Passive Learning of Symbolic Automata over Monotonic Algebras
Pith reviewed 2026-06-27 22:37 UTC · model grok-4.3
The pith
SAI learns deterministic symbolic automata over monotonic algebras by merging and splitting states to infer interval predicates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
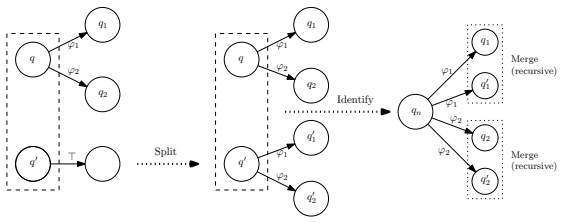
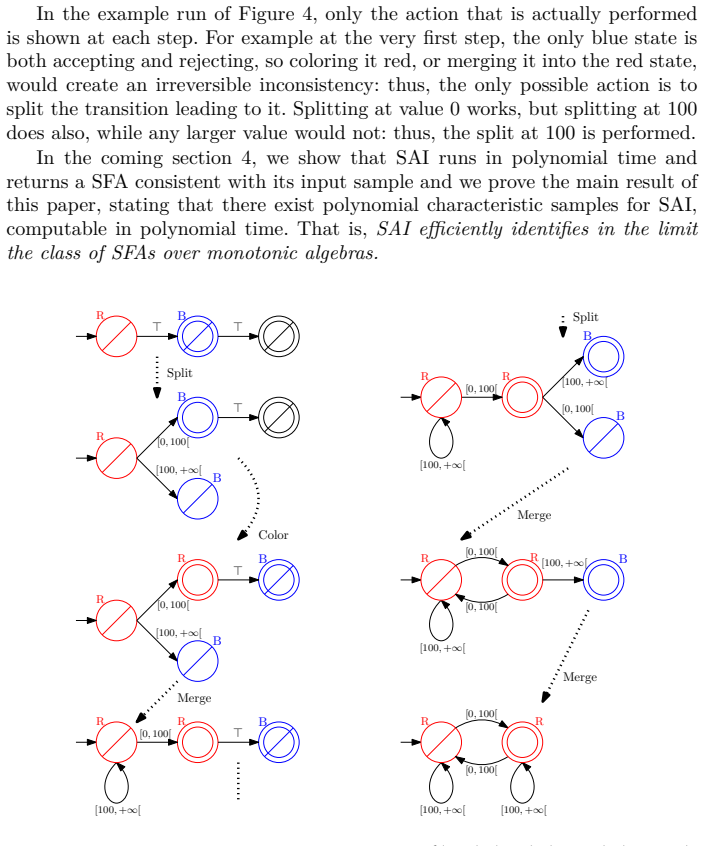
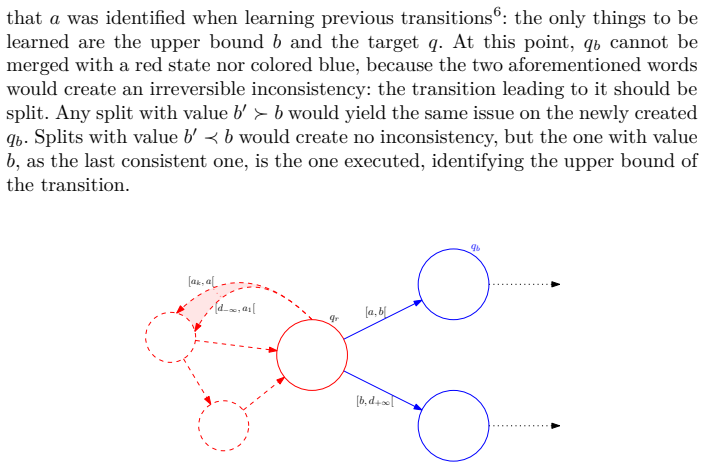
SAI identifies in the limit any deterministic symbolic automaton over a monotonic algebra whose transitions are labeled by predicates of the form a ≤ x < b. Starting from a prefix tree, the algorithm repeatedly merges states according to RPNI-style consistency checks and splits states to refine interval predicates, thereby constructing the correct transition guards without an oracle. The proof shows that the procedure converges and that polynomial-size characteristic samples suffice for every target automaton in the class.
What carries the argument
SAI, the merge-and-split learning procedure that extends RPNI with a top-down splitting step to discover interval predicates on monotonic algebras.
If this is right
- SAI converges to the correct automaton whenever a sufficiently large sample is provided.
