CoRe: Combined Rewards with Vision-Language Model Feedback for Preference-Aligned Reinforcement Learning
Pith reviewed 2026-07-03 12:25 UTC · model grok-4.3
The pith
CoRe combines formal and residual rewards optimized by vision-language models to create preference-aligned policies for robotic reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
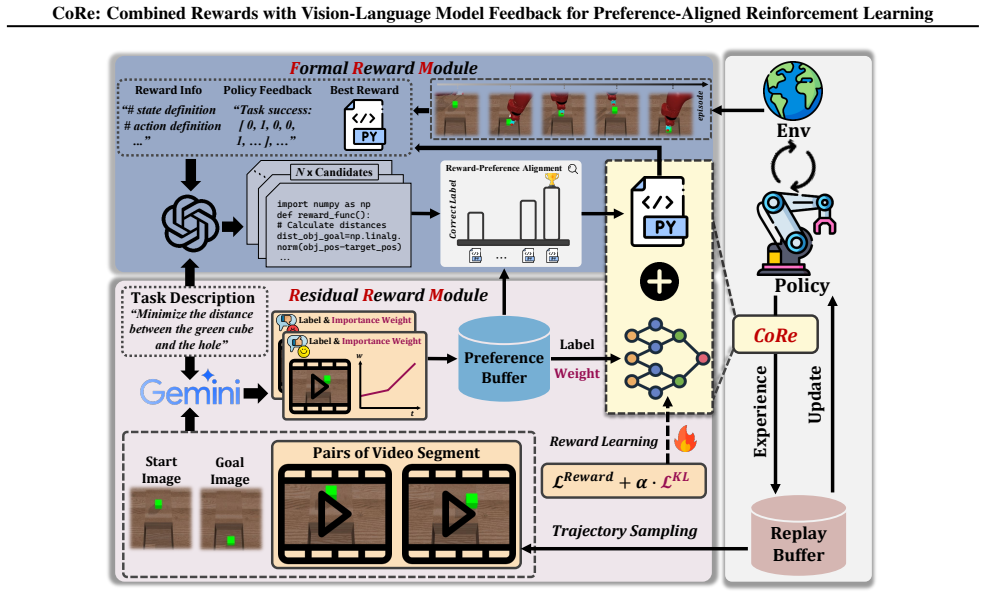
CoRe is a hybrid framework that integrates Formal Rewards (FR), explicitly designed based on task knowledge, and Residual Rewards (RR), learned from observations to capture implicit and nuanced preferences, by leveraging vision-language models in a Formal Reward Module to iteratively design and optimize FR and in a Residual Reward Module to generate video-level preference labels, such that the synergy produces reliable, efficient, and preference-aligned rewards for robotic policies.
What carries the argument
The CoRe framework's synergy of the Formal Reward Module (FRM) for VLM-driven iterative optimization of formal rewards and the Residual Reward Module (RRM) for VLM-labeled preference learning of residual rewards.
