Trustworthy Runtime Verification via Bisimulation (Extended Experience Report)
Pith reviewed 2026-07-03 01:06 UTC · model grok-4.3
The pith
CopilotVerifier generates bisimulation proofs that equate a Copilot monitor with its compiled form on outputs and crashes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
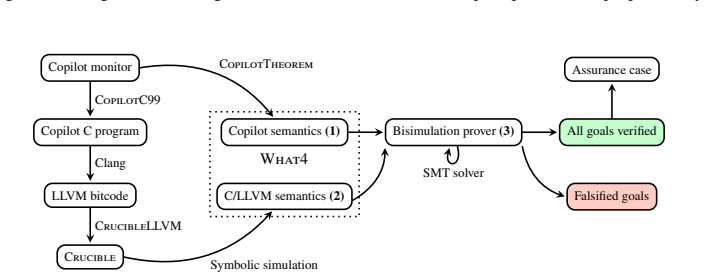
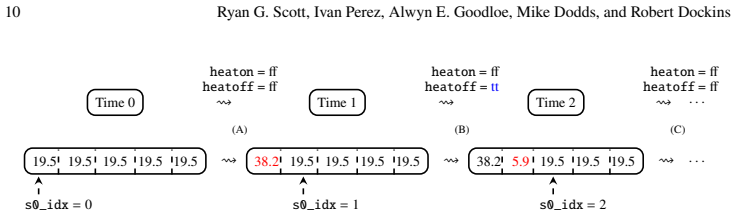
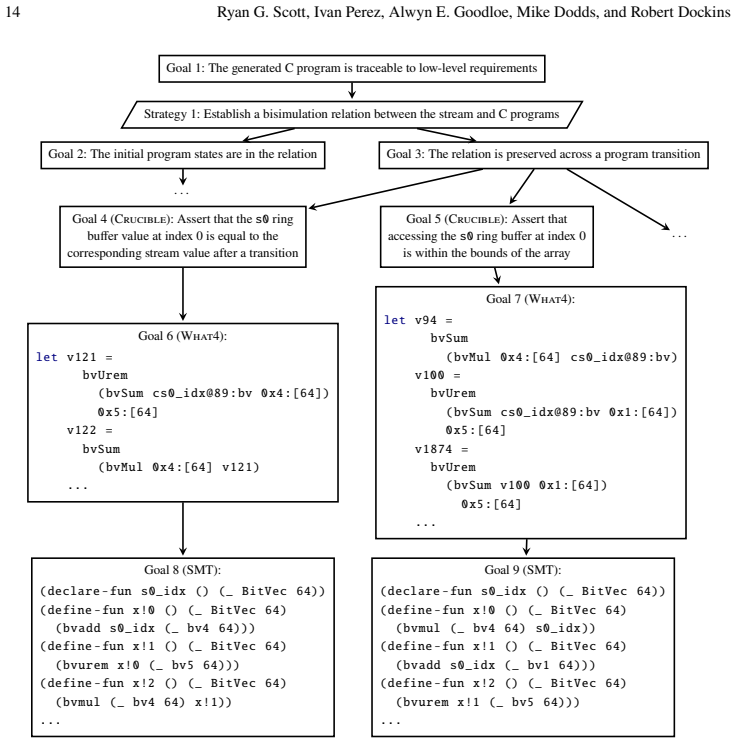
CopilotVerifier runs alongside the Copilot compiler and emits a bisimulation proof establishing that a given monitor and its compiled form produce equivalent outputs on equivalent inputs and either crash in identical circumstances or cannot crash. The bisimulation is expressed as a collection of verification conditions that are checked by Crucible's symbolic executor for LLVM together with the What4 solver interface.
What carries the argument
Bisimulation relation between Copilot semantics and compiled LLVM code, decomposed into verification conditions solved by symbolic execution.
If this is right
- Every compiled monitor is accompanied by a machine-checked argument of behavioral equivalence.
