PRISM: Processing-In-Memory Sparse MTTKRP for Tensor Decomposition Acceleration
Pith reviewed 2026-06-29 05:42 UTC · model grok-4.3
The pith
Processing-in-memory hardware accelerates the core sparse tensor operation in decomposition by up to 2.64 times when paired with a CPU.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
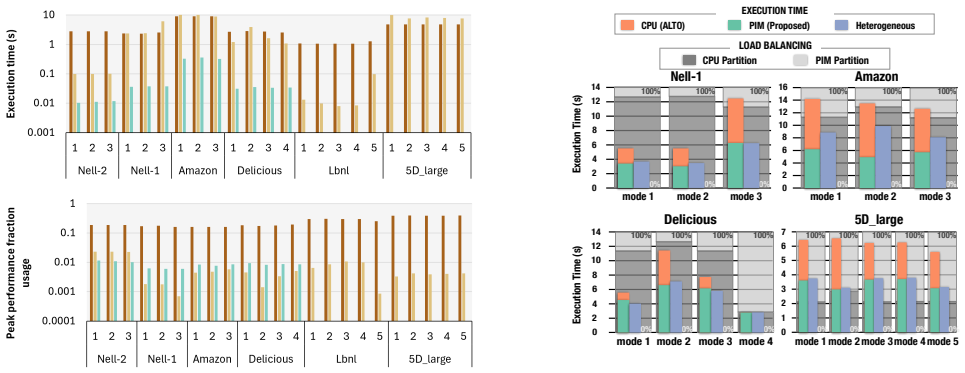
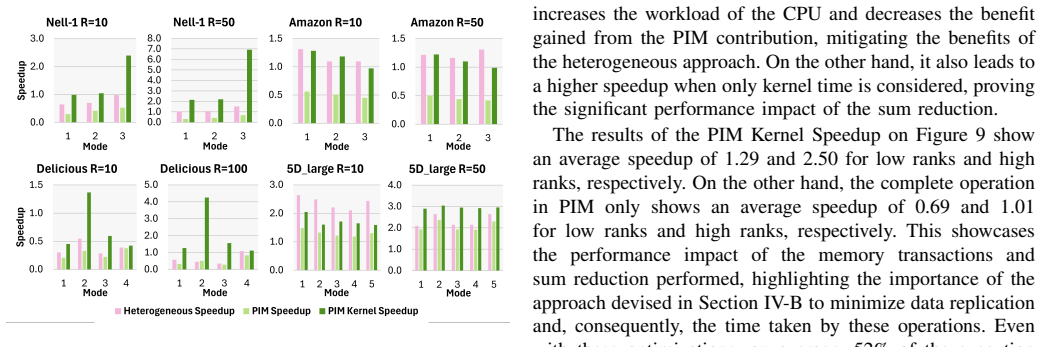
PRISM provides the first processing-in-memory implementation of sparse MTTKRP and shows that it reaches 2.37 times the speed of state-of-the-art CPU code; a heterogeneous CPU-PIM version reaches 2.64 times while consuming a larger fraction of peak hardware performance than either CPU or GPU baselines, although the distributed memory layout on UPMEM can reduce gains on some workloads.
What carries the argument
Partitioning strategies that distribute the sparse MTTKRP computation across UPMEM PIM modules together with number-format and kernel choices that adapt the irregular memory accesses to the hardware.
If this is right
- Sparse MTTKRP can be performed faster on PIM hardware than on general-purpose CPUs alone.
- Adding a CPU to the PIM execution yields an extra performance increment beyond PIM-only runs.
- The fraction of peak performance achieved is higher than for CPU or GPU versions of the same operation.
- Workload-dependent variation occurs because the distributed memory can hinder performance on certain sparse patterns.
Where Pith is reading between the lines
- The same PIM mapping techniques could be tried on other memory-bound sparse linear-algebra kernels common in machine learning.
- Future PIM architectures might benefit from hardware features that reduce overhead for irregular sparse accesses.