If this is right
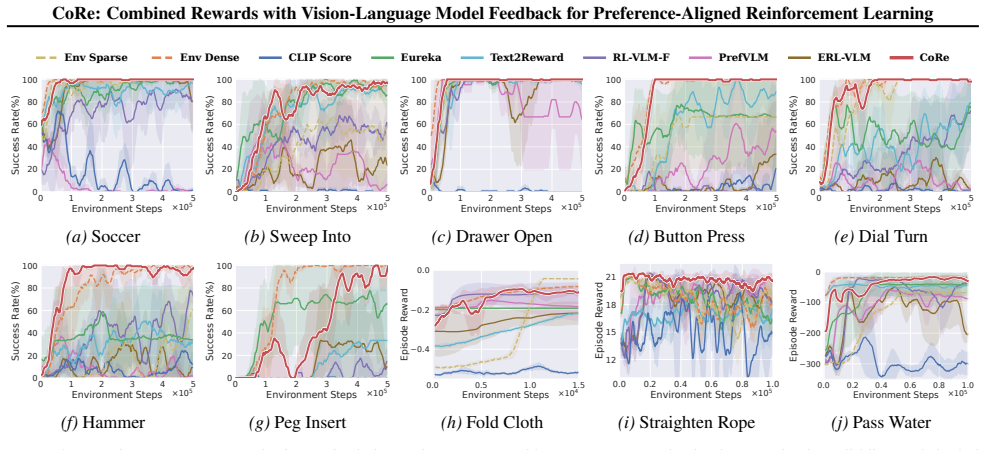
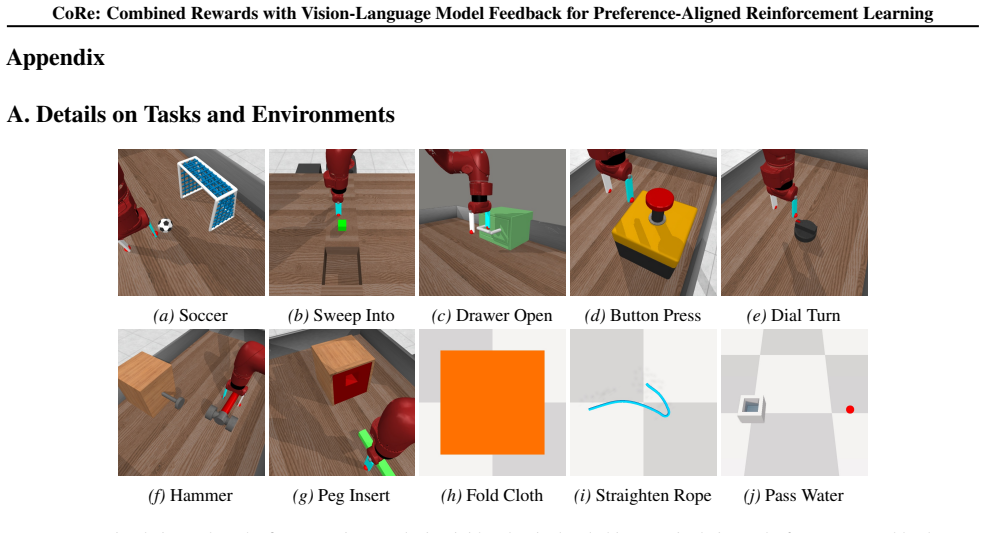
- Policy learning effectiveness and efficiency improve across ten robotic manipulation tasks in simulation.
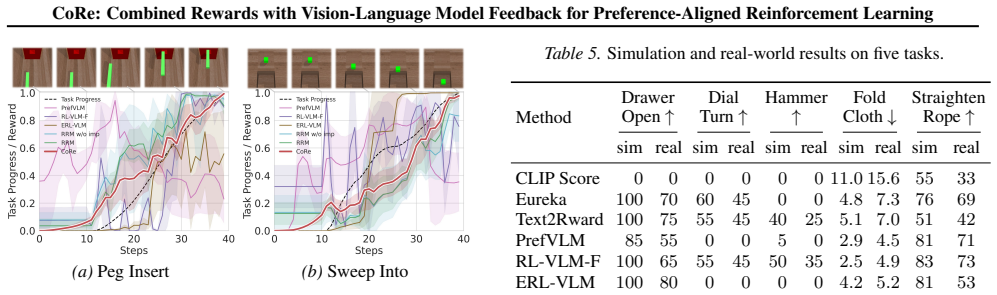
- Outperformance extends to five real-world robotic manipulation tasks.
- Rewards are constructed automatically without human involvement during training.
- Continual policy improvement occurs through iterative optimization of formal rewards based on preference feedback.
Where Pith is reading between the lines
- The FR and RR decomposition might reduce the need for extensive manual reward engineering in other reinforcement learning settings beyond robotics.
- If VLM reliability scales, the method could support preference alignment in tasks with complex or hard-to-specify human intent.
- Similar hybrid reward structures could be tested in non-robotic domains such as game playing or autonomous navigation.
Load-bearing premise
Vision-language models can reliably generate optimized formal rewards and accurate video-level preference labels without introducing systematic biases or hallucinations that degrade the learned policy.
