Floating-point autotuning with customized precisions
Pith reviewed 2026-06-27 18:42 UTC · model grok-4.3
The pith
Automated precision tuning finds mixed-precision floating-point configurations that reduce many variables to lower precision while preserving required accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that customized floating-point formats combined with numerical validation and systematic search generate valid mixed-precision program variants, and evaluation on numerical codes shows that a substantial proportion of variables can be safely lowered in precision while accuracy requirements remain satisfied.
What carries the argument
The PROMISE precision autotuning tool, which combines numerical validation with systematic search over user-defined exponent and significand sizes to produce accuracy-compliant program variants.
If this is right
- Standard double precision is often over-provisioned for the accuracy demands of the tested linear solvers and benchmark applications.
- Mixed-precision configurations can be derived automatically for a range of numerical programs to reduce resource use while respecting accuracy constraints.
- Customized exponent and significand sizes enable exploration of both emerging low-precision formats and non-standard configurations in a single framework.
- Containerized parallel benchmarking allows the search process to scale across multiple algorithms and parameter sets.
Where Pith is reading between the lines
- If such autotuning were integrated into compilers, many existing double-precision codes could be rewritten with lower memory footprints without manual intervention.
- The results raise the question of whether hardware designers should prioritize support for a wider set of custom precisions rather than fixed formats.
- Similar search-plus-validation loops could be applied to other resource-accuracy trade-offs, such as choosing between different numerical algorithms.
Load-bearing premise
The combination of numerical validation and systematic search correctly identifies precision settings that meet accuracy requirements without missing errors introduced by the emulation or testing process.
What would settle it
Take a program variant produced by the tool, execute it on a fresh set of inputs or a different architecture, and observe whether accuracy falls below the user-specified threshold.
Figures
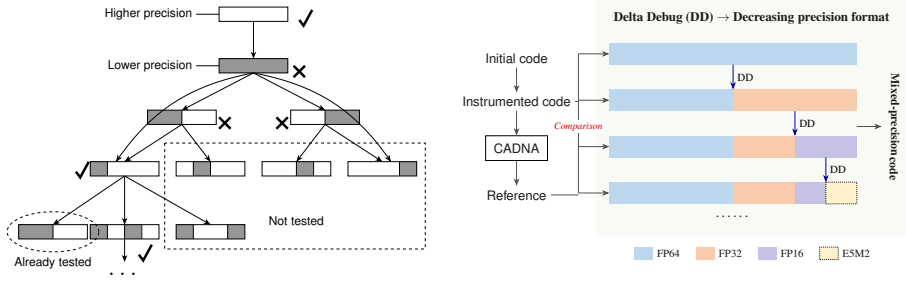


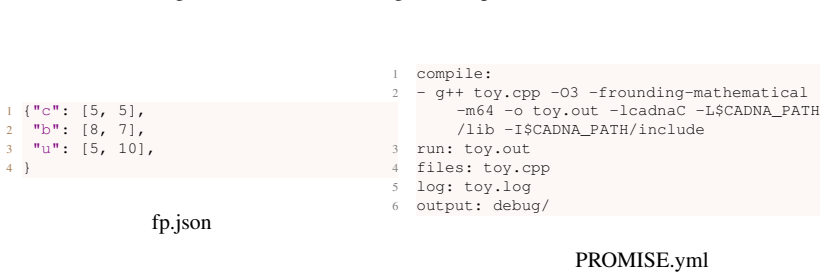

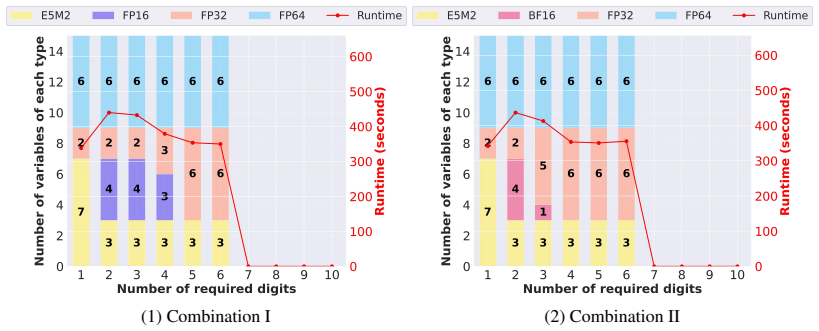
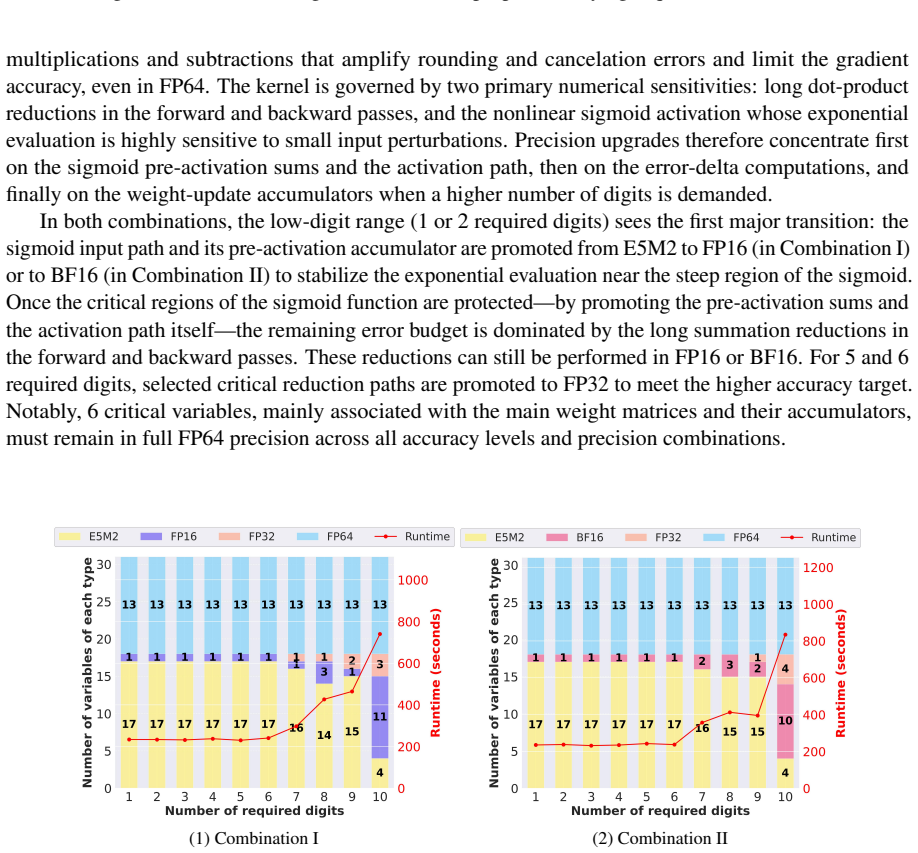
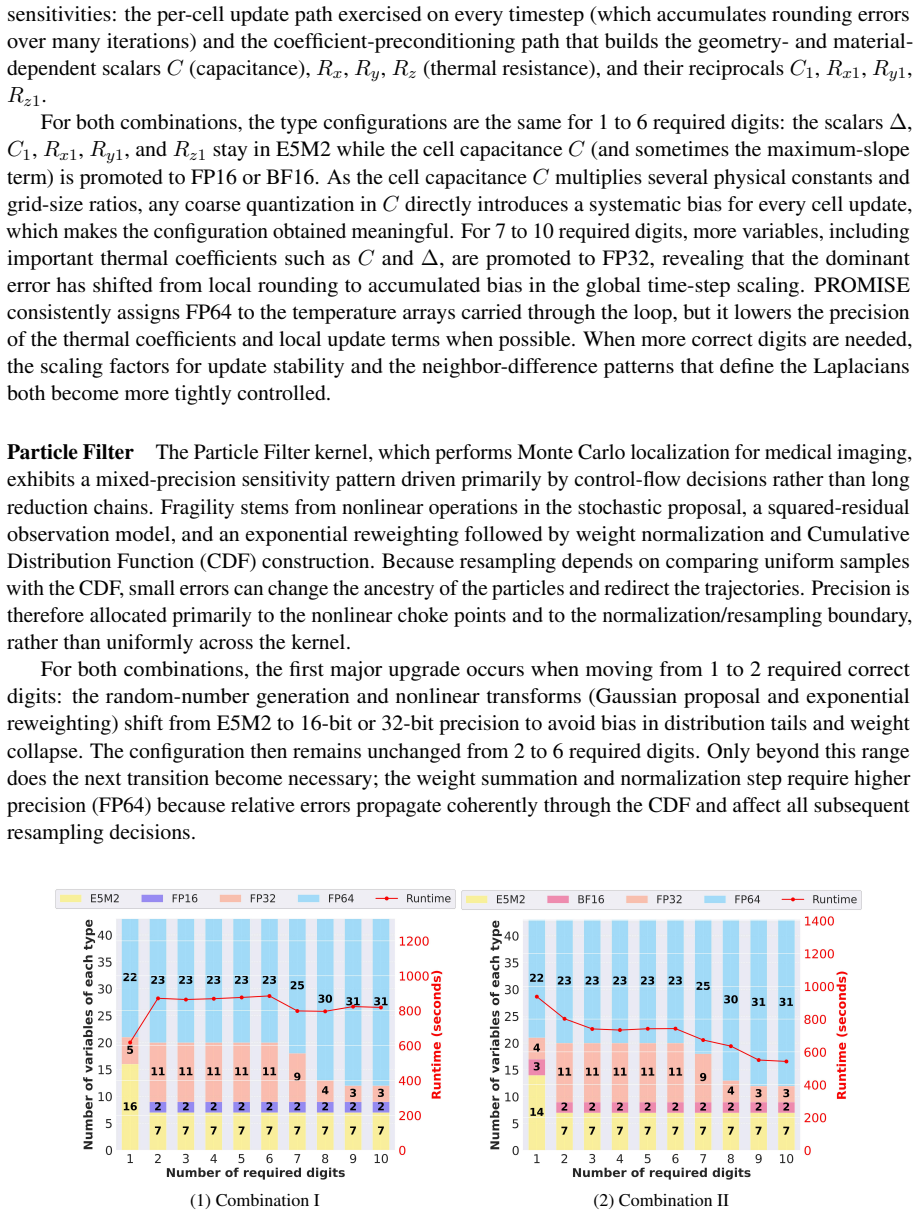
