Tournament Informed Adversarial Quality Diversity
Pith reviewed 2026-05-21 14:36 UTC · model grok-4.3
The pith
Tournament-informed task selection improves quality and diversity in adversarial quality diversity algorithms.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
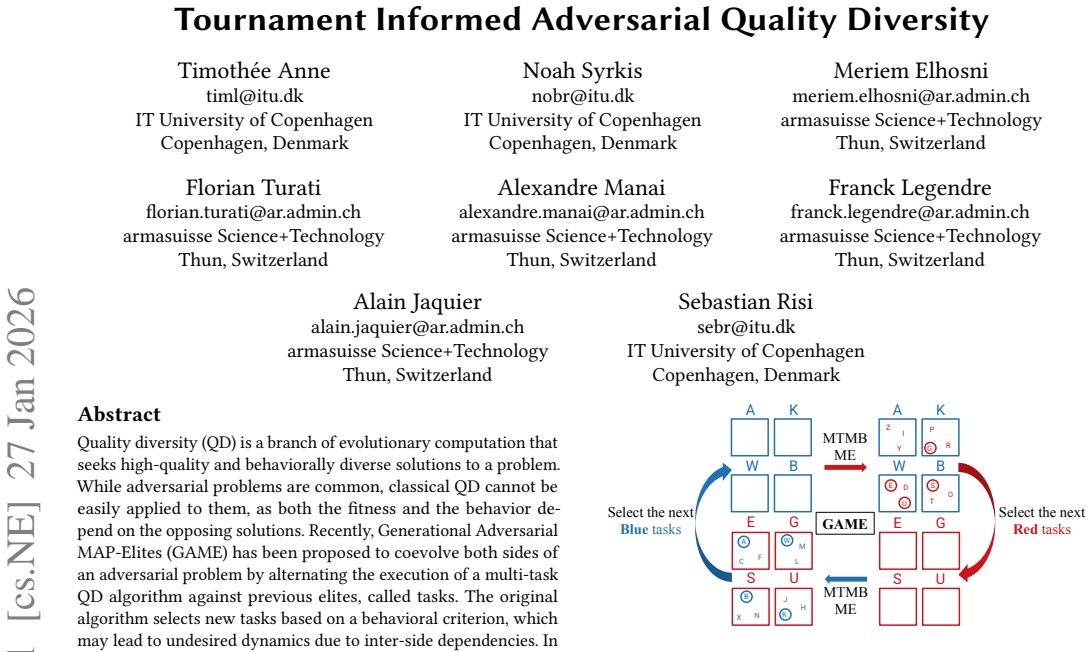
By replacing behavioral task selection with methods guided by the outcomes of inter-variants tournaments, the algorithm achieves higher adversarial quality and greater behavioral diversity across generations in coevolutionary settings. The tournament uses six measures to compare solution sets from different variants without the side-dependency bias that affects standard QD metrics.
What carries the argument
Tournament-informed task selection methods that rank opposing elites using six quality and diversity measures from an inter-variants tournament and then choose the next tasks accordingly.
If this is right
- Solution sets on each side of an adversarial problem reach higher performance against a wider range of opponents.
- Direct comparison of different algorithmic variants becomes possible without relying on metrics that favor one side.
- The same selection approach can be inserted into other multi-task quality diversity frameworks that face opponent dependence.
- Over generations the populations maintain both high fitness and spread-out behaviors even as the opposing side improves.
Where Pith is reading between the lines
- The approach may transfer to non-game adversarial domains such as robust control or security strategy generation where one agent must counter another.
- If the tournament ranking proves stable, it could replace manual metric tuning in other coevolutionary algorithms.
- Testing whether the same gains appear when the number of measures inside the tournament is reduced would clarify which components drive the improvement.
Load-bearing premise
The six quality and diversity measures inside the inter-variants tournament give a fair, unbiased ranking of solution sets that removes the comparison problems caused by side dependencies.
