An Ultra-Low-Bitrate Neural Speech Codec with Plain-to-Pseudo Synergistic Vector Quantization
Pith reviewed 2026-06-27 23:54 UTC · model grok-4.3
The pith
P2PSynCodec transmits tokens from one plain vector quantizer and predicts the rest to match 2 kbps speech quality at 0.5 kbps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
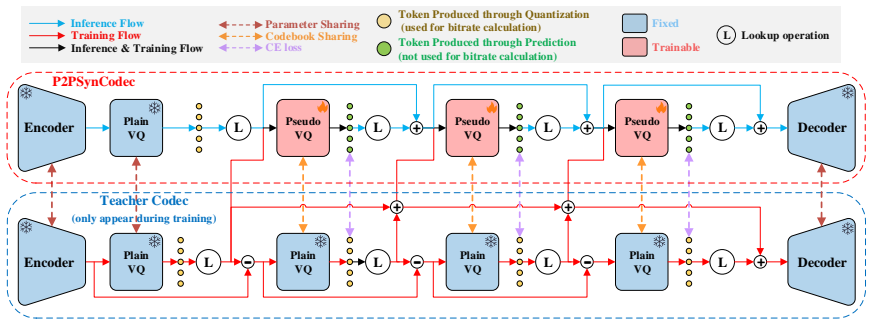
P2PSynCodec with its plain-to-pseudo synergistic vector quantizer (P2PSVQ) consists of one plain VQ that produces basic tokens by quantization and multiple pseudo VQs that generate auxiliary tokens by neural prediction at zero transmitted bitrate; speech is decoded from the combination of the transmitted plain-VQ tokens and the predicted pseudo-VQ tokens, yielding reconstruction quality comparable to competing codecs at 2.0 kbps while operating at only 0.5 kbps.
What carries the argument
The plain-to-pseudo synergistic vector quantizer (P2PSVQ), which separates one transmitted plain VQ from multiple zero-bitrate pseudo VQs whose tokens are generated by neural prediction rather than quantization.
If this is right
- Only the bitrate of a single VQ layer needs to be transmitted instead of the full stack of residual layers.
- Later residual quantizers in conventional RVQ can be replaced by predictors without loss of the quality they normally provide.
- Speech reconstruction at 0.5 kbps becomes feasible at quality levels previously associated with 2.0 kbps codecs.
- The same plain-plus-pseudo structure can be inserted into other RVQ-based neural codecs to lower their operating bitrate.
Where Pith is reading between the lines
- The method implies that hierarchical representations in audio codecs can be made asymmetric, with only the first layer requiring explicit transmission.
- Predictive substitution for residual quantization may extend to other modalities where successive refinement layers exhibit diminishing returns.
- Accuracy requirements on the neural predictors set a practical limit on how many pseudo layers can be added before prediction error dominates.
- The design invites direct comparison between prediction error and quantization error at each pseudo stage to quantify the bitrate-quality trade-off.
Load-bearing premise
The neural predictors can produce auxiliary tokens whose contribution to perceptual quality is close enough to the contribution of actual residual quantizers that overall quality stays comparable when bitrate is cut from 2 kbps to 0.5 kbps.
What would settle it
An ablation that replaces the predicted pseudo-VQ tokens with zeros or random values and measures whether objective or subjective quality at 0.5 kbps falls below the level reported for the full P2PSynCodec system.
Figures

read the original abstract
Most neural speech codecs use residual vector quantization (RVQ), in which later VQs contribute less but consume the same bitrate, leading to inefficiency. We propose P2PSynCodec, an ultra-low-bitrate neural speech codec with a plain-to-pseudo synergistic vector quantizer (P2PSVQ). P2PSVQ consists of one plain VQ and multiple pseudo VQs. The plain VQ produces basic tokens by quantization, while the pseudo VQs generate auxiliary tokens by neural prediction and incur zero transmitted bitrate. Thus, speech is decoded from the plain-VQ tokens together with predicted pseudo-VQ tokens, greatly reducing bitrate. Experiments show that P2PSynCodec achieves speech reconstruction quality comparable to competing codecs at 2.0 kbps while operating at only 0.5 kbps, demonstrating high efficiency for ultra-low-bitrate speech coding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes P2PSynCodec, a neural speech codec that replaces conventional residual vector quantization (RVQ) with a plain-to-pseudo synergistic vector quantizer (P2PSVQ). P2PSVQ uses a single plain VQ whose tokens are transmitted and multiple pseudo VQs whose auxiliary tokens are generated by neural predictors conditioned on the plain-VQ output; the pseudo tokens incur zero transmitted bitrate. The central claim is that this architecture achieves speech reconstruction quality comparable to competing neural codecs at 2.0 kbps while operating at only 0.5 kbps.
