TacEvo: Self-Evolving Architecture Discovery for Robotic Tactile Perception via LLM-Driven Quality-Diversity Search
Pith reviewed 2026-06-30 05:44 UTC · model grok-4.3
The pith
TacEvo uses an LLM to generate code mutations inside a quality-diversity loop that produces trainable tactile networks matching or beating an expert baseline on force and texture tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
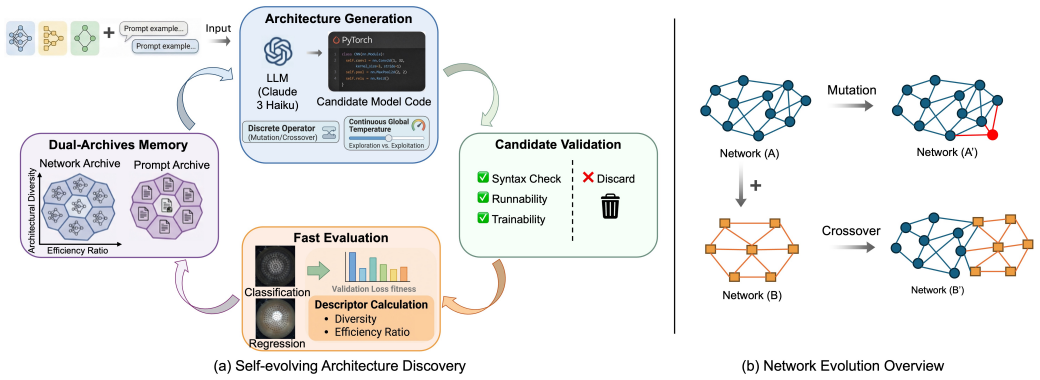
TacEvo shows that LLM-generated code mutations and crossovers, filtered only by Architectural Diversity and Efficiency Ratio inside a MAP-Elites loop, reliably yield valid networks whose downstream fitness on ViTacTip force regression and grating classification improves substantially over generations and reaches or surpasses a hand-crafted expert baseline in post-search evaluation.
What carries the argument
MAP-Elites quality-diversity archive driven by LLM code-level mutations and crossovers, with Architectural Diversity and Efficiency Ratio as the two behavioral descriptors that shape the preserved population.
If this is right
- The same search loop can be applied to new tactile sensor hardware without redesigning a discrete search space.
- The Efficiency Ratio descriptor produces networks whose compute-size trade-offs remain usable for onboard robot inference.
- Prompt reuse across generations allows the system to favor mutation styles that historically produced trainable improvements.
- High autonomous generation reliability indicates that the two-descriptor filter removes most invalid code before training.
Where Pith is reading between the lines
- The same LLM-QD pattern could be tested on other sensor modalities whose images are likewise physics-specific.
- If the LLM version changes, the fraction of trainable outputs may shift and require re-tuning of the diversity descriptors.
- The method implicitly treats architecture code as an evolvable program, which may extend to other code-level design tasks beyond neural nets.
Load-bearing premise
Fitness gains observed after twenty generations arise from the LLM-driven search process rather than from differences in training code, hyper-parameters, or baseline implementation details.
What would settle it
Run an otherwise identical twenty-generation MAP-Elites loop that replaces every LLM mutation with random but syntactically valid architecture edits and measure whether the fitness trajectory and final performance remain statistically indistinguishable from the reported TacEvo results.