- Every target automaton in the class possesses a characteristic sample whose size is polynomial in the number of states.
- The same merge-and-split strategy works uniformly for any monotonic algebra once the predicates are restricted to intervals.
- No membership or equivalence oracle is required; learning proceeds from positive and negative examples alone.
Where Pith is reading between the lines
- The top-down splitting step may be adaptable to other restricted predicate families beyond intervals, provided the algebra supplies an ordering that permits consistent refinement.
- Because the method works for any monotonic algebra, it could be instantiated directly on concrete domains such as integers or reals without first discretizing the alphabet.
- The polynomial characteristic-sample bound supplies an explicit data-complexity guarantee that could be used to decide when to stop collecting examples in a verification pipeline.
Load-bearing premise
The unknown target is a deterministic symbolic automaton whose transition predicates are exactly the intervals a ≤ x < b over some monotonic algebra.
What would settle it
A concrete deterministic symbolic automaton over a monotonic algebra with interval predicates for which SAI either fails to converge on the correct model or requires a characteristic sample whose size grows superpolynomially with the number of states.
Figures



read the original abstract
Symbolic automata extend classical finite-state automata to handle large or infinite alphabets by labeling transitions by predicates coming from a boolean algebra. Many results from automata theory have been lifted to this model, and it has proved its usefulness for example in multiple software verification applications. Here, we tackle the passive learning problem of identification in the limit, i.e. learning a model from a sample without access to an oracle to query. We provide an algorithm, SAI, that efficiently identifies in the limit symbolic automata over any monotonic algebra where predicates labeling transitions are of the form a <= x < b. The algorithm extends the RPNI framework for passive learning of finite-state automata to symbolic automata thanks to a new splitting operation inspired by RTI, a passive learning algorithm for deterministic real-time automata, a subclass of timed automata. The learning algorithm combines merging of states and splitting of states allowing to infer the predicates on transitions in a top-down fashion. We prove that SAI admits polynomial size characteristic samples.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents the SAI algorithm for passive identification in the limit of symbolic automata over monotonic algebras, restricted to interval predicates of the form a ≤ x < b on transitions. SAI extends the RPNI state-merging framework by adding a top-down splitting operation inspired by RTI, and the central claim is that the algorithm identifies the target deterministic symbolic automaton in the limit while admitting characteristic samples whose size is polynomial in the size of the target automaton.
Significance. If the polynomial characteristic-sample result is established, the work supplies a theoretically grounded passive learner for a useful subclass of symbolic automata that arises in verification applications. The combination of RPNI-style merging with RTI-style splitting is a natural technical step, and a polynomial-sample guarantee would be a concrete strengthening of existing identification-in-the-limit results for automata over infinite alphabets.
major comments (1)
- [Proof of polynomial characteristic samples] The proof that SAI admits polynomial-size characteristic samples (the main theorem establishing the identification-in-the-limit result) must explicitly bound the number of examples required by the splitting operation independently of the concrete magnitudes or density of elements in the monotonic algebra. The argument needs to show that distinguishing the exact endpoints a and b of each interval predicate can always be performed with a number of samples polynomial in the automaton size alone; otherwise the claimed polynomial bound does not hold for arbitrary monotonic algebras.
minor comments (1)
- Clarify in the complexity discussion whether the overall running time of SAI (beyond the sample-size bound) remains polynomial when the algebra operations themselves are taken into account.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for the positive evaluation of the significance of the polynomial characteristic-sample result. We address the single major comment below.
read point-by-point responses
-
Referee: [Proof of polynomial characteristic samples] The proof that SAI admits polynomial-size characteristic samples (the main theorem establishing the identification-in-the-limit result) must explicitly bound the number of examples required by the splitting operation independently of the concrete magnitudes or density of elements in the monotonic algebra. The argument needs to show that distinguishing the exact endpoints a and b of each interval predicate can always be performed with a number of samples polynomial in the automaton size alone; otherwise the claimed polynomial bound does not hold for arbitrary monotonic algebras.