- Crash freedom or crash equivalence is established automatically for each monitor.
- Assurance cost remains moderate because the proof reuses existing symbolic execution and SMT infrastructure.
- The generated proofs supply the formal content needed for human-auditable assurance arguments.
Where Pith is reading between the lines
- The same bisimulation technique could be applied to other high-level specification languages that compile to C for embedded use.
- If the approach scales to larger monitors, it reduces the portion of the runtime verification toolchain that must be trusted without formal evidence.
- Auditors could eventually treat the generated bisimulation proof as the primary evidence rather than reviewing source or binary directly.
Load-bearing premise
The bisimulation relation and Crucible's symbolic execution model correctly capture the operational semantics of both the high-level Copilot language and the generated code.
What would settle it
A concrete input sequence on which the high-level monitor and the compiled version produce different outputs or differ in whether they crash.
Figures



read the original abstract
When runtime verification is used to monitor safety-critical systems, it is essential that monitoring code behaves correctly. The Copilot runtime verification framework pursues this goal by automatically generating C monitor programs from a high-level DSL embedded in Haskell. In safety-critical domains, every piece of deployed code must be accompanied by an assurance argument that is convincing to human auditors. However, it is difficult for auditors to determine with confidence that a compiled monitor cannot crash and implements the behavior required by the Copilot semantics. In this paper we describe CopilotVerifier, which runs alongside the Copilot compiler, generating a proof of correctness for the compiled output. The proof establishes that a given Copilot monitor and its compiled form produce equivalent outputs on equivalent inputs, and that they either crash in identical circumstances or cannot crash. The proof takes the form of a bisimulation broken down into a set of verification conditions. We leverage two pieces of SMT-backed technology: the Crucible symbolic execution library for LLVM and the What4 solver interface library. Our results demonstrate that dramatically increased compiler assurance can be achieved at moderate cost by building on existing tools. This paves the way to our ultimate goal of generating formal assurance arguments that are convincing to human auditors.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents CopilotVerifier, which augments the Copilot compiler to emit a bisimulation proof (as a set of VCs) establishing that a Copilot monitor and its compiled LLVM/C form produce equivalent outputs on equivalent inputs and exhibit identical crash behavior (or are crash-free). The proof is generated by encoding the high-level Copilot semantics into a bisimulation relation and using Crucible's symbolic execution of the LLVM binary together with the What4 SMT interface.
Significance. If the central claim holds, the work demonstrates a practical route to stronger machine-checked assurance for runtime monitors in safety-critical systems by composing existing, independently developed symbolic-execution and SMT tools rather than building a custom verifier from scratch. The experience-report character and reported moderate cost are useful data points for the community.
major comments (2)
- [§3 (Bisimulation construction and VC generation)] The soundness of the generated bisimulation rests on the unstated assumption that Crucible's LLVM model and the encoding of Copilot semantics into the bisimulation relation faithfully capture the respective operational semantics (including memory model, undefined behavior, and calling conventions). No separate soundness argument, cross-validation against a reference semantics, or validation suite is supplied; this is load-bearing for both the output-equivalence and crash-equivalence claims.
- [§3.2 (Crash equivalence)] The crash-equivalence claim requires that the symbolic execution in Crucible correctly identifies all possible crash sites in the compiled code. Because Crucible is treated as a black box, any mismatch between its model and real LLVM behavior would invalidate the claim that the monitor and compiled form 'crash in identical circumstances or cannot crash.'
minor comments (2)
- [Abstract] The abstract states the ultimate goal is 'formal assurance arguments that are convincing to human auditors,' yet the paper does not discuss how the generated VCs or bisimulation relation would be presented to auditors.
- [§3] Notation for the bisimulation relation and the form of the generated VCs could be made more explicit (e.g., by showing a small example VC in the main text rather than only in an appendix).