Figures


read the original abstract
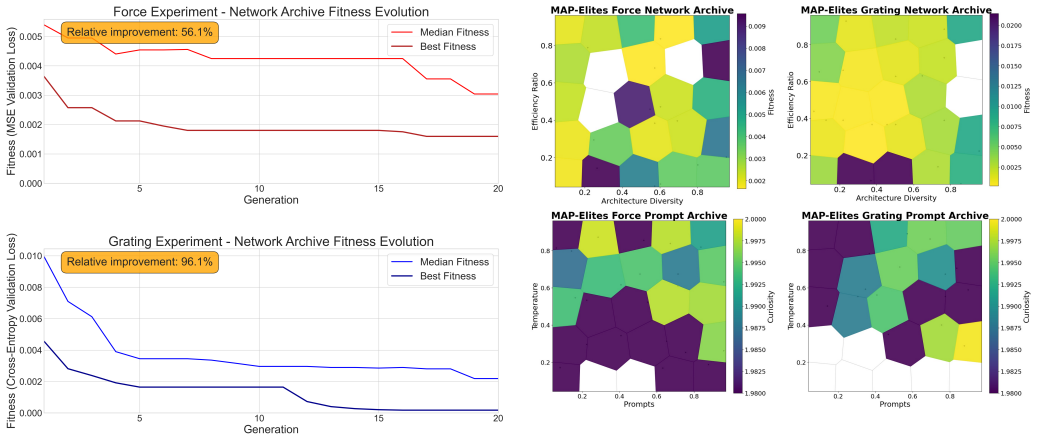
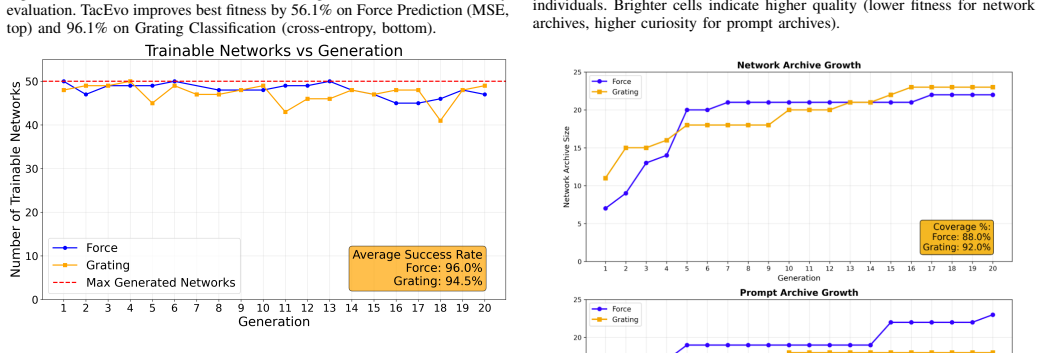
Vision-based tactile sensing converts contact-induced surface deformation into images, enabling robots to infer contact forces and fine surface textures that are not accessible through conventional vision alone. However, tactile images are sensor- and physics-specific, so effective architectures often require expert intuition and extensive manual iteration. Existing neural architecture search (NAS) pipelines can reduce this burden, but they are often computationally expensive and restricted to hand-designed search spaces, which limits architectural novelty and diversity. We introduce TacEvo, a self-evolving architecture discovery framework that improves network designs from downstream feedback. TacEvo uses an LLM to generate code-level mutations and crossovers, and a MAP-Elites quality-diversity loop that preserves diverse elite architectures while preferentially reusing prompts that consistently yield improvements. Exploration is guided by two behavioural descriptors, Architectural Diversity and Efficiency Ratio, which encourage coverage across structural variations and compute-size trade-offs. On ViTacTip force regression and grating classification, TacEvo achieves high autonomous generation reliability (96.0%/94.5% trainable) and improves best validation fitness over 20 generations by 56.1%/96.1%. In a 20-seed post-search high-fidelity evaluation, TacEvo matches the expert baseline on force prediction and outperforms it on fine-grained grating classification. These results suggest that LLM-driven self-evolving search constitutes a practical paradigm for AI-assisted scientific discovery in specialised robotic sensing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
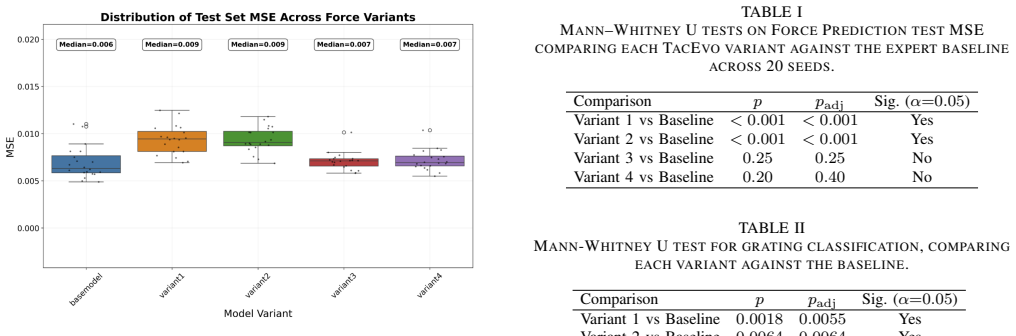
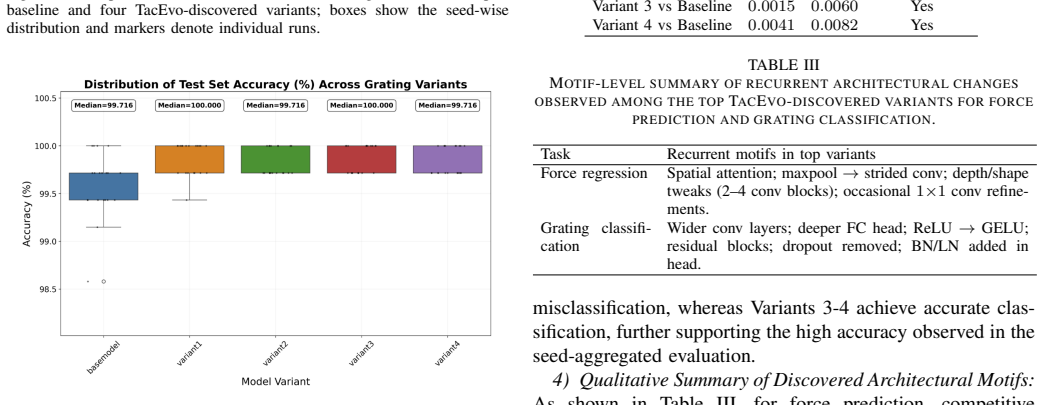
