Evaluating Architectural Trade-offs in CGRAs: The Impact of Scratchpad Memory and Heterogeneity on Compute-Intensive Kernels
Pith reviewed 2026-06-26 01:49 UTC · model grok-4.3
The pith
Scratchpad memory in CGRAs reduces memory traffic eightfold, while homogeneous designs cut area by 4.4x-8.2x and reach 5x speedup on matrix computations over heterogeneous ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Our evaluation demonstrates that the SPM significantly optimizes data movement, reducing memory traffic eightfold compared to a memory-less design. While the heterogeneous architecture achieves superior energy efficiency for data-shuffling tasks, the homogeneous design minimizes area overhead by 4.4x to 8.2x relative to state-of-the-art CGRAs. Furthermore, it sustains a 700 MHz operating frequency, enabling up to a 5x execution speedup over the heterogeneous configuration during matrix computations. Ultimately, this work provides an architectural roadmap for selecting CGRA fabrics based on the arithmetic intensity, performance goals, and resource envelopes of edge-scale workloads.
What carries the argument
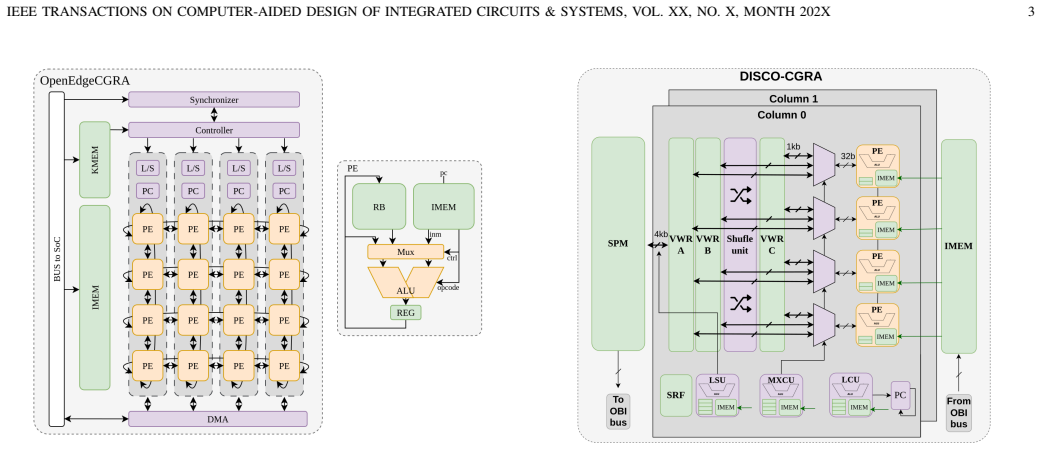
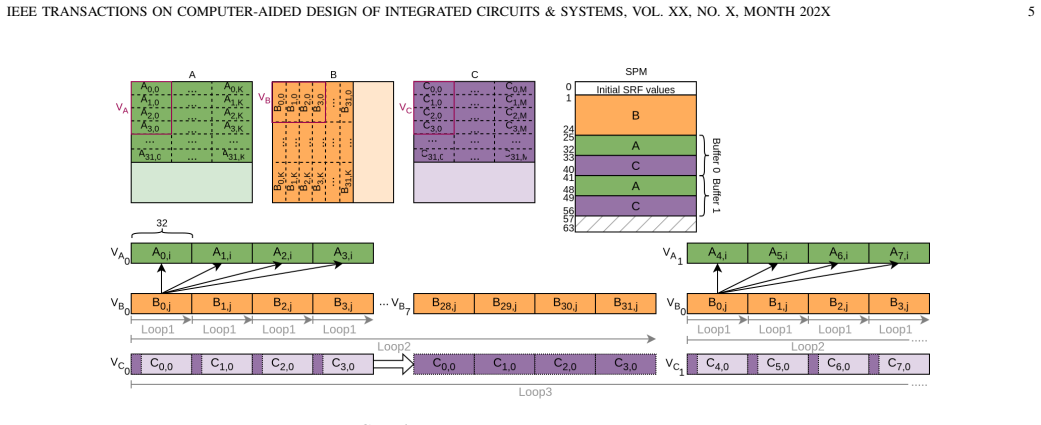
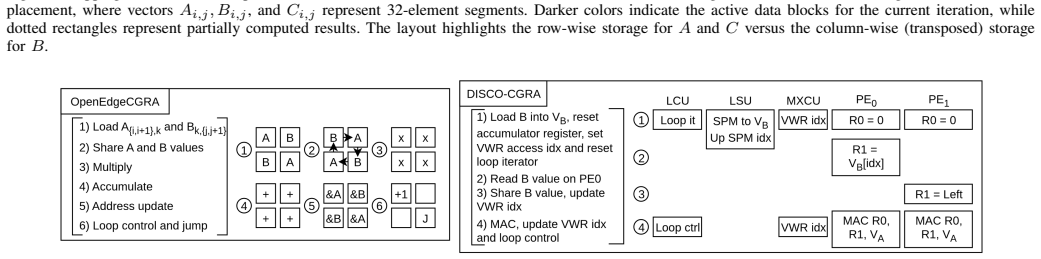
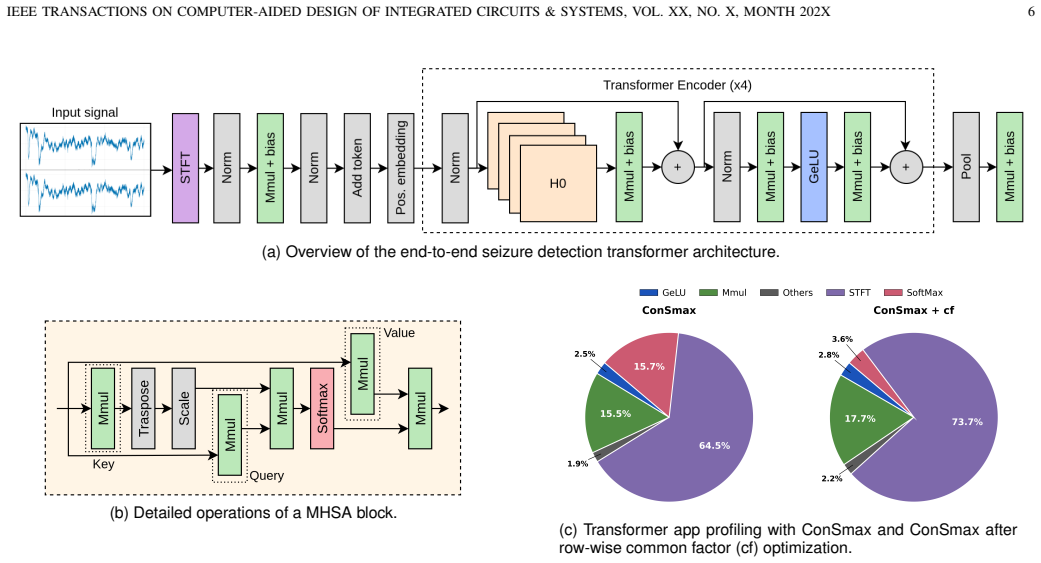
Direct comparison of a homogeneous baseline CGRA against a heterogeneous variant that adds specialized functional units plus Scratchpad Memory (SPM) for local data reuse, applied to FFT, GEMM, and transformer kernels.
Load-bearing premise
The two CGRA configurations were simulated under identical conditions with no unstated differences in routing, clocking, or tool flow that could explain the reported area, frequency, and speedup differences.
What would settle it
Re-simulate both the homogeneous and heterogeneous CGRA configurations using exactly the same synthesis, routing, and clocking parameters to check whether the 4.4x-8.2x area reduction, 700 MHz frequency, and 5x matrix speedup remain.
Figures
read the original abstract