Simulated Author's Rebuttal
We thank the referee for the careful review and the focus on soundness assumptions. We respond to each major comment below, indicating where the manuscript will be revised to improve clarity.
read point-by-point responses
-
Referee: [§3 (Bisimulation construction and VC generation)] The soundness of the generated bisimulation rests on the unstated assumption that Crucible's LLVM model and the encoding of Copilot semantics into the bisimulation relation faithfully capture the respective operational semantics (including memory model, undefined behavior, and calling conventions). No separate soundness argument, cross-validation against a reference semantics, or validation suite is supplied; this is load-bearing for both the output-equivalence and crash-equivalence claims.
Authors: We agree that the equivalence claims depend on the fidelity of Crucible's LLVM model and our bisimulation encoding. As an experience report on tool composition rather than a foundational verification effort, the manuscript does not supply an independent soundness argument. In the revision we will add an explicit subsection in §3 stating these assumptions, their scope, and references to Crucible's existing validation and usage in other projects. This will make the dependencies transparent without changing the core contribution. revision: yes
-
Referee: [§3.2 (Crash equivalence)] The crash-equivalence claim requires that the symbolic execution in Crucible correctly identifies all possible crash sites in the compiled code. Because Crucible is treated as a black box, any mismatch between its model and real LLVM behavior would invalidate the claim that the monitor and compiled form 'crash in identical circumstances or cannot crash.'
Authors: This observation is correct and closely related to the prior comment. The revised manuscript will expand §3.2 to state explicitly that crash equivalence is conditional on Crucible correctly modeling all LLVM crash behaviors. We will note the black-box reliance as a standard limitation when composing existing symbolic-execution tools and will not add a new validation suite, as that would exceed the scope of this experience report. revision: yes
Circularity Check
No significant circularity; proof relies on external Crucible/What4 tools
full rationale
The paper generates a bisimulation proof using external SMT-backed libraries Crucible (for LLVM symbolic execution) and What4. No self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations appear in the derivation. The central claim (equivalence and crash equivalence via VCs) is not reduced to its own inputs by construction; it depends on the (unverified here) soundness of the external tools matching Copilot/LLVM semantics, which is an external assumption rather than internal circularity. This is the normal case of a self-contained argument against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The Core Flight System (cFS)
2026. The Core Flight System (cFS). https://github.com/nasa/cfs
2026
-
[2]
Lennart Augustsson and Kent Petersson. 1994. Silly Type Families* DRAFT. (1994)
1994
-
[3]
Haniel Barbosa, Clark W. Barrett, Martin Brain, Gereon Kremer, Hanna Lachnitt, Makai Mann, Abdalrhman Mohamed, Mudathir Mohamed, Aina Niemetz, Andres N ¨otzli, Alex Ozdemir, Mathias Preiner, Andrew Reynolds, Ying Sheng, Cesare Tinelli, and Yoni Zohar. 2022. cvc5: A Versatile and Industrial-Strength SMT Solver. InTools and Algorithms for the Construction a...