Summary. The paper introduces TacEvo, a self-evolving architecture discovery framework for vision-based tactile sensing that employs an LLM to generate code-level mutations and crossovers within a MAP-Elites quality-diversity loop. Exploration is guided by two behavioral descriptors (Architectural Diversity and Efficiency Ratio), with preferential reuse of successful prompts. On ViTacTip force regression and grating classification tasks, it reports 96.0%/94.5% trainable generation rates and best-validation-fitness gains of 56.1%/96.1% over 20 generations; a 20-seed high-fidelity evaluation shows the evolved networks matching an expert baseline on force prediction and outperforming it on fine-grained grating classification.
Significance. If the fitness gains and task improvements can be robustly attributed to the LLM-driven QD search rather than unstated training details or generator variance, the work would demonstrate a practical route to automated architecture design in physics-specific robotic sensing, reducing dependence on manual expert iteration.
major comments (2)
- [§4 and §5] §4 (Experimental results) and §5 (post-search evaluation): the central performance claims (56.1%/96.1% fitness lifts and grating-classification superiority) rest on comparisons whose attribution to the MAP-Elites archive, LLM mutations, and prompt-reuse mechanism is not isolated. No ablations are described that hold the LLM generator, training protocol, data splits, and optimizer fixed while disabling the quality-diversity archive or preferential prompt reuse; without these controls the reported gains cannot be confidently ascribed to the proposed search process rather than variance in LLM outputs or baseline choices.
- [Abstract and §4] Abstract and §4: the quantitative claims supply concrete percentages but contain no mention of statistical tests, error bars, or variance across the 20 generations or 20-seed evaluations, leaving the reliability of the reported improvements unevaluable.
minor comments (2)
- [Abstract and §4] The abstract and results sections should explicitly state the exact expert baseline architectures, data splits, and hyper-parameter settings used for comparison.