Authors: We agree that the proof would be strengthened by an explicit argument showing that the splitting operation requires only a number of examples polynomial in the target automaton size and independent of element magnitudes or density. In the revised manuscript we will insert a supporting lemma before the main theorem. The lemma will establish that, by monotonicity, each interval predicate can be forced to its exact endpoints a and b by at most a constant number of examples (two positive examples inside the interval and two negative examples immediately outside the boundaries). Since the target automaton contains only linearly many such predicates, the total size of the characteristic sample contributed by splitting remains polynomial in the automaton size alone. This addition will make the claimed independence explicit while leaving the overall identification-in-the-limit result unchanged. revision: yes
Circularity Check
No circularity: derivation builds on external frameworks with independent proof
full rationale
The abstract and description present SAI as an algorithmic extension of RPNI (for DFA) combined with RTI-style splitting for interval predicates over monotonic algebras. The polynomial characteristic sample claim is stated as a proved property of this construction. No quoted equations or steps reduce the target result to a fitted parameter, self-definition, or load-bearing self-citation chain. The correctness argument is described as independent of the inputs being learned. This matches the default expectation of a self-contained derivation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The underlying algebra is monotonic
- domain assumption Transition predicates are exactly of the form a <= x < b
Reference graph
Works this paper leans on
-
[1]
Information and computation75(2), 87–106 (1987)
Angluin, D.: Learning regular sets from queries and counterexamples. Information and computation75(2), 87–106 (1987)
1987
-
[2]
Argyros, G., D’Antoni, L.: The learnability of symbolic automata. In: Computer Aided Verification: 30th International Conference, CAV 2018, Held as Part of the Federated Logic Conference, FloC 2018, Oxford, UK, July 14-17, 2018, Proceed- ings, Part I 30. pp. 427–445. Springer (2018)
2018
-
[3]
MIT press (2008)
Baier, C., Katoen, J.P.: Principles of model checking. MIT press (2008)
2008
-
[4]
In: Computer Aided Verification, 29th International Conference (CAV’17)
D’Antoni, L., Veanes, M.: The power of symbolic automata and transducers. In: Computer Aided Verification, 29th International Conference (CAV’17). Springer (July 2017), https://www.microsoft.com/en-us/research/publication/power- symbolic-automata-transducers-invited-tutorial/
2017
-
[5]
https://doi.org/10.1145/3419404, https://doi.org/10.1145/3419404
D’Antoni,L.,Veanes,M.:Automatamodulotheories.Commun.ACM64(5),86–95 (2021). https://doi.org/10.1145/3419404, https://doi.org/10.1145/3419404
-
[6]
Logi- cal Methods in Computer ScienceV olume 19, Issue 2, 5 (Apr 2023)
Fisman, D., Frenkel, H., Zilles, S.: Inferring symbolic automata. Logi- cal Methods in Computer ScienceV olume 19, Issue 2, 5 (Apr 2023). https://doi.org/10.46298/lmcs-19(2:5)2023, https://lmcs.episciences.org/8899
-
[7]
Gold, E.M.: Language identification in the limit. Inf. Control. 10(5), 447–474 (1967). https://doi.org/10.1016/S0019-9958(67)91165-5, https://doi.org/10.1016/S0019-9958(67)91165-5
-
[8]
Gold, E.M.: Complexity of automaton identification from given data. Inf. Control.37(3), 302–320 (1978). https://doi.org/10.1016/S0019-9958(78)90562-4, https://doi.org/10.1016/S0019-9958(78)90562-4
-
[9]
Ma- chine Learning27, 125–138 (1997)
de la Higuera, C.: Characteristic sets for polynomial grammatical inference. Ma- chine Learning27, 125–138 (1997)
1997
-
[10]
Cambridge University Press, USA (2010)
de la Higuera, C.: Grammatical Inference: Learning Automata and Grammars. Cambridge University Press, USA (2010)
2010
-
[11]
In: International Colloquium on Grammatical Inference
Lang, K.J., Pearlmutter, B.A., Price, R.A.: Results of the abbadingo one dfa learning competition and a new evidence-driven state merging algorithm. In: International Colloquium on Grammatical Inference. pp. 1–12. Springer (1998)
1998
-
[12]
Oncina, J., García, P.: Inferring regular languages in polynomial update time. World Scientific (01 1992). https://doi.org/10.1142/9789812797902_0004
-
[13]
Tîrnăucă, C.: A survey of state merging strategies for dfa identification in the limit. Triangle p. 121 (06 2018). https://doi.org/10.17345/triangle8.121-136
-
[14]
Machine Learning86, 295–333 (03 2012)
Verwer, S., Weerdt, M., Witteveen, C.: Efficiently identifying deterministic real- time automata from labeled data. Machine Learning86, 295–333 (03 2012). https://doi.org/10.1007/s10994-011-5265-4 17
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.