FlexiSLM: A Dynamic and Controllable Frame Rate Spoken Language Model
Pith reviewed 2026-07-01 03:46 UTC · model grok-4.3
The pith
FlexiSLM is the first spoken language model with dynamic and controllable frame rates for both speech input and output.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
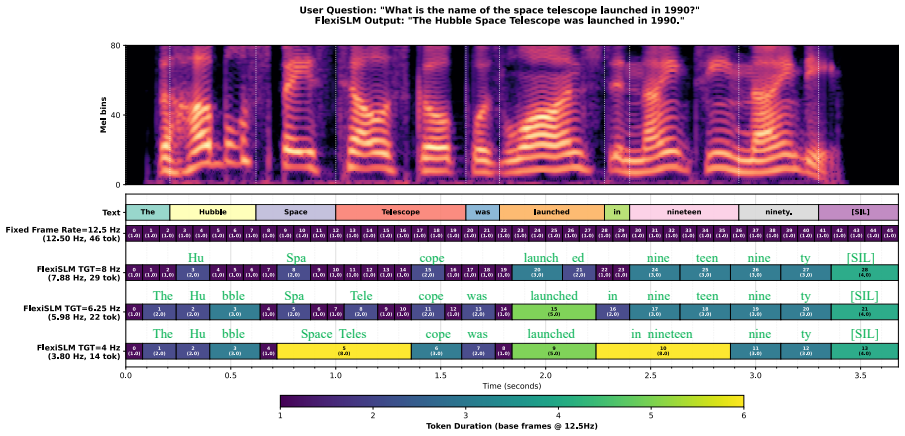
FlexiSLM supports dynamic and controllable frame rates on both speech input and output. Using these representations, it outperforms fixed-frame-rate 7B models including Qwen2.5-Omni and Kimi-Audio at high-quality operating points. It can be steered down to 4.0 Hz, and at 6.25 Hz it halves inference time relative to 12.5 Hz while keeping strong speech-to-speech quality.
What carries the argument
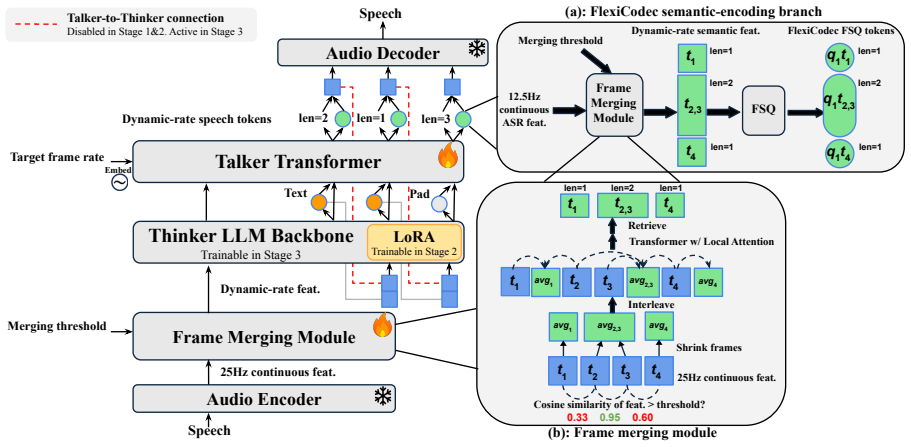
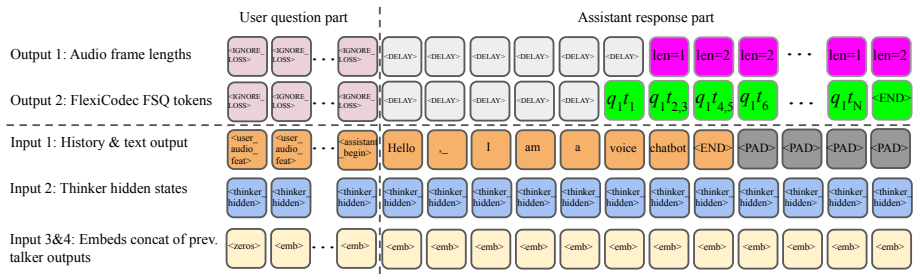
Dynamic frame rate representations integrated into the spoken language model that enable variable rates on input and output.