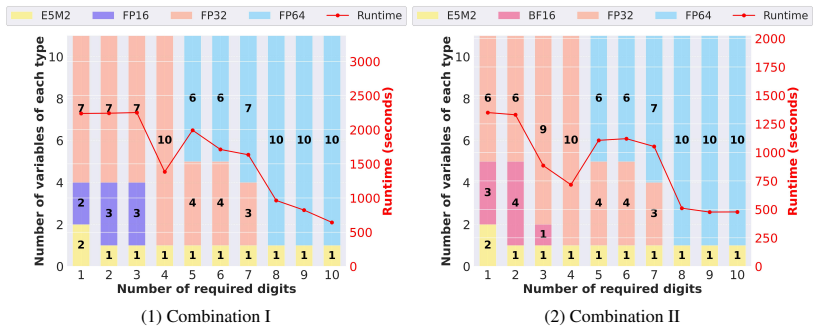
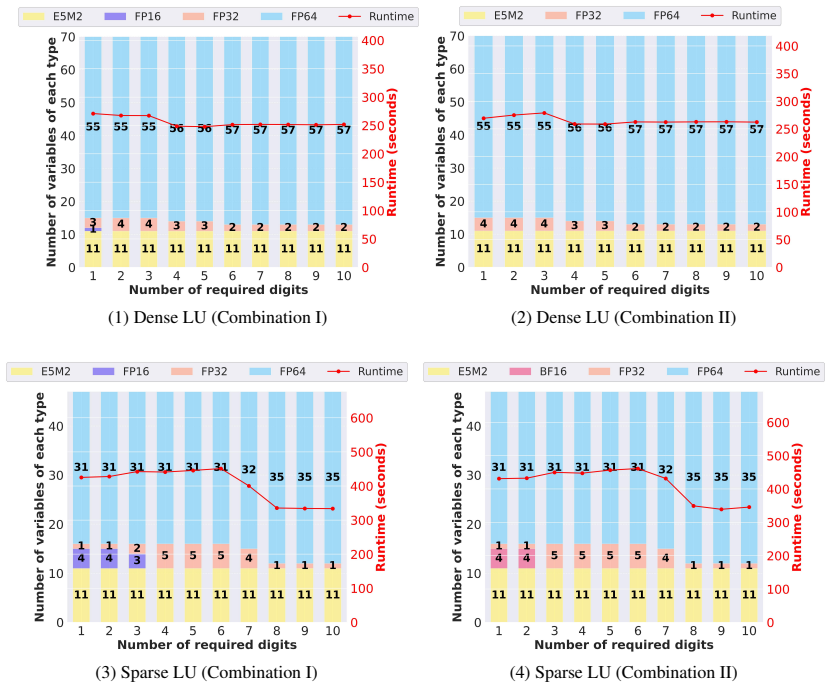
read the original abstract
Reduced-precision arithmetic offers significant opportunities to improve performance, memory usage, and energy efficiency in numerical applications, provided that numerical accuracy is preserved. This work investigates automated precision tuning through customized floating-point formats with user-defined exponent and significand sizes, enabling the emulation of emerging low-precision formats and the exploration of non-standard precision configurations within a unified mixed-precision framework. The proposed methodology, implemented in the PROMISE precision autotuning tool, combines numerical validation with a systematic search to generate program variants that satisfy user-defined accuracy requirements. To address the computational cost of this exploration, a containerized benchmarking framework supports parallel execution across multiple algorithms and parameter configurations. The approach is evaluated on a suite of numerical programs, including linear solvers and applications from the Rodinia benchmark. Results show that a substantial proportion of variables can be safely reduced to lower precision while preserving accuracy, indicating that standard double precision is often over-provisioned. These findings highlight the potential of automated precision tuning to derive efficient mixed-precision configurations tailored to application-specific accuracy requirements.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents the PROMISE precision autotuning tool for floating-point applications. It supports customized floating-point formats with user-defined exponent and significand bit widths to emulate low-precision formats within a mixed-precision framework. The tool combines numerical validation against user-specified accuracy requirements with a systematic search over precision configurations; a containerized parallel benchmarking framework is used to manage the computational cost of the exploration. Evaluation on linear solvers and Rodinia benchmarks indicates that a substantial proportion of variables can be reduced to lower precision while meeting accuracy targets, suggesting that double precision is frequently over-provisioned.
Significance. If the empirical validation is robust, the work demonstrates a practical automated method for deriving application-specific mixed-precision configurations that exploit custom exponent/significand formats. This directly addresses performance, memory, and energy opportunities in numerical computing while providing a unified framework that includes both standard and non-standard precisions. The containerized benchmarking component is a concrete engineering contribution that enables reproducible parallel evaluation across multiple programs and configurations.
