Faster Cache-Efficient Pattern Matching for Deterministic Wheeler Pangenome Graphs
Pith reviewed 2026-07-03 03:58 UTC · model grok-4.3
The pith
A cache-friendly index for Wheeler DFAs reduces I/O in pattern matching by interleaving binary search with sequential automaton scans.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that its new data structure for Wheeler DFAs, by interleaving a binary search with fast sequential scans of the automaton, reduces the number of I/O operations below the pattern length bound of backward search, resulting in up to 500 times faster pattern matching while using at most 15 times the space.
What carries the argument
The interleaving of binary search and sequential scans on the Wheeler DFA, analogous to suffix array search.
If this is right
- The new structure can process each pattern character in under 3 ns on tested graphs.
- It achieves speedups of up to 500 times over backward search.
- Space usage increases by at most a factor of 15 compared to the BWT-based index.
- This approach maintains correctness for pattern matching on Wheeler DFAs while improving cache efficiency.
Where Pith is reading between the lines
- Such a method might extend to other classes of automata beyond Wheeler DFAs if similar structural properties hold.
- Deployments with memory constraints may need to balance the space-time tradeoff based on available hardware.
- Future work could test the method on synthetic graphs to see if speedups persist without real-world structure.
Load-bearing premise
The observed performance gains on the specific real-world Wheeler pangenome graphs will generalize to other graphs and workloads.
What would settle it
Running the algorithm on a Wheeler DFA where the number of I/O operations per pattern character exceeds that of backward search would falsify the efficiency claim.
Figures
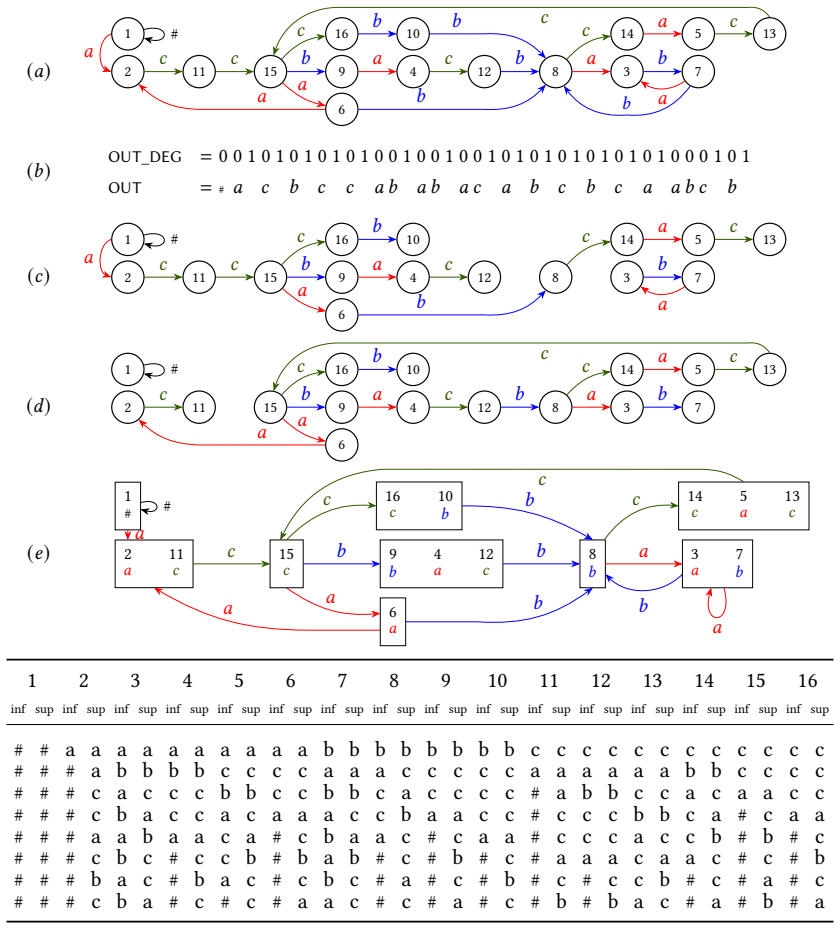
read the original abstract
Pattern matching on strings is regarded as one of the core operations in computer science. Although researchers proposed several solutions to this problem, some of the most elegant and widely used approaches are based on the renowned Burrows-Wheeler transform (BWT). The success of the BWT lies in its pattern matching algorithm known as backward search, which is not only near-optimal in the RAM model, but also runs directly on a compressed representation of the input string. More recently, the backward search has been generalized to Wheeler deterministic finite automata (DFAs), a subclass of standard DFAs, without losing its near-optimal time efficiency. Similarly to the case of strings, this pattern matching algorithm for Wheeler DFAs has found applications in bioinformatics, where researchers have shown that specific pangenome graphs of human chromosomes can be transformed into Wheeler DFAs and consequently indexed using this strategy. However, this BWT-based index on Wheeler DFAs inherited a significant drawback from the original backward search, namely the high number of I/O operations triggered during the algorithm execution, which are in the worst-case lower-bounded by the length of the pattern. In this paper, we address this limitation by proposing the first cache-friendly algorithm specifically designed for Wheeler DFAs. Our new data structure reduces the number of I/O operations by employing a strategy analogous to the suffix array: it interleaves a binary search with fast sequential scans of the automaton. We empirically validate this new indexing strategy by running our algorithm on real-world Wheeler pangenome graphs. We show that while our data structure can use up to 15 times the space required by the backward search, it can also be 500 times faster and able to process a single character of the pattern in less than 3 ns.