BBC: Improving Large-k Approximate Nearest Neighbor Search with a Bucket-based Result Collector
Pith reviewed 2026-05-13 20:43 UTC · model grok-4.3
The pith
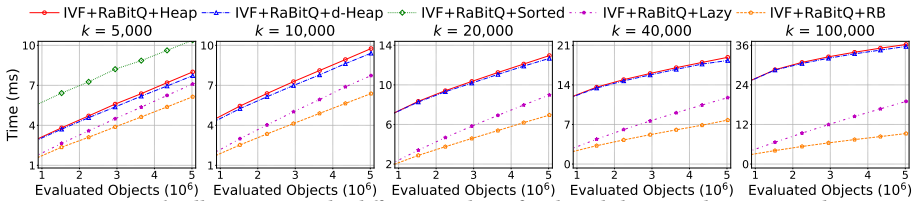
A bucket-based collector organizes ANN candidates by distance to speed up large-k queries in quantization indexes by up to 3.8 times.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
BBC improves quantization-based ANN indexes for large-k queries by replacing conventional top-k collectors with a bucket-based result buffer that organizes candidates into distance buckets, reducing ranking costs and cache misses while enabling lightweight final selection, together with two re-ranking algorithms that cut either candidate volume or cache misses depending on the underlying quantizer.
What carries the argument
Bucket-based result buffer that organizes candidates into buckets by distance to the query for efficient superset maintenance and top-k selection.
If this is right
- Existing quantization-based ANN indexes gain substantial speed for large-k queries without altering their core structure.
- Re-ranking overhead drops by limiting candidates examined or by improving memory access patterns.
- Cache efficiency rises during candidate ranking and selection phases.
- The same collector works across multiple quantization methods while preserving recall.
- Final top-k extraction becomes a lightweight step after bucket organization.
Where Pith is reading between the lines
- The same bucket organization could be tested on non-quantization ANN indexes that also produce large candidate sets.
- Applications that vary k at runtime might benefit from adaptive bucket sizing tuned to expected result cardinality.
- Index designers facing high-k workloads may need to treat result collection as a first-class optimization target rather than an afterthought.
- Direct measurement of cache miss rates before and after BBC on new hardware would confirm the memory-efficiency mechanism.
Load-bearing premise
Grouping candidates by distance reduces ranking costs and cache misses enough to offset the overhead of maintaining the buckets.
What would settle it
Running BBC-augmented indexes against standard large-k ANN benchmarks and measuring no reduction in query time or cache misses would disprove the acceleration claim.
Figures








read the original abstract
Although Approximate Nearest Neighbor (ANN) search has been extensively studied, large-k ANN queries that aim to retrieve a large number of nearest neighbors remain underexplored, despite their numerous real-world applications. Existing ANN methods face significant performance degradation for such queries. In this work, we first investigate the reasons for the performance degradation of quantization-based ANN indexes: (1) the inefficiency of existing top-k collectors, which incurs significant overhead in candidate maintenance, and (2) the reduced pruning effectiveness of quantization methods, which leads to a costly re-ranking process. To address this, we propose a novel bucket-based result collector (BBC) to enhance the efficiency of existing quantization-based ANN indexes for large-k ANN queries. BBC introduces two key components: (1) a bucket-based result buffer that organizes candidates into buckets by their distances to the query. This design reduces ranking costs and improves cache efficiency, enabling high performance maintenance of a candidate superset and a lightweight final selection of top-k results. (2) two re-ranking algorithms tailored for different types of quantization methods, which accelerate their re-ranking process by reducing either the number of candidate objects to be re-ranked or cache misses. Extensive experiments on real-world datasets demonstrate that BBC accelerates existing quantization-based ANN methods by up to 3.8x at recall@k = 0.95 for large-k ANN queries.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes BBC, a bucket-based result collector, to address performance degradation in quantization-based ANN indexes for large-k queries. It identifies two issues—inefficient top-k candidate maintenance and reduced pruning effectiveness leading to costly re-ranking—and introduces a distance-bucketed buffer for candidate organization plus two tailored re-ranking algorithms. Experiments on real-world datasets are reported to yield speedups of up to 3.8× at recall@k = 0.95.
Significance. If the claimed speedups are robustly verified with full experimental controls, the work would offer a practical, low-overhead enhancement to existing quantization indexes without altering their core structure. This could benefit database applications involving large-k retrieval (e.g., recommendation or analytics workloads) by improving cache behavior and reducing ranking costs in the high-candidate regime.
major comments (2)
- [Abstract] Abstract: the central performance claim of up to 3.8× speedup at recall@k=0.95 is presented without any description of datasets, quantization methods, baselines, number of trials, or variance; this leaves the offset between bucket-maintenance overhead and saved ranking/cache work unverifiable, especially for the large-superset regime the method targets.
- [Abstract] The design rationale (bucket insertion and re-ranking) assumes that organizing candidates by distance reduces ranking costs enough to offset linear bucket-maintenance overhead; no analytic bound or worst-case analysis is supplied for the case when quantization pruning returns a very large candidate superset, which is precisely the operating point emphasized in the paper.
minor comments (1)
- [Abstract] The abstract would benefit from a brief statement of the range of k values tested and the specific recall@k target used for the 3.8× figure.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and the request for stronger analytical support. We address each major comment below and will revise the manuscript to improve clarity and verifiability of the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claim of up to 3.8× speedup at recall@k=0.95 is presented without any description of datasets, quantization methods, baselines, number of trials, or variance; this leaves the offset between bucket-maintenance overhead and saved ranking/cache work unverifiable, especially for the large-superset regime the method targets.
Authors: We agree that the abstract would benefit from additional context to make the speedup claim more self-contained. In the revision we will expand the abstract with a brief clause noting that the results are obtained on standard real-world datasets using common quantization-based indexes (with full details on baselines, number of trials, and variance reported in the experimental section). Due to strict length limits we cannot embed every experimental parameter in the abstract itself, but the added sentence will allow readers to immediately locate the supporting evidence and verify the net benefit of bucket maintenance versus ranking savings. revision: partial
-
Referee: [Abstract] The design rationale (bucket insertion and re-ranking) assumes that organizing candidates by distance reduces ranking costs enough to offset linear bucket-maintenance overhead; no analytic bound or worst-case analysis is supplied for the case when quantization pruning returns a very large candidate superset, which is precisely the operating point emphasized in the paper.
Authors: We acknowledge that a formal analytic bound would strengthen the design rationale. The current manuscript supplies extensive empirical measurements (Section 5) across increasing candidate-superset sizes that demonstrate the bucket-maintenance cost is more than offset by reduced ranking and cache-miss overhead. In the revision we will add a short cost-model paragraph in the design section that contrasts the amortized O(1) bucket insertion with the O(n log n) cost of full sorting or the full re-ranking scan, and we will explicitly discuss the regime where the superset size greatly exceeds k. While a complete worst-case proof is not provided, the added model together with the existing empirical data will address the concern for the targeted operating point. revision: yes
Circularity Check
No circularity: structural proposal with empirical validation
full rationale
The paper identifies performance bottlenecks in quantization-based ANN for large-k queries via investigation, then introduces BBC as a bucket-organized buffer plus two re-ranking algorithms. No equations, parameter fits, or derivations are present that reduce to inputs by construction. No self-citations serve as load-bearing uniqueness theorems or ansatzes. The speedup claims rest on experimental measurements rather than self-referential logic, satisfying the self-contained criterion.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
BBC introduces a bucket-based result buffer that organizes candidates into buