PlanRAG-Audio: Planning and Retrieval Augmented Generation for Long-form Audio Understanding
Pith reviewed 2026-05-21 06:51 UTC · model grok-4.3
The pith
PlanRAG-Audio plans required modalities and time spans then retrieves only relevant segments to improve accuracy on long audio.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
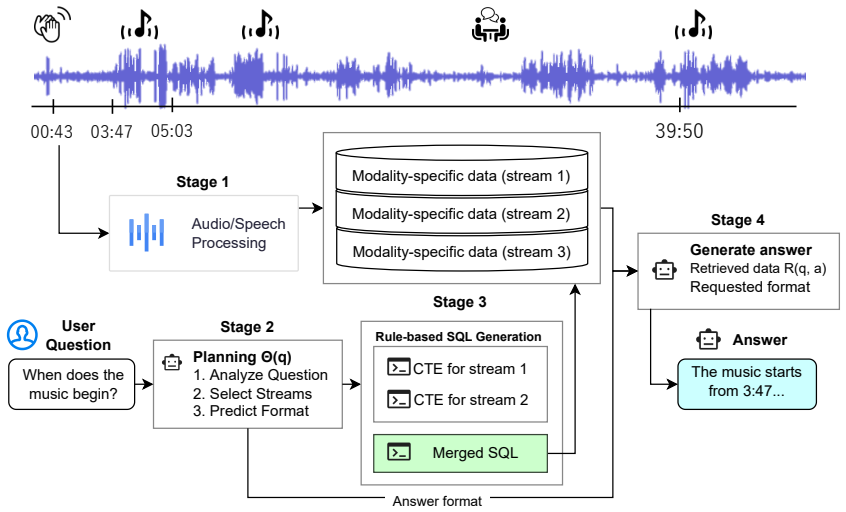
PlanRAG-Audio is a planning-based retrieval-augmented generation framework that explicitly plans which modalities and temporal spans are required for a given query and retrieves only query-relevant information from a structured text and audio database rather than processing entire recordings directly. This retrieval planning enables effective reasoning over complex, cross-domain audio queries while substantially reducing the input length passed to the large language models. Experiments show improved reasoning accuracy and stabilized performance as audio duration increases by decoupling inference cost from raw audio length.
What carries the argument
The explicit planning of modalities and temporal spans followed by targeted retrieval from a structured text and audio database.
Load-bearing premise
The structured database must contain every query-relevant acoustic cue and the planning step must correctly select the needed modalities and time spans without leaving out critical details.
What would settle it
A set of queries where the planner omits a time span containing a decisive sound event or emotion and the model then gives wrong answers that a full-audio baseline would have answered correctly.
Figures


read the original abstract
Long-form audio understanding poses significant challenges for large audio language models (LALMs) due to the extreme length of audio sequences and the need to reason over heterogeneous acoustic cues distributed over time, such as speech content, speaker identity, emotion, and sound events. To address these challenges, we propose \textbf{PlanRAG-Audio}, a planning-based retrieval-augmented generation framework for scalable long-form audio understanding. Rather than having audio LALMs process entire recordings directly, PlanRAG-Audio explicitly plans which modalities and temporal spans are required for a given query, and retrieves only query-relevant information from a structured text and audio database. This retrieval planning enables effective reasoning over complex, cross-domain audio queries while substantially reducing the input length passed to the large language models. Experiments across a wide range of speech/audio retrieval demonstrate that PlanRAG-Audio improves reasoning accuracy and stabilizes performance as audio duration increases by decoupling inference cost from raw audio length.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PlanRAG-Audio, a planning-based retrieval-augmented generation framework for long-form audio understanding. Instead of feeding entire recordings to large audio language models (LALMs), the method explicitly plans which modalities and temporal spans are needed for a query, retrieves only the relevant information from a structured text and audio database, and performs reasoning on the reduced context. The central claim is that this improves reasoning accuracy and stabilizes performance as audio duration grows by decoupling inference cost from raw audio length.