- Combining PIM with additional accelerators could create multi-level heterogeneous systems for tensor workloads.
Load-bearing premise
The UPMEM distributed memory system and the chosen partitioning strategies will not introduce slowdowns large enough to erase the measured speedups on the workloads of interest.
What would settle it
Running the same PRISM code on a broader collection of real-world sparse tensors and finding that the distributed-memory overhead drops performance below the CPU baseline on more than a small fraction of cases.
Figures

read the original abstract
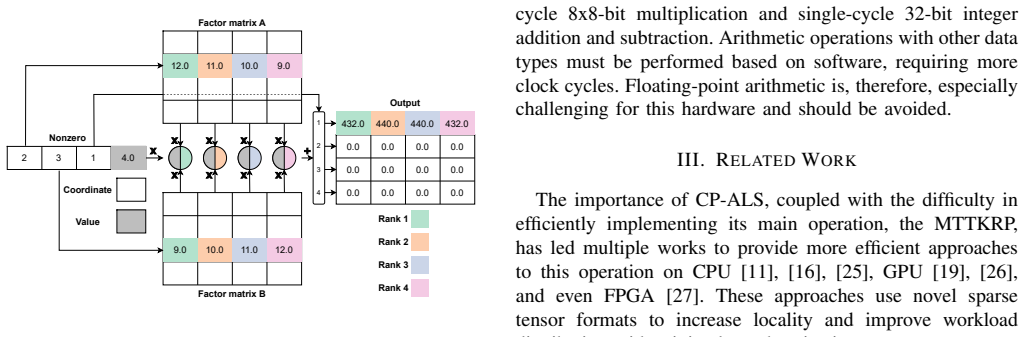
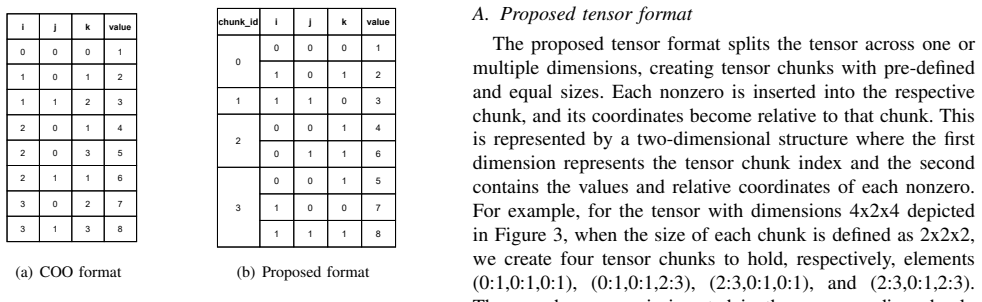
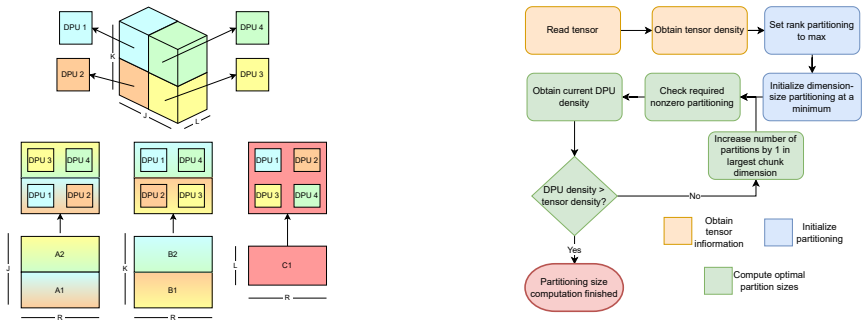
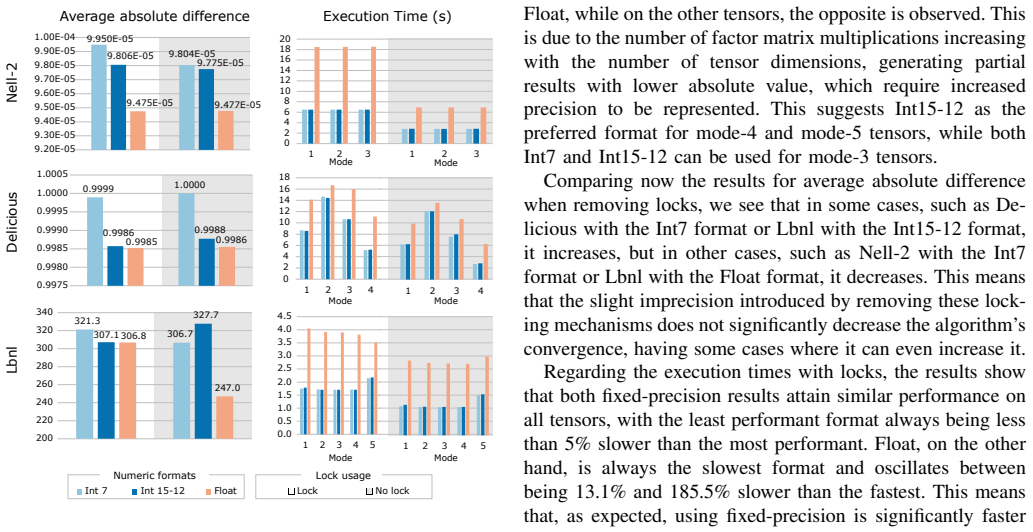
Sparse tensors are the most used representation of sparse multidimensional data. Operations that decompose them, selecting their most important features while reducing their dimension, have become prevalent procedures in machine learning. One of the most used tensor decomposition algorithms is the Alternating Least Squares Canonical Polyadic Decomposition (CP-ALS), where the most time-consuming operation is the Sparse Matricized Tensor Times Khatri-Rao Product (spMTTKRP). This operation is strongly memory-bound, making it hard to implement efficiently on general-purpose processors. This work proposes PRISM, the first approach to tackle this operation using Processing-In-Memory (PIM) technology. We extensively characterize different partitioning strategies, number formats, and kernel optimizations that efficiently adapt this operation to UPMEM PIM, which is further boosted by heterogeneous collaboration with the CPU. The experimental results show that the proposed PIM-based and heterogeneous approaches achieve up to 2.37x and 2.64x speedup compared to state-of-the-art CPU implementations, respectively. However, the UPMEM distributed memory system can significantly hinder performance on certain workloads. Nonetheless, the efficiency of resource consumption for this approach, measured by peak performance fraction usage, is significantly higher than for both CPU and GPU.