-
[5]
Twan Basten. 1996. Branching bisimilarity is an equivalence indeed!Inform. Process. Lett.58, 3 (1996), 141–147
1996
-
[6]
Sylvie Boldo and Guillaume Melquiond. 2011. Flocq: A unified library for proving floating-point algorithms in Coq. In2011 IEEE 20th Symposium on Computer Arithmetic. IEEE, 243–252. https://doi.org/10.1109/ ARITH.2011.40
2011
-
[7]
Brett Boston, Samuel Breese, Joey Dodds, Mike Dodds, Brian Huffman, Adam Petcher, and Andrei Stefanescu
-
[8]
Verified cryptographic code for everybody. InCAV 2021. https://doi.org/10.1007/978-3-030-81685-8 31
-
[9]
Timothy Bourke, L´elio Brun, Pierre- ´Evariste Dagand, Xavier Leroy, Marc Pouzet, and Lionel Rieg. 2017. A Formally Verified Compiler for Lustre. InProceedings of the 38th ACM SIGPLAN Conference on Programming Language Design and Implementation(Barcelona, Spain)(PLDI 2017). Association for Computing Machinery, 586–601. https://doi.org/10.1145/3140587.3062358
-
[10]
Timothy Bourke, L´elio Brun, and Marc Pouzet. 2019. Mechanized Semantics and Verified Compilation for a Dataflow Synchronous Language with Reset.Proc. ACM Program. Lang.4, POPL, Article 44 (dec 2019), 29 pages. https://doi.org/10.1145/3371112
-
[11]
Timothy Bourke, Paul Jeanmaire, Basile Pesin, and Marc Pouzet. 2021. Verified Lustre Normalization with Node Subsampling.ACM Trans. Embed. Comput. Syst.20, 5s, Article 98 (sep 2021), 25 pages. https://doi.org/10.1145/3477041
-
[12]
California Institute of Technology. 2026. F Prime. https://github.com/nasa/fprime
2026
-
[13]
P. Caspi, D. Pialiud, N. Halbwachs, and J. Plaice. 1987. LUSTRE: a Declarative Language for Programming Synchronous Systems. In14th Symposium on Principles of Programming Languages. 178–188. https: //doi.org/10.1145/41625.41641
-
[14]
Manuel M. T. Chakravarty, Gabriele Keller, and Simon Peyton Jones. 2005. Associated type synonyms. In Proceedings of the Tenth ACM SIGPLAN International Conference on Functional Programming(Tallinn, Estonia)(ICFP ’05). Association for Computing Machinery, New York, NY, USA, 241–253. https: //doi.org/10.1145/1086365.1086397
-
[15]
Diatchki, Robert Dockins, Joe Hendrix, and Tristan Ravitch
David Thrane Christiansen, Iavor S. Diatchki, Robert Dockins, Joe Hendrix, and Tristan Ravitch. 2019. Dependently Typed Haskell in Industry (Experience Report).Proc. ACM Program. Lang.3, ICFP, Article 100 (July 2019), 16 pages. https://doi.org/10.1145/3341704
-
[16]
Andrey Chudnov, Nathan Collins, Byron Cook, Joey Dodds, Brian Huffman, Colm MacC´arthaigh, Stephen Magill, Eric Mertens, Eric Mullen, Serdar Tasiran, Aaron Tomb, and Eddy Westbrook. 2018. Continuous Formal Verification of Amazon s2n. InComputer Aided Verification, Hana Chockler and Georg Weissenbacher (Eds.). Springer International Publishing, Cham, 430–4...
-
[17]
Koen Claessen and John Hughes. 2000. QuickCheck: a lightweight tool for random testing of Haskell programs. InProceedings of the fifth ACM SIGPLAN international conference on Functional programming. 268–279. https://doi.org/10.1145/351240.351266
-
[18]
Edmund Clarke, Daniel Kroening, and Flavio Lerda. 2004. A tool for checking ANSI-C programs. In International Conference on Tools and Algorithms for the Construction and Analysis of Systems. Springer, 168–176. https://doi.org/10.1007/978-3-540-24730-2 15 Trustworthy Runtime Verification via Bisimulation (Extended Experience Report) 29
-
[19]
Darren Cofer. 2021. Unintended Behavior in Learning-Enabled Systems: Detecting the Unknown Unknowns. In 2021 IEEE/AIAA 40th Digital Avionics Systems Conference (DASC). 1–7. https://doi.org/10.1109/DASC52595. 2021.9594406
-
[20]
Darren Cofer, Isaac Amundson, Ramachandra Sattigeri, Arjun Passiand Christopher Boggs, Eric Smith, Limei Gilham, Taejoon Byun, and Sanjai Rayadurgam. 2020. Run-Time Assurance for Learning-Enabled Systems. In NASA Formal Methods: 12th International Symposium, NFM 2020, Moffett Field, CA, USA, May 11–15, 2020, Proceedings. Springer-Verlag, Berlin, Heidelber...