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a cache-efficient data structure for pattern matching on deterministic Wheeler DFAs arising from pangenome graphs. It replaces the standard backward search with an approach that interleaves binary search over the automaton with fast sequential scans, drawing an analogy to the suffix array. The construction is evaluated empirically on real-world Wheeler pangenome graphs derived from human chromosomes, reporting up to 15 imes space overhead relative to backward search but up to 500 imes speedup and sub-3 ns per character query time.
Significance. If the reported speedups prove robust, the work would offer a practical improvement for I/O-bound pattern matching in pangenomics. The empirical validation on concrete real-world graphs is a positive feature, and the suffix-array analogy is a clean conceptual contribution. However, the absence of any worst-case I/O analysis or external-memory bounds limits the result's theoretical significance and makes generalization beyond the tested instances uncertain.
major comments (2)
- [Abstract] Abstract and experimental evaluation section: the headline claims of 500 imes speedup and <3 ns per character are stated without any description of baselines, hardware platform, graph sizes, number of queries, statistical aggregation, or reproducibility details. This directly affects verifiability of the central performance claim.
- [Theoretical analysis] Theoretical analysis (throughout, especially any section presenting the data structure): no worst-case bound on I/O operations, cache-miss count, or external-memory complexity is derived. The reduction in I/O is asserted only via the binary-search-plus-scan strategy and demonstrated solely on specific human-chromosome pangenome graphs; without a general argument, the speedup may be instance-specific rather than a property of the construction.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the practical value of the empirical results and the suffix-array analogy. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract and experimental evaluation section: the headline claims of 500 times speedup and <3 ns per character are stated without any description of baselines, hardware platform, graph sizes, number of queries, statistical aggregation, or reproducibility details. This directly affects verifiability of the central performance claim.
Authors: We agree that additional experimental context is required for verifiability. In the revised version we will expand both the abstract and the experimental section to specify the baseline (standard backward search), the hardware platform, the sizes of the human-chromosome-derived Wheeler pangenome graphs, the number of queries, the statistical aggregation method, and reproducibility instructions. revision: yes
-
Referee: [Theoretical analysis] Theoretical analysis (throughout, especially any section presenting the data structure): no worst-case bound on I/O operations, cache-miss count, or external-memory complexity is derived. The reduction in I/O is asserted only via the binary-search-plus-scan strategy and demonstrated solely on specific human-chromosome pangenome graphs; without a general argument, the speedup may be instance-specific rather than a property of the construction.