Significance. If the central claim is substantiated by rigorous listening tests and objective metrics, the work would represent a meaningful advance in ultra-low-bitrate neural speech coding by removing the transmission cost of residual quantizers through learned prediction. This could enable more efficient codecs for bandwidth-limited applications while preserving perceptual quality.
major comments (2)
- [Abstract] Abstract: the claim that reconstruction quality at 0.5 kbps is comparable to 2.0 kbps codecs is load-bearing for the paper's contribution, yet the abstract (and the provided description) supplies no quantitative results, error bars, dataset details, or listening-test protocol, preventing verification of the equivalence.
- [Method / P2PSVQ] P2PSVQ description (method section): the assumption that neural predictors, conditioned only on plain-VQ tokens, can generate auxiliary tokens whose effect on the decoder matches the contribution of ~1.5 kbps of true residual VQ is not supported by ablation studies or error analysis; residual quantization encodes fine spectral/temporal details that are only weakly predictable from coarse tokens, and any systematic mismatch (e.g., unvoiced segments) would undermine the bitrate-quality equivalence.
minor comments (1)
- [Notation / Figure 1] The notation distinguishing plain VQ from pseudo VQ tokens could be made more explicit, e.g., by adding an equation or flowchart showing the conditioning and zero-bitrate path.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and revise the manuscript to strengthen the presentation of results and supporting analyses.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that reconstruction quality at 0.5 kbps is comparable to 2.0 kbps codecs is load-bearing for the paper's contribution, yet the abstract (and the provided description) supplies no quantitative results, error bars, dataset details, or listening-test protocol, preventing verification of the equivalence.
Authors: We agree that the abstract should include supporting quantitative details. In the revised version we will expand the abstract to report key objective metrics (PESQ, STOI) with confidence intervals, the evaluation datasets, and a concise description of the listening-test protocol, thereby allowing direct verification of the claimed quality equivalence. revision: yes
-
Referee: [Method / P2PSVQ] P2PSVQ description (method section): the assumption that neural predictors, conditioned only on plain-VQ tokens, can generate auxiliary tokens whose effect on the decoder matches the contribution of ~1.5 kbps of true residual VQ is not supported by ablation studies or error analysis; residual quantization encodes fine spectral/temporal details that are only weakly predictable from coarse tokens, and any systematic mismatch (e.g., unvoiced segments) would undermine the bitrate-quality equivalence.
Authors: We acknowledge the need for explicit validation of the predictors. The revised manuscript will add ablation experiments that isolate the contribution of the pseudo-VQ tokens and provide error analysis stratified by speech type (including unvoiced segments) to quantify any systematic mismatches and confirm that the learned prediction approximates the effect of the omitted residual quantizers. revision: yes
Circularity Check
No circularity detected from provided text
full rationale
The abstract and visible description introduce P2PSVQ as a new architecture separating plain VQ (transmitted) from pseudo VQs (predicted, zero bitrate) without any equations, fitted parameters, or self-citations that reduce the claimed bitrate savings or quality equivalence to inputs by construction. No load-bearing steps invoke prior author work as uniqueness theorems or smuggle ansatzes. The central claim rests on experimental comparison to competing codecs, which is externally falsifiable and does not reduce to self-definition or renaming. This is the normal case of a self-contained proposal.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction A speech codec compresses and reconstructs speech signals to enable efficient transmission and storage [1, 2, 3, 4]. Its core objective is to balance bitrate and reconstruction quality, mak- ing speech codecs essential for applications such as real-time communication, voice archiving, and remote conferencing un- der bandwidth or storage const...
