LLM-as-a-Judge for Reliable and Explainable Offline Evaluation in Top-K Recommendation
Pith reviewed 2026-06-26 06:57 UTC · model grok-4.3
The pith
LLM-as-a-Judge uses semantic proxies from user text to deliver reliable and explainable top-K recommendation evaluation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
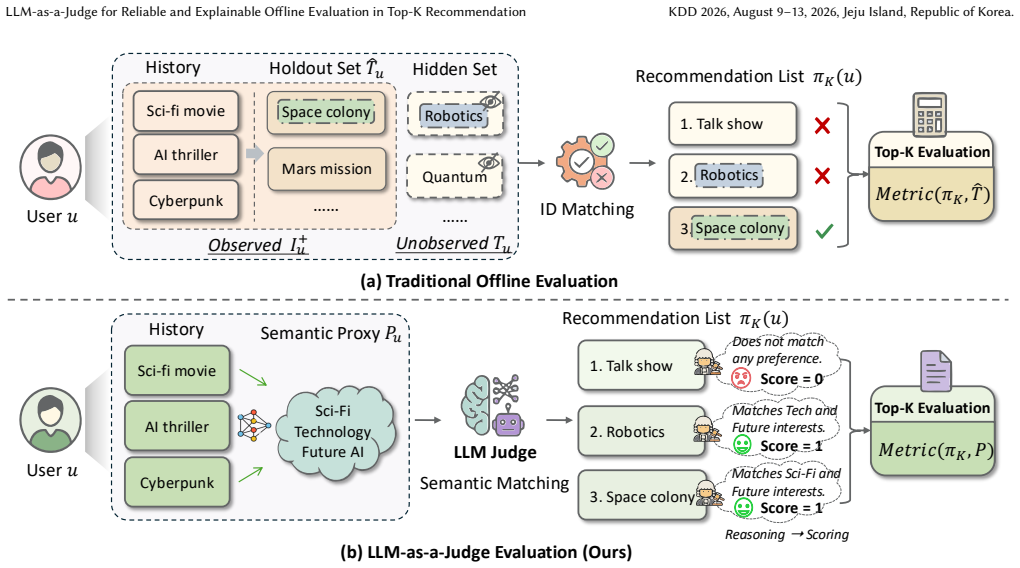
The LLM Judge framework replaces rigid ID matching on biased holdout data with semantic matching on a textual preference proxy, using an LLM to generate reasoned relevance judgments that aggregate into reliable Top-K metrics while supplying explicit justifications for each assessment.
What carries the argument
The LLM Judge that executes a reasoning-then-scoring process on semantic proxies derived from user textual behaviors to produce relevance judgments and rationales.
If this is right
- Recommendation quality can be measured via flexible semantic matching rather than exact item ID matches on holdout feedback.
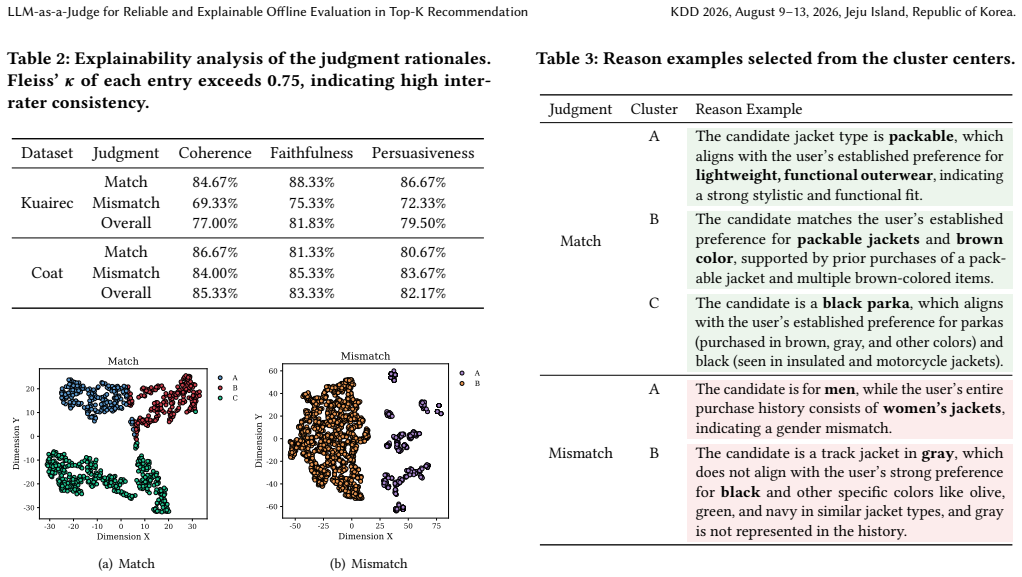
- Each preference hit or miss receives an explicit rationale from the LLM to support the numerical scores.