-
[21]
Darren Cofer and Steven Miller. 2014. DO-333 Certification Case Studies. InNASA Formal Methods, Julia M. Badger and Kristin Yvonne Rozier (Eds.). Springer International Publishing, Cham, 1–15. https: //doi.org/10.1007/978-3-319-06200-6 1
-
[22]
2014.Autonomy Research for Civil Aviation: Toward a New Era of Flight
National Research Council. 2014.Autonomy Research for Civil Aviation: Toward a New Era of Flight. The National Academies Press
2014
-
[23]
Pascal Cuoq, Florent Kirchner, Nikolai Kosmatov, Virgile Prevosto, Julien Signoles, and Boris Yakobowski
-
[24]
InInternational conference on software engineering and formal methods
Frama-c. InInternational conference on software engineering and formal methods. Springer, 233–247. https://doi.org/10.1007/978-3-642-33826-7 16
-
[25]
B. D’ Angelo, S. Sankaranarayanan, C. S´anchez, W. Robinson, Zohar Manna, B. Finkbeiner, H. Spima, and S. Mehrotra. 2005. LOLA: Runtime Monitoring of Synchronous Systems. In12th International Symposium on Temporal Representation and Reasoning. IEEE, 166–174. https://doi.org/10.1109/TIME.2005.26
-
[26]
Leonardo De Moura and Nikolaj Bjørner. 2008. Z3: An Efficient SMT Solver. InProceedings of the Theory and Practice of Software, 14th International Conference on Tools and Algorithms for the Construction and Analysis of Systems(Budapest, Hungary)(TACAS’08/ETAPS’08). Springer-Verlag, Berlin, Heidelberg, 337–340
2008
-
[27]
Robert Dockins, Adam Foltzer, Joe Hendrix, Brian Huffman, Dylan McNamee, and Aaron Tomb. 2016. Constructing Semantic Models of Programs with the Software Analysis Workbench. InVerified Software. Theories, Tools, and Experiments, Sandrine Blazy and Marsha Chechik (Eds.). Springer International Publishing, Cham, 56–72. https://doi.org/10.1007/978-3-319-48869-1 5
-
[28]
Bruno Dutertre. 2014. Yices 2.2. InComputer Aided Verification, Armin Biere and Roderick Bloem (Eds.). Springer International Publishing, Cham, 737–744
2014
-
[29]
Yli`es Falcone, Klaus Havelund, and Giles Reger. 2013. A Tutorial on Runtime Verification. InEngineering Dependable Software Systems, Manfred Broy, Doron A. Peled, and Georg Kalus (Eds.). NATO Science for Peace and Security Series, D: Information and Communication Security, Vol. 34. IOS Press, 141–175. https://doi.org/10.3233/978-1-61499-207-3-141
-
[30]
Federal Aviation Administration. 2009. Sense and Avoid (SAA) for Unmanned Aircraft Systems (UAS)
2009
-
[31]
George Fink and Matt Bishop. 1997. Property-Based Testing: A New Approach to Testing for Assurance. SIGSOFT Softw. Eng. Notes22, 4 (jul 1997), 74–80. https://doi.org/10.1145/263244.263267
-
[32]
GitHub. 2025. Copilot Verifier. https://github.com/Copilot-Language/copilot/tree/master/copilot-verifier
2025
-
[33]
GitHub, Issue on Copilot. 2021a. Generated C code accesses stream buffer out of bounds. https: //github.com/Copilot-Language/copilot/issues/238
-
[34]
GitHub, Issue on Copilot. 2021b. C translation doesn’t correctly select operations based on types. https: //github.com/Copilot-Language/copilot/issues/263
-
[35]
GitHub, Issue on Copilot. 2021c. Basic example involving structs generates invalid C code. https: //github.com/Copilot-Language/copilot/issues/275
-
[36]
GitHub, Issue on Copilot. 2021d. Delaying streams of arrays or structs produces C code that fails to compile with Clang. https://github.com/Copilot-Language/copilot/issues/276
-
[37]