Modern edge computing applications, particularly high-throughput stream processing like Vision Transformers (ViTs), demand massive spatial parallelism and efficient data movement under tight power and area constraints. Coarse-Grained Reconfigurable Architectures (CGRAs) offer a promising paradigm to balance performance, flexibility, and energy efficiency. This paper analyzes the impact of two critical CGRA design choices: processing element heterogeneity and local data reuse support. We evaluate essential computational kernels (Fast Fourier Transform (FFT) and General Matrix Multiply (GEMM)) alongside an end-to-end seizure detection transformer workload across two distinct configurations: a baseline homogeneous architecture and a heterogeneous evolution integrating specialized functional units with an Scratchpad Memory (SPM). Our evaluation demonstrates that the SPM significantly optimizes data movement, reducing memory traffic eightfold compared to a memory-less design. While the heterogeneous architecture achieves superior energy efficiency for data-shuffling tasks, the homogeneous design minimizes area overhead by 4.4x to 8.2x relative to state-of-the-art CGRAs. Furthermore, it sustains a 700 MHz operating frequency, enabling up to a 5x execution speedup over the heterogeneous configuration during matrix computations. Ultimately, this work provides an architectural roadmap for selecting CGRA fabrics based on the arithmetic intensity, performance goals, and resource envelopes of edge-scale workloads.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates architectural trade-offs in CGRAs for edge workloads (FFT, GEMM, seizure-detection ViT) by comparing a homogeneous baseline to a heterogeneous design augmented with specialized functional units and scratchpad memory (SPM). It claims that SPM yields an 8× reduction in memory traffic versus a memory-less design, that the heterogeneous variant offers better energy efficiency on data-shuffling kernels, that the homogeneous variant reduces area by 4.4–8.2× relative to prior CGRAs while sustaining 700 MHz and delivering up to 5× speedup on matrix kernels.