Significance. If the planning step reliably recovers all query-relevant acoustic cues (speech content, speaker identity, emotion, sound events) distributed over time, the framework would provide a practical route to scalable long-form audio reasoning without quadratic growth in context length. The approach is procedurally novel in its explicit modality-and-span planning layer, but its impact hinges on empirical verification of that layer.
major comments (2)
- [Abstract] Abstract: the claim that experiments 'demonstrate accuracy gains and stabilized performance' is unsupported by any reported baselines, datasets, metrics, controls, or statistical tests. Without these details it is impossible to determine whether the observed improvements are attributable to the planning-retrieval mechanism or to other factors.
- [Method / Experiments] Method and Experiments sections: the headline accuracy and stability improvements rest on the planner correctly identifying all query-relevant modalities and temporal spans. The manuscript provides no implementation details for the planning module, no error analysis of planner omissions, and no ablation that measures recall of ground-truth relevant segments. If even one critical cue (e.g., a brief overlapping sound event) is missed, the subsequent retrieval supplies incomplete context that the LALM reasoning step cannot recover.
minor comments (2)
- [Method] Clarify how the structured database is constructed and indexed, including the exact representation of acoustic cues and the retrieval mechanism (e.g., embedding model, similarity metric).
- [Experiments] Figure captions and experimental tables should explicitly state the audio durations tested and the number of queries per duration bin to allow readers to assess the 'stabilization with duration' claim.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review of our manuscript on PlanRAG-Audio. We have carefully considered the major comments and provide point-by-point responses below. Where the comments identify areas needing clarification or additional analysis, we outline specific revisions that will be incorporated into the next version of the paper.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that experiments 'demonstrate accuracy gains and stabilized performance' is unsupported by any reported baselines, datasets, metrics, controls, or statistical tests. Without these details it is impossible to determine whether the observed improvements are attributable to the planning-retrieval mechanism or to other factors.
Authors: We agree that the abstract, due to its length constraints, does not explicitly list the experimental details. In the revised manuscript we will update the abstract to briefly reference the evaluation datasets, the primary metrics (accuracy and stability measures), the baseline methods compared against, and note that improvements are statistically significant. The full experimental protocol, controls, and results remain in the Experiments section; the abstract revision will better anchor the high-level claim to the reported evidence. revision: yes
-
Referee: [Method / Experiments] Method and Experiments sections: the headline accuracy and stability improvements rest on the planner correctly identifying all query-relevant modalities and temporal spans. The manuscript provides no implementation details for the planning module, no error analysis of planner omissions, and no ablation that measures recall of ground-truth relevant segments. If even one critical cue (e.g., a brief overlapping sound event) is missed, the subsequent retrieval supplies incomplete context that the LALM reasoning step cannot recover.
Authors: This is a fair and important observation. The effectiveness of PlanRAG-Audio indeed depends on the planner's ability to surface all necessary cues. In the revised version we will expand the Method section with concrete implementation details of the planning module (including the prompting strategy and decision criteria for modality and span selection). We will also add a dedicated error analysis of planner omissions together with an ablation that reports recall of ground-truth relevant segments. These additions will directly quantify the planner's reliability and address the risk of missing critical acoustic cues. revision: yes
Circularity Check
No circularity: procedural framework with experimental claims
full rationale
The paper introduces PlanRAG-Audio as an explicit planning-plus-retrieval procedure that selects modalities and temporal spans before querying a structured database, then feeds the results to an LALM. No equations, fitted parameters, or self-referential definitions appear in the provided text. Performance improvements are asserted via experiments rather than derived from prior fits or self-citations. The central claim therefore remains independent of its own inputs and does not reduce by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A structured text and audio database exists that stores query-relevant information extractable without loss of critical cues.
invented entities (1)
-
PlanRAG-Audio planning module
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
PlanRAG-Audio explicitly plans which modalities and temporal spans are required for a given query, and retrieves only query-relevant information from a structured text and audio database.
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the system first plans which modalities (e.g., spoken content, speaker information, emotional cues, and non-verbal acoustic events), temporal spans, and constraints are required
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.