major comments (1)
- [Abstract] Abstract and overall description: the central claim that 'a substantial proportion of variables can be safely reduced to lower precision while preserving accuracy' rests on the combination of numerical validation and systematic search, yet no details are supplied on the accuracy metric used, the search algorithm itself, or how emulation errors are bounded. This information is load-bearing for verifying that the reported configurations satisfy requirements without undetected violations.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The single major comment highlights a valid gap in the abstract's description of key methodological components. We will revise the manuscript to address this.
read point-by-point responses
-
Referee: [Abstract] Abstract and overall description: the central claim that 'a substantial proportion of variables can be safely reduced to lower precision while preserving accuracy' rests on the combination of numerical validation and systematic search, yet no details are supplied on the accuracy metric used, the search algorithm itself, or how emulation errors are bounded. This information is load-bearing for verifying that the reported configurations satisfy requirements without undetected violations.
Authors: We agree that the abstract does not provide sufficient detail on these load-bearing elements. The full manuscript describes the accuracy metric (user-specified relative or absolute error tolerances validated against a reference implementation), the search algorithm (a systematic enumeration combined with pruning based on numerical validation), and emulation error bounding (via interval arithmetic and cross-validation against higher-precision runs) in Sections 3 and 4. However, these details are not summarized at the abstract level. In the revised manuscript we will expand the abstract with a concise description of the accuracy metric, search procedure, and error-control approach so that the central claim can be evaluated directly from the abstract. revision: yes
Circularity Check
No significant circularity; empirical search+validation is independent of inputs
full rationale
The paper describes an engineering tool (PROMISE) that performs systematic search over custom floating-point formats combined with numerical validation against user-specified accuracy requirements. No derivation chain reduces a claimed result to its own fitted parameters by construction, no self-citation is load-bearing for a uniqueness theorem, and no ansatz or renaming is presented as a first-principles prediction. The central empirical finding (many variables safely reduced) is produced by external benchmark execution and accuracy checks that are not tautological with the search procedure itself. This is the normal case of a self-contained experimental paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InIEEE International Symposium on Workload Characterization
Rodinia: A benchmark suite for heterogeneous computing. InIEEE International Symposium on Workload Characterization. 44–54. doi:10.1109/IISWC.2009.5306797 Stefano Cherubin and Giovanni Agosta
-
[2]
Tools for Reduced Precision Computation: A Survey. ACM Comput. Surv.53, 2 (April 2020), 35 pages. doi:10.1145/3381039 Wei-Fan Chiang, Mark Baranowski, Ian Briggs, Alexey Solovyev, Ganesh Gopalakrishnan, and Zvonimir Rakamari´c
-
[3]
InProceedings of the 44th ACM SIGPLAN Symposium on Principles of Programming Languages (POPL ’17)
Rigorous floating-point mixed-precision tuning. InProceedings of the 44th ACM SIGPLAN Symposium on Principles of Programming Languages (POPL ’17). ACM, USA, 300–315. doi:10.1145/3009837.3009846 Timothy A. Davis and Yifan Hu
-
[4]
The University of Florida sparse matrix collection.ACM Trans. Math. Software38, 1 (2011), 1–25. doi:10.1145/2049662.2049663 P. Eberhart, J. Brajard, P. Fortin, and F. Jézéquel
-
[5]
Quentin Ferro, Stef Graillat, Thibault Hilaire, and Fabienne Jézéquel
High Performance Numerical Validation using Stochastic Arithmetic.Reliable Computing21 (2015), 35–52. Quentin Ferro, Stef Graillat, Thibault Hilaire, and Fabienne Jézéquel
2015
-
[6]
In2023 IEEE 16th International Symposium on Embedded Multicore/Many-core Systems-on-Chip (MCSoC)
Performance of precision auto- tuned neural networks. In2023 IEEE 16th International Symposium on Embedded Multicore/Many-core Systems-on-Chip (MCSoC). 592–599. doi:10.1109/MCSoC60832.2023.00092 Goran Flegar, Florian Scheidegger, Vedran Novakovi´c, Giovani Mariani, Andrés E. Tomás, A. Cristiano I. Malossi, and Enrique S. Quintana-Ortí
-
[7]
FloatX: A C++ Library for Customized Floating-Point Arithmetic.ACM Trans. Math. Softw.45, 4, Article 40 (Dec. 2019), 23 pages. doi: 10.1145/ 3368086 Laurent Fousse, Guillaume Hanrot, Vincent Lefèvre, Patrick Pélissier, and Paul Zimmermann
2019
-
[8]
Algorithm 866: IFISS, a Matlab toolbox for modelling incompressible flow