GitHub, Issue on Copilot. 2021e. Copilot-c99: C99 and interpretation of signum behave inconsistently for 0 and NaN. https://github.com/Copilot-Language/copilot/issues/278
-
[38]
GitHub, Issue on Copilot. 2022a. Copilot-c99: appending values to a stream of arrays produces incorrect C99 code. https://github.com/Copilot-Language/copilot/issues/314
-
[39]
GitHub, Issue on Copilot. 2022b. Copilot-c99: array has incomplete element type error when declaring stream with array of structs. https://github.com/Copilot-Language/copilot/issues/373
-
[40]
GitHub, Issue on Copilot. 2022c. Copilot-c99: Streams of arrays result in C code with undefined behavior. https://github.com/Copilot-Language/copilot/issues/386
-
[41]
Alwyn Goodloe. 2016. Challenges in high-assurance runtime verification. InInternational Symposium on Leveraging Applications of Formal Methods. Springer, 446–460. https://doi.org/10.1007/978-3-319-47166- 2 31 30 Ryan G. Scott, Ivan Perez, Alwyn E. Goodloe, Mike Dodds, and Robert Dockins
-
[42]
2010.Monitoring Distributed Real-Time Systems: A Survey and Future Directions
Alwyn Goodloe and Lee Pike. 2010.Monitoring Distributed Real-Time Systems: A Survey and Future Directions. Technical Report NASA/CR-2010-216724. NASA Langley Research Center
2010
-
[43]
Hackage. 2025. Copilot-verifier: System for verifying the correctness of generated Copilot programs. https://hackage.haskell.org/package/copilot-verifier
2025
-
[44]
Klaus Havelund. 2008. Runtime verification of C programs. InTesting of Software and Communicating Systems. Springer, 7–22. https://doi.org/10.1007/978-3-540-68524-1 3
-
[45]
Joe Hendrix, Ben Selfridge, and Robert Dockins. 2020. What4: New Library to Help Developers Build Verification and Program Analysis Tools. https://galois.com/blog/2020/07/what4-new-library-to-help-devs- build-verification-program-tools/
2020
-
[46]
Tim Kelly and Rob Weaver. 2004. The goal structuring notation–a safety argument notation. InProceedings of the dependable systems and networks 2004 workshop on assurance cases, Vol. 6. Citeseer
2004
-
[47]
Ramana Kumar, Magnus O Myreen, Michael Norrish, and Scott Owens. 2014. CakeML: a verified implemen- tation of ML.ACM SIGPLAN Notices49, 1 (2014), 179–191. https://doi.org/10.1145/2578855.2535841
-
[48]
Jonathan Laurent, Alwyn Goodloe, and Lee Pike. 2015. Assuring the guardians. InRuntime Verification. Springer, 87–101. https://doi.org/10.1007/978-3-319-23820-3 6
-
[49]
Xavier Leroy. 2009. Formal verification of a realistic compiler.Commun. ACM52, 7 (2009), 107–115. https://doi.org/10.1145/1538788.1538814
-
[50]
Nuno P Lopes, Juneyoung Lee, Chung-Kil Hur, Zhengyang Liu, and John Regehr. 2021. Alive2: bounded translation validation for LLVM. InProceedings of the 42nd ACM SIGPLAN International Conference on Programming Language Design and Implementation. 65–79. https://doi.org/10.1145/3453483.3454030
-
[51]
2021.Adding Runtime Verification to the Proteus Language
Brian McClelland. 2021.Adding Runtime Verification to the Proteus Language. Ph. D. Dissertation. California State University, Northridge
2021
-
[52]
Brian McClelland, Daniel Tellier, Meyer Millman, Kate Beatrix Go, Alice Balayan, Michael J Munje, Kyle Dewey, Nhut Ho, Klaus Havelund, and Michel Ingham. 2021. Towards a systems programming language designed for hierarchical state machines. In2021 IEEE 8th International Conference on Space Mission Challenges for Information Technology (SMC-IT). IEEE, 23–3...