If this is right
- Outperforms fixed-frame-rate 7B models at high-quality operating points.
- Can be steered accurately down to frame rates as low as 4.0 Hz.
- At 6.25 Hz roughly halves inference time relative to 12.5 Hz while retaining strong quality.
- Provides inference-time controllability to trade quality for speed.
Where Pith is reading between the lines
- The same dynamic-rate approach may extend to other multimodal language models that process non-uniform signals.
- Inference controllability could support new real-time applications where latency targets are set by the user.
Load-bearing premise
Dynamic frame rate speech coding techniques from audio tokenizers transfer effectively when integrated into spoken language models.
What would settle it
Experiments in which FlexiSLM fails to outperform fixed-frame-rate models at equivalent high-quality operating points or in which lowering the frame rate produces no reduction in inference time.
Figures

read the original abstract
Spoken language models (SLMs) extend LLMs to speech input and output. Existing SLMs represent speech at fixed frame rates (e.g., 25 or 12.5 Hz), ignoring the time-varying information density of speech and offering no flexibility to trade off quality for speed at inference time. Recent audio tokenizer research has proposed dynamic frame rate speech coding, which exploits this non-uniformity and enables two new capabilities: very low average frame rates and frame rate controllability. However, this technique has not yet been applied to SLMs. We introduce Flexible Spoken Language Model (FlexiSLM), the first SLM that supports dynamic and controllable frame rates on both speech input and output. Using dynamic frame rate representations, FlexiSLM outperforms fixed-frame-rate 7B models including Qwen2.5-Omni and Kimi-Audio at its high-quality operating points. We further verify that FlexiSLM can be accurately steered down to 4.0 Hz; at 6.25 Hz, it roughly halves inference time relative to 12.5 Hz while retaining strong speech-to-speech quality. Audio samples are available at https://flexislm.github.io .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FlexiSLM, the first spoken language model supporting dynamic and controllable frame rates on both speech input and output by integrating dynamic frame rate speech coding from audio tokenizers. It claims outperformance over fixed-frame-rate 7B models (Qwen2.5-Omni, Kimi-Audio) at high-quality operating points and demonstrates controllability down to 4.0 Hz, with 6.25 Hz halving inference time while retaining strong speech-to-speech quality. Audio samples are linked.
Significance. If the empirical results hold, the work is significant for spoken language models by enabling inference-time trade-offs between quality and speed via dynamic rates, extending tokenizer techniques to SLMs in a novel way and addressing a limitation of fixed-rate models.
minor comments (2)
- Abstract lacks any mention of specific metrics, baselines, datasets, or experimental setup used to support the outperformance and controllability claims; this should be summarized briefly even in the abstract for clarity.
- The manuscript should include a dedicated section or table detailing the exact frame rate operating points tested, corresponding quality metrics, and inference time measurements to allow direct comparison with the cited 7B baselines.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of FlexiSLM and the recommendation for minor revision. The review correctly identifies the core contributions around dynamic frame-rate controllability and its potential for quality-speed trade-offs in spoken language models. No major comments were provided in the report, so we have no specific points requiring response or rebuttal at this stage. We remain available to address any minor revisions or clarifications the editor may request.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents FlexiSLM as the first integration of dynamic frame rate speech coding (previously developed for audio tokenizers) into spoken language models for both input and output. Central claims rest on empirical outperformance versus fixed-rate baselines and controllability verification at specific frame rates (e.g., 4.0 Hz, 6.25 Hz), with no equations, fitted parameters, or self-citations that reduce any prediction or uniqueness claim to the inputs by construction. No self-definitional steps, fitted-input-as-prediction, or ansatz smuggling via citation are present in the provided abstract or description. The work is a straightforward architectural application with external benchmarks, making the derivation self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[2]