Authors: The manuscript presents a practical algorithm whose I/O reduction is demonstrated empirically on real pangenome graphs; no worst-case I/O or external-memory analysis is provided. Cache-miss counts depend on concrete hardware parameters, which precludes simple general bounds. The binary-search-plus-scan strategy is motivated by the suffix-array analogy, but we make no claim of instance-independent worst-case guarantees. We will add a limitations paragraph discussing this point and suggesting avenues for future theoretical work. revision: partial
- Deriving a general worst-case bound on I/O operations or cache misses
Circularity Check
No circularity: novel algorithmic construction with independent empirical validation
full rationale
The paper presents a constructive algorithm that interleaves binary search with sequential automaton scans, modeled on the suffix array but defined directly via the new data structure. No equations or claims reduce by construction to fitted inputs, self-definitions, or self-citation chains. Performance numbers (500x speedup, <3 ns/char) are reported as experimental outcomes on specific graphs rather than predictions derived from the algorithm itself. The derivation chain is self-contained and does not rely on load-bearing self-citations or renamed known results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Regular languages meet prefix sorting
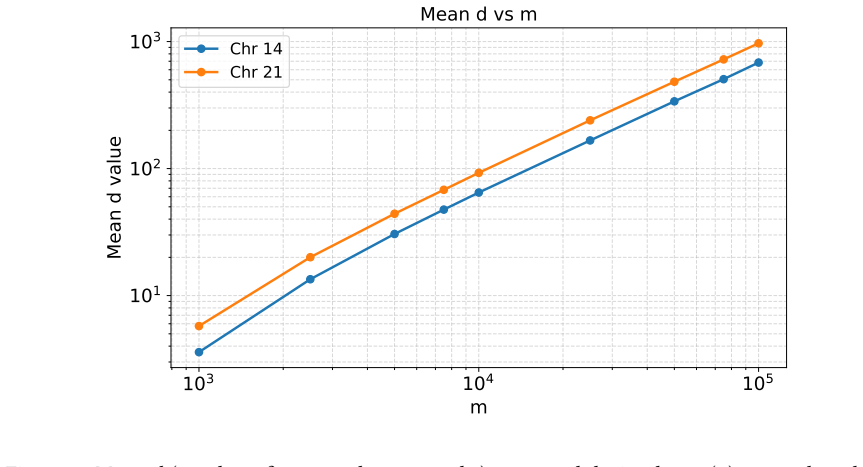
Jarno Alanko, Giovanna D’Agostino, Alberto Policriti, and Nicola Prezza. Regular languages meet prefix sorting. In Shuchi Chawla, editor,Proceedings of the 2020 ACM-SIAM Symposium 13 103 104 105 m 101 102 103 Mean d value Mean d vs m Chr 14 Chr 21 Figure 2: Mean 𝑑 (number of traversed unary paths) measured during locate( 𝛼) versus length 𝑚 (log-log scale)...
work page doi:10.1137/1.9781611975994.55doi:10.1137/1.9781611975994.55 2020
-
[2]
Encoding co-lex orders of finite-state automata in linear space
Ruben Becker, Nicola Cotumaccio, Sung-Hwan Kim, Nicola Prezza, and Carlo Tosoni. Encoding co-lex orders of finite-state automata in linear space. In Paola Bonizzoni and Veli Mäkinen, editors,36th Annual Symposium on Combinatorial Pattern Matching, CPM 2025, Milan, Italy, June 17-19, 2025, LIPIcs, pages 15:1–15:17. Schloss Dagstuhl - Leibniz-Zentrum für In...
work page doi:10.4230/lipics.cpm.2025.15doi:10.4230/lipics.cpm.2025.15 2025
-
[3]
Optimal lower and upper bounds for representing sequences.ACM Trans
Djamal Belazzougui and Gonzalo Navarro. Optimal lower and upper bounds for representing sequences.ACM Trans. Algorithms, 11(4):31:1–31:21, 2015. doi:10.1145/2629339doi:10.1145/2629339
-
[4]
Michael Burrows and David J. Wheeler. A block-sorting lossless data compres- sion algorithm. Technical Report 124, Digital Equipment Corporation, 1994. URL: https://www.hp.com/hpinfo/ex-labs/research/src/digital_src_research_report_1994_124.pdfhttps://www.hp.com/hpinfo/ex-labs/research/src/digital_src_research_report_1994_124.pdf
1994
-
[5]
Phd thesis, University of Waterloo, 1996
David Clark.Compact Pat Trees. Phd thesis, University of Waterloo, 1996. Section 2.2.2. URL: http://www.nlc-bnc.ca/obj/s4/f2/dsk3/ftp04/nq21335.pdfhttp://www.nlc-bnc.ca/obj/s4/f2/dsk3/ftp04/nq21335.pdf
1996
-
[6]
The Computational Pan-Genomics Consortium. Computational pan-genomics: status, promises and challenges.Briefings in Bioinformatics, 19(1):118–135, 01 2018. doi:10.1093/bib/bbw089doi:10.1093/bib/bbw089
-
[7]
Computing matching statistics on wheeler dfas
Alessio Conte, Nicola Cotumaccio, Travis Gagie, Giovanni Manzini, Nicola Prezza, and Marinella Sciortino. Computing matching statistics on wheeler dfas. In2023 Data Compression Conference (DCC), pages 150–159, 2023. doi:10.1109/DCC55655.2023.00023doi:10.1109/DCC55655.2023.00023
work page doi:10.1109/dcc55655.2023.00023doi:10.1109/dcc55655.2023.00023 2023
-
[8]
Massimo Equi, Veli Mäkinen, and Alexandru I. Tomescu. Graphs cannot be indexed in polynomial time for sub-quadratic time string matching, unless SETH fails. In Tomás Bures, Riccardo Dondi, Johann Gamper, Giovanna Guerrini, Tomasz Jurdzinski, Claus Pahl, Florian Sikora, and Prudence W. H. Wong, editors,SOFSEM 2021: Theory and Practice of Computer Science -...