-
[53]
2020.AFE 87 - Machine Learning
AFE87 Project Members. 2020.AFE 87 - Machine Learning. Technical Report. Aerospace Vehicle Systems Institute
2020
-
[54]
Robin Milner. 1990. Operational and algebraic semantics of concurrent processes. InFormal Models and Semantics. Elsevier, 1201–1242
1990
-
[55]
NASA. 2021. Ogma. https://github.com/nasa/ogma Accessed 2026-09-29
2021
-
[56]
NASA. 2022. NPR 7150.2 NASA Software Engineering Requirements (Appendix D. Software Classifications). https://nodis3.gsfc.nasa.gov/displayDir.cfm?Internal ID=N PR 7150 002D &page name=AppendixD
2022
-
[57]
George C. Necula. 1997. Proof-carrying code. InProceedings of the 24th ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages(Paris, France)(POPL ’97). Association for Computing Machinery, New York, NY, USA, 106–119. https://doi.org/10.1145/263699.263712
- [58]
-
[59]
David Park. 1981. Concurrency and Automata on Infinite Sequences. InProceedings of the 5th GI-Conference on Theoretical Computer Science. Springer-Verlag, Berlin, Heidelberg, 167–183
1981
-
[60]
2020.Copilot 3
Ivan Perez, Frank Dedden, and Alwyn Goodloe. 2020.Copilot 3. Technical Report. NASA Langley Research Center
2020
-
[61]
Simon Peyton Jones, Dimitrios Vytiniotis, Stephanie Weirich, and Geoffrey Washburn. 2006. Simple unification-based type inference for GADTs. InProceedings of the Eleventh ACM SIGPLAN International Conference on Functional Programming(Portland, Oregon, USA)(ICFP ’06). Association for Computing Machinery, New York, NY, USA, 50–61. https://doi.org/10.1145/11...
-
[62]
Lee Pike, Alwyn Goodloe, Robin Morisset, and Sebastian Niller. 2010. Copilot: a hard real-time runtime monitor. InInternational Conference on Runtime Verification. Springer, 345–359. https://doi.org/10.1007/978- 3-642-16612-9 26
-
[63]
Lee Pike, Nis Wegmann, Sebastian Niller, and Alwyn Goodloe. 2012. Experience report: a do-it-yourself high-assurance compiler. InProceedings of the 17th ACM SIGPLAN international conference on Functional programming. 335–340. https://doi.org/10.1145/2398856.2364553 Trustworthy Runtime Verification via Bisimulation (Extended Experience Report) 31
-
[64]
Lee Pike, Nis Wegmann, Sebastian Niller, and Alwyn Goodloe. 2013. Copilot: monitoring embedded systems. Innovations in Systems and Software Engineering9, 4 (2013), 235–255. https://doi.org/10.1007/s11334-013- 0223-x
-
[65]
Amir Pnueli, Michael Siegel, and Eli Singerman. 1998. Translation validation. InInternational Conference on Tools and Algorithms for the Construction and Analysis of Systems. Springer, 151–166. https://doi.org/10. 1007/BFb0054170
1998
-
[66]
Tahina Ramananandro, Paul Mountcastle, Benoˆıt Meister, and Richard Lethin. 2016. A unified Coq framework for verifying C programs with floating-point computations. InProceedings of the 5th ACM SIGPLAN Conference on Certified Programs and Proofs. 15–26. https://doi.org/10.1145/2854065.2854066
-
[67]
Formal Methods Supplement to DO-178C and DO-278A
RTCA 2011. Formal Methods Supplement to DO-178C and DO-278A. RTCA, Inc.. RCTA/DO333
2011
-
[68]
RTCA. 2011. Software Considerations in Airborne Systems and Equipment Certification. RTCA, Inc.. RCTA/DO-178C
2011
-
[69]
