GigaSpeechBench: A Real-World Multilingual Speech-to-Text Benchmark
Pith reviewed 2026-06-30 08:23 UTC · model grok-4.3
The pith
GigaSpeechBench introduces 680 hours of annotated real-world speech to show that current ASR models degrade sharply on low-resource languages, dialects, accents, and age variations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Modern ASR systems achieve low error rates on high-resource benchmarks but overestimate real-world robustness because existing evaluations address challenges in isolation; GigaSpeechBench fills the gap with a unified 680-hour multilingual benchmark covering low-resource languages from the Middle East and Southeast Asia, Chinese dialects, English accents, dense terminology in 12 domains, and older adult and child speech, plus human-annotated translations for AST, and shows that foundation models and commercial APIs exhibit significant performance degradation in these settings.
What carries the argument
GigaSpeechBench, a 680-hour human-annotated multilingual ASR and AST benchmark divided into five modules that combine low-resource languages, dialects, accents, terminology, and age-specific speech in a single evaluation suite.
If this is right
- Leading foundation models and commercial APIs exhibit significant performance degradation on the benchmark's challenging conditions.
- Current high-resource benchmarks leave critical evaluation blind spots for real-world speech variations.
- The benchmark enables joint ASR and AST assessment through provided Chinese and English translations for 11 languages.
- Regions representing over one billion under-evaluated speakers now have a dedicated test set for multilingual speech systems.
- Performance estimates from isolated challenge tests do not reflect robustness across combined domain, accent, dialect, and age factors.
Where Pith is reading between the lines
- Model developers could use the benchmark's modular structure to diagnose which variation type causes the largest drops and prioritize data collection accordingly.
- The multi-module design could be extended to test interactions between factors, such as accented speech containing domain terminology.
- Policymakers assessing speech technology accessibility might apply similar coverage criteria to ensure systems serve diverse age and dialect groups.
- Similar benchmark construction methods could apply to other sequence tasks like machine translation or audio event detection.
Load-bearing premise
The 680 hours of human-annotated speech accurately and representatively capture the targeted real-world variations without substantial annotation errors or selection biases.
What would settle it
Collect and annotate a fresh 100-hour subset matching the same language, dialect, accent, domain, and age categories; if model error rates on this subset match high-resource benchmark levels rather than showing degradation, the claimed blind spots would not hold.
Figures
read the original abstract
While modern ASR systems achieve low error rates on high-resource benchmarks, such performance often overestimates real-world robustness. Existing evaluations address challenges in isolation, lacking a unified benchmark for domain terminology, age variation, dialects, accents, and low-resource languages, particularly across the Middle East and Southeast Asia, representing over one billion under-evaluated speakers. To address this gap, we introduce GigaSpeechBench, a comprehensive multilingual and multidimensional in-the-wild ASR & AST benchmark comprising 680 hours of human-annotated speech. It features five modules: (1) 12 low-resource Middle Eastern and Southeast Asian languages, plus challenging Japanese and Korean; (2) 6 Chinese dialects; (3) 6 English accents; (4) dense terminology across 12 vertical domains for Chinese and English; and (5) older adult and child speech. We further provide human-annotated Chinese and English translations for 11 languages to support AST evaluation. Extensive evaluations of leading foundation models and commercial APIs reveal significant performance degradation in these challenging settings, exposing critical evaluation blind spots.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GigaSpeechBench, a 680-hour human-annotated multilingual ASR/AST benchmark with five modules covering 12 low-resource Middle Eastern/Southeast Asian languages (plus Japanese/Korean), 6 Chinese dialects, 6 English accents, dense terminology in 12 domains (Chinese/English), and older-adult/child speech, plus human translations for 11 languages. Extensive evaluations of foundation models and commercial APIs are reported to show substantial performance degradation relative to high-resource settings, exposing evaluation blind spots.
Significance. If the annotations can be verified as accurate and representative, the benchmark would supply a much-needed unified testbed for real-world robustness in multilingual and demographically diverse speech, addressing coverage gaps for over a billion speakers and potentially informing more reliable model development and evaluation practices.
major comments (3)
- [Abstract] Abstract: the central claim of 'significant performance degradation' exposing 'critical evaluation blind spots' rests on the 680 h of human-annotated data being both accurate and representative; however, the abstract (and, per the manuscript's data description) supplies no annotation protocol, inter-annotator agreement statistics, or verification steps for the 12 low-resource languages, 6 Chinese dialects, or age-specific modules.
