Flow as Flow: Modeling Robot Velocity Fields as Probability Velocity Fields for Flow-Based Object Manipulation
Pith reviewed 2026-06-26 08:38 UTC · model grok-4.3
The pith
Modeling robot velocity fields as probability flows via flow matching enables faster generation and higher success in object manipulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
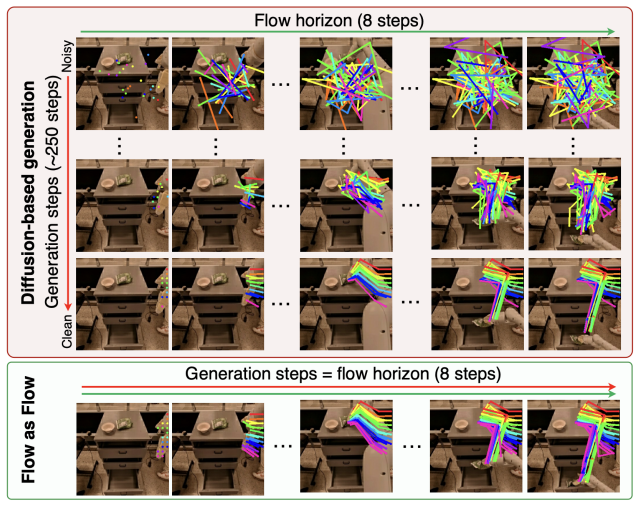
By formulating robot flows as probability flows based on a flow matching formulation, the method achieves efficient and high-quality robot flow generation, outperforming representative baseline methods on standard metrics with approximately 33× faster generation and higher average success rates in real-world experiments across 13 manipulation tasks.
What carries the argument
Flow matching formulation applied to dense robot velocity fields treated as probability flows, which directly models continuous-time motion representations instead of sparse keypoint displacements.
If this is right
- Outperforms baselines on standard metrics for flow generation.
- Achieves approximately 33 times faster generation than compared methods.
- Delivers higher average success rates across 13 manipulation tasks in 260 trials per method.
- Supports use of heterogeneous cross-embodiment data for robotic foundation models.
Where Pith is reading between the lines
- The same probability-flow treatment could be tested on continuous trajectory tasks outside manipulation, such as locomotion or navigation.
- Integration into larger foundation-model training pipelines may reduce the need for explicit keypoint extraction steps.
- Performance gains might scale differently when the amount of cross-embodiment data increases substantially beyond the current experiments.
Load-bearing premise
The premise that dense velocity fields formulated as probability flows within flow matching inherently better capture the continuous-time nature of motions and yield superior performance compared with sparse keypoint displacements.
What would settle it
A head-to-head evaluation on the same 13 real-world tasks with identical training data and compute budget in which any baseline method matches or exceeds both the reported generation speed and success rate.
Figures





read the original abstract
Cross-embodiment data have become central to training robotic foundation models. To leverage such heterogeneous data, we focus on flow-based object manipulation, where robot flows (robot velocity fields) serve as embodiment-agnostic motion representations. Previous studies do not formulate robot flows as dense velocity fields, but as displacements of sparse keypoints, while such velocity fields better match the continuous-time nature of motions. We propose Flow as Flow, a framework that models robot flows as probability flows based on a flow matching formulation. By naturally modeling such velocity fields within this formulation, our method achieves efficient and high-quality robot flow generation. Across standard benchmarks, our method outperforms representative baseline methods on standard metrics, while achieving approximately 33$\times$ faster generation. Furthermore, through real-world experiments evaluating 9 methods with 260 trials per method across 13 manipulation tasks, we show that our method achieves a higher average success rate than the baseline methods. Our project page is available at https://flow-as-flow-u0n5y.kinsta.page.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes 'Flow as Flow', a framework modeling robot velocity fields as probability flows via flow matching to serve as embodiment-agnostic representations for object manipulation from cross-embodiment data. It claims this dense formulation better matches continuous-time motions than prior sparse keypoint displacements, yielding ~33x faster generation on benchmarks and higher average success rates than 9 baselines across 260 trials per method on 13 real-world tasks.