Michael Ryabtsev and Ofer Strichman. 2009. Translation validation: From simulink to c. InInternational Conference on Computer Aided Verification. Springer, 696–701. https://doi.org/10.1007/978-3-642-02658- 4 57
-
[70]
SAE International. 2010. Guidelines For Development Of Civil Aircraft and Systems. SAE International. ARP4754A
2010
-
[71]
Tom Schrijvers, Simon Peyton Jones, Manuel Chakravarty, and Martin Sulzmann. 2008. Type checking with open type functions. InProceedings of the 13th ACM SIGPLAN International Conference on Functional Programming(Victoria, BC, Canada)(ICFP ’08). Association for Computing Machinery, New York, NY, USA, 51–62. https://doi.org/10.1145/1411204.1411215
-
[72]
Ryan Scott, Robert Dockins, Tristan Ravitch, and Aaron Tomb. 2021. Crux: Symbolic Execution Meets SMT-based Verification (Competition Contribution). https://doi.org/10.5281/zenodo.6147218
-
[73]
Scott, Mike Dodds, Ivan Perez, Alwyn E
Ryan G. Scott, Mike Dodds, Ivan Perez, Alwyn E. Goodloe, and Robert Dockins. 2023.Artifact for ”Trustworthy Runtime Verification via Bisimulation (Experience Report)”. https://doi.org/10.5281/zenodo.7978326
-
[74]
Thomas Arthur Leck Sewell, Magnus O Myreen, and Gerwin Klein. 2013. Translation validation for a verified OS kernel. InProceedings of the 34th ACM SIGPLAN conference on Programming language design and implementation. 471–482
2013
-
[75]
Aaron Tomb. 2020. Crux: Introducing Our New Open-Source Tool for Software Verification. https: //galois.com/blog/2020/10/crux-introducing-our-new-open-source-tool-for-software-verification/
2020
-
[76]
2014.Analysis of Well-Clear Boundary Models for the Integration of UAS in the NAS
Jason M Upchurch, Cesar A Munoz, Anthony J Narkawicz, James P Chamberlain, and Maria C Consiglio. 2014.Analysis of Well-Clear Boundary Models for the Integration of UAS in the NAS. Technical Report. NASA Langley Research Center
2014
-
[77]
Rob J Van Glabbeek and W Peter Weijland. 1996. Branching time and abstraction in bisimulation semantics. Journal of the ACM (JACM)43, 3 (1996), 555–600
1996
-
[78]
Lucas Wagner, Alain Mebsout, Cesare Tinelli, Darren Cofer, and Konrad Slind. 2017. Qualification of a Model Checker for Avionics Software Verification. InNASA Formal Methods, Clark Barrett, Misty Davies, and Temesghen Kahsai (Eds.). Springer International Publishing, Cham, 404–419. https://doi.org/10.1007/978-3- 319-57288-8 29
-
[79]
Stephanie Weirich, Justin Hsu, and Richard A. Eisenberg. 2013. System FC with explicit kind equality. In Proceedings of the 18th ACM SIGPLAN International Conference on Functional Programming(Boston, Massachusetts, USA)(ICFP ’13). Association for Computing Machinery, New York, NY, USA, 275–286. https://doi.org/10.1145/2500365.2500599
-
[80]
Jonathan Wilmot. 2005. A core flight software system. InProceedings of the 3rd IEEE/ACM/IFIP international conference on Hardware/software codesign and system synthesis. 13–14
2005
-
[81]
Brent A. Yorgey, Stephanie Weirich, Julien Cretin, Simon Peyton Jones, Dimitrios Vytiniotis, and Jos´e Pedro Magalh˜aes. 2012. Giving Haskell a promotion. InProceedings of the 8th ACM SIGPLAN Workshop on Types in Language Design and Implementation(Philadelphia, Pennsylvania, USA)(TLDI ’12). Association for Computing Machinery, New York, NY, USA, 53–66. ht...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.