What would settle it
Running the original behavioral task selection and the new tournament-informed versions on the same three game domains and finding no consistent gain in the six tournament measures would show the claimed improvement does not hold.
Figures


read the original abstract
Quality diversity (QD) is a branch of evolutionary computation that seeks high-quality and behaviorally diverse solutions to a problem. While adversarial problems are common, classical QD cannot be easily applied to them, as both the fitness and the behavior depend on the opposing solutions. Recently, Generational Adversarial MAP-Elites (GAME) has been proposed to coevolve both sides of an adversarial problem by alternating the execution of a multi-task QD algorithm against previous elites, called tasks. The original algorithm selects new tasks based on a behavioral criterion, which may lead to undesired dynamics due to inter-side dependencies. In addition, comparing sets of solutions cannot be done directly using classical QD measures due to side dependencies. In this paper, we (1) use an inter-variants tournament to compare the sets of solutions, ensuring a fair comparison, with 6 measures of quality and diversity, and (2) propose two tournament-informed task selection methods to promote higher quality and diversity at each generation. We evaluate the variants across three adversarial problems: Pong, a Cat-and-mouse game, and a Pursuers-and-evaders game. We show that the tournament-informed task selection method leads to higher adversarial quality and diversity. We hope that this work will help further advance adversarial quality diversity. Code, videos, and supplementary material are available at https://github.com/Timothee-ANNE/GAME_tournament_informed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper extends Generational Adversarial MAP-Elites (GAME) by introducing two tournament-informed task selection methods that use an inter-variants tournament over six quality and diversity measures. This addresses side-dependency issues in task selection for adversarial QD and enables fair comparison of solution sets. The authors evaluate the variants on Pong, a Cat-and-mouse game, and a Pursuers-and-evaders game, claiming that the tournament-informed selection produces higher adversarial quality and diversity than prior GAME variants. Code, videos, and supplementary material are provided.
Significance. If the empirical gains hold under independent validation, the work would meaningfully advance adversarial quality diversity by providing a practical mechanism for task selection that mitigates inter-side dependencies. The open release of code and the use of multiple game benchmarks are positive for reproducibility and generalizability within evolutionary computation.
major comments (2)
- [Methods and Evaluation sections] The inter-variants tournament is employed both to select tasks during evolution (to promote quality and diversity) and to perform the final comparison of solution sets across variants. This dual usage creates a risk that reported improvements are partly an artifact of alignment with the chosen six measures rather than an independent demonstration of stronger archives. The manuscript should clarify whether final rankings rely on the same tournament protocol or on an external validation set of adversaries (see the description of the comparison challenge and the evaluation protocol).
- [Experimental results] The abstract states positive outcomes on three distinct adversarial problems, yet the support for the central claim would be strengthened by explicit reporting of statistical tests, number of independent runs, effect sizes, and ablation studies that isolate the contribution of individual tournament measures. Without these, it remains unclear whether the gains generalize beyond the internal comparison protocol.
minor comments (2)
- [Abstract] The abstract could include one or two quantitative highlights (e.g., average improvement in a key measure) to give readers an immediate sense of effect magnitude.
- [Methods] Notation for the six quality/diversity measures should be introduced consistently in the main text and cross-referenced to the supplementary material for reproducibility.
Simulated Author's Rebuttal
Thank you for the detailed review and constructive feedback on our manuscript. We appreciate the opportunity to clarify and strengthen our work on tournament-informed adversarial quality diversity. Below, we provide point-by-point responses to the major comments.
read point-by-point responses
-
Referee: [Methods and Evaluation sections] The inter-variants tournament is employed both to select tasks during evolution (to promote quality and diversity) and to perform the final comparison of solution sets across variants. This dual usage creates a risk that reported improvements are partly an artifact of alignment with the chosen six measures rather than an independent demonstration of stronger archives. The manuscript should clarify whether final rankings rely on the same tournament protocol or on an external validation set of adversaries (see the description of the comparison challenge and the evaluation protocol).