What would settle it
An experiment in which policies trained under CoRe show no improvement over baselines on the ten simulation tasks or five real-world tasks, or in which VLM preference labels produce inconsistent reward signals leading to unstable training.
Figures



read the original abstract
Reward design remains a central challenge in reinforcement learning (RL). Hand-crafted rewards are often difficult to specify and may lead to suboptimal policies, while learned rewards from preferences can suffer from inefficiency and unstable training. Inspired by the dual nature of human learning explored in cognitive science, we decompose rewards into two complementary components: Formal Rewards (FR), explicitly designed based on task knowledge, and Residual Rewards (RR), learned from observations to capture implicit and nuanced preferences. Based on this decomposition, we propose CoRe, a hybrid framework that integrates FR and RR with vision-language models (VLMs) feedback to achieve preference-aligned policies without human involvement. Our contributions are twofold: (1) We propose a Formal Reward Module (FRM) that leverages VLMs to iteratively design and optimize FR based on task knowledge and preference feedback, enabling the continual improvement of policy during training; (2) We introduce a Residual Reward Module (RRM) that learns RR from video-level preference by employing VLMs to generate preference labels and capturing nuanced rewards that complement FR, ensuring alignment with human intent. Through the synergy of FRM and RRM, CoRe enables the automatic construction of reliable rewards that are efficient and preference-aligned. Extensive experiments demonstrate that CoRe outperforms existing approaches in terms of policy learning effectiveness and efficiency on ten robotic manipulation tasks in simulation and five real-worlds. Videos can be found on our project website: https://core-2026.github.io/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CoRe, a hybrid RL framework that decomposes rewards into Formal Rewards (FR) iteratively designed and optimized by a Formal Reward Module (FRM) leveraging VLMs from task knowledge plus preference feedback, and Residual Rewards (RR) learned by a Residual Reward Module (RRM) from VLM-generated video-level preference labels. The claimed synergy produces reliable, efficient, preference-aligned rewards without human involvement, with experiments demonstrating outperformance over baselines in policy learning effectiveness and efficiency across ten robotic manipulation tasks in simulation and five real-world tasks.
Significance. If the VLM-driven components prove reliable and the reported gains are reproducible, the work could meaningfully advance automatic reward design in robotics RL by reducing reliance on hand-crafted rewards or large-scale human preference collection while improving alignment.
major comments (1)
- [Abstract] Abstract: The central claim that 'through the synergy of FRM and RRM, CoRe enables the automatic construction of reliable rewards' is load-bearing on the assumption that VLMs can iteratively produce improved formal rewards and accurate video-level preference labels without hallucinations or systematic bias. No mechanism (consistency checks, verification, or debiasing) is described to prevent such errors from propagating into the learned policy; if this assumption fails, the outperformance on the 10+5 tasks cannot be attributed to the proposed FRM+RRM decomposition.
minor comments (1)
- [Abstract] Abstract: 'five real-worlds' is grammatically imprecise and should read 'five real-world tasks'.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comment regarding the reliability assumptions underlying our VLM-based components. We address the concern directly below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'through the synergy of FRM and RRM, CoRe enables the automatic construction of reliable rewards' is load-bearing on the assumption that VLMs can iteratively produce improved formal rewards and accurate video-level preference labels without hallucinations or systematic bias. No mechanism (consistency checks, verification, or debiasing) is described to prevent such errors from propagating into the learned policy; if this assumption fails, the outperformance on the 10+5 tasks cannot be attributed to the proposed FRM+RRM decomposition.