- [Data construction section] Data construction section: without reported annotation error rates, selection-bias controls, or quality-assurance procedures for low-resource and dialectal speech, it remains possible that a non-negligible fraction of the observed WER/CER increases is attributable to label noise rather than model limitations, directly undermining the headline degradation claim.
- [Evaluation/results section] Evaluation/results section: the manuscript reports performance drops across models and modules but provides no statistical significance tests, confidence intervals, or error analysis that would allow readers to distinguish systematic degradation from sampling variability or annotation artifacts.
minor comments (1)
- [Abstract] Abstract: the per-module hour counts are not broken out, making it difficult to assess the scale of coverage for each challenging dimension.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater transparency on annotation quality and statistical analysis. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of 'significant performance degradation' exposing 'critical evaluation blind spots' rests on the 680 h of human-annotated data being both accurate and representative; however, the abstract (and, per the manuscript's data description) supplies no annotation protocol, inter-annotator agreement statistics, or verification steps for the 12 low-resource languages, 6 Chinese dialects, or age-specific modules.
Authors: We agree the abstract is too concise on this point. The data construction section describes sourcing and native-speaker annotation but lacks explicit protocol details and IAA figures. In revision we will add a sentence to the abstract referencing the annotation process and expand the data section with a dedicated protocol subsection, reporting IAA where multiple annotators were used. revision: yes
-
Referee: [Data construction section] Data construction section: without reported annotation error rates, selection-bias controls, or quality-assurance procedures for low-resource and dialectal speech, it remains possible that a non-negligible fraction of the observed WER/CER increases is attributable to label noise rather than model limitations, directly undermining the headline degradation claim.
Authors: This concern is valid. While the manuscript notes public sources and human annotation with spot reviews, it does not quantify error rates or selection controls. We will revise the data construction section to detail all quality-assurance steps performed and any available error estimates, while acknowledging the limitation that full error rates are not available for every low-resource module. The cross-model consistency of drops still supports the core claim. revision: partial
-
Referee: [Evaluation/results section] Evaluation/results section: the manuscript reports performance drops across models and modules but provides no statistical significance tests, confidence intervals, or error analysis that would allow readers to distinguish systematic degradation from sampling variability or annotation artifacts.
Authors: We accept this criticism. The revised evaluation section will add bootstrap confidence intervals, paired significance tests on the reported WER/CER differences, and a brief error analysis to help separate systematic effects from variability. revision: yes
Circularity Check
No circularity: purely empirical benchmark with no derivations or fitted predictions
full rationale
This paper constructs and releases a 680-hour multilingual ASR/AST benchmark and reports model evaluations on it. There are no equations, no parameter fitting, no predictions derived from inputs, and no load-bearing self-citations that reduce claims to prior author work by definition. The central results are direct empirical measurements (WER/CER on held-out annotated speech), which are falsifiable against external data and do not rely on any self-referential construction. The derivation chain is empty; the work is self-contained as a data release and evaluation study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Gpt-4o system card.Preprint, arXiv:2410.21276. Deepak Babu Piskala. 2025. Profasr-bench: A benchmark for context-conditioned asr in high-stakes professional speech.arXiv preprint arXiv:2512.23686. Maja Popovi´c. 2017. chrF++: words helping character n-grams. InProceedings of the Second Conference on Machine Translation, pages 612–618, Copenhagen, Denmark....
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
InInternational conference on machine learning, pages 28492–28518
Robust speech recognition via large-scale weak supervision. InInternational conference on machine learning, pages 28492–28518. PMLR. Ricardo Rei, Craig Stewart, Ana C Farinha, and Alon Lavie. 2020. Comet: A neural framework for mt evaluation.Preprint, arXiv:2009.09025. Ramon Sanabria, Nikolay Bogoychev, Nina Markl, Andrea Carmantini, Ondrej Klejch, and Pe...