Authors: We thank the referee for highlighting this important methodological consideration. The inter-variants tournament is used both for task selection during evolution and for final comparison of solution sets because it provides a fair, side-independent evaluation mechanism, which directly addresses the inter-side dependency issues discussed in the paper. In the revised manuscript, we will add explicit clarification in the Methods and Evaluation sections stating that final rankings rely on the same tournament protocol, as it is the appropriate and consistent approach for comparing variants without introducing external biases. We will also expand the discussion to explain why this does not constitute an artifact, emphasizing that the six measures are standard in the QD literature and applied uniformly. To further address the concern, we will include additional analysis in the supplementary material comparing performance against a fixed external set of adversaries where feasible. revision: partial
-
Referee: [Experimental results] The abstract states positive outcomes on three distinct adversarial problems, yet the support for the central claim would be strengthened by explicit reporting of statistical tests, number of independent runs, effect sizes, and ablation studies that isolate the contribution of individual tournament measures. Without these, it remains unclear whether the gains generalize beyond the internal comparison protocol.
Authors: We agree that greater statistical transparency would strengthen the results section. The experiments were performed with 10 independent runs per variant per problem, as noted in the supplementary material, but we acknowledge that explicit reporting of tests, effect sizes, and ablations is not detailed in the main text. In the revision, we will add this information directly to the Experimental results section, including statistical tests (e.g., Wilcoxon rank-sum with corrections), effect sizes, and an ablation isolating the contribution of each tournament measure. This will better demonstrate that the observed gains in quality and diversity generalize across the three problems. revision: yes
Circularity Check
Empirical evaluation of algorithmic variants on external benchmarks shows no definitional circularity
full rationale
The paper presents an empirical study of new task-selection variants within the GAME framework, evaluated on standard external game benchmarks (Pong, Cat-and-mouse, Pursuers-and-evaders). The central claim rests on direct performance comparisons of solution sets rather than any derivation or equation that reduces a prediction to a fitted parameter or self-referential definition. Although the inter-variant tournament supplies both the selection criterion and the final quality/diversity measures, this is a consistent methodological protocol introduced to address acknowledged side-dependency problems; it does not create a load-bearing self-definition or fitted-input loop because the reported gains are measured against baseline variants on independent game environments. No self-citation chain is invoked to justify uniqueness, and the work remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Coevolutionary search can produce high-quality diverse solutions when task selection accounts for inter-side dependencies in adversarial problems.
Reference graph
Works this paper leans on
-
[1]
Timothée Anne and Jean-Baptiste Mouret. 2023. Multi-task multi-behavior map- elites. InProceedings of the companion conference on genetic and evolutionary computation. 111–114
work page 2023
-
[2]
Timothée Anne, Noah Syrkis, Meriem Elhosni, Florian Turati, Franck Legendre, Alain Jaquier, and Sebastian Risi. 2025. Generational Adversarial MAP-Elites for Multi-Agent Game Illumination. InArtificial Life Conference Proceedings 37, Vol. 2025. MIT Press One Rogers Street, Cambridge, MA 02142-1209, USA journals-info . . . , 31