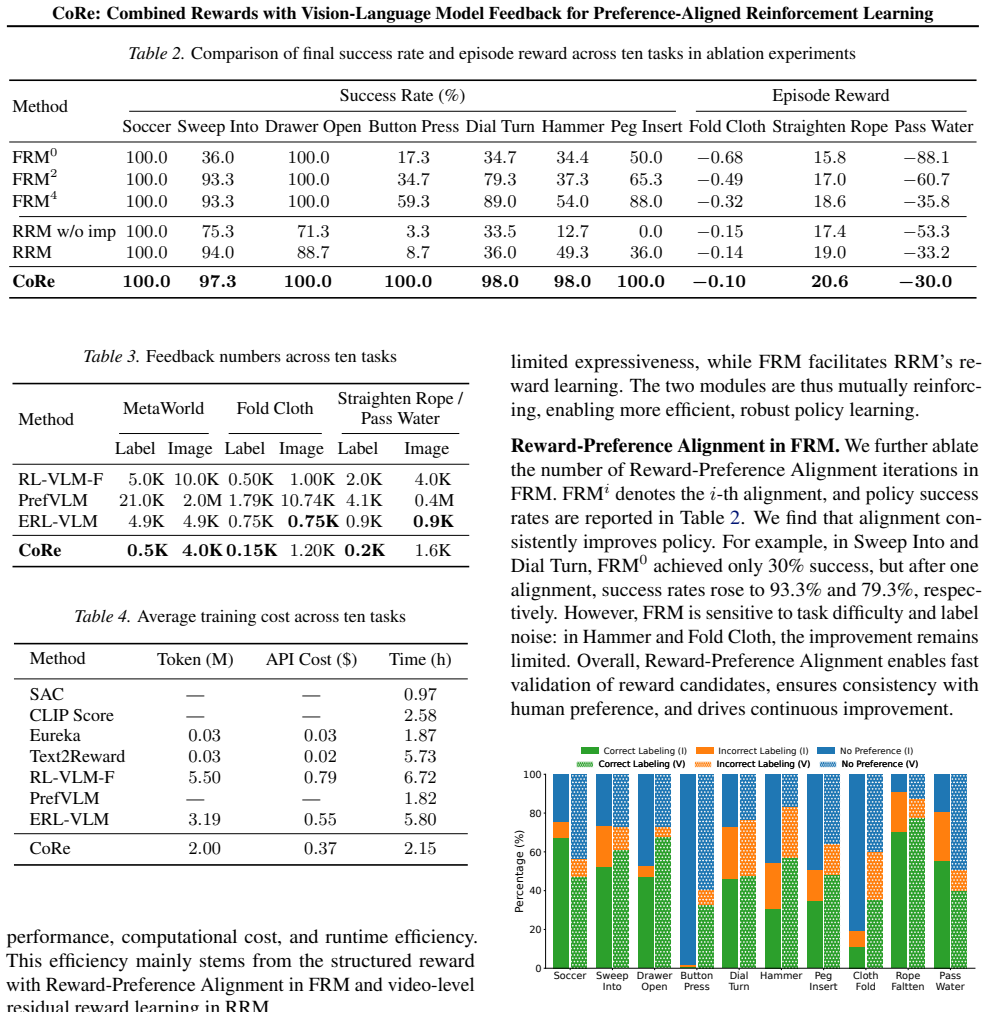
Authors: We agree that the manuscript does not describe explicit consistency checks, verification steps, or debiasing procedures for VLM outputs. The FRM iteration uses downstream policy performance (via preference feedback) as an empirical signal to refine formal rewards, while the RRM learns residuals that are only retained if they improve alignment with the combined reward. The reported gains on the ten simulation and five real-world tasks provide evidence that the overall pipeline produced effective rewards, but we acknowledge this does not constitute a formal safeguard against VLM errors. We will add a dedicated limitations paragraph discussing VLM hallucination risks and error propagation, together with suggestions for future verification mechanisms, in the revised version. revision: partial
Circularity Check
No circularity: framework is conceptual with no equations or self-referential derivations
full rationale
The paper introduces CoRe as a hybrid reward framework decomposing rewards into Formal Rewards (FR) via FRM and Residual Rewards (RR) via RRM, both leveraging VLMs for iterative optimization and preference labeling. The abstract and description contain no equations, no derivation steps, no fitted parameters presented as predictions, and no self-citations invoked to justify uniqueness or load-bearing premises. Claims rest on the proposed modules and experimental results rather than any mathematical chain that reduces to its own inputs by construction. No patterns from the enumerated circularity kinds apply.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume=
Deep reinforcement learning from human preferences , author=. Advances in Neural Information Processing Systems , volume=
-
[3]
Advances in Neural Information Processing Systems , year=
B-pref: Benchmarking preference-based reinforcement learning , author=. Advances in Neural Information Processing Systems , year=
-
[4]
International Conference on Machine Learning , year=
Pebble: Feedback-efficient interactive reinforcement learning via relabeling experience and unsupervised pre-training , author=. International Conference on Machine Learning , year=
-
[5]
International Conference on Learning Representations , year=
Reward uncertainty for exploration in preference-based reinforcement learning , author=. International Conference on Learning Representations , year=
-
[6]
Advances in Neural Information Processing Systems , volume=
Meta-reward-net: Implicitly differentiable reward learning for preference-based reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[7]
IEEE International Conference on Robotics and Automation , pages=
Efficient preference-based reinforcement learning using learned dynamics models , author=. IEEE International Conference on Robotics and Automation , pages=
-
[8]
International Conference on Learning Representations , year=
SURF: Semi-supervised reward learning with data augmentation for feedback-efficient preference-based reinforcement learning , author=. International Conference on Learning Representations , year=
-
[9]
2018 , publisher=
Reinforcement learning: An introduction , author=. 2018 , publisher=
2018
-
[11]
Conference on Robot Learning , pages=
Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning , author=. Conference on Robot Learning , pages=
-
[13]
nature , volume=
Mastering the game of Go with deep neural networks and tree search , author=. nature , volume=. 2016 , publisher=
2016
-
[15]
IEEE Transactions on Intelligent Transportation Systems , volume=
Deep reinforcement learning for autonomous driving: A survey , author=. IEEE Transactions on Intelligent Transportation Systems , volume=. 2021 , publisher=