Rosana Ardila, Megan Branson, Kelly Davis, Michael Kohler, Josh Meyer, Michael Henretty, Reuben Morais, Lindsay Saunders, Francis Tyers, and Gregor Weber. 2020. Common voice: A massively-multilingual speech corpus. In Proceedings of the twelfth language resources and evaluation conference, pages 4218--4222
2020
-
[5]
Jonathan Berant, Andrew Chou, Roy Frostig, and Percy Liang. 2013. https://aclanthology.org/D13-1160/ Semantic parsing on F reebase from question-answer pairs . In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, pages 1533--1544, Seattle, Washington, USA. Association for Computational Linguistics
2013
-
[6]
Zal \'a n Borsos, Rapha \"e l Marinier, Damien Vincent, Eugene Kharitonov, Olivier Pietquin, Matt Sharifi, Dominik Roblek, Olivier Teboul, David Grangier, Marco Tagliasacchi, and 1 others. 2023. Audiolm: a language modeling approach to audio generation. IEEE/ACM transactions on audio, speech, and language processing, 31:2523--2533
2023
-
[7]
Houwei Cao, David G Cooper, Michael K Keutmann, Ruben C Gur, Ani Nenkova, and Ragini Verma. 2014. Crema-d: Crowd-sourced emotional multimodal actors dataset. IEEE transactions on affective computing, 5(4):377--390
2014
-
[17]
Jesse Engel, Cinjon Resnick, Adam Roberts, Sander Dieleman, Mohammad Norouzi, Douglas Eck, and Karen Simonyan. 2017. Neural audio synthesis of musical notes with wavenet autoencoders. In International conference on machine learning, pages 1068--1077. PMLR
2017
-
[18]
Sefik Emre Eskimez, Xiaofei Wang, Manthan Thakker, Canrun Li, Chung-Hsien Tsai, Zhen Xiao, Hemin Yang, Zirun Zhu, Min Tang, Xu Tan, and 1 others. 2024. E2 tts: Embarrassingly easy fully non-autoregressive zero-shot tts. In 2024 IEEE Spoken Language Technology Workshop (SLT), pages 682--689. IEEE
2024
-
[20]
Yuan Gong, Jin Yu, and James Glass. 2022. Vocalsound: A dataset for improving human vocal sounds recognition. In ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 151--155. IEEE
2022
-
[22]
Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, and Abdelrahman Mohamed. 2021. Hubert: Self-supervised speech representation learning by masked prediction of hidden units. IEEE/ACM transactions on audio, speech, and language processing, 29:3451--3460
2021
-
[23]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, and 1 others. 2022. Lora: Low-rank adaptation of large language models. Iclr, 1(2):3
2022
-
[28]
Matthew Le, Apoorv Vyas, Bowen Shi, Brian Karrer, Leda Sari, Rashel Moritz, Mary Williamson, Vimal Manohar, Yossi Adi, Jay Mahadeokar, and 1 others. 2023. Voicebox: Text-guided multilingual universal speech generation at scale. Advances in neural information processing systems, 36:14005--14034
2023
-
[29]
Jiaqi Li, Xiaolong Lin, Zhekai Li, Shixi Huang, Yuancheng Wang, Chaoren Wang, Zhenpeng Zhan, and Zhizheng Wu. 2025 a . Dualcodec: A low-frame-rate, semantically-enhanced neural audio codec for speech generation. In Proceedings of Interspeech 2025
2025
-
[32]
Hashimoto
Xuechen Li, Tianyi Zhang, Yann Dubois, Rohan Taori, Ishaan Gulrajani, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. 2023. Alpacaeval: An automatic evaluator of instruction-following models. https://github.com/tatsu-lab/alpaca_eval
2023
-
[36]
Aleksandr Meister, Matvei Novikov, Nikolay Karpov, Evelina Bakhturina, Vitaly Lavrukhin, and Boris Ginsburg. 2023. Librispeech-pc: Benchmark for evaluation of punctuation and capitalization capabilities of end-to-end asr models. In 2023 IEEE automatic speech recognition and understanding workshop (ASRU), pages 1--7. IEEE
2023
-
[38]
Eliya Nachmani, Alon Levkovitch, Roy Hirsch, Julian Salazar, Chulayuth Asawaroengchai, Soroosh Mariooryad, Ehud Rivlin, RJ Skerry-Ryan, and Michelle Tadmor Ramanovich. 2024. https://openreview.net/forum?id=izrOLJov5y Spoken question answering and speech continuation using spectrogram-powered LLM . In The Twelfth International Conference on Learning Repres...