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PRISM, the first Processing-In-Memory approach for the sparse Matricized Tensor Times Khatri-Rao Product (spMTTKRP) in CP-ALS tensor decomposition on UPMEM PIM hardware. It characterizes partitioning strategies, number formats, and kernel optimizations, augmented by heterogeneous CPU collaboration. Experimental results report up to 2.37x (PIM-only) and 2.64x (heterogeneous) speedups over state-of-the-art CPU baselines, with higher peak-performance-fraction efficiency than CPU or GPU, while noting that UPMEM distributed memory can significantly hinder performance on certain workloads.
Significance. If the measured speedups prove representative across workloads and the partitioning strategies generalize, the work would demonstrate a practical path for accelerating memory-bound sparse tensor kernels via PIM, with explicit credit for the extensive characterization of partitioning, formats, and heterogeneous mapping that enables the reported gains.
major comments (2)
- [Abstract] Abstract and experimental results: the headline speedups of 2.37x/2.64x are reported without error bars, workload-size distributions, or baseline implementation details; this directly affects whether the central performance claim can be considered robust rather than potentially influenced by favorable sparsity patterns or tensor sizes.
- [Abstract] Abstract: the statement that 'the UPMEM distributed memory system can significantly hinder performance on certain workloads' is load-bearing for the generalization of the speedup claims, yet no quantification is provided of the fraction of tested workloads where speedup exceeds 1x versus where hindrance occurs; this leaves the representativeness of the headline numbers unverified.
minor comments (2)
- Clarify the exact state-of-the-art CPU baselines used (library versions, optimization flags) to allow direct reproduction of the reported speedups.