work page 2025
-
[3]
Bowen Baker, Ingmar Kanitscheider, Todor Markov, Yi Wu, Glenn Powell, Bob McGrew, and Igor Mordatch. 2019. Emergent tool use from multi-agent autocur- ricula. InInternational conference on learning representations
work page 2019
-
[4]
Mark A Bedau, John S McCaskill, Norman H Packard, Steen Rasmussen, Chris Adami, David G Green, Takashi Ikegami, Kunihiko Kaneko, and Thomas S Ray
-
[5]
Open problems in artificial life.Artificial life6, 4 (2000), 363–376
work page 2000
-
[6]
Christopher Berner, Greg Brockman, Brooke Chan, Vicki Cheung, Przemysław Dębiak, Christy Dennison, David Farhi, Quirin Fischer, Shariq Hashme, Chris Hesse, et al. 2019. Dota 2 with large scale deep reinforcement learning.arXiv preprint arXiv:1912.06680(2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[7]
James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Chris Leary, Dougal Maclaurin, George Necula, Adam Paszke, Jake VanderPlas, Skye Wanderman-Milne, and Qiao Zhang. 2018. JAX: composable transformations of Python+NumPy programs
work page 2018
-
[8]
Loïc Brevault and Mathieu Balesdent. 2024. Bayesian Quality-Diversity ap- proaches for constrained optimization problems with mixed continuous, discrete and categorical variables.Engineering Applications of Artificial Intelligence133 (2024), 108118
work page 2024
-
[9]
Estelle Chigot and Dennis G Wilson. 2022. Coevolution of neural networks for agents and environments. InProceedings of the Genetic and Evolutionary Computation Conference Companion. 2306–2309
work page 2022
-
[10]
Antoine Cully, Jeff Clune, Danesh Tarapore, and Jean-Baptiste Mouret. 2015. Robots that can adapt like animals.Nature521, 7553 (2015), 503–507
work page 2015
- [11]
-
[12]
Richard Dawkins and John Richard Krebs. 1979. Arms races between and within species.Proceedings of the Royal Society of London. Series B. Biological Sciences 205, 1161 (1979), 489–511
work page 1979
-
[13]
Kalyanmoy Deb and Himanshu Jain. 2013. An evolutionary many-objective opti- mization algorithm using reference-point-based nondominated sorting approach, part I: solving problems with box constraints.IEEE transactions on evolutionary computation18, 4 (2013), 577–601
work page 2013
-
[14]
Aaron Dharna, Cong Lu, and Jeff Clune. 2024. Quality-Diversity Self-Play: Open- Ended Strategy Innovation via Foundation Models. InNeurIPS 2024 Workshop on Open-World Agents
work page 2024
-
[15]
Alan Dorin and Susan Stepney. 2024. What Is Artificial Life Today, and Where Should It Go? 15 pages
work page 2024
-
[16]
Maxence Faldor, Jenny Zhang, Antoine Cully, and Jeff Clune. 2024. OMNI- EPIC: Open-endedness via Models of human Notions of Interestingness with Environments Programmed in Code. InThe Thirteenth International Conference on Learning Representations
work page 2024
-
[17]
Sevan G Ficici and Jordan B Pollack. 1998. Challenges in coevolutionary learning: Arms-race dynamics, open-endedness, and mediocre stable states. InProceedings of the sixth international conference on Artificial life. MIT Press Cambridge, MA, 238–247
work page 1998
-
[18]
Matthew C Fontaine, Scott Lee, Lisa B Soros, Fernando de Mesentier Silva, Julian Togelius, and Amy K Hoover. 2019. Mapping hearthstone deck spaces through map-elites with sliding boundaries. InProceedings of The Genetic and Evolutionary Computation Conference. 161–169
work page 2019
-
[19]
Matthew C Fontaine, Julian Togelius, Stefanos Nikolaidis, and Amy K Hoover
-
[20]
InProceedings of the 2020 genetic and evolutionary computation conference
Covariance matrix adaptation for the rapid illumination of behavior space. InProceedings of the 2020 genetic and evolutionary computation conference. 94–102
work page 2020
-
[21]
Deep Ganguli, Liane Lovitt, Jackson Kernion, Amanda Askell, Yuntao Bai, Saurav Kadavath, Ben Mann, Ethan Perez, Nicholas Schiefer, Kamal Ndousse, et al. 2022. Red teaming language models to reduce harms: Methods, scaling behaviors, and lessons learned.arXiv preprint arXiv:2209.07858(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[22]
Daniele Gravina, Ahmed Khalifa, Antonios Liapis, Julian Togelius, and Georgios N Yannakakis. 2019. Procedural content generation through quality diversity. In 2019 IEEE Conference on Games (CoG). IEEE, 1–8
work page 2019
-
[23]
Rufus Isaacs. 1999.Differential games: a mathematical theory with applications to warfare and pursuit, control and optimization. Courier Corporation
work page 1999
-
[24]
Yibin Jiang, Daniel Salley, Abhishek Sharma, Graham Keenan, Margaret Mullin, and Leroy Cronin. 2022. An artificial intelligence enabled chemical synthesis robot for exploration and optimization of nanomaterials.Science advances8, 40 (2022), eabo2626
work page 2022
- [25]
-
[26]
Joel Lehman and Kenneth O Stanley. 2011. Evolving a diversity of virtual creatures through novelty search and local competition. InProceedings of the 13th annual conference on Genetic and evolutionary computation. 211–218
work page 2011
-
[27]
Jean-Baptiste Mouret and Jeff Clune. 2015. Illuminating search spaces by mapping elites.arXiv preprint arXiv:1504.04909(2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[28]
Jean-Baptiste Mouret and Glenn Maguire. 2020. Quality diversity for multi-task optimization. InProceedings of the 2020 Genetic and Evolutionary Computation Conference. 121–129
work page 2020
-
[29]
Thai Huy Nguyen and Ngoc Hoang Luong. 2025. Diversifying Adversarial Attacks on Text-to-image Generation. InProceedings of the Genetic and Evolutionary Computation Conference Companion. 315–318
work page 2025
-
[30]
Justin K Pugh, Lisa B Soros, and Kenneth O Stanley. 2016. Quality diversity: A new frontier for evolutionary computation.Frontiers in Robotics and AI3 (2016), 40
work page 2016
-
[31]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. InInternational conference on machine learning. PmLR, 8748–8763
work page 2021
- [32]
-
[33]
Raparthy, Andrei Lupu, Eric Hambro, Aram H
Mikayel Samvelyan, S. Raparthy, Andrei Lupu, Eric Hambro, Aram H. Markosyan, Manish Bhatt, Yuning Mao, Minqi Jiang, Jack Parker-Holder, Jakob Foerster, Tim Rocktaschel, and Roberta Raileanu. 2024. Rainbow Teaming: Open-Ended Generation of Diverse Adversarial Prompts.ArXivabs/2402.16822 (2024). https: //api.semanticscholar.org/CorpusId:268031888
-
[34]
David Silver, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou, Aja Huang, Arthur Guez, Thomas Hubert, Lucas Baker, Matthew Lai, Adrian Bolton, et al. 2017. Mastering the game of go without human knowledge.nature550, 7676 (2017), 354–359
work page 2017
-
[35]
Kirby Steckel and Jacob Schrum. 2021. Illuminating the space of beatable lode runner levels produced by various generative adversarial networks. InProceedings of the genetic and evolutionary computation conference companion. 111–112
work page 2021
-
[36]
Oriol Vinyals, Igor Babuschkin, Wojciech M Czarnecki, Michaël Mathieu, An- drew Dudzik, Junyoung Chung, David H Choi, Richard Powell, Timo Ewalds, Petko Georgiev, et al. 2019. Grandmaster level in StarCraft II using multi-agent reinforcement learning.nature575, 7782 (2019), 350–354
work page 2019
-
[37]
Rui Wang, Joel Lehman, Jeff Clune, and Kenneth O Stanley. 2019. Poet: open- ended coevolution of environments and their optimized solutions. InProceedings of the Genetic and Evolutionary Computation Conference. 142–151. Preprint, submitted to Gecco ’26, in January 2026 Anne et al
work page 2019
-
[38]
Rui Wang, Joel Lehman, Aditya Rawal, Jiale Zhi, Yulun Li, Jeffrey Clune, and Kenneth Stanley. 2020. Enhanced poet: Open-ended reinforcement learning through unbounded invention of learning challenges and their solutions. In International conference on machine learning. PMLR, 9940–9951
work page 2020
- [39]
- [40]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.