Significance. If the reported deltas can be reproduced under controlled, identical experimental conditions, the work supplies concrete guidance on when homogeneous versus heterogeneous CGRA fabrics are preferable for arithmetic-intensity and area-constrained edge applications. The empirical nature of the comparison is a strength, but the absence of any methodology prevents assessment of whether the headline numbers reflect architectural differences or uncontrolled variables in the tool flow.
major comments (2)
- [Abstract] Abstract: The central numerical claims (8× memory-traffic reduction, 4.4–8.2× area advantage, 700 MHz operation, 5× speedup) are presented with no accompanying experimental methodology, simulation parameters, place-and-route settings, clock-tree synthesis details, or explicit statement that the homogeneous and heterogeneous configurations were evaluated under identical tool-flow and routing-fabric conditions. This omission is load-bearing because any reported delta could arise from unequal experimental conditions rather than the SPM or heterogeneity variables under study.
- [Abstract] Abstract: No baseline CGRA configurations, synthesis tools, or target technology node are named when stating the 4.4–8.2× area comparison to “state-of-the-art CGRAs,” preventing verification that the area advantage is attributable to the homogeneous design choice rather than differences in implementation assumptions.
minor comments (1)
- [Abstract] Abstract: 'an Scratchpad Memory' is grammatically incorrect and should read 'a Scratchpad Memory'.
Simulated Author's Rebuttal
We thank the referee for the feedback on the abstract. The full manuscript contains the experimental details in dedicated sections, but we acknowledge that the abstract would benefit from explicit references to methodology and baselines for improved verifiability. We will revise the abstract accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central numerical claims (8× memory-traffic reduction, 4.4–8.2× area advantage, 700 MHz operation, 5× speedup) are presented with no accompanying experimental methodology, simulation parameters, place-and-route settings, clock-tree synthesis details, or explicit statement that the homogeneous and heterogeneous configurations were evaluated under identical tool-flow and routing-fabric conditions. This omission is load-bearing because any reported delta could arise from unequal experimental conditions rather than the SPM or heterogeneity variables under study.
Authors: The abstract serves as a high-level summary. Complete details on the experimental methodology—including simulation parameters, place-and-route settings, clock-tree synthesis, target technology, and explicit confirmation that homogeneous and heterogeneous configurations were evaluated under identical tool-flow and routing conditions—are provided in Section 4 (Experimental Setup) of the manuscript. We will revise the abstract to add a concise reference to this section. revision: yes
-
Referee: [Abstract] Abstract: No baseline CGRA configurations, synthesis tools, or target technology node are named when stating the 4.4–8.2× area comparison to “state-of-the-art CGRAs,” preventing verification that the area advantage is attributable to the homogeneous design choice rather than differences in implementation assumptions.