- [§3] Notation for the two behavioral descriptors (Architectural Diversity and Efficiency Ratio) should be defined with equations or pseudocode in the methods section for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify gaps in component isolation and statistical reporting. We address each major comment below and commit to revisions that strengthen attribution and reliability assessment.
read point-by-point responses
-
Referee: [§4 and §5] §4 (Experimental results) and §5 (post-search evaluation): the central performance claims (56.1%/96.1% fitness lifts and grating-classification superiority) rest on comparisons whose attribution to the MAP-Elites archive, LLM mutations, and prompt-reuse mechanism is not isolated. No ablations are described that hold the LLM generator, training protocol, data splits, and optimizer fixed while disabling the quality-diversity archive or preferential prompt reuse; without these controls the reported gains cannot be confidently ascribed to the proposed search process rather than variance in LLM outputs or baseline choices.
Authors: We agree that the manuscript does not contain ablations that disable the MAP-Elites archive or preferential prompt reuse while holding the LLM generator, training protocol, data splits, and optimizer fixed. This limits confident attribution of the fitness gains specifically to the quality-diversity and prompt-reuse components. In the revised version we will add these controls: (i) a non-QD evolutionary baseline that retains LLM mutations/crossovers but removes the archive and behavioral descriptors, and (ii) a version without preferential prompt reuse. Results will be reported alongside the original TacEvo curves to isolate the contribution of each mechanism. revision: yes
-
Referee: [Abstract and §4] Abstract and §4: the quantitative claims supply concrete percentages but contain no mention of statistical tests, error bars, or variance across the 20 generations or 20-seed evaluations, leaving the reliability of the reported improvements unevaluable.
Authors: We acknowledge that the current manuscript reports point estimates without error bars, variance across generations or seeds, or statistical tests. In the revision we will augment §4 with standard-deviation bands on the fitness-evolution plots (across the 20 generations) and on the 20-seed post-search evaluation. We will also add the results of paired statistical tests (Wilcoxon signed-rank or t-tests, as appropriate) between TacEvo and the expert baseline for both tasks, together with p-values, to allow readers to assess the reliability of the reported improvements. revision: yes
Circularity Check
No circularity: empirical search results independent of inputs
full rationale
The paper describes an empirical MAP-Elites + LLM mutation procedure evaluated on tactile sensing tasks. Reported fitness lifts (56.1%/96.1%) and post-search comparisons are measured outcomes of running the loop on held-out validation data, not quantities defined by the same parameters or reduced to self-citations. No equations, uniqueness theorems, or ansatzes appear that would make any result equivalent to its inputs by construction. The method is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Visuo- haptic object perception for robots: an overview,
N. Navarro-Guerrero, S. Toprak, J. Josifovski, and L. Jamone, “Visuo- haptic object perception for robots: an overview,”Autonomous Robots, vol. 47, no. 4, pp. 377–403, 2023
2023
-
[2]
Gelsight: High-resolution robot tactile sensors for estimating geometry and force,
W. Yuan, S. Dong, and E. H. Adelson, “Gelsight: High-resolution robot tactile sensors for estimating geometry and force,”Sensors, vol. 17, no. 12, p. 2762, 2017
2017
-
[3]
Taceva: A performance evaluation framework for vision-based tactile sensors,
Q. Cong, S. Oh, W. Fan, S. Luo, K. Althoefer, and D. Zhang, “Taceva: A performance evaluation framework for vision-based tactile sensors,” Advanced Intelligent Systems, p. e202501179, 2025
2025
-
[4]
C. Higuera, A. Sharma, C. K. Bodduluri, T. Fan, P. Lancaster, M. Kalakr- ishnan, M. Kaess, B. Boots, M. Lambeta, T. Wuet al., “Sparsh: Self- supervised touch representations for vision-based tactile sensing,”arXiv preprint arXiv:2410.24090, 2024
-
[5]
A comprehensive survey of neural architecture search: Challenges and solutions,
P. Ren, Y . Xiao, X. Chang, P.-Y . Huang, Z. Li, X. Chen, and X. Wang, “A comprehensive survey of neural architecture search: Challenges and solutions,”ACM Computing Surveys (CSUR), vol. 54, no. 4, pp. 1–34, 2021
2021
-
[6]
A review of neural architecture search methods for super-resolution imaging,
J. Guo, X. Wang, and Y . Guo, “A review of neural architecture search methods for super-resolution imaging,”Artificial Intelligence Review, 2026
2026
-
[7]
Weight-sharing neural architecture search: A battle to shrink the optimization gap,
L. Xie, X. Chen, K. Bi, L. Wei, Y . Xu, L. Wang, Z. Chen, A. Xiao, J. Chang, X. Zhanget al., “Weight-sharing neural architecture search: A battle to shrink the optimization gap,”ACM Computing Surveys (CSUR), vol. 54, no. 9, pp. 1–37, 2021
2021
-
[8]
A review on code generation with llms: Application and evaluation,
J. Wang and Y . Chen, “A review on code generation with llms: Application and evaluation,” in2023 IEEE International Conference on Medical Artificial Intelligence (MedAI). IEEE, 2023, pp. 284–289
2023
-
[9]
A Survey on Code Generation with LLM-based Agents
Y . Dong, X. Jiang, J. Qian, T. Wang, K. Zhang, Z. Jin, and G. Li, “A survey on code generation with llm-based agents,”arXiv preprint arXiv:2508.00083, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Evaluating Large Language Models Trained on Code
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. D. O. Pinto, J. Kaplan, H. Edwards, Y . Burda, N. Joseph, G. Brockmanet al., “Evaluating large language models trained on code,”arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
Mathematical discoveries from program search with large language models,
B. Romera-Paredes, M. Barekatain, A. Novikov, M. Balog, M. P. Kumar, E. Dupont, F. J. Ruiz, J. S. Ellenberg, P. Wang, O. Fawziet al., “Mathematical discoveries from program search with large language models,”Nature, vol. 625, no. 7995, pp. 468–475, 2024
2024
-
[12]
Nas-bench-101: Towards reproducible neural architecture search,
C. Ying, A. Klein, E. Christiansen, E. Real, K. Murphy, and F. Hutter, “Nas-bench-101: Towards reproducible neural architecture search,” in International conference on machine learning. PMLR, 2019, pp. 7105– 7114
2019
-
[13]
V . Vassiliades, K. Chatzilygeroudis, and J.-B. Mouret, “Using centroidal vorono¨ı tessellations to scale up the multi-dimensional archive of phe- notypic elites algorithm,”arXiv preprint arXiv:1610.05729, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[14]
Vitactip: Design and verification of a novel biomimetic physical vision-tactile fusion sensor,
W. Fan, H. Li, W. Si, S. Luo, N. Lepora, and D. Zhang, “Vitactip: Design and verification of a novel biomimetic physical vision-tactile fusion sensor,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 1056–1062
2024
-
[15]
Design and benchmarking of a multimodality sensor for robotic manipulation with gan-based cross-modality interpretation,
D. Zhang, W. Fan, J. Lin, H. Li, Q. Cong, W. Liu, N. F. Lepora, and S. Luo, “Design and benchmarking of a multimodality sensor for robotic manipulation with gan-based cross-modality interpretation,” IEEE Transactions on Robotics, vol. 41, pp. 1278–1295, 2025
2025
-
[16]
Automl: A survey of the state-of-the-art,
X. He, K. Zhao, and X. Chu, “Automl: A survey of the state-of-the-art,” Knowledge-based systems, vol. 212, p. 106622, 2021