MPFR: A multiple-precision binary floating-point library with correct rounding. 33, 2 (2007), 13–es. doi:10.1145/1236463.1236468 Gene H. Golub and Charles F. Van Loan. 2013.Matrix Computations(4 ed.). Johns Hopkins University Press, Baltimore. Stef Graillat, Fabienne Jézéquel, Romain Picot, François Févotte, and Bruno Lathuilière
-
[9]
doi:10.1016/j.jocs.2019.07.004 Hui Guo and Cindy Rubio-González
Auto- tuning for floating-point precision with Discrete Stochastic Arithmetic.Journal of Computational Science36 (2019), 101017. doi:10.1016/j.jocs.2019.07.004 Hui Guo and Cindy Rubio-González
-
[10]
Exploiting community structure for floating-point precision tuning. InProceedings of the 27th ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA 2018). ACM, USA, 333–343. doi:10.1145/3213846.3213862 Nicholas J. Higham and Theo Mary
-
[11]
doi:10.1017/S0962492922000022 IEEE Computer Society
Mixed precision algorithms in numerical linear algebra.Acta Numerica31 (2022), 347–414. doi:10.1017/S0962492922000022 IEEE Computer Society
-
[12]
IEEE Standard for Floating-Point Arithmetic.IEEE Std 754-2019(2019). doi:10.1109/IEEESTD.2019.8766229 F. Jézéquel and J.-M. Chesneaux
-
[13]
Computer Physics Communications178, 12 (2008), 933–955
CADNA: A Library for Estimating Round-Off Error Propagation. Computer Physics Communications178, 12 (2008), 933–955. doi: 10.1016/j.cpc.2008.02. 013 16 Fabienne Jézéquel, Sara sadat Hoseininasab, and Thibault Hilaire
-
[14]
arXiv:2412.19322 [cs.CE]https://arxiv.org/abs/2412.19322 Michael O Lam and Jeffrey K Hollingsworth
Mixed-precision numerics in scientific applications: survey and perspectives. arXiv:2412.19322 [cs.CE]https://arxiv.org/abs/2412.19322 Michael O Lam and Jeffrey K Hollingsworth
-
[15]
Fine-grained floating-point precision analysis.Int. J. High Perform. Comput. Appl.32, 2 (2018), 231–245. doi:10.1177/1094342016652462 Michael O. Lam, Tristan Vanderbruggen, Harshitha Menon, and Markus Schordan
-
[16]
Tool Integration for Source-Level Mixed Precision. In2019 IEEE/ACM 3rd International Workshop on Software Correctness for HPC Applications (Correctness). 27–35. doi: 10.1109/Correctness49594. 2019.00009 Harshitha Menon, Michael O. Lam, Daniel Osei-Kuffuor, Markus Schordan, Scott Lloyd, Kathryn Mohror, and Jeffrey Hittinger
-
[17]
ADAPT: Algorithmic Differentiation Applied to Floating-Point Precision Tuning. InProceedings of the International Conference for High Performance Computing, Networking, Storage, and Analysis (SC). 48:1–48:13. doi:10.1109/SC.2018.00051 Konstantinos Parasyris, Ignacio Laguna, Harshitha Menon, Markus Schordan, Daniel Osei-Kuffuor, Giorgis Georgakoudis, Micha...