-
[9]
Massimo Equi, Veli Mäkinen, Alexandru I. Tomescu, and Roberto Grossi. On the com- plexity of string matching for graphs.ACM Trans. Algorithms, 19(3):21:1–21:25, 2023. doi:10.1145/3588334doi:10.1145/3588334
-
[10]
Cambridge University Press, 2023
Paolo Ferragina.Pearls of Algorithm Engineering. Cambridge University Press, 2023. doi:10.1017/9781009128933doi:10.1017/9781009128933
work page doi:10.1017/9781009128933doi:10.1017/9781009128933 2023
-
[11]
Paolo Ferragina and Giovanni Manzini. Indexing compressed text.J. ACM, 52(4):552–581, 2005. doi:10.1145/1082036.1082039doi:10.1145/1082036.1082039
work page doi:10.1145/1082036.1082039doi:10.1145/1082036.1082039 2005
-
[12]
Wheeler graphs: A framework for bwt-based data structures.Theor
Travis Gagie, Giovanni Manzini, and Jouni Sirén. Wheeler graphs: A framework for bwt-based data structures.Theor. Comput. Sci., 698:67–78, 2017. doi:10.1016/J.TCS.2017.06.016doi:10.1016/J.TCS.2017.06.016
work page doi:10.1016/j.tcs.2017.06.016doi:10.1016/j.tcs.2017.06.016 2017
-
[13]
Daniel Gibney and Sharma V. Thankachan. On the hardness and inapproximability of recognizing wheeler graphs. In Michael A. Bender, Ola Svensson, and Grzegorz Herman, editors,27th Annual European Symposium on Algorithms, ESA 2019, Munich/Garching, Germany, September 9-11, 2019, LIPIcs, pages 51:1–51:16. Schloss Dagstuhl - Leibniz-Zentrum für Informatik, 20...
work page doi:10.4230/lipics.esa.2019.51doi:10.4230/lipics.esa.2019.51 2019
-
[14]
Compressed suffix arrays and suffix trees with applica- tions to text indexing and string matching (extended abstract)
Roberto Grossi and Jeffrey Scott Vitter. Compressed suffix arrays and suffix trees with applica- tions to text indexing and string matching (extended abstract). InProceedings of the Thirty-Second Annual ACM Symposium on Theory of Computing, STOC ’00, page 397–406, New York, NY, USA,
-
[15]
doi:10.1145/335305.335351doi:10.1145/335305.335351
Association for Computing Machinery. doi:10.1145/335305.335351doi:10.1145/335305.335351
work page doi:10.1145/335305.335351doi:10.1145/335305.335351
-
[16]
Space-efficient static trees and graphs
Guy Jacobson. Space-efficient static trees and graphs. In30th Annual Symposium on Foundations of Computer Science, Research Triangle Park, North Carolina, USA, 30 October - 1 November 1989, pages 549–554. IEEE Computer Society, 1989. doi:10.1109/SFCS.1989.63533doi:10.1109/SFCS.1989.63533
work page doi:10.1109/sfcs.1989.63533doi:10.1109/sfcs.1989.63533 1989
-
[17]
Faster Prefix-Sorting Algorithms for Deterministic Finite Automata
Sung-Hwan Kim, Francisco Olivares, and Nicola Prezza. Faster Prefix-Sorting Algorithms for Deterministic Finite Automata. In Laurent Bulteau and Zsuzsanna Lipták, editors,34th Annual Symposium on Combinatorial Pattern Matching (CPM 2023), volume 259 ofLeibniz International Proceedings in Informatics (LIPIcs), pages 16:1–16:16, Dagstuhl, Germany, 2023. Sch...