2021
-
[18]
Conference on Robot Learning , pages=
QT-Opt: Scalable Deep Reinforcement Learning for Vision-Based Robotic Manipulation , author=. Conference on Robot Learning , pages=
-
[19]
International Journal of Robotics Research , volume=
Reinforcement learning in robotics: A survey , author=. International Journal of Robotics Research , volume=. 2013 , publisher=
2013
-
[20]
Advances in Neural Information Processing Systems , volume=
Generative adversarial imitation learning , author=. Advances in Neural Information Processing Systems , volume=
-
[22]
International Conference on Learning Representations , volume=
Query-policy misalignment in preference-based reinforcement learning , author=. International Conference on Learning Representations , volume=
-
[23]
International Conference on Machine Learning , pages=
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor , author=. International Conference on Machine Learning , pages=
-
[24]
International Conference on Learning Representations , year=
Hindsight PRIORs for Reward Learning from Human Preferences , author=. International Conference on Learning Representations , year=
-
[25]
Wang, Yufei and Sun, Zhanyi and Zhang, Jesse and Xian, Zhou and Biyik, Erdem and Held, David and Erickson, Zackory , booktitle=
-
[26]
International Conference on Autonomous Agents and Multiagent Systems , pages=
Online Preference-based Reinforcement Learning with Self-augmented Feedback from Large Language Model , author=. International Conference on Autonomous Agents and Multiagent Systems , pages=
-
[27]
IEEE Robotics and Automation Letters , volume=
Prefclm: Enhancing preference-based reinforcement learning with crowdsourced large language models , author=. IEEE Robotics and Automation Letters , volume=. 2025 , publisher=
2025
-
[28]
IEEE/RSJ International Conference on Intelligent Robots and Systems , pages=
Real-World Offline Reinforcement Learning from Vision Language Model Feedback , author=. IEEE/RSJ International Conference on Intelligent Robots and Systems , pages=
-
[29]
Advances in Neural Information Processing Systems , volume=
Roboclip: One demonstration is enough to learn robot policies , author=. Advances in Neural Information Processing Systems , volume=
-
[30]
International Conference on Learning Representations , year=
Vision-language models are zero-shot reward models for reinforcement learning , author=. International Conference on Learning Representations , year=
-
[31]
International Conference on Machine Learning , pages=
Liv: Language-image representations and rewards for robotic control , author=. International Conference on Machine Learning , pages=
-
[32]
International Conference on Machine Learning , pages=
Learning transferable visual models from natural language supervision , author=. International Conference on Machine Learning , pages=
-
[33]
International Conference on Learning Representations , year=
Eureka: Human-level reward design via coding large language models , author=. International Conference on Learning Representations , year=
-
[34]
International Conference on Learning Representations , year=
Text2reward: Automated dense reward function generation for reinforcement learning , author=. International Conference on Learning Representations , year=
-
[35]
Conference on Robot Learning , pages=
Language to rewards for robotic skill synthesis , author=. Conference on Robot Learning , pages=
-
[36]
Ryu, Kanghyun and Liao, Qiayuan and Li, Zhongyu and Delgosha, Payam and Sreenath, Koushil and Mehr, Negar , booktitle=
-
[37]
IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Auto mc-reward: Automated dense reward design with large language models for minecraft , author=. IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[38]