Significance. If the central modeling claim holds after proper isolation of the probability-flow choice, the work could strengthen flow-based manipulation by supplying a dense, continuous-time velocity-field representation that improves efficiency and real-world reliability when training on heterogeneous robot data.
major comments (2)
- [Abstract, §3] Abstract and §3 (method): the central claim that formulating robot flows as probability flows 'naturally' produces the reported 33× speedup and higher success rates is not supported by any derivation showing why the flow-matching ODE is required rather than optional, nor by an ablation that holds network architecture, training data, and optimization fixed while switching only between dense probability velocity fields and sparse keypoint displacements.
- [§4] §4 (experiments): performance numbers are reported without baseline descriptions, metric definitions, error bars, or statistical tests; the 33× speedup and success-rate gains cannot be attributed to the probability-flow modeling choice on the evidence supplied.
minor comments (2)
- [Abstract] Abstract: the phrase 'standard benchmarks' and 'standard metrics' should be replaced by explicit citations to the datasets and metrics used.
- [Abstract] Project page URL should be checked for permanence and content matching the manuscript claims.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and outline the revisions we will make.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (method): the central claim that formulating robot flows as probability flows 'naturally' produces the reported 33× speedup and higher success rates is not supported by any derivation showing why the flow-matching ODE is required rather than optional, nor by an ablation that holds network architecture, training data, and optimization fixed while switching only between dense probability velocity fields and sparse keypoint displacements.
Authors: The flow-matching formulation is selected because it directly parameterizes dense, continuous-time velocity fields as probability flows, aligning with the continuous nature of robot motions in a way that sparse keypoint displacements do not. While this motivation is stated conceptually in the manuscript, we acknowledge that an explicit derivation isolating the ODE and a controlled ablation would strengthen the attribution. In the revised manuscript we will add a derivation in §3 explaining why the flow-matching ODE is required for this dense representation and include an ablation that holds network architecture, data, and optimization fixed while varying only the dense probability velocity field versus sparse keypoint formulation. revision: yes
-
Referee: [§4] §4 (experiments): performance numbers are reported without baseline descriptions, metric definitions, error bars, or statistical tests; the 33× speedup and success-rate gains cannot be attributed to the probability-flow modeling choice on the evidence supplied.
Authors: We agree that the experimental reporting requires additional detail for reproducibility and to support attribution of gains to the modeling choice. In the revised §4 we will expand all baseline descriptions, provide precise metric definitions, add error bars to all quantitative results, and include statistical tests (e.g., paired significance tests) on the reported speedups and success rates. revision: yes
Circularity Check
No circularity; derivation chain self-contained against external benchmarks
full rationale