work page doi:10.4230/lipics.cpm.2023.16doi:10.4230/lipics.cpm.2023.16 2023
-
[18]
Fast pattern matching in strings
Donald E Knuth, James H Morris, Jr, and Vaughan R Pratt. Fast pattern matching in strings. SIAM journal on computing, 6(2):323–350, 1977
1977
-
[19]
Salzberg
Ben Langmead, Cole Trapnell, Mihai Pop, and Steven L. Salzberg. Ultrafast and memory- efficient alignment of short dna sequences to the human genome.Genome Biology, 10(3):R25,
-
[20]
doi:10.1186/gb-2009-10-3-r25doi:10.1186/gb-2009-10-3-r25
work page doi:10.1186/gb-2009-10-3-r25doi:10.1186/gb-2009-10-3-r25 2009
-
[21]
Heng Li and Nils Homer. A survey of sequence alignment algorithms for next-generation sequencing.Briefings Bioinform., 11(5):473–483, 2010. doi:10.1093/BIB/BBQ015doi:10.1093/BIB/BBQ015
-
[22]
Suffix arrays: a new method for on-line string searches
Udi Manber and Gene Myers. Suffix arrays: a new method for on-line string searches. In Proceedings of the First Annual ACM-SIAM Symposium on Discrete Algorithms, SODA ’90, page 319–327, USA, 1990. Society for Industrial and Applied Mathematics
1990
-
[23]
Edward M. McCreight. A space-economical suffix tree construction algorithm.J. ACM, 23(2):262– 272, 1976. doi:10.1145/321941.321946doi:10.1145/321941.321946
work page doi:10.1145/321941.321946doi:10.1145/321941.321946 1976
-
[24]
Indexing graphs for path queries with appli- cations in genome research.IEEE ACM Trans
Jouni Sirén, Niko Välimäki, and Veli Mäkinen. Indexing graphs for path queries with appli- cations in genome research.IEEE ACM Trans. Comput. Biol. Bioinform., 11(2):375–388, 2014. doi:10.1109/TCBB.2013.2297101doi:10.1109/TCBB.2013.2297101
work page doi:10.1109/tcbb.2013.2297101doi:10.1109/tcbb.2013.2297101 2014
-
[25]
Haplotype-aware graph indexes.Bioinformatics, 36(2):400–407, 01 2020
Jouni Sirén, Erik Garrison, Adam M Novak, Benedict Paten, and Richard Durbin. Haplotype-aware graph indexes.Bioinformatics, 36(2):400–407, 01 2020. doi:10.1093/bioinformatics/btz575doi:10.1093/bioinformatics/btz575
work page doi:10.1093/bioinformatics/btz575doi:10.1093/bioinformatics/btz575 2020
-
[26]
A data structure for dynamic trees.J
Daniel Dominic Sleator and Robert Endre Tarjan. A data structure for dynamic trees.J. Comput. Syst. Sci., 26(3):362–391, 1983. doi:10.1016/0022-0000(83)90006-5doi:10.1016/0022-0000(83)90006-5
work page doi:10.1016/0022-0000(83)90006-5doi:10.1016/0022-0000(83)90006-5 1983
-
[27]
DFAs encoding the finnish subset of frequent mutations from dbSNP (GCSA’s experimental data)
University of Helsinki. DFAs encoding the finnish subset of frequent mutations from dbSNP (GCSA’s experimental data). https://www.cs.helsinki.fi/group/gsa/1000gen-FIN-WholeGenome/https://www.cs.helsinki.fi/group/gsa/1000gen-FIN-WholeGenome/, 2014. Accessed: 2026-02-04
2014
-
[28]
Linear pattern matching algorithms
Peter Weiner. Linear pattern matching algorithms. In14th Annual Symposium on Switching and Automata Theory, Iowa City, Iowa, USA, October 15-17, 1973, pages 1–11. IEEE Computer Society,
1973
-
[29]
doi:10.1109/SWAT.1973.13doi:10.1109/SWAT.1973.13. 16
work page doi:10.1109/swat.1973.13doi:10.1109/swat.1973.13 1973
-
[30]
A new algorithm for optimal 2-constraint satisfaction and its implications.Theor
Ryan Williams. A new algorithm for optimal 2-constraint satisfaction and its implications.Theor. Comput. Sci., 348(2-3):357–365, 2005. doi:10.1016/J.TCS.2005.09.023doi:10.1016/J.TCS.2005.09.023. 17
work page doi:10.1016/j.tcs.2005.09.023doi:10.1016/j.tcs.2005.09.023 2005
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.