- Add a table or figure summarizing the fraction of workloads exhibiting speedup versus slowdown to address the generalization concern.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on the robustness of our performance claims. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of results.
read point-by-point responses
-
Referee: [Abstract] Abstract and experimental results: the headline speedups of 2.37x/2.64x are reported without error bars, workload-size distributions, or baseline implementation details; this directly affects whether the central performance claim can be considered robust rather than potentially influenced by favorable sparsity patterns or tensor sizes.
Authors: We agree that the abstract's headline numbers would benefit from additional context on variability and baselines. The full manuscript already includes per-tensor results across a range of sizes and sparsity patterns in Section 5, along with descriptions of the CPU baselines (state-of-the-art sparse MTTKRP implementations from the literature). To address the concern directly, we will add error bars (standard deviation across repeated runs) to the key speedup figures, include a summary table or histogram of workload sizes and sparsity levels, and expand the baseline implementation details in the experimental setup subsection. These changes will be reflected in both the abstract (if space permits) and the main text. revision: yes
-
Referee: [Abstract] Abstract: the statement that 'the UPMEM distributed memory system can significantly hinder performance on certain workloads' is load-bearing for the generalization of the speedup claims, yet no quantification is provided of the fraction of tested workloads where speedup exceeds 1x versus where hindrance occurs; this leaves the representativeness of the headline numbers unverified.
Authors: The manuscript already notes the hindrance effect and reports that the maximum speedups are 2.37x/2.64x while acknowledging cases below 1x. However, we did not include an explicit count or fraction of workloads in each category. We will add this quantification in the revised version by including a breakdown (e.g., number/percentage of tensors where PIM or heterogeneous execution exceeds 1x speedup versus those hindered), supported by the per-workload data already collected. This will be presented in a new table or as part of the existing results figures to clarify representativeness. revision: yes
Circularity Check
No circularity: experimental measurements only
full rationale
The paper is an experimental systems work reporting measured speedups (up to 2.37x/2.64x) on UPMEM PIM hardware for spMTTKRP. No derivations, equations, fitted parameters presented as predictions, or self-citation chains appear in the provided abstract or described claims. All performance numbers are direct empirical results, not reductions to inputs by construction. The paper itself notes workload-dependent hindrance, so no hidden self-definition or load-bearing self-citation is required for the central claim.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Tensor decompositions for learning latent variable models,
A. Anandkumar, R. Ge, D. Hsu, S. M. Kakade, and M. Telgarsky, “Tensor decompositions for learning latent variable models,”J. Mach. Learn. Res., vol. 15, no. 1, p. 2773–2832, Jan. 2014
2014
-
[2]
Uppipe: A novel pipeline management on in-memory processors for rna-seq quantification,
L.-C. Chen, C.-C. Ho, and Y .-H. Chang, “Uppipe: A novel pipeline management on in-memory processors for rna-seq quantification,” in 2023 60th ACM/IEEE Design Automation Conference (DAC), 2023, pp. 1–6
2023
-
[3]
Exploiting hierarchical parallelism and reusability in tensor kernel pro- cessing on heterogeneous hpc systems,