- Global Top-K metrics are computed by aggregating the individual reasoned judgments.
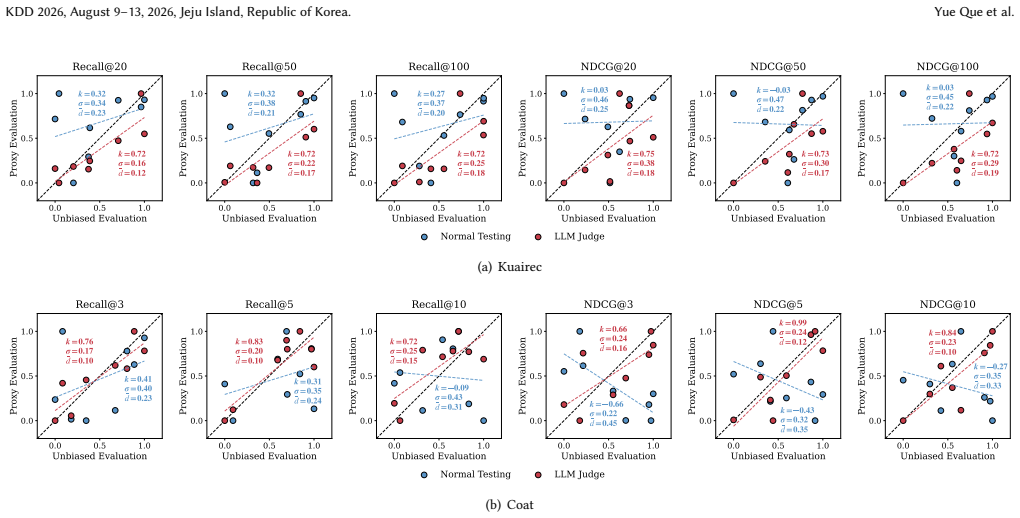
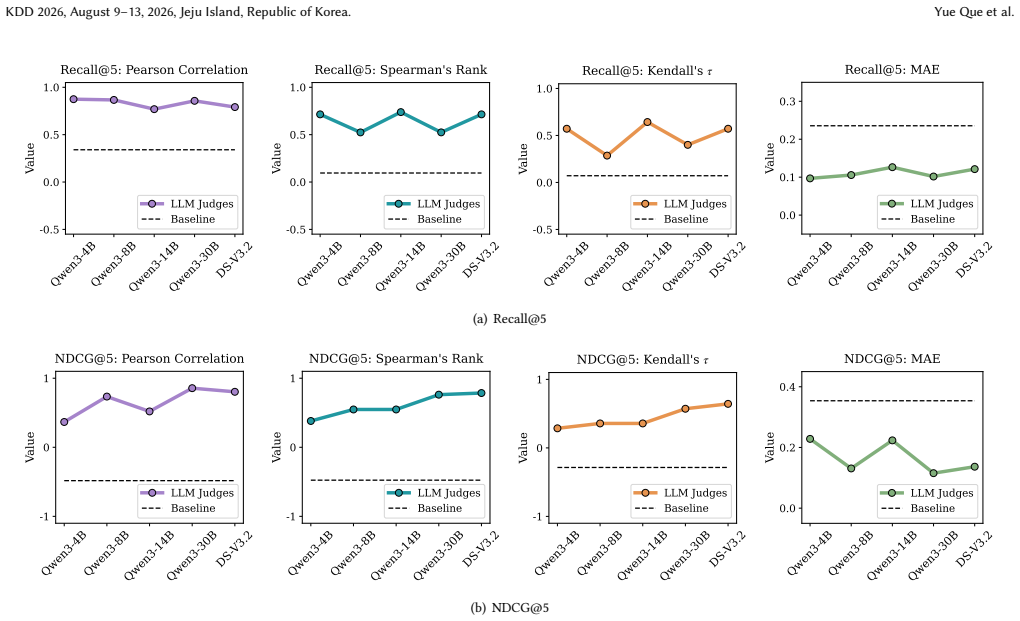
- The evaluation process maintains robustness when tested across varied recommendation models and datasets.