The abstract and method description introduce a modeling choice (robot velocity fields as probability flows via flow matching) and report empirical gains (33x speedup, higher success rates) without any equations, fitted parameters, or self-citations that reduce the claimed advantage to a quantity defined by the inputs themselves. No self-definitional steps, fitted-input predictions, or load-bearing self-citations appear. The central premise is presented as an empirical modeling decision whose optimality is asserted via performance on benchmarks and real-world trials rather than by algebraic reduction or prior-author uniqueness theorems. This is the most common honest finding for papers whose contributions rest on implementation and evaluation rather than closed-form derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Black, N
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, et al.π 0: A Vision-Language-Action Flow Model for General Robot Control. InRSS, 2025
2025
-
[2]
Black, N
K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, et al.π 0.5: a Vision- Language-Action Model with Open-World Generalization. InCoRL, pages 17–40, 2025
2025
-
[3]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
J. Bjorck, F. Castañeda, N. Cherniadev, X. Da, R. Ding, L. Fan, et al. GR00T N1: An Open Foundation Model for Generalist Humanoid Robots.arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [4]
-
[5]
O’Neill, A
A. O’Neill, A. Rehman, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, et al. Open X- Embodiment: Robotic Learning Datasets and RT-X Models. InICRA, pages 6892–6903, 2024
2024
-
[6]
F. Lin, Y . Hu, P. Sheng, C. Wen, J. You, and Y . Gao. Data Scaling Laws in Imitation Learning for Robotic Manipulation. InICLR, 2025
2025
-
[7]
G. Yang, T. Zhang, H. Hao, W. Wang, Y . Liu, D. Wang, G. Chen, Z. Cai, J. Chen, et al. Vlaser: Vision-Language-Action Model with Synergistic Embodied Reasoning. InICLR, 2026
2026
-
[8]
Bharadhwaj, R
H. Bharadhwaj, R. Mottaghi, A. Gupta, et al. Track2Act: Predicting Point Tracks from Internet Videos enables Generalizable Robot Manipulation. InECCV, pages 306–324, 2024
2024
-
[9]
M. Xu, Z. Xu, Y . Xu, C. Chi, G. Wetzstein, M. Veloso, and S. Song. Flow as the Cross-Domain Manipulation Interface. InCoRL, pages 2475–2499, 2024
2024
-
[10]
C. Wen, X. Lin, J. So, K. Chen, Q. Dou, Y . Gao, and P. Abbeel. Any-point Trajectory Modeling for Policy Learning. InRSS, 2024
2024
-
[11]
Brohan, N
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, et al. RT-1: Robotics Transformer for Real-World Control at Scale. InRSS, 2023
2023
-
[12]
Walke, K
H. Walke, K. Black, T. Zhao, Q. Vuong, C. Zheng, P. Hansen-Estruch, A. He, V . Myers, et al. BridgeData V2: A Dataset for Robot Learning at Scale. InCoRL, pages 1723–1736, 2023
2023
-
[13]
Khazatsky, K
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, et al. DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset. InRSS, 2024
2024
-
[14]
X. Zhu, R. Tian, C. Xu, M. Huo, W. Zhan, M. Tomizuka, and M. Ding. Fanuc Manipulation: A Dataset for Learning-based Manipulation with FANUC Mate 200iD Robot.https:// sites.google.com/berkeley.edu/fanuc-manipulation, 2023
2023
-
[15]
Rombach, A
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer. High-Resolution Image Synthesis with Latent Diffusion Models. InCVPR, pages 10684–10695, 2022
2022
-
[16]
Esser, S
P. Esser, S. Kulal, A. Blattmann, R. Entezari, J. Müller, H. Saini, et al. Scaling Rectified Flow Transformers for High-Resolution Image Synthesis. InICML, pages 12606–12633, 2024
2024
-
[17]
Peebles and S
W. Peebles and S. Xie. Scalable Diffusion Models with Transformers. InICCV, pages 4172– 4182, 2023
2023
-
[18]