Authors: The specific baseline CGRA configurations, synthesis tools, and target technology node are named and compared in Sections 2 (Related Work) and 4 (Experimental Setup). We agree the abstract would be clearer by naming these baselines explicitly instead of the general phrase. We will revise the abstract to do so. revision: yes
Circularity Check
No circularity: pure empirical simulation results with no derivations or fitted predictions
full rationale
The paper is an evaluation study reporting measured outcomes from CGRA simulations (area, frequency, memory traffic, speedup) for homogeneous vs. heterogeneous designs with/without SPM on FFT/GEMM kernels. No equations, ansatzes, fitted parameters, predictions derived from the same data, or load-bearing self-citations appear in the abstract or described methodology. All numerical claims are presented as direct simulation outputs rather than reductions of prior results by construction. This is the expected non-finding for a measurement-focused architecture paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Tsd: Transformers for seizure detection,
Y . Ma, C. Liu, M. S. Ma, Y . Yang, N. D. Truong, K. Kothur, A. Nikpour, and O. Kavehei, “Tsd: Transformers for seizure detection,”bioRxiv, 2023
2023
-
[2]
VersaSens: an extendable multimodal platform for next-generation edge-AI wearables,
T. A. Najafi, J. ´A. Miranda Calero, J. Thevenot, B. Duc, S. Albini, A. Amirshahi, H. Taji, M. J. Belda Beneyto, A. Affanni, and D. Atienza, “VersaSens: an extendable multimodal platform for next-generation edge-AI wearables,”IEEE Transactions on Circuits and Systems for Artificial Intelligence, vol. 1, no. 1, pp. 83–96, 2024
2024
-
[3]
Transformers in vision: A survey,
S. Khan, M. Naseer, M. Hayat, S. W. Zamir, F. S. Khan, and M. Shah, “Transformers in vision: A survey,”ACM computing surveys (CSUR), vol. 54, no. 10s, pp. 1–41, 2022
2022
-
[4]
Plasticine: A reconfigurable architecture for parallel paterns,
R. Prabhakar, Y . Zhang, D. Koeplinger, M. Feldman, T. Zhao, S. Hadjis, A. Pedram, C. Kozyrakis, and K. Olukotun, “Plasticine: A reconfigurable architecture for parallel paterns,” inProceedings of the 44th Annual International Symposium on Computer Architecture, 2017, pp. 389–402
2017
-
[5]
Low-power flexible classifier chip for atrial fibrillation detection,
J. Sanchez, S. P. Bhanushali, S. Sadasivuni, I. Banerjee, and A. Sanyal, “Low-power flexible classifier chip for atrial fibrillation detection,”IEEE transactions on circuits and systems for artificial intelligence, 2025
2025
-
[6]
Flexible circuits and architectures for ultralow power,
B. H. Calhoun, J. F. Ryan, S. Khanna, M. Putic, and J. Lach, “Flexible circuits and architectures for ultralow power,”Proceedings of the IEEE, vol. 98, no. 2, pp. 267–282, 2010
2010
-
[7]
FPGA architecture: Survey and challenges,
I. Kuon, R. Tessier, and J. Rose, “FPGA architecture: Survey and challenges,”Foundations and Trends in Electronic Design Automation, vol. 2, no. 2, pp. 135–253, 2008
2008
-
[8]
A detailed power model for field- programmable gate arrays,
K. K. Poon, S. J. Wilton, and A. Yan, “A detailed power model for field- programmable gate arrays,”ACM Transactions on Design Automation of Electronic Systems (TODAES), vol. 10, no. 2, pp. 279–302, 2005. IEEE TRANSACTIONS ON COMPUTER-AIDED DESIGN OF INTEGRATED CIRCUITS & SYSTEMS, VOL. XX, NO. X, MONTH 202X 12
2005
-
[9]
A survey of coarse-grained reconfigurable architecture and design: Taxonomy, challenges, and applications,
L. Liu, J. Zhu, Z. Li, Y . Lu, Y . Deng, J. Han, S. Yin, and S. Wei, “A survey of coarse-grained reconfigurable architecture and design: Taxonomy, challenges, and applications,”ACM Computing Surveys (CSUR), vol. 52, no. 6, pp. 1–39, 2019
2019
-
[10]
A survey on coarse-grained reconfigurable architectures from a performance perspective,
A. Podobas, K. Sano, and S. Matsuoka, “A survey on coarse-grained reconfigurable architectures from a performance perspective,”IEEE Access, vol. 8, pp. 146 719–146 743, 2020
2020
-
[11]
Revamp: A sys- tematic framework for heterogeneous CGRA realization,
T. K. Bandara, D. Wijerathne, T. Mitra, and L.-S. Peh, “Revamp: A sys- tematic framework for heterogeneous CGRA realization,” inProceedings of the 27th ACM international conference on architectural support for programming languages and operating systems, 2022, pp. 918–932