Where Pith is reading between the lines
- The approach could support evaluation in settings where holdout interaction data is sparse or unavailable.
- It opens the possibility of assessing qualitative aspects such as explanation quality alongside relevance.
- Existing offline benchmarks may need re-examination if semantic proxies consistently diverge from ID-based results.
Load-bearing premise
The semantic proxy extracted from user textual behaviors accurately captures true preferences without the exposure bias that affects holdout interaction data.
What would settle it
A controlled study on a dataset with unbiased preference labels where traditional ID-based metrics and the LLM Judge produce materially different top-K rankings, and the LLM rankings show lower correlation with the unbiased labels.
Figures

read the original abstract
Recommendation evaluation plays a crucial role in guiding the refinement and deployment of recommender systems. Most existing trials rely on offline evaluation using Top-K metrics computed over holdout user behaviors. However, we identify two fundamental limitations that undermine their ability to deliver reliable and explainable evaluations. Regarding reliability, offline evaluation treats observed user feedback as a proxy of true preferences and enforces rigid ID matching between the proxy and recommendation. In practice, feedback collections are inherently shaped by incomplete and biased item exposure, leading to distorted and unreliable assessments. Regarding explainability, Top-K metrics only establish numerical scores without offering meaningful insights to support them, thereby reinforcing the black-box nature of offline evaluation. In this paper, we propose a reliable and explainable LLM-as-a-Judge framework for offline recommendation evaluation. To enhance reliability, we introduce a semantic proxy from user textual behaviors to represent their true preferences. This proxy allows for more flexible matching between preferences and recommendations in the semantic space, rather than depending on the holdout feedback. To ensure explainability, the LLM Judge adopts a reasoning-then-scoring process to generate relevance judgments along with explicit rationale. Finally, we aggregate the individual scores into global Top-K metrics to quantify overall recommendation quality, and provide justification for each preference hit or miss. Extensive experiments demonstrate that the LLM Judge achieves solid reliability, explainability, and robustness in evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies two limitations in traditional offline top-K recommendation evaluation: unreliability due to exposure bias in holdout feedback used as proxy for true preferences, and lack of explainability in numerical metrics. It proposes an LLM-as-a-Judge framework that introduces a semantic proxy from user textual behaviors for flexible semantic space matching, uses a reasoning-then-scoring process to generate relevance judgments with rationales, and aggregates these into global Top-K metrics with justifications for hits and misses. The paper claims that extensive experiments show the framework achieves solid reliability, explainability, and robustness.
Significance. If the results hold, this framework could offer a valuable alternative to standard offline evaluation methods in recommender systems by addressing exposure bias and providing explainable outputs. This is significant for the field as it attempts to make evaluations more aligned with true user preferences. The approach is novel in applying LLM reasoning to recsys evaluation.
major comments (2)
- [Abstract and methods description] The central claim rests on the semantic proxy from textual behaviors being less distorted by exposure bias than holdout ID matching; the manuscript provides no validation experiment or direct comparison demonstrating this (e.g., in the methods or results sections), which is load-bearing for the reliability argument.
- [Framework description] The aggregation of individual LLM judgments into global Top-K metrics is described at a high level but lacks detail on how per-item rationales are combined without introducing new selection bias; this step is central to claiming equivalence or superiority to standard metrics.
minor comments (1)
- [Abstract] The abstract asserts 'extensive experiments' but provides no quantitative results, datasets, or baselines; adding a sentence summarizing key metrics would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and commit to revisions that strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and methods description] The central claim rests on the semantic proxy from textual behaviors being less distorted by exposure bias than holdout ID matching; the manuscript provides no validation experiment or direct comparison demonstrating this (e.g., in the methods or results sections), which is load-bearing for the reliability argument.