2024
-
[39]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, and 1 others. 2022. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730--27744
2022
-
[40]
Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur. 2015. Librispeech: an asr corpus based on public domain audio books. In 2015 IEEE international conference on acoustics, speech and signal processing (ICASSP), pages 5206--5210. IEEE
2015
-
[41]
Soujanya Poria, Devamanyu Hazarika, Navonil Majumder, Gautam Naik, Erik Cambria, and Rada Mihalcea. 2019. Meld: A multimodal multi-party dataset for emotion recognition in conversations. In Proceedings of the 57th annual meeting of the association for computational linguistics, pages 527--536
2019
-
[43]
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. 2023. Robust speech recognition via large-scale weak supervision. In International conference on machine learning, pages 28492--28518. PMLR
2023
-
[44]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. 2023. Direct preference optimization: Your language model is secretly a reward model. Advances in Neural Information Processing Systems, 36:53728--53741
2023
-
[45]
Jeff Rasley, Samyam Rajbhandari, Olatunji Ruwase, and Yuxiong He. 2020. Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters. In Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining, pages 3505--3506
2020
-
[50]
Hashimoto
Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. 2023. Stanford alpaca: An instruction-following LLaMA model. https://github.com/tatsu-lab/stanford_alpaca
2023
-
[51]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, ukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. Advances in neural information processing systems, 30
2017
-
[55]
Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, Bin Zhang, Xiong Wang, Yunfei Chu, and Junyang Lin. 2025 a . https://arxiv.org/abs/2503.20215 Qwen2.5-omni technical report . Preprint, arXiv:2503.20215
Pith/arXiv arXiv 2025
-
[57]
Zhangchen Xu, Fengqing Jiang, Luyao Niu, Yuntian Deng, Radha Poovendran, Yejin Choi, and Bill Yuchen Lin. 2025 c . Magpie: Alignment data synthesis from scratch by prompting aligned LLM s with nothing. In The Thirteenth International Conference on Learning Representations
2025
-
[58]
Junichi Yamagishi, Christophe Veaux, and Kirsten MacDonald. 2019. Cstr vctk corpus: English multi-speaker corpus for cstr voice cloning toolkit (version 0.92). The Rainbow Passage which the speakers read out can be found in the International Dialects of English Archive:(http://web. ku. edu/\ idea/readings/rainbow. htm)
2019
-
[60]
Neil Zeghidour, Alejandro Luebs, Ahmed Omran, Jan Skoglund, and Marco Tagliasacchi. 2021. Soundstream: An end-to-end neural audio codec. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 30:495--507
2021
-
[65]
Wenting Zhao, Xiang Ren, Jack Hessel, Claire Cardie, Yejin Choi, and Yuntian Deng. 2024. WildChat : 1m ChatGPT interaction logs in the wild. In The Twelfth International Conference on Learning Representations
2024
-
[69]
arXiv preprint arXiv:2504.08528 , year=
On the landscape of spoken language models: A comprehensive survey , author=. arXiv preprint arXiv:2504.08528 , year=
-
[70]
arXiv preprint arXiv:2601.05543 , year=
Closing the Modality Reasoning Gap for Speech Large Language Models , author=. arXiv preprint arXiv:2601.05543 , year=
-
[71]
arXiv preprint arXiv:2410.07168 , year=
Sylber: Syllabic embedding representation of speech from raw audio , author=. arXiv preprint arXiv:2410.07168 , year=
-
[72]
arXiv preprint arXiv:2510.00981 , year=
FlexiCodec: A Dynamic Neural Audio Codec for Low Frame Rates , author=. arXiv preprint arXiv:2510.00981 , year=
-
[73]
arXiv preprint arXiv:1308.3432 , year=
Estimating or propagating gradients through stochastic neurons for conditional computation , author=. arXiv preprint arXiv:1308.3432 , year=
-
[74]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[75]
(No Title) , year=
TIMIT acoustic-phonetic continuous speech corpus , author=. (No Title) , year=
-
[76]
arXiv preprint arXiv:2406.06992 , year=