2022
-
[12]
Coarse-grained recon- figurable array architectures,
B. D. Sutter, P. Raghavan, and A. Lambrechts, “Coarse-grained recon- figurable array architectures,” inHandbook of signal processing systems. Springer, 2018, pp. 427–472
2018
-
[13]
Energy efficient design of coarse-grained reconfigurable architectures: Insights, trends and challenges,
E. Aliagha and D. G ¨ohringer, “Energy efficient design of coarse-grained reconfigurable architectures: Insights, trends and challenges,” in2022 International Conference on Field-Programmable Technology (ICFPT). IEEE, 2022, pp. 1–11
2022
-
[14]
Hastily: Hardware-software co- design for accelerating transformer inference leveraging compute-in- memory,
D. E. Kim, T. Sharma, and K. Roy, “Hastily: Hardware-software co- design for accelerating transformer inference leveraging compute-in- memory,”IEEE Transactions on Circuits and Systems for Artificial Intelligence, 2025
2025
-
[15]
Taem 2.0: A faster transfer- aware effective loop mapping for heterogeneous resources on CGRA,
M. Kou, J. Gu, H. Yao, S. Wei, and S. Yin, “Taem 2.0: A faster transfer- aware effective loop mapping for heterogeneous resources on CGRA,” IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 42, no. 8, pp. 2552–2565, 2023
2023
-
[16]
Dependency- aware data parallelism on spatial CGRA via constraint satisfaction and graph coloring,
Y . Dai, X. Gao, H. Lin, W. Yin, W.-S. Luk, and L. Wang, “Dependency- aware data parallelism on spatial CGRA via constraint satisfaction and graph coloring,”IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2025
2025
-
[17]
Multisky: Dy- namic resource allocation framework for high-throughput cgra multitask execution,
Y . Yang, C. Xie, R. Wang, L. Liu, X. Peng, and Y . Peng, “Multisky: Dy- namic resource allocation framework for high-throughput cgra multitask execution,”IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 45, no. 3, pp. 1339–1351, 2026
2026
-
[18]
Transmap: Transformer-enhanced divide- and-conquer reinforcement learning framework for efficient CGRA com- pilation,
J. Li, W. Yin, and L. Wang, “Transmap: Transformer-enhanced divide- and-conquer reinforcement learning framework for efficient CGRA com- pilation,”IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2026
2026
-
[19]
Data transfer optimization for loop mapping on cgras via polyhedral transformation,
Z. Chen, L. Huang, X. Xiong, and D. Liu, “Data transfer optimization for loop mapping on cgras via polyhedral transformation,”IEEE Trans- actions on Computer-Aided Design of Integrated Circuits and Systems, vol. 45, no. 7, pp. 3291–3304, 2026
2026
-
[20]
An open-hardware coarse-grained reconfigurable array for edge computing,
R. Rodr ´ıguez ´Alvarez, B. Denkinger, J. Sapriza, J. Miranda Calero, G. Ansaloni, and D. Atienza Alonso, “An open-hardware coarse-grained reconfigurable array for edge computing,” inProceedings of the 20th ACM International Conference on Computing Frontiers, 2023, pp. 391– 392
2023
-
[21]
Morphosys: an integrated reconfigurable system for data-parallel and computation-intensive applications,
H. Singh, M.-H. Lee, G. Lu, F. Kurdahi, N. Bagherzadeh, and E. Chaves Filho, “Morphosys: an integrated reconfigurable system for data-parallel and computation-intensive applications,”IEEE Transac- tions on Computers, vol. 49, no. 5, pp. 465–481, 2000
2000
-
[22]
RipTide: A Programmable, Energy-Minimal Dataflow Compiler and Architecture,
G. Gobieski, S. Ghosh, M. Heule, T. Mowry, T. Nowatzki, N. Beckmann, and B. Lucia, “RipTide: A Programmable, Energy-Minimal Dataflow Compiler and Architecture,” in2022 55th IEEE/ACM International Symposium on Microarchitecture (MICRO), Oct. 2022, pp. 546–564. [Online]. Available: https://ieeexplore.ieee.org/document/9923793
arXiv 2022
-
[23]
Snafu: An Ultra-Low-Power, Energy-Minimal CGRA-Generation Framework and Architecture,
G. Gobieski, A. O. Atli, K. Mai, B. Lucia, and N. Beckmann, “Snafu: An Ultra-Low-Power, Energy-Minimal CGRA-Generation Framework and Architecture,” in2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA), Jun. 2021, pp. 1027–1040, iSSN: 2575-713X. [Online]. Available: https: //ieeexplore.ieee.org/document/9499726/
arXiv 2021
-
[24]