-
[2]
However, waveform-domain modeling can be computa- tionally expensive and may struggle to preserve long-term spec- tral structure
and EnCodec [6] directly encode waveforms using causal convolutional networks, while DAC [7] further improves fi- delity through a non-causal backbone and enhanced quantiza- tion. However, waveform-domain modeling can be computa- tionally expensive and may struggle to preserve long-term spec- tral structure. To address this issue, MDCTCodec [8] discretize...
-
[3]
Proposed Method 2.1. Overview Fig. 1 shows an overview of the proposed P2PSynCodec. It consists of an encoder, a P2PSVQ, and a decoder, in which the quantizer is a cascaded structure of plain and pseudo VQs. At the encoding end, the encoder downsamples the input speech to produce compressed encoded representations. Subsequently, the P2PSVQ quantizes the c...
Pith/arXiv arXiv 2026
-
[4]
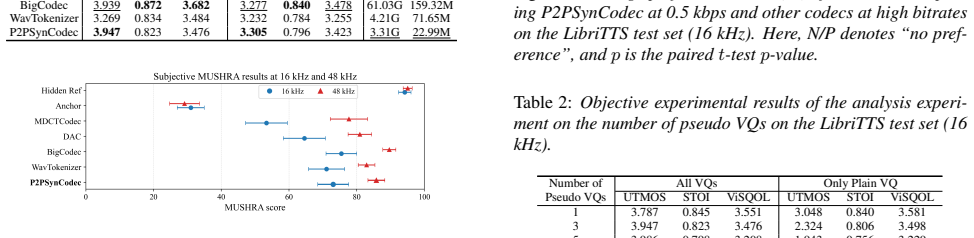
Experiments and Results 3.1. Experimental Setup Our experiments were conducted on the LibriTTS [17] and VCTK [18] datasets. For LibriTTS, with a sampling rate of 16 kHz, the training process utilized the train-clean-100 and train- clean-360 subsets, while the dev-clean and test-clean subsets were employed for validation and evaluation, respectively. As fo...
-
[5]
The plain VQ generates the transmitted tokens, while pseudo VQs predict auxiliary tokens to enrich the representation without increasing bitrate
Conclusion In this paper, we proposed P2PSynCodec, an ultra-low-bitrate neural speech codec with a plain-to-pseudo synergistic vector quantizer (P2PSVQ). The plain VQ generates the transmitted tokens, while pseudo VQs predict auxiliary tokens to enrich the representation without increasing bitrate. Trained with teacher forcing using an RVQ-based teacher c...
-
[6]
62301521
Acknowledgments This work was supported by the National Natural Science Foun- dation of China under Grant No. 62301521
-
[7]
After using this tool, the authors reviewed and edited the content as needed and take full responsibility for the final version of the manuscript
Generative AI Use Disclosure During the preparation of this manuscript, the authors used ChatGPT 5.2 to polish the language and improve the flow of the text. After using this tool, the authors reviewed and edited the content as needed and take full responsibility for the final version of the manuscript
-
[8]
A toll quality 8 kb/s speech codec for the personal communications sys- tem (pcs),
R. Salami, C. Laflamme, J.-P. Adoul, and D. Massaloux, “A toll quality 8 kb/s speech codec for the personal communications sys- tem (pcs),”IEEE Transactions on Vehicular Technology, vol. 43, no. 3, pp. 808–816, 1994
1994
-
[9]
ISO/MPEG-1 audio: A generic standard for coding of high-quality digital audio,
K. Brandenburg and G. Stoll, “ISO/MPEG-1 audio: A generic standard for coding of high-quality digital audio,”Journal of the Audio Engineering Society, vol. 42, no. 10, pp. 780–792, 1994
1994
-
[10]
Descrip- tion of ITU-t recommendation g. 729 annex a: reduced complex- ity 8 kbit/s cs-acelp codec,
R. Salami, C. Laflamme, B. Bessette, and J.-P. Adoul, “Descrip- tion of ITU-t recommendation g. 729 annex a: reduced complex- ity 8 kbit/s cs-acelp codec,” inProc. ICASSP, vol. 2. IEEE, 1997, pp. 775–778
1997
-
[11]
A comprehensive survey of voice over ip security research,
