaugment: A simple data augmentation method for automatic speech recognition,” 2019.DOI: 10.48550/ARXIV.1904. 08779 [Online]. Available: https://arxiv.org/abs/1904.08779
-
[46]
A. Triantafyllopoulos, M. Fendler, A. Batliner, M. Gerczuk, S. Amiri- parian, T. Berghaus, and B. W. Schuller, “Distinguishing between pre- and post-treatment in the speech of patients with chronic obstructive pulmonary disease,” inInterspeech 2022, ISCA, Sep. 2022, pp. 3623– 3627.DOI: 10 . 21437 / interspeech . 2022 - 10333 [Online]. Available: http://dx...
-
[47]
Y . Tian, C. Sun, B. Poole, D. Krishnan, C. Schmid, and P. Isola,What makes for good views for contrastive learning?2020.DOI: 10.48550/ ARXIV.2005.10243 [Online]. Available: https://arxiv.org/abs/2005. 10243
arXiv 2020
-
[48]
Charting 15 years of progress in deep learning for speech emotion recognition: A replication study,
A. Triantafyllopoulos, A. Batliner, and B. W. Schuller, “Charting 15 years of progress in deep learning for speech emotion recognition: A replication study,”IEEE Transactions on Affective Computing, 2026
2026
-
[49]
Detecting copd through speech analysis: A dataset of danish speech and machine learning approach,
C. Sankey-Olsen, R. H. Olesen, T. O. Eberhard, A. Triantafyllopoulos, B. Schuller, and I. Aslan, “Detecting copd through speech analysis: A dataset of danish speech and machine learning approach,”arXiv preprint arXiv:2508.02354, 2025
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.