International Conference on Machine Learning , pages=
Learning reward for robot skills using large language models via self-alignment , author=. International Conference on Machine Learning , pages=
-
[39]
European Conference on Artificial Intelligence , pages=
Video2Reward: Generating Reward Function from Videos for Legged Robot Behavior Learning , author=. European Conference on Artificial Intelligence , pages=
-
[40]
AAAI Conference on Artificial Intelligence , volume=
Efficient Language-instructed Skill Acquisition via Reward-Policy Co-Evolution , author=. AAAI Conference on Artificial Intelligence , volume=
-
[41]
International Conference on Machine Learning , pages=
ELEMENTAL: Interactive Learning from Demonstrations and Vision-Language Models for Reward Design in Robotics , author=. International Conference on Machine Learning , pages=
-
[42]
International Conference on Learning Representations , volume=
Motif: Intrinsic motivation from artificial intelligence feedback , author=. International Conference on Learning Representations , volume=
-
[43]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
Navigating Noisy Feedback: Enhancing Reinforcement Learning with Error-Prone Language Models , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[44]
Advances in Neural Information Processing Systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[45]
Journal of Machine Learning Research , volume=
A survey of preference-based reinforcement learning methods , author=. Journal of Machine Learning Research , volume=
-
[46]
Conference on Robot Learning , pages=
Softgym: Benchmarking deep reinforcement learning for deformable object manipulation , author=. Conference on Robot Learning , pages=
-
[47]
2025 , howpublished =
2025
-
[49]
, author=
The proof and measurement of association between two things. , author=. 1961 , publisher=
1961
-
[50]
The annals of probability , pages=
I-divergence geometry of probability distributions and minimization problems , author=. The annals of probability , pages=. 1975 , publisher=
1975
-
[52]
International Conference on Machine Learning , year=
Enhancing Rating-Based Reinforcement Learning to Effectively Leverage Feedback from Large Vision-Language Models , author=. International Conference on Machine Learning , year=
-
[53]
International Conference on Machine Learning , pages=
Zero-shot reward specification via grounded natural language , author=. International Conference on Machine Learning , pages=
-
[54]
Learning for Dynamics and Control Conference , pages=
Can foundation models perform zero-shot task specification for robot manipulation? , author=. Learning for Dynamics and Control Conference , pages=
-
[56]
International Conference on Machine Learning , pages=
RIME: Robust Preference-based Reinforcement Learning with Noisy Preferences , author=. International Conference on Machine Learning , pages=
-
[57]
AAAI Conference on Artificial Intelligence , volume=
Rating-based reinforcement learning , author=. AAAI Conference on Artificial Intelligence , volume=
-
[58]
Learning and Individual Differences , volume=
How does prior knowledge affect learning? A review of 16 mechanisms and a framework for future research , author=. Learning and Individual Differences , volume=. 2025 , publisher=
2025
-
[59]
Frontiers in psychology , volume=
How does prior knowledge influence learning engagement? The mediating roles of cognitive load and help-seeking , author=. Frontiers in psychology , volume=. 2020 , publisher=
2020
-
[60]
Educational Psychology Review , volume=