A. D. Keromytis, “A comprehensive survey of voice over ip security research,”IEEE Communications Surveys & Tutorials, vol. 14, no. 2, pp. 514–537, 2011
2011
-
[12]
SoundStream: An end-to-end neural audio codec,
N. Zeghidour, A. Luebs, A. Omran, J. Skoglund, and M. Tagliasacchi, “SoundStream: An end-to-end neural audio codec,”IEEE/ACM Transactions on Audio, Speech, and Lan- guage Processing, vol. 30, pp. 495–507, 2021
2021
-
[13]
High Fidelity Neural Audio Compression,
A. D ´efossez, J. Copet, G. Synnaeve, and Y . Adi, “High Fidelity Neural Audio Compression,”Transactions on Machine Learning Research, 2023
2023
-
[14]
High-fidelity audio compression with improved rvqgan,
R. Kumar, P. Seetharaman, A. Luebs, I. Kumar, and K. Kumar, “High-fidelity audio compression with improved rvqgan,” inProc. NIPS, vol. 36, 2024
2024
-
[15]
MDCTCodec: A lightweight MDCT-based neural audio codec towards high sampling rate and low bitrate scenarios,
X.-H. Jiang, Y . Ai, R.-C. Zheng, H.-P. Du, Y .-X. Lu, and Z.-H. Ling, “MDCTCodec: A lightweight MDCT-based neural audio codec towards high sampling rate and low bitrate scenarios,” in Proc. SLT, 2024, pp. 550–557
2024
-
[16]
One quantizer is enough: Toward a lightweight audio codec,
L. Zhai, H. Ding, C. Zhao, G. Wang, W. Zhi, W. Xiet al., “One quantizer is enough: Toward a lightweight audio codec,”arXiv preprint arXiv:2504.04949, 2025
arXiv 2025
-
[17]
Fi- nite Scalar Quantization: VQ-V AE made simple,
F. Mentzer, D. Minnen, E. Agustsson, and M. Tschannen, “Fi- nite Scalar Quantization: VQ-V AE made simple,” inProc. ICLR, 2024
2024
-
[18]
Bigcodec: Pushing the limits of low-bitrate neural speech codec,
D. Xin, X. Tan, S. Takamichi, and H. Saruwatari, “Bigcodec: Pushing the limits of low-bitrate neural speech codec,”arXiv preprint arXiv:2409.05377, 2024
arXiv 2024
-
[19]
Wavtokenizer: an efficient acoustic discrete codec tokenizer for audio language modeling,
S. Ji, Z. Jiang, W. Wang, Y . Chen, M. Fang, J. Zuo, Q. Yang, X. Cheng, Z. Wang, R. Liet al., “Wavtokenizer: an efficient acoustic discrete codec tokenizer for audio language modeling,” inProc. ICLR, 2025
2025
-
[20]
ConvNeXt v2: Co-designing and scaling convnets with masked autoencoders,
S. Woo, S. Debnath, R. Hu, X. Chen, Z. Liu, I. S. Kweon, and S. Xie, “ConvNeXt v2: Co-designing and scaling convnets with masked autoencoders,” inProc. CVPR, 2023, pp. 16 133–16 142
2023
-
[21]
Gaussian error linear units (gelus),
D. Hendrycks and K. Gimpel, “Gaussian error linear units (gelus),”arXiv preprint arXiv:1606.08415, 2016
Pith/arXiv arXiv 2016
-
[22]
Conformer: Convolution- augmented transformer for speech recognition,
A. Gulati, J. Qin, C.-C. Chiu, N. Parmar, Y . Zhang, J. Yu, W. Han, S. Wang, Z. Zhang, Y . Wuet al., “Conformer: Convolution- augmented transformer for speech recognition,” inProc. Inter- speech, 2020, pp. 5036–5040
2020
-
[23]
Long short-term memory,
S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural computation, vol. 9, no. 8, pp. 1735–1780, 1997
1997
-
[24]
LibriTTS: A corpus derived from LibriSpeech for text-to-speech,
H. Zen, V . Dang, R. Clark, Y . Zhang, R. J. Weiss, Y . Jia, Z. Chen, and Y . Wu, “LibriTTS: A corpus derived from LibriSpeech for text-to-speech,” inProc. Interspeech, 2019, pp. 1526–1530
2019
-
[25]
Superseded- CSTR vctk corpus: English multi-speaker corpus for CSTR voice cloning toolkit,