Z. Li, Q. Zhou, X. Zhang, Y . Zhang, Y . Wang, and W. Xie. Open-vocabulary Object Segmen- tation with Diffusion Models. InICCV, pages 7667–7676, 2023
2023
-
[19]
Iioka, Y
Y . Iioka, Y . Yoshida, Y . Wada, et al. Multimodal Diffusion Segmentation Model for Object Segmentation from Manipulation Instructions. InIROS, pages 7590–7597, 2023
2023
-
[20]
Zhang et al
Q. Zhang et al. FlowPolicy: Enabling Fast and Robust 3D Flow-based Policy via Consistency Flow Matching for Robot Manipulation. InAAAI, volume 39, pages 14754–14762, 2025. 9
2025
-
[21]
Zhang, C
T. Zhang, C. Yu, S. Su, and Y . Wang. ReinFlow: Fine-tuning Flow Matching Policy with Online Reinforcement Learning. InNeurIPS, 2025
2025
-
[22]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion Policy: Visuomotor Policy Learning via Action Diffusion. InRSS, 2023
2023
-
[23]
M. Sun, W. Wang, G. Li, J. Liu, J. Sun, W. Feng, et al. AR-Diffusion: Asynchronous Video Generation with Auto-Regressive Diffusion. InCVPR, pages 7364–7373, 2025
2025
-
[24]
K. Tian, Y . Jiang, Z. Yuan, B. Peng, et al. Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction. InNeurIPS, volume 37, pages 84839–84865, 2024
2024
-
[25]
S. Ren, Q. Yu, J. He, X. Shen, A. Yuille, and L.-C. Chen. FlowAR: Scale-wise Autoregressive Image Generation Meets Flow Matching. InICML, pages 51489–51502, 2025
2025
-
[26]
D. Yashima, K. Seno, S. Kurita, Y . Oda, et al. HiFlow: Tokenization-Free Scale-Wise Autore- gressive Policy Learning via Flow Matching.arXiv preprint arXiv:2603.27281, 2026
-
[27]
Block et al
A. Block et al. Provable Guarantees for Generative Behavior Cloning: Bridging Low-Level Stability and High-Level Behavior. InNeurIPS, volume 36, pages 48534–48547, 2023
2023
-
[28]
Jiang, X
S. Jiang, X. Fang, N. Roy, T. Lozano-Pérez, et al. Streaming Flow Policy: Simplifying diffusion/flow-matching policies by treating action trajectories as flow trajectories. InCoRL, 2025
2025
-
[29]
C. Yuan, C. Wen, T. Zhang, and Y . Gao. General Flow as Foundation Affordance for Scalable Robot Learning. InCoRL, pages 1541–1566, 2024
2024
-
[30]
H. Chen, B. Sun, et al. VidBot: Learning Generalizable 3D Actions from In-the-Wild 2D Human Videos for Zero-Shot Robotic Manipulation. InCVPR, pages 27661–27672, 2025
2025
-
[31]
L.-H. Lin, Y . Cui, A. Xie, T. Hua, and D. Sadigh. FlowRetrieval: Flow-Guided Data Retrieval for Few-Shot Imitation Learning. InCoRL, pages 4084–4099, 2024
2024
-
[32]
S. Wang, J. You, Y . Hu, J. Li, and Y . Gao. SKIL: Semantic Keypoint Imitation Learning for Generalizable Data-efficient Manipulation. InRSS, 2025
2025
-
[33]
Vecerik, C
M. Vecerik, C. Doersch, Y . Yang, T. Davchev, Y . Aytar, G. Zhou, R. Hadsell, et al. RoboTAP: Tracking Arbitrary Points for Few-Shot Visual Imitation. InICRA, pages 5397–5403, 2024
2024
-
[34]
C. Gao, H. Zhang, Z. Xu, Z. Cai, and L. Shao. FLIP: Flow-Centric Generative Planning as General-Purpose Manipulation World Model. InICLR, 2025
2025
-
[35]
Zheng, Z
Y . Zheng, Z. Ye, W. Dong, S. Wang, Y . Liu, C. Zhang, C. Wen, and Y . Gao. Translating Flow to Policy via Hindsight Online Imitation. InICLR, 2026
2026
-
[36]
Eisner, H
B. Eisner, H. Zhang, and D. Held. FlowBot3D: Learning 3D Articulation Flow to Manipulate Articulated Objects. InRSS, 2022
2022
-
[37]
Yoshida, S
T. Yoshida, S. Kurita, T. Nishimura, et al. Generating 6DoF Object Manipulation Trajectories from Action Description in Egocentric Vision. InCVPR, pages 17370–17382, 2025
2025
-
[38]
Yoshida, S
T. Yoshida, S. Kurita, T. Nishimura, and S. Mori. Developing Vision-Language-Action Model from Egocentric Videos. InICRA, 2026
2026
-
[39]