-
[18]
InIEEE International Symposium on Workload Characterization
HPC-MixPBench: An HPC Benchmark Suite for Mixed-Precision Analysis. InIEEE International Symposium on Workload Characterization. 25–36. doi:10.1109/IISWC50251.2020.00012 Cindy Rubio-González, Cuong Nguyen, Hong Diep Nguyen, James Demmel, William Kahan, Koushik Sen, David H. Bailey, Costin Iancu, and David Hough
-
[19]
Precimonious: tuning assistant for floating- point precision. InProceedings of the International Conference on High Performance Computing, Net- working, Storage and Analysis (SC ’13). ACM, USA, 12 pages. doi:10.1145/2503210.2503296 Cindy Rubio-González, Cuong Nguyen, Benjamin Mehne, Koushik Sen, James Demmel, William Kahan, Costin Iancu, Wim Lavrijsen, Da...
-
[20]
InIEEE/ACM 38th International Conference on Software Engineering
Floating-Point Precision Tuning Using Blame Analysis. InIEEE/ACM 38th International Conference on Software Engineering. 1074–1085. doi:10.1145/2884781.2884850 Garima Singh, Baidyanath Kundu, Harshitha Menon, Alexander Penev, David J. Lange, and Vassil Vassilev
-
[21]
InProceedings of the IEEE International Parallel and Distributed Processing Symposium (IPDPS)
Fast and Automatic Floating-Point Error Analysis with CHEF-FP. InProceedings of the IEEE International Parallel and Distributed Processing Symposium (IPDPS). 1018–1028. doi:10.1109/IPDPS54959.2023.00105 Alexey Solovyev, Marek S. Baranowski, Ian Briggs, Charles Jacobsen, Zvonimir Rakamaric, and Ganesh Gopalakrishnan
-
[22]
doi:10.1145/3230733 Jackson Vanover, Alper Altuntas, and Cindy Rubio-González
Rigorous Estimation of Floating-Point Round-Off Errors with Symbolic Taylor Expansions.ACM Transactions on Programming Languages and Systems41, 1 (2019), 2:1–2:39. doi:10.1145/3230733 Jackson Vanover, Alper Altuntas, and Cindy Rubio-González
-
[23]
1109/SCW63240.2024.00026 Jean Vignes
arXiv 2024
-
[24]
doi:10.1016/0378-4754(93)90003-D Jean Vignes
A stochastic arithmetic for reliable scientific computation.Mathematics and Computers in Simulation35, 3 (1993), 233–261. doi:10.1016/0378-4754(93)90003-D Jean Vignes
-
[25]
doi:10.1023/B:NUMA.0000049483.75679.ce 17 Yutong Wang and Cindy Rubio-González
Discrete Stochastic Arithmetic for Validating Results of Numerical Software.Numer- ical Algorithms37, 1 (2004), 377–390. doi:10.1023/B:NUMA.0000049483.75679.ce 17 Yutong Wang and Cindy Rubio-González
-
[26]
In2024 IEEE/ACM 46th International Conference on Software Engineering (ICSE)
Predicting Performance and Accuracy of Mixed- Precision Programs for Precision Tuning. In2024 IEEE/ACM 46th International Conference on Software Engineering (ICSE). 152–164. doi:10.1145/3597503.3623338 A. Zeller and R. Hildebrandt
-
[27]
Simplifying and isolating failure-inducing input.IEEE Transactions on Software Engineering28, 2 (2002), 183–200. doi:10.1109/32.988498 18
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.