Authors: We agree this is a load-bearing claim and that the current experiments demonstrate overall reliability without a direct head-to-head validation of exposure-bias reduction in the semantic proxy versus ID matching. In the revised version we will add a targeted experiment that simulates controlled exposure bias and measures alignment of each proxy with held-out true preferences. revision: yes
-
Referee: [Framework description] The aggregation of individual LLM judgments into global Top-K metrics is described at a high level but lacks detail on how per-item rationales are combined without introducing new selection bias; this step is central to claiming equivalence or superiority to standard metrics.
Authors: We acknowledge that the aggregation procedure is presented at a high level and that explicit safeguards against new selection bias are not detailed. The revised manuscript will expand Section 3.3 with the precise aggregation algorithm, including how rationales are weighted, how ties or low-confidence judgments are handled, and the bias-mitigation steps employed. revision: yes
Circularity Check
No significant circularity
full rationale
The paper proposes an LLM-as-a-Judge framework that introduces a semantic proxy derived from user textual behaviors and a reasoning-then-scoring process for relevance judgments. No equations, fitted parameters, or derivation steps are present in the provided text that reduce a claimed prediction or result to its own inputs by construction. The central claims rest on the introduction of new components and experimental validation rather than self-referential definitions or load-bearing self-citations. The argument is self-contained as a methodological proposal without internal reduction to prior fitted values or ansatzes from the authors' own prior work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Christine Bauer, Eva Zangerle, and Alan Said. 2024. Exploring the Landscape of Recommender Systems Evaluation: Practices and Perspectives.ACM Trans. Recomm. Syst.2, 1, Article 11 (March 2024), 31 pages
2024
-
[2]
Joeran Beel, Marcel Genzmehr, Stefan Langer, Andreas Nürnberger, and Bela Gipp
-
[3]
InProceedings of the International Workshop on Reproducibility and Replication in Recommender Systems Evaluation (Hong Kong, China)(RepSys ’13)
A comparative analysis of offline and online evaluations and discussion of research paper recommender system evaluation. InProceedings of the International Workshop on Reproducibility and Replication in Recommender Systems Evaluation (Hong Kong, China)(RepSys ’13). Association for Computing Machinery, New York, NY, USA, 7–14
-
[4]
Rocío Cañamares, Pablo Castells, and Alistair Moffat. 2020. Offline evaluation options for recommender systems.Inf. Retr.23, 4 (March 2020), 387–410
2020
-
[5]
Pablo Castells and Alistair Moffat. 2022. Offline recommender system evaluation: Challenges and new directions.AI Magazine43, 2 (2022), 225–238
2022
-
[6]
Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu
-
[7]
M3-Embedding: Multi-Linguality, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation. arXiv:2402.03216
-
[8]
Lei Chen, Le Wu, Richang Hong, Kun Zhang, and Meng Wang. 2020. Revisiting Graph based Collaborative Filtering: A Linear Residual Graph Convolutional Network Approach. arXiv:2001.10167
arXiv 2020
-
[9]
Xu Chen, Yongfeng Zhang, and Ji-Rong Wen. 2022. Measuring "Why" in Rec- ommender Systems: a Comprehensive Survey on the Evaluation of Explainable Recommendation. arXiv:2202.06466
arXiv 2022
-
[10]
DeepSeek-AI, Aixin Liu, Bei Feng, et al. 2025. DeepSeek-V3 Technical Report. arXiv:2412.19437
Pith/arXiv arXiv 2025
-
[11]
Francesco Fabbri, Gustavo Penha, Edoardo D’Amico, Alice Wang, Marco De Nadai, Jackie Doremus, Paul Gigioli, Andreas Damianou, Oskar Stål, and Mounia Lalmas
-
[12]
InProceedings of the Nineteenth ACM Conference on Recommender Systems (RecSys ’25)
Evaluating Podcast Recommendations with Profile-Aware LLM-as-a-Judge. InProceedings of the Nineteenth ACM Conference on Recommender Systems (RecSys ’25). Association for Computing Machinery, New York, NY, USA, 1181–1186
-
[13]
Guglielmo Faggioli, Laura Dietz, Charles L. A. Clarke, Gianluca Demartini, Matthias Hagen, Claudia Hauff, Noriko Kando, Evangelos Kanoulas, Martin Potthast, Benno Stein, and Henning Wachsmuth. 2023. Perspectives on Large Language Models for Relevance Judgment. InProceedings of the 2023 ACM SI- GIR International Conference on Theory of Information Retrieva...