Q. Bu, Y . Yang, J. Cai, S. Gao, G. Ren, M. Yao, P. Luo, and H. Li. UniVLA: Learning to Act Anywhere with Task-centric Latent Actions. InRSS, 2025
2025
-
[40]
Y . Ma, S. Sodhani, D. Jayaraman, O. Bastani, V . Kumar, and A. Zhang. VIP: Towards Univer- sal Visual Reward and Representation via Value-Implicit Pre-Training. InICLR, 2023
2023
-
[41]
S. Nair, A. Rajeswaran, V . Kumar, C. Finn, and A. Gupta. R3M: A Universal Visual Repre- sentation for Robot Manipulation. InCoRL, pages 892–909, 2023. 10
2023
-
[42]
In- The-Wild
A. Chen, S. Nair, and C. Finn. Learning Generalizable Robotic Reward Functions from "In- The-Wild" Human Videos. InRSS, 2021
2021
-
[43]
Zakka, A
K. Zakka, A. Zeng, P. Florence, J. Tompson, J. Bohg, and D. Dwibedi. XIRL: Cross- embodiment Inverse Reinforcement Learning. InCoRL, pages 537–546, 2022
2022
-
[44]
K. Shaw, S. Bahl, and D. Pathak. VideoDex: Learning Dexterity from Internet Videos. In CoRL, pages 654–665, 2023
2023
-
[45]
S. Bahl, R. Mendonca, L. Chen, U. Jain, and D. Pathak. Affordances from Human Videos as a Versatile Representation for Robotics . InCVPR, pages 13778–13790, 2023
2023
-
[46]
Goyal, S
M. Goyal, S. Modi, R. Goyal, and S. Gupta. Human Hands as Probes for Interactive Object Understanding. InCVPR, pages 3293–3303, 2022
2022
-
[47]
S. Liu, S. Tripathi, S. Majumdar, and X. Wang. Joint Hand Motion and Interaction Hotspots Prediction from Egocentric Videos. InCVPR, pages 3282–3292, 2022
2022
-
[48]
Y . Liu, A. Gupta, P. Abbeel, and S. Levine. Imitation from Observation: Learning to Imitate Behaviors from Raw Video via Context Translation. InICRA, pages 1118–1125, 2018
2018
-
[49]
L. Chen, K. Hari, K. Dharmarajan, C. Xu, Q. Vuong, and K. Goldberg. Mirage: Cross- Embodiment Zero-Shot Policy Transfer with Cross-Painting. InRSS, 2024
2024
-
[50]
Schmeckpeper, O
K. Schmeckpeper, O. Rybkin, K. Daniilidis, S. Levine, et al. Reinforcement Learning with Videos: Combining Offline Observations with Interaction. InCoRL, pages 339–354, 2021
2021
-
[51]
Grauman, A
K. Grauman, A. Westbury, E. Byrne, Z. Chavis, A. Furnari, R. Girdhar, et al. Ego4D: Around The World in 3,000 Hours of Egocentric Video. InCVPR, pages 18995–19012, 2022
2022
-
[52]
Damen, H
D. Damen, H. Doughty, G. Farinella, S. Fidler, A. Furnari, E. Kazakos, D. Moltisanti, et al. Scaling Egocentric Vision: The EPIC-KITCHENS Dataset. InECCV, pages 720–736, 2018
2018
-
[53]
something something
R. Goyal, S. Kahou, V . Michalski, J. Materzynska, et al. The “something something” video database for learning and evaluating visual common sense. InICCV, pages 5842–5850, 2017
2017
-
[54]
S. Ye, J. Jang, B. Jeon, S. Joo, J. Yang, B. Peng, A. Mandlekar, R. Tan, Y .-W. Chao, B. Lin, L. Liden, K. Lee, J. Gao, et al. Latent Action Pretraining from Videos. InICLR, 2025
2025
-
[55]
Y . Du, S. Yang, B. Dai, H. Dai, O. Nachum, J. Tenenbaum, et al. Learning Universal Policies via Text-Guided Video Generation. InNeurIPS, volume 36, pages 9156–9172, 2023
2023
-
[56]
Lipman, R
Y . Lipman, R. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow Matching for Generative Modeling. InICLR, 2023
2023
-
[57]
J. Wu, R. Antonova, A. Kan, M. Lepert, A. Zeng, S. Song, J. Bohg, et al. TidyBot: Personalized Robot Assistance with Large Language Models.Autonomous Robots, 47(8):1087–1102, 2023
2023
-
[58]
J. Liu, J. Han, B. Yan, H. Wu, F. Zhu, X. Wang, Y . Jiang, B. Peng, and Z. Yuan. InfinityStar: Unified Spacetime AutoRegressive Modeling for Visual Generation. InNeurIPS, 2025
2025
-
[59]
K. He, X. Zhang, S. Ren, and J. Sun. Deep Residual Learning for Image Recognition. In CVPR, pages 770–778, 2016
2016
-
[60]
Dasari, O