Scaling up masked audio encoder learning for general audio classification , author=. arXiv preprint arXiv:2406.06992 , year=
-
[77]
arXiv preprint arXiv:2512.23808 , year=
MiMo-Audio: Audio Language Models are Few-Shot Learners , author=. arXiv preprint arXiv:2512.23808 , year=
-
[78]
Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining , pages=
Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters , author=. Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining , pages=
-
[79]
arXiv preprint arXiv:2411.18138 , year=
Salmonn-omni: A codec-free llm for full-duplex speech understanding and generation , author=. arXiv preprint arXiv:2411.18138 , year=
-
[80]
, author=
Lora: Low-rank adaptation of large language models. , author=. Iclr , volume=
-
[81]
arXiv preprint arXiv:2012.03411 , year=
Mls: A large-scale multilingual dataset for speech research , author=. arXiv preprint arXiv:2012.03411 , year=
Pith/arXiv arXiv 2012
-
[82]
arXiv preprint arXiv:2508.15418 , year=
LLaSO: A Foundational Framework for Reproducible Research in Large Language and Speech Model , author=. arXiv preprint arXiv:2508.15418 , year=
-
[83]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[84]
arXiv preprint arXiv:2505.16845 , year=
Unlocking Temporal Flexibility: Neural Speech Codec with Variable Frame Rate , author=. arXiv preprint arXiv:2505.16845 , year=
-
[85]
Overview of the Amphion Toolkit (v0. 2) , author=. arXiv preprint arXiv:2501.15442 , year=
-
[86]
2024 IEEE Spoken Language Technology Workshop (SLT) , pages=
Investigating neural audio codecs for speech language model-based speech generation , author=. 2024 IEEE Spoken Language Technology Workshop (SLT) , pages=. 2024 , organization=
2024
-
[87]
Advances in neural information processing systems , volume=
Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis , author=. Advances in neural information processing systems , volume=
-
[88]
Advances in Neural Information Processing Systems , volume=
Neural networks fail to learn periodic functions and how to fix it , author=. Advances in Neural Information Processing Systems , volume=
-
[89]
arXiv preprint arXiv:2509.04685 , year=
Say More with Less: Variable-Frame-Rate Speech Tokenization via Adaptive Clustering and Implicit Duration Coding , author=. arXiv preprint arXiv:2509.04685 , year=
-
[90]
2023 IEEE automatic speech recognition and understanding workshop (ASRU) , pages=
Librispeech-pc: Benchmark for evaluation of punctuation and capitalization capabilities of end-to-end asr models , author=. 2023 IEEE automatic speech recognition and understanding workshop (ASRU) , pages=. 2023 , organization=
2023
-
[91]
ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Libriheavy: A 50,000 hours ASR corpus with punctuation casing and context , author=. ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2024 , organization=
2024
-
[92]
2024 IEEE Spoken Language Technology Workshop (SLT) , pages=
E2 tts: Embarrassingly easy fully non-autoregressive zero-shot tts , author=. 2024 IEEE Spoken Language Technology Workshop (SLT) , pages=. 2024 , organization=
2024
-
[93]
arXiv preprint arXiv:2505.17589 , year=
Cosyvoice 3: Towards in-the-wild speech generation via scaling-up and post-training , author=. arXiv preprint arXiv:2505.17589 , year=
-
[94]
arXiv preprint arXiv:2504.07053 , year=
TASTE: Text-Aligned Speech Tokenization and Embedding for Spoken Language Modeling , author=. arXiv preprint arXiv:2504.07053 , year=
-
[95]
arXiv preprint arXiv:2411.01156 , year=
Fish-speech: Leveraging large language models for advanced multilingual text-to-speech synthesis , author=. arXiv preprint arXiv:2411.01156 , year=
-
[96]
ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Libri-light: A benchmark for asr with limited or no supervision , author=. ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2020 , organization=
2020
-
[97]
arXiv preprint arXiv:2508.16790 , year=
TaDiCodec: Text-aware Diffusion Speech Tokenizer for Speech Language Modeling , author=. arXiv preprint arXiv:2508.16790 , year=