2023
-
[14]
Wenqi Fan, Xiaorui Liu, Wei Jin, Xiangyu Zhao, Jiliang Tang, and Qing Li. 2022. Graph Trend Filtering Networks for Recommendation. InProceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval(Madrid, Spain)(SIGIR ’22). Association for Computing Machinery, New York, NY, USA, 112–121
2022
-
[15]
Leticia Freire de Figueiredo, Antonio A. de A. Rocha, and Aline Paes. 2025. Tell me why: how Explanation can affect Recommender Systems. InProceedings of the 2025 ACM International Conference on Interactive Media Experiences (IMX ’25). Association for Computing Machinery, New York, NY, USA, 492–493
2025
-
[16]
Chongming Gao, Shijun Li, Wenqiang Lei, Jiawei Chen, Biao Li, Peng Jiang, Xiangnan He, Jiaxin Mao, and Tat-Seng Chua. 2022. KuaiRec: A Fully-observed Dataset and Insights for Evaluating Recommender Systems. InProceedings of the 31st ACM International Conference on Information & Knowledge Management (Atlanta, GA, USA)(CIKM ’22). Association for Computing M...
2022
-
[17]
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, Saizhuo Wang, Kun Zhang, Yuanzhuo Wang, Wen Gao, Lionel Ni, and Jian Guo. 2025. A Survey on LLM-as- a-Judge. arXiv:2411.15594
Pith/arXiv arXiv 2025
-
[18]
Xiangnan He, Kuan Deng, Xiang Wang, Yan Li, YongDong Zhang, and Meng Wang. 2020. LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation. InProceedings of the 43rd International ACM SIGIR Confer- ence on Research and Development in Information Retrieval(Virtual Event, China) (SIGIR ’20). Association for Computing Machinery, New Yor...
2020
-
[19]
Xiangnan He, Lizi Liao, Hanwang Zhang, Liqiang Nie, Xia Hu, and Tat-Seng Chua. 2017. Neural Collaborative Filtering. InProceedings of the 26th International Conference on World Wide Web(Perth, Australia)(WWW ’17). International World Wide Web Conferences Steering Committee, Republic and Canton of Geneva, CHE, 173–182
2017
-
[20]
Herlocker, Joseph A
Jonathan L. Herlocker, Joseph A. Konstan, Loren G. Terveen, and John T. Riedl
-
[21]
Evaluating collaborative filtering recommender systems.ACM Trans. Inf. KDD 2026, August 9–13, 2026, Jeju Island, Republic of Korea. Yue Que et al. Syst.22, 1 (Jan. 2004), 5–53
2026
-
[22]
Yifan Hu, Yehuda Koren, and Chris Volinsky. 2008. Collaborative Filtering for Implicit Feedback Datasets. InProceedings of the 2008 Eighth IEEE International Conference on Data Mining (ICDM ’08). IEEE Computer Society, USA, 263–272
2008
-
[23]
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, and Ting Liu. 2025. A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions.ACM Trans. Inf. Syst.43, 2, Article 42 (Jan. 2025), 55 pages
2025
-
[24]
Ikotun, Absalom E
Abiodun M. Ikotun, Absalom E. Ezugwu, Laith Abualigah, Belal Abuhaija, and Jia Heming. 2023. K-means clustering algorithms: A comprehensive review, variants analysis, and advances in the era of big data.Information Sciences622 (2023), 178–210
2023
-
[25]
Jadidinejad, Craig Macdonald, and Iadh Ounis
Amir H. Jadidinejad, Craig Macdonald, and Iadh Ounis. 2020. Using Exploration to Alleviate Closed Loop Effects in Recommender Systems. InProceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval(Virtual Event, China)(SIGIR ’20). Association for Computing Machinery, New York, NY, USA, 2025–2028
2020
-
[26]
Jadidinejad, Craig Macdonald, and Iadh Ounis
Amir H. Jadidinejad, Craig Macdonald, and Iadh Ounis. 2021. The Simpson’s Paradox in the Offline Evaluation of Recommendation Systems.ACM Trans. Inf. Syst.40, 1, Article 4 (Sept. 2021), 22 pages
2021
-
[27]