Y . Chen, G. Xiao, M. T. ¨Ozsu, Z. Tang, A. Y . Zomaya, and K. Li, “Exploiting hierarchical parallelism and reusability in tensor kernel pro- cessing on heterogeneous hpc systems,” in2022 IEEE 38th International Conference on Data Engineering (ICDE), 2022, pp. 2522–2535
2022
-
[4]
Dfacto: Distributed factorization of tensors,
J. H. Choi and S. Vishwanathan, “Dfacto: Distributed factorization of tensors,” inAdvances in Neural Information Processing Systems, Z. Ghahramani, M. Welling, C. Cortes, N. Lawrence, and K. Weinberger, Eds., vol. 27. Curran Associates, Inc., 2014
2014
-
[5]
A framework for high-throughput sequence alignment using real processing-in-memory systems,
S. Diab, A. Nassereldine, M. Alser, J. G ´omez Luna, O. Mutlu, and I. El Hajj, “A framework for high-throughput sequence alignment using real processing-in-memory systems,”Bioinformatics, vol. 39, no. 5, p. btad155, 03 2023. [Online]. Available: https://doi.org/10.1093/bioinformatics/btad155
-
[6]
High-throughput pairwise alignment with the wavefront algorithm using processing-in-memory,
S. Diab, A. Nassereldine, M. Alser, J. G. Luna, O. Mutlu, and I. E. Hajj, “High-throughput pairwise alignment with the wavefront algorithm using processing-in-memory,”arXiv preprint arXiv:2204.02085, 2022
-
[7]
GitHub - Dr-Noob/peakperf: Achieve peak performance on x86 CPUs and NVIDIA GPUs,
Dr-Noob, “GitHub - Dr-Noob/peakperf: Achieve peak performance on x86 CPUs and NVIDIA GPUs,” https://github.com/Dr-Noob/peakperf, 2021, [Accessed 02-02-2025]
2021
-
[8]
C. Giannoula, I. Fernandez, J. G. Luna, N. Koziris, G. Goumas, and O. Mutlu, “Sparsep: Towards efficient sparse matrix vector multiplication on real processing-in-memory architectures,”Proc. ACM Meas. Anal. Comput. Syst., vol. 6, no. 1, Feb. 2022. [Online]. Available: https://doi.org/10.1145/3508041
-
[9]
Benchmarking Memory-centric Computing Systems: Analysis of Real Processing-in-Memory Hardware,
J. G ´omez-Luna, I. E. Hajj, I. Fernandez, C. Giannoula, G. F. Oliveira, and O. Mutlu, “Benchmarking Memory-centric Computing Systems: Analysis of Real Processing-in-Memory Hardware,” in2021 12th Inter- national Green and Sustainable Computing Conference (IGSC). IEEE, 2021
2021
-
[10]
Foundations of the parafac procedure: Models and conditions for an “explanatory
R. A. Harshmanet al., “Foundations of the parafac procedure: Models and conditions for an “explanatory” multi-modal factor analysis,”UCLA working papers in phonetics, vol. 16, no. 1, p. 84, 1970
1970
-
[11]
Alto: adaptive linearized storage of sparse tensors,
A. E. Helal, J. Laukemann, F. Checconi, J. J. Tithi, T. Ranadive, F. Petrini, and J. Choi, “Alto: adaptive linearized storage of sparse tensors,” inProceedings of the 35th ACM International Conference on Supercomputing, ser. ICS ’21. New York, NY , USA: Association for Computing Machinery, 2021, p. 404–416. [Online]. Available: https://doi.org/10.1145/344...
-
[12]
Gigatensor: scaling tensor analysis up by 100 times - algorithms and discoveries,
U. Kang, E. Papalexakis, A. Harpale, and C. Faloutsos, “Gigatensor: scaling tensor analysis up by 100 times - algorithms and discoveries,” inProceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2012
2012
-
[13]
Parallel algorithms for tensor completion in the cp format,
L. Karlsson, D. Kressner, and A. Uschmajew, “Parallel algorithms for tensor completion in the cp format,”Parallel Computing, vol. 57, pp. 222–234, 2016. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0167819115001210
2016
-
[14]
Sparsity- aware tensor decomposition,
S. E. Kurt, S. Raje, A. Sukumaran-Rajam, and P. Sadayappan, “Sparsity- aware tensor decomposition,” in2022 IEEE International Parallel and Distributed Processing Symposium (IPDPS), 2022, pp. 952–962