The landscape of research on prior knowledge and learning: A bibliometric analysis , author=. Educational Psychology Review , volume=. 2023 , publisher=
2023
-
[61]
IEEE Transactions on Robotics , volume=
Reward learning from very few demonstrations , author=. IEEE Transactions on Robotics , volume=
-
[62]
Conference on Robot Learning , pages=
SDS--See it, Do it, Sorted: Quadruped Skill Synthesis from Single Video Demonstration , author=. Conference on Robot Learning , pages=
-
[64]
Conference on Empirical Methods in Natural Language Processing , pages=
VLP: Vision-Language Preference Learning for Embodied Manipulation , author=. Conference on Empirical Methods in Natural Language Processing , pages=
-
[66]
IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Deep residual learning for image recognition , author=. IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[69]
Conference on empirical methods in natural language processing , pages=
Video-llava: Learning united visual representation by alignment before projection , author=. Conference on empirical methods in natural language processing , pages=
-
[70]
Language reward modulation for pretraining reinforcement learning
Adeniji, A., Xie, A., Sferrazza, C., Seo, Y., James, S., and Abbeel, P. Language reward modulation for pretraining reinforcement learning. arXiv preprint arXiv:2308.12270, 2023
-
[71]
Concrete Problems in AI Safety
Amodei, D., Olah, C., Steinhardt, J., Christiano, P., Schulman, J., and Man \'e , D. Concrete problems in ai safety. arXiv preprint arXiv:1606.06565, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[72]
Dota 2 with Large Scale Deep Reinforcement Learning
Berner, C., Brockman, G., Chan, B., Cheung, V., Debiak, P., Dennison, C., Farhi, D., Fischer, Q., Hashme, S., Hesse, C., et al. Dota 2 with large scale deep reinforcement learning. arXiv preprint arXiv:1912.06680, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[73]
A., and Schneider, M
Bittermann, A., McNamara, D., Simonsmeier, B. A., and Schneider, M. The landscape of research on prior knowledge and learning: A bibliometric analysis. Educational Psychology Review, 35 0 (2): 0 58, 2023
2023
-
[74]
and Gombolay, M
Chen, L. and Gombolay, M. Elemental: Interactive learning from demonstrations and vision-language models for reward design in robotics. In International Conference on Machine Learning, pp.\ 8700--8725, 2025
2025
-
[75]
Rime: Robust preference-based reinforcement learning with noisy preferences
Cheng, J., Xiong, G., Dai, X., Miao, Q., Lv, Y., and Wang, F.-Y. Rime: Robust preference-based reinforcement learning with noisy preferences. In International Conference on Machine Learning, pp.\ 8229--8247, 2024
2024
-
[76]
F., Leike, J., Brown, T., Martic, M., Legg, S., and Amodei, D
Christiano, P. F., Leike, J., Brown, T., Martic, M., Legg, S., and Amodei, D. Deep reinforcement learning from human preferences. In Advances in Neural Information Processing Systems, volume 30, 2017
2017
-
[77]
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[78]
I-divergence geometry of probability distributions and minimization problems
Csisz \'a r, I. I-divergence geometry of probability distributions and minimization problems. The annals of probability, pp.\ 146--158, 1975
1975
-
[79]
Can foundation models perform zero-shot task specification for robot manipulation? In Learning for Dynamics and Control Conference, pp.\ 893--905, 2022
Cui, Y., Niekum, S., Gupta, A., Kumar, V., and Rajeswaran, A. Can foundation models perform zero-shot task specification for robot manipulation? In Learning for Dynamics and Control Conference, pp.\ 893--905, 2022
2022
-
[80]
S.-Y., and King, R