Olivier Jeunen and Aleksei Ustimenko. 2024. Δ-OPE: Off-Policy Estimation with Pairs of Policies. InProceedings of the 18th ACM Conference on Recommender Systems(Bari, Italy)(RecSys ’24). Association for Computing Machinery, New York, NY, USA, 878–883
2024
-
[28]
Petr Kasalický, Rodrigo Alves, and Pavel Kordík. 2023. Bridging Offline-Online Evaluation with a Time-dependent and Popularity Bias-free Offline Metric for Recommenders. arXiv:2308.06885
arXiv 2023
-
[29]
Seyedeh Baharan Khatami, Sayan Chakraborty, Ruomeng Xu, and Babak Salimi
-
[30]
Towards Robust Offline Evaluation: A Causal and Information Theoretic Framework for Debiasing Ranking Systems. arXiv:2504.03997
-
[31]
Yehuda Koren, Robert Bell, and Chris Volinsky. 2009. Matrix Factorization Tech- niques for Recommender Systems.Computer42, 8 (2009), 30–37
2009
-
[32]
Marlin and Richard S
Benjamin M. Marlin and Richard S. Zemel. 2009. Collaborative prediction and ranking with non-random missing data. InProceedings of the Third ACM Confer- ence on Recommender Systems(New York, New York, USA)(RecSys ’09). Associa- tion for Computing Machinery, New York, NY, USA, 5–12
2009
-
[33]
Yusuke Narita, Shota Yasui, and Kohei Yata. 2021. Debiased Off-Policy Evaluation for Recommendation Systems. InProceedings of the 15th ACM Conference on Recommender Systems(Amsterdam, Netherlands)(RecSys ’21). Association for Computing Machinery, New York, NY, USA, 372–379
2021
-
[34]
Yue Que, Yingyi Zhang, Xiangyu Zhao, and Chen Ma. 2025. Causality-aware Graph Aggregation Weight Estimator for Popularity Debiasing in Top-K Recom- mendation. InProceedings of the 34th ACM International Conference on Information and Knowledge Management(Seoul, Republic of Korea)(CIKM ’25). Association for Computing Machinery, New York, NY, USA, 2471–2481
2025
-
[35]
Webb (Eds.)
Claude Sammut and Geoffrey I. Webb (Eds.). 2010.Holdout Evaluation. Springer US, Boston, MA, 506–507
2010
-
[36]
Tobias Schnabel, Adith Swaminathan, Ashudeep Singh, Navin Chandak, and Thorsten Joachims. 2016. Recommendations as treatments: debiasing learning and evaluation. InProceedings of the 33rd International Conference on International Conference on Machine Learning - Volume 48(New York, NY, USA)(ICML’16). JMLR.org, 1670–1679
2016
-
[37]
Jianing Sun, Yingxue Zhang, Chen Ma, Mark Coates, Huifeng Guo, Ruiming Tang, and Xiuqiang He. 2019. Multi-graph Convolution Collaborative Filtering. In2019 IEEE International Conference on Data Mining (ICDM). 1306–1311
2019
-
[38]
Yi-Da Tang, Er-Dan Dong, and Wen Gao. 2024. LLMs in medicine: The need for advanced evaluation systems for disruptive technologies.The Innovation5, 3 (2024)
2024
-
[39]
Paul Thomas, Seth Spielman, Nick Craswell, and Bhaskar Mitra. 2024. Large Language Models can Accurately Predict Searcher Preferences. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Infor- mation Retrieval(Washington DC, USA)(SIGIR ’24). Association for Computing Machinery, New York, NY, USA, 1930–1940
2024
-
[40]
Yu Tokutake, Kazushi Okamoto, Kei Harada, Atsushi Shibata, and Koki Karube
-
[41]
InProceedings of the 34th ACM Interna- tional Conference on Information and Knowledge Management(Seoul, Republic of Korea)(CIKM ’25)
A Universal Framework for Offline Serendipity Evaluation in Recommender Systems via Large Language Models. InProceedings of the 34th ACM Interna- tional Conference on Information and Knowledge Management(Seoul, Republic of Korea)(CIKM ’25). Association for Computing Machinery, New York, NY, USA, 5294–5298
-
[42]