2022
-
[15]
Scalable tensor decompositions in high performance computing environments,
J. Li, “Scalable tensor decompositions in high performance computing environments,” 2018
2018
-
[16]
Hicoo: Hierarchical storage of sparse tensors,
J. Li, J. Sun, and R. Vuduc, “Hicoo: Hierarchical storage of sparse tensors,” inSC18: International Conference for High Performance Computing, Networking, Storage and Analysis, 2018, pp. 238–252
2018
-
[17]
Design and analysis of a processing-in-dimm join algorithm: A case study with upmem dimms,
C. Lim, S. Lee, J. Choi, J. Lee, S. Park, H. Kim, J. Lee, and Y . Kim, “Design and analysis of a processing-in-dimm join algorithm: A case study with upmem dimms,”Proc. ACM Manag. Data, vol. 1, no. 2, Jun. 2023. [Online]. Available: https://doi.org/10.1145/3589258
-
[18]
A computer oriented geodetic data base and a new technique in file sequencing,
G. M. Morton, “A computer oriented geodetic data base and a new technique in file sequencing,” 1966
1966
-
[19]
Efficient, out-of-memory sparse mttkrp on massively parallel architectures,
A. Nguyen, A. E. Helal, F. Checconi, J. Laukemann, J. J. Tithi, Y . Soh, T. Ranadive, F. Petrini, and J. W. Choi, “Efficient, out-of-memory sparse mttkrp on massively parallel architectures,” inProceedings of the 36th ACM International Conference on Supercomputing, ser. ICS ’22. New York, NY , USA: Association for Computing Machinery,
-
[20]
Available: https://doi.org/10.1145/3524059.3532363
[Online]. Available: https://doi.org/10.1145/3524059.3532363
-
[21]
How much is an nvidia a100?
M. Shen, “How much is an nvidia a100?” 2024. [Online]. Available: https://modal.com/blog/nvidia-a100-price-article
2024
-
[22]
Smith, J
S. Smith, J. W. Choi, J. Li, R. Vuduc, J. Park, X. Liu, and G. Karypis. (2017) FROSTT: The formidable repository of open sparse tensors and tools. [Online]. Available: http://frostt.io/
2017
-
[23]
The true processing in mem- ory accelerator,
UPMEM, “The true processing in mem- ory accelerator,” 2019. [Online]. Available: https://old.hotchips.org/hc31/HC31 1.4 UPMEM.FabriceDevaux.v2 1.pdf
2019
-
[24]
Coding tips and recommended practices,
——, “Coding tips and recommended practices,” 2025. [Online]. Available: https://sdk.upmem.com/2025.1.0/fff CodingTips.html
2025
-
[25]
Robust iterative fitting of multilinear models,
S. V orobyov, Y . Rong, N. Sidiropoulos, and A. Gershman, “Robust iterative fitting of multilinear models,”IEEE Transactions on Signal Processing, vol. 53, no. 8, pp. 2678–2689, 2005
2005
-
[26]
Dynasor: A dynamic memory layout for accelerating sparse mttkrp for tensor decomposition on multi-core cpu,
S. Wijeratne, R. Kannan, and V . Prasanna, “Dynasor: A dynamic memory layout for accelerating sparse mttkrp for tensor decomposition on multi-core cpu,” in2023 IEEE 35th International Symposium on Computer Architecture and High Performance Computing (SBAC-PAD), 2023, pp. 23–33
2023
-
[27]
Sparse mttkrp acceleration for tensor decomposition on gpu,
——, “Sparse mttkrp acceleration for tensor decomposition on gpu,” inProceedings of the 21st ACM International Conference on Computing Frontiers, ser. CF ’24. New York, NY , USA: Association for Computing Machinery, 2024, p. 88–96. [Online]. Available: https://doi.org/10.1145/3649153.3649187
-
[28]
Accelerating sparse mttkrp for tensor decomposition on fpga,
S. Wijeratne, T.-Y . Wang, R. Kannan, and V . Prasanna, “Accelerating sparse mttkrp for tensor decomposition on fpga,” inProceedings of the 2023 ACM/SIGDA International Symposium on Field Programmable Gate Arrays, ser. FPGA ’23. New York, NY , USA: Association for Computing Machinery, 2023, p. 259–269. [Online]. Available: https://doi.org/10.1145/3543622.3573179
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.