VWR2A: a very-wide-register reconfigurable-array architecture for low-power embedded devices,
B. W. Denkinger, M. Pe ´on-Quir´os, M. Konijnenburg, D. Atienza, and F. Catthoor, “VWR2A: a very-wide-register reconfigurable-array architecture for low-power embedded devices,” inACM/IEEE Design Automation Conference, Jul. 2022, pp. 895–900. [Online]. Available: https://dl.acm.org/doi/10.1145/3489517.3530980
-
[25]
Ulp- srp: Ultra low-power samsung reconfigurable processor for biomedical applications,
C. Kim, M. Chung, Y . Cho, M. Konijnenburg, S. Ryu, and J. Kim, “Ulp- srp: Ultra low-power samsung reconfigurable processor for biomedical applications,”ACM Trans. Reconfigurable Technol. Syst., vol. 7, no. 3, Sep. 2014. [Online]. Available: https://doi.org/10.1145/2629610
-
[26]
R-Blocks: an Energy-Efficient, Flexible, and Programmable CGRA,
B. De Bruin, K. Vadivel, M. Wijtvliet, P. J ¨a¨askel¨ainen, and H. Corporaal, “R-Blocks: an Energy-Efficient, Flexible, and Programmable CGRA,” ACM Transactions on Reconfigurable Technology and Systems, vol. 17, no. 2, pp. 1–34, Jun. 2024. [Online]. Available: https: //dl.acm.org/doi/10.1145/3656642
-
[27]
ADRES: an architecture with tightly coupled VLIW processor and coarse-grained reconfigurable matrix,
B. Mei, S. Vernalde, D. Verkest, H. De Man, and R. Lauwereins, “ADRES: an architecture with tightly coupled VLIW processor and coarse-grained reconfigurable matrix,” inInternational conference on field programmable logic and applications. Springer, 2003, pp. 61–70
2003
-
[28]
Exploiting pre-optimized kernels with polyhedral transformations for CGRA compilation,
Y . Wang, M. J. Belda, F. Castro, K. Olcoz, D. Atienza, and G. Ansaloni, “Exploiting pre-optimized kernels with polyhedral transformations for CGRA compilation,” 2026. [Online]. Available: https://arxiv.org/abs/2604.22297
Pith/arXiv arXiv 2026
-
[29]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gellyet al., “An image is worth 16x16 words: Transformers for image recognition at scale,”arXiv preprint arXiv:2010.11929, 2020
Pith/arXiv arXiv 2010
-
[30]
Fetch: A fast and efficient technique for channel selection in EEG wearable systems,
A. Amirshahi, J. Dan, J. A. Miranda Calero, A. Aminifar, and D. Atienza Alonso, “Fetch: A fast and efficient technique for channel selection in EEG wearable systems,” inConference on Health, Inference, and Learning, 2024
2024
-
[31]
Consmax: Hardware-friendly alterna- tive softmax with learnable parameters,
S. Liu, G. Tao, Y . Zou, D. Chow, Z. Fan, K. Lei, B. Pan, D. Sylvester, G. Kielian, and M. Saligane, “Consmax: Hardware-friendly alterna- tive softmax with learnable parameters,” inProceedings of the 43rd IEEE/ACM International Conference on Computer-Aided Design, 2024, pp. 1–9
2024
-
[32]
H. Taji, J. Miranda, M. Pe ´on-Quir´os, and D. Atienza, “Medea: A design-time multi-objective manager for energy-efficient dnn inference on heterogeneous ultra-low power platforms,” 2025. [Online]. Available: https://arxiv.org/abs/2506.19067
arXiv 2025
-
[33]
Genus Synthesis Solution
“Genus Synthesis Solution.” [Online]. Available: https://www.cadence.com/en US/home/tools/digital-design-and-signoff/ synthesis/genus-synthesis-solution.html
-
[34]
PrimePower: RTL to Signoff Power Analysis| Synopsys
“PrimePower: RTL to Signoff Power Analysis| Synopsys.” [Online]. Available: https://www.synopsys.com/ implementation-and-signoff/signoff/primepower.html
-
[35]
Polybench: The polyhedral benchmark suite,
L.-N. Pouchetet al., “Polybench: The polyhedral benchmark suite,” URL: http://www. cs. ucla. edu/pouchet/software/polybench, vol. 437, pp. 1–1, 2012
2012
-
[36]
Exploring brain-inspired multi-core heterogeneous hardware templates for low-power biomedical embedded systems,
B. W. Denkinger, “Exploring brain-inspired multi-core heterogeneous hardware templates for low-power biomedical embedded systems,” PhD Thesis, EPFL, 2023
2023
-
[37]
An Algorithm for the Machine Calculation of Complex Fourier Series,
J. W. Cooley and J. W. Tukey, “An Algorithm for the Machine Calculation of Complex Fourier Series,”Mathematics of Computation, vol. 19, no. 90, pp. 297–301, 1965, publisher: American Mathematical Society. [Online]. Available: https://www.jstor.org/stable/2003354
arXiv 1965
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.