Xiang Wang, Xiangnan He, Meng Wang, Fuli Feng, and Tat-Seng Chua. 2019. Neural Graph Collaborative Filtering. InProceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval (Paris, France)(SIGIR’19). Association for Computing Machinery, New York, NY, USA, 165–174
2019
-
[43]
Yilei Wang, Jiabao Zhao, Deniz Ones, Liang He, and Xin Xu. 2025. Evaluating the ability of large language models to emulate personality.Scientific Reports15 (01 2025)
2025
-
[44]
Timo Wilm and Philipp Normann. 2025. Identifying Offline Metrics that Predict Online Impact: A Pragmatic Strategy for Real-World Recommender Systems. In Proceedings of the Nineteenth ACM Conference on Recommender Systems (RecSys ’25). Association for Computing Machinery, New York, NY, USA, 967–970
2025
-
[45]
Zhuo Wu, Qinglin Jia, Chuhan Wu, Zhaocheng Du, Shuai Wang, Zan Wang, and Zhenhua Dong. 2024. RecSys Arena: Pair-wise Recommender System Evaluation with Large Language Models. arXiv:2412.11068
arXiv 2024
-
[46]
An Yang, Anfeng Li, Baosong Yang, et al . 2025. Qwen3 Technical Report. arXiv:2505.09388
Pith/arXiv arXiv 2025
-
[47]
Longqi Yang, Yin Cui, Yuan Xuan, Chenyang Wang, Serge Belongie, and Debo- rah Estrin. 2018. Unbiased offline recommender evaluation for missing-not-at- random implicit feedback. InProceedings of the 12th ACM Conference on Recom- mender Systems(Vancouver, British Columbia, Canada)(RecSys ’18). Association for Computing Machinery, New York, NY, USA, 279–287
2018
-
[48]
Junliang Yu, Hongzhi Yin, Xin Xia, Tong Chen, Lizhen Cui, and Quoc Viet Hung Nguyen. 2022. Are Graph Augmentations Necessary? Simple Graph Contrastive Learning for Recommendation. InProceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval(Madrid, Spain)(SIGIR ’22). Association for Computing Machinery,...
2022
-
[49]
Eva Zangerle and Christine Bauer. 2022. Evaluating Recommender Systems: Sur- vey and Framework.ACM Comput. Surv.55, 8, Article 170 (Dec. 2022), 38 pages
2022
-
[50]
Xiaoyu Zhang, Yishan Li, Jiayin Wang, Bowen Sun, Weizhi Ma, Peijie Sun, and Min Zhang. 2024. Large Language Models as Evaluators for Recommendation Explanations. InProceedings of the 18th ACM Conference on Recommender Systems (Bari, Italy)(RecSys ’24). Association for Computing Machinery, New York, NY, USA, 33–42
2024
-
[51]
Xiaokun Zhang, Bo Xu, Chenliang Li, Bowei He, Hongfei Lin, Chen Ma, and Fenglong Ma. 2025. A Survey on Side Information-Driven Session-Based Recom- mendation: From a Data-Centric Perspective.IEEE Transactions on Knowledge and Data Engineering37, 8 (2025), 4411–4431
2025
-
[52]
Xiaokun Zhang, Bo Xu, Zhaochun Ren, Xiaochen Wang, Hongfei Lin, and Fen- glong Ma. 2024. Disentangling ID and Modality Effects for Session-based Rec- ommendation. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval(Washington DC, USA)(SIGIR ’24). Association for Computing Machinery, New York, N...
2024
-
[53]
Xiaokun Zhang, Bo Xu, Youlin Wu, Yuan Zhong, Hongfei Lin, and Fenglong Ma. 2024. FineRec: Exploring Fine-grained Sequential Recommendation. In Proceedings of the 47th International ACM SIGIR Conference on Research and Devel- opment in Information Retrieval(Washington DC, USA)(SIGIR ’24). Association for Computing Machinery, New York, NY, USA, 1599–1608
2024
-
[54]
Discovered by the little cutie
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, Hao Zhang, Joseph E Gonzalez, and Ion Stoica. 2023. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. InAdvances in Neural Information Processing Systems, Vol. 36. Curran Associates, Inc., 46595–46623. A Additional Detail...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.