-
[98]
arXiv preprint arXiv:2410.04029 , year=
Syllablelm: Learning coarse semantic units for speech language models , author=. arXiv preprint arXiv:2410.04029 , year=
-
[99]
ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Sd-hubert: Sentence-level self-distillation induces syllabic organization in hubert , author=. ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2024 , organization=
2024
-
[100]
arXiv preprint arXiv:2407.04051 , year=
Funaudiollm: Voice understanding and generation foundation models for natural interaction between humans and llms , author=. arXiv preprint arXiv:2407.04051 , year=
-
[101]
1996 IEEE international conference on acoustics, speech, and signal processing conference proceedings , volume=
Unit selection in a concatenative speech synthesis system using a large speech database , author=. 1996 IEEE international conference on acoustics, speech, and signal processing conference proceedings , volume=. 1996 , organization=
1996
-
[102]
arXiv preprint arXiv:2502.07243 , year=
Vevo: Controllable zero-shot voice imitation with self-supervised disentanglement , author=. arXiv preprint arXiv:2502.07243 , year=
-
[103]
International conference on machine learning , pages=
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[104]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
A convnet for the 2020s , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[105]
arXiv preprint arXiv:1703.10135 , year=
Tacotron: Towards end-to-end speech synthesis , author=. arXiv preprint arXiv:1703.10135 , year=
-
[106]
arXiv preprint arXiv:2406.07422 , year=
Single-codec: Single-codebook speech codec towards high-performance speech generation , author=. arXiv preprint arXiv:2406.07422 , year=
-
[107]
arXiv preprint arXiv:1609.03499 , volume=
Wavenet: A generative model for raw audio , author=. arXiv preprint arXiv:1609.03499 , volume=
-
[108]
arXiv preprint arXiv:2411.18803 , year=
Ts3-codec: Transformer-based simple streaming single codec , author=. arXiv preprint arXiv:2411.18803 , year=
-
[109]
arXiv preprint arXiv:2506.23325 , year=
XY-Tokenizer: Mitigating the Semantic-Acoustic Conflict in Low-Bitrate Speech Codecs , author=. arXiv preprint arXiv:2506.23325 , year=
-
[110]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[111]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[112]
arXiv preprint arXiv:2402.08093 , year=
BASE TTS: Lessons from building a billion-parameter text-to-speech model on 100K hours of data , author=. arXiv preprint arXiv:2402.08093 , year=
-
[113]
arXiv preprint arXiv:2305.07243 , year=
Better speech synthesis through scaling , author=. arXiv preprint arXiv:2305.07243 , year=
-
[114]
arXiv preprint arXiv:2207.12598 , year=
Classifier-free diffusion guidance , author=. arXiv preprint arXiv:2207.12598 , year=
-
[115]
arXiv preprint arXiv:2306.17806 , year=
Stay on topic with classifier-free guidance , author=. arXiv preprint arXiv:2306.17806 , year=
-
[116]
arXiv preprint arXiv:2306.00814 , year=
Vocos: Closing the gap between time-domain and Fourier-based neural vocoders for high-quality audio synthesis , author=. arXiv preprint arXiv:2306.00814 , year=
-
[117]
Advances in Neural Information Processing Systems , volume=
High-fidelity audio compression with improved rvqgan , author=. Advances in Neural Information Processing Systems , volume=
-
[118]
arXiv preprint arXiv:2206.04658 , year=
Bigvgan: A universal neural vocoder with large-scale training , author=. arXiv preprint arXiv:2206.04658 , year=
-
[119]
arXiv preprint arXiv:2307.09288 , year=
Llama 2: Open foundation and fine-tuned chat models , author=. arXiv preprint arXiv:2307.09288 , year=
-
[120]
arXiv preprint arXiv:2312.09911 , year=
Amphion: An Open-Source Audio, Music and Speech Generation Toolkit , author=. arXiv preprint arXiv:2312.09911 , year=
-
[121]
arXiv preprint arXiv:2210.13438 , year=
High fidelity neural audio compression , author=. arXiv preprint arXiv:2210.13438 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.