S. Dasari, O. Mees, S. Zhao, M. Srirama, and S. Levine. The Ingredients for Robotic Diffusion Transformers . InICRA, pages 15617–15625, 2025
2025
-
[61]
Reuss, O
M. Reuss, O. Yagmurlu, F. Wenzel, and R. Lioutikov. Multimodal Diffusion Transformer: Learning Versatile Behavior from Multimodal Goals. InRSS, 2024
2024
-
[62]
M. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, et al. Open- VLA: An Open-Source Vision-Language-Action Model. InCoRL, pages 2679–2713, 2024. 11
2024
- [63]
-
[64]
Karaev, Y
N. Karaev, Y . Makarov, J. Wang, N. Neverova, A. Vedaldi, et al. CoTracker3: Simpler and Better Point Tracking by Pseudo-Labelling Real Videos. InICCV, pages 6013–6022, 2025
2025
-
[65]
Karaev, I
N. Karaev, I. Rocco, B. Graham, N. Neverova, A. Vedaldi, and C. Rupprecht. CoTracker: It is Better to Track Together. InECCV, pages 18–35, 2024
2024
-
[66]
Yamamoto, K
T. Yamamoto, K. Terada, A. Ochiai, F. Saito, et al. Development of Human Support Robot as the research platform of a domestic mobile manipulator.ROBOMECH Journal, 6(1):4, 2019
2019
-
[67]
J. Ma, Y . Qin, Y . Li, X. Liao, Y . Guo, and R. Zhang. CDP: Towards Robust Autoregressive Visuomotor Policy Learning via Causal Diffusion. InCoRL, pages 4190–4205, 2025
2025
-
[68]
Kawaharazuka, T
K. Kawaharazuka, T. Matsushima, A. Gambardella, J. Guo, C. Paxton, and A. Zeng. Real- World Robot Applications of Foundation Models: A Review.AR, 38(18):1232–1254, 2024
2024
-
[69]
Firoozi, J
R. Firoozi, J. Tucker, S. Tian, A. Majumdar, J. Sun, W. Liu, Y . Zhu, et al. Foundation Models in Robotics: Applications, Challenges, and the Future.IJRR, 44(5):701–739, 2025
2025
-
[70]
Urain, A
J. Urain, A. Mandlekar, Y . Du, N. Shafiullah, D. Xu, et al. A Survey on Deep Generative Models for Robot Learning From Multimodal Demonstrations.T-RO, 42:60–79, 2026
2026
-
[71]
J. Ho, A. Jain, and P. Abbeel. Denoising Diffusion Probabilistic Models. InNeurIPS, vol- ume 33, pages 6840–6851, 2020
2020
-
[72]
Y . Wang, Y . He, Y . Li, K. Li, J. Yu, X. Ma, X. Li, G. Chen, X. Chen, et al. InternVid: A Large- scale Video-Text Dataset for Multimodal Understanding and Generation. InICLR, 2024
2024
-
[73]
M. Bain, A. Nagrani, G. Varol, and A. Zisserman. Frozen in Time: A Joint Video and Image Encoder for End-to-End Retrieval. InICCV, pages 1728–1738, 2021
2021
-
[74]
D. Shan, J. Geng, M. Shu, and D. Fouhey. Understanding Human Hands in Contact at Internet Scale. InCVPR, pages 9869–9878, 2020
2020
-
[75]
H. Xue, T. Hang, Y . Zeng, Y . Sun, B. Liu, et al. Advancing High-Resolution Video-Language Representation with Large-Scale Video Transcriptions. InCVPR, pages 5036–5045, 2022
2022
-
[76]
Zellers, X
R. Zellers, X. Lu, J. Hessel, Y . Yu, J. Park, J. Cao, A. Farhadi, et al. MERLOT: Multimodal Neural Script Knowledge Models. InNeurIPS, volume 34, pages 23634–23651, 2021
2021
-
[77]
Grauman, A
K. Grauman, A. Westbury, L. Torresani, K. Kitani, J. Malik, T. Afouras, K. Ashutosh, V . Baiyya, S. Bansal, B. Boote, E. Byrne, et al. Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives. InCVPR, pages 19383–19400, 2024
2024
-
[78]
Sivakumar, K
A. Sivakumar, K. Shaw, and D. Pathak. Robotic Telekinesis: Learning a Robotic Hand Imitator by Watching Humans on YouTube. InRSS, 2023
2023
-
[79]
S. Bahl, R. Mendonca, L. Chen, U. Jain, and D. Pathak. Affordances from Human Videos as a Versatile Representation for Robotics. InCVPR, pages 13778–13790, 2023
2023
-
[80]
Y . Yang, M. Chen, Q. Qiu, J. Wu, et al. Adapt2Reward: Adapting Video-Language Models to Generalizable Robotic Rewards via Failure Prompts. InECCV, pages 163–180, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.