-
[3]
X-LANCE Lab, MoE Key Lab of Artificial Intelligence, Jiangsu Key Lab of Language Computing, Shanghai Jiao Tong University
-
[4]
Shanghai Innovation Institute
-
[5]
Audio, Speech and Language Processing Group, School of Computer Science, Northwestern Polytechnical University
-
[6]
Nanyang Technological University
-
[7]
Institute of Automation, Chinese Academy of Sciences
-
[8]
University of Chinese Academy of Sciences
-
[9]
University of Illinois Urbana-Champaign, Urbana
-
[10]
The Chinese University of Hong Kong, Shenzhen
-
[11]
Fudan University, Shanghai, China
-
[12]
State Key Laboratory of Complex & Critical Software Environment
-
[13]
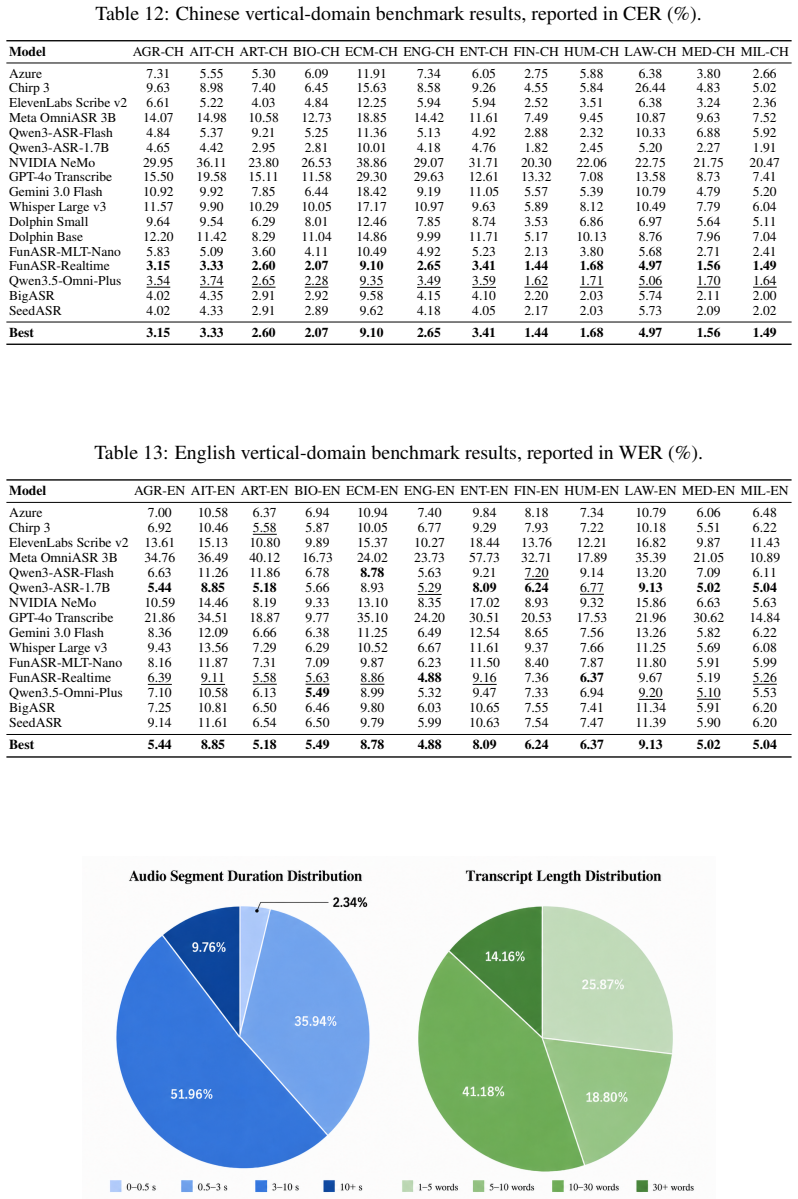
Overall, the data are concentrated in short-to-medium utterances, with the vast majority of audio segments falling between 0.5 and 10 seconds
SpeechColab B Segment Duration and Text Length Statistics Figure 2 shows the distributions of audio segment duration and reference text length after V AD and manual transcription. Overall, the data are concentrated in short-to-medium utterances, with the vast majority of audio segments falling between 0.5 and 10 seconds. This pattern is consistent with sp...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.