C. Veaux, J. Yamagishi, K. MacDonaldet al., “Superseded- CSTR vctk corpus: English multi-speaker corpus for CSTR voice cloning toolkit,” 2017
2017
-
[26]
UTMOS: Utokyo-sarulab system for voiceMOS challenge 2022,
T. Saeki, D. Xin, W. Nakata, T. Koriyama, S. Takamichi, and H. Saruwatari, “UTMOS: Utokyo-sarulab system for voiceMOS challenge 2022,” inProc. Interspeech, 2022, pp. 4521–4525
2022
-
[27]
Icassp 2024 speech signal improvement challenge,
N.-C. Ristea, B. Naderi, A. Saabas, R. Cutler, S. Braun, and S. Branets, “Icassp 2024 speech signal improvement challenge,” IEEE Open Journal of Signal Processing, vol. 6, pp. 238–246, 2025
2024
-
[28]
A short- time objective intelligibility measure for time-frequency weighted noisy speech,
C. H. Taal, R. C. Hendriks, R. Heusdens, and J. Jensen, “A short- time objective intelligibility measure for time-frequency weighted noisy speech,” inProc. ICASSP, 2010, pp. 4214–4217
2010
-
[29]
ViSQOL v3: An open source production ready objec- tive speech and audio metric,
M. Chinen, F. S. Lim, J. Skoglund, N. Gureev, F. O’Gorman, and A. Hines, “ViSQOL v3: An open source production ready objec- tive speech and audio metric,” inProc. QoMEX, 2020, pp. 1–6
2020
-
[30]
The Livermore Fortran Kernels: A computer test of the numerical performance range,
F. H. McMahon, “The Livermore Fortran Kernels: A computer test of the numerical performance range,” Lawrence Livermore National Lab., CA (USA), Tech. Rep., 1986
1986
-
[31]
Method for the subjective assessment of intermediate sound quality (MUSHRA),
I. Recommendation, “Method for the subjective assessment of intermediate sound quality (MUSHRA),”ITU, BS, pp. 1543–1, 2001
2001
-
[32]
Per- ceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs,
A. W. Rix, J. G. Beerends, M. P. Hollier, and A. P. Hekstra, “Per- ceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs,” in Proc. ICASSP, vol. 2, 2001, pp. 749–752
2001
-
[33]
Perceptual objective listen- ing quality assessment (POLQA), the third generation itu-t stan- dard for end-to-end speech quality measurement part i—temporal alignment,
J. G. Beerends, C. Schmidmer, J. Berger, M. Obermann, R. Ull- mann, J. Pomy, and M. Keyhl, “Perceptual objective listen- ing quality assessment (POLQA), the third generation itu-t stan- dard for end-to-end speech quality measurement part i—temporal alignment,”journal of the audio engineering society, vol. 61, no. 6, pp. 366–384, 2013
2013
-
[34]
Speaker independence of neural vocoders and their effect on parametric resynthesis speech en- hancement,
S. Maiti and M. I. Mandel, “Speaker independence of neural vocoders and their effect on parametric resynthesis speech en- hancement,” inProc. ICASSP, 2020, pp. 206–210
2020
-
[35]
GenSE: Generative speech enhancement via language models using hier- archical modeling,
J. Yao, H. Liu, C. Chen, Y . Hu, E. Chng, and L. Xie, “GenSE: Generative speech enhancement via language models using hier- archical modeling,” inProc. ICLR, 2025
2025
-
[36]
Revise: Self-supervised speech resynthesis with visual input for universal and generalized speech regeneration,
W.-N. Hsu, T. Remez, B. Shi, J. Donley, and Y . Adi, “Revise: Self-supervised speech resynthesis with visual input for universal and generalized speech regeneration,” inProc. CVPR, 2023, pp. 18 795–18 805
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.