2021
-
[17]
Eight years of automl: categorisation, review and trends,
R. Barbudo, S. Ventura, and J. R. Romero, “Eight years of automl: categorisation, review and trends,”Knowledge and Information Systems, vol. 65, no. 12, pp. 5097–5149, 2023
2023
-
[18]
Neural architecture search: A survey,
T. Elsken, J. H. Metzen, and F. Hutter, “Neural architecture search: A survey,”Journal of Machine Learning Research, vol. 20, no. 55, pp. 1–21, 2019
2019
-
[19]
Design principle transfer in neural architecture search via large language models,
X. Zhou, X. Wu, L. Feng, Z. Lu, and K. C. Tan, “Design principle transfer in neural architecture search via large language models,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 21, 2025, pp. 23 000–23 008
2025
-
[20]
Software architecture-based self-adaptation in robotics,
E. Alberts, I. Gerostathopoulos, I. Malavolta, C. H. Corbato, and P. Lago, “Software architecture-based self-adaptation in robotics,”Journal of Systems and Software, vol. 219, p. 112258, 2025
2025
-
[21]
Optimization of forcemyography sensor placement for arm movement recognition,
X. Xu, Z. Du, H. Zhang, R. Zhang, Z. Hong, Q. Huang, and B. Han, “Optimization of forcemyography sensor placement for arm movement recognition,” in2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2022, pp. 9845–9850
2022
-
[22]
Optimal placement of passive sensors for robot localisation,
F. Zenatti, D. Fontanelli, L. Palopoli, D. Macii, and P. Nazemzadeh, “Optimal placement of passive sensors for robot localisation,” in2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2016, pp. 4586–4593
2016
-
[23]
H. Wang, J. Gong, H. Zhang, J. Xu, and Z. Wang, “Ai agentic programming: A survey of techniques, challenges, and opportunities,” arXiv preprint arXiv:2508.11126, 2025
-
[24]
EvoPrompting: Language models for code-level neural architecture search,
A. Chen, D. M. Dohan, and D. R. So, “EvoPrompting: Language models for code-level neural architecture search,”arXiv preprint arXiv:2302.14838, 2023. [Online]. Available: https://arxiv.org/abs/2302. 14838
-
[25]
LL- Matic: Neural architecture search via large language models and quality diversity optimization,
M. U. Nasir, S. Earle, J. Togelius, S. James, and C. Cleghorn, “LL- Matic: Neural architecture search via large language models and quality diversity optimization,”arXiv preprint arXiv:2306.01102, 2024
-
[26]
Illuminating search spaces by mapping elites
J.-B. Mouret and J. Clune, “Illuminating search spaces by mapping elites,”arXiv preprint arXiv:1504.04909, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[27]
Using cen- troidal voronoi tessellations to scale up the multidimensional archive of phenotypic elites algorithm,
V . Vassiliades, K. Chatzilygeroudis, and J.-B. Mouret, “Using cen- troidal voronoi tessellations to scale up the multidimensional archive of phenotypic elites algorithm,”IEEE Transactions on Evolutionary Computation, vol. 22, no. 4, pp. 623–630, 2017
2017
-
[28]
Robots that can adapt like animals,
A. Cully, J. Clune, D. Tarapore, and J.-B. Mouret, “Robots that can adapt like animals,”Nature, vol. 521, no. 7553, pp. 503–507, 2015
2015
-
[29]
AlphaEvolve: A coding agent for scientific and algorithmic discovery
A. Novikov, N. V ˜u, M. Eisenberger, E. Dupont, P.-S. Huang, A. Z. Wagner, S. Shirobokov, B. Kozlovskii, F. J. Ruiz, A. Mehrabianet al., “Alphaevolve: A coding agent for scientific and algorithmic discovery,” arXiv preprint arXiv:2506.13131, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
The claude 3 model family: Opus, sonnet, haiku,
Anthropic, “The claude 3 model family: Opus, sonnet, haiku,” 2024, accessed: 2026-03-05. [Online]. Available: https://www.anthropic.com/ news/claude-3-family
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.