Dong, A., Jong, M. S.-Y., and King, R. B. How does prior knowledge influence learning engagement? the mediating roles of cognitive load and help-seeking. Frontiers in psychology, 11: 0 591203, 2020
2020
-
[81]
u de, D., and Akg \
Eteke, C., Keb \"u de, D., and Akg \"u n, B. Reward learning from very few demonstrations. IEEE Transactions on Robotics, 37 0 (3): 0 893--904, 2020
2020
-
[82]
arXiv preprint arXiv:2209.12941 (2022)
Geng, Y., An, B., Geng, H., Chen, Y., Yang, Y., and Dong, H. End-to-end affordance learning for robotic manipulation. arXiv preprint arXiv:2209.12941, 2022
-
[83]
S., Li, J., Karydis, K., and Roy-Chowdhury, A
Ghosh, U., Raychaudhuri, D. S., Li, J., Karydis, K., and Roy-Chowdhury, A. Preference vlm: Leveraging vlms for scalable preference-based reinforcement learning. arXiv preprint arXiv:2502.01616, 2025
-
[84]
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor
Haarnoja, T., Zhou, A., Abbeel, P., and Levine, S. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In International Conference on Machine Learning, pp.\ 1861--1870, 2018
2018
-
[85]
Deep residual learning for image recognition
He, K., Zhang, X., Ren, S., and Sun, J. Deep residual learning for image recognition. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 770--778, 2016
2016
-
[86]
and Ermon, S
Ho, J. and Ermon, S. Generative adversarial imitation learning. In Advances in Neural Information Processing Systems, volume 29, 2016
2016
-
[87]
Query-policy misalignment in preference-based reinforcement learning
Hu, X., Li, J., Zhan, X., Jia, Q.-S., and Zhang, Y.-Q. Query-policy misalignment in preference-based reinforcement learning. In International Conference on Learning Representations, volume 2024, pp.\ 45579--45603, 2024
2024
-
[88]
Efficient language-instructed skill acquisition via reward-policy co-evolution
Huang, C., Chang, Y., Lin, J., Liang, J., Zeng, R., and Li, J. Efficient language-instructed skill acquisition via reward-policy co-evolution. In AAAI Conference on Artificial Intelligence, volume 39, pp.\ 14576--14584, 2025
2025
-
[89]
Qt-opt: Scalable deep reinforcement learning for vision-based robotic manipulation
Kalashnikov, D., Irpan, A., Pastor, P., Ibarz, J., Herzog, A., Jang, E., Quillen, D., Holly, E., Kalakrishnan, M., Vanhoucke, V., et al. Qt-opt: Scalable deep reinforcement learning for vision-based robotic manipulation. In Conference on Robot Learning, pp.\ 651--673, 2018
2018
-
[90]
Kingma, D. P. and Ba, J. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[91]
R., Sobh, I., Talpaert, V., Mannion, P., Al Sallab, A
Kiran, B. R., Sobh, I., Talpaert, V., Mannion, P., Al Sallab, A. A., Yogamani, S., and P \'e rez, P. Deep reinforcement learning for autonomous driving: A survey. IEEE Transactions on Intelligent Transportation Systems, 23 0 (6): 0 4909--4926, 2021
2021
-
[92]
Motif: Intrinsic motivation from artificial intelligence feedback
Klissarov, M., D'Oro, P., Sodhani, S., Raileanu, R., Bacon, P.-L., Vincent, P., Zhang, A., and Henaff, M. Motif: Intrinsic motivation from artificial intelligence feedback. In International Conference on Learning Representations, volume 2024, pp.\ 38888--38921, 2024
2024
-
[93]
A., and Peters, J
Kober, J., Bagnell, J. A., and Peters, J. Reinforcement learning in robotics: A survey. International Journal of Robotics Research, 32 0 (11): 0 1238--1274, 2013
2013
-
[94]
Pebble: Feedback-efficient interactive reinforcement learning via relabeling experience and unsupervised pre-training
Lee, K., Smith, L., and Abbeel, P. Pebble: Feedback-efficient interactive reinforcement learning via relabeling experience and unsupervised pre-training. In International Conference on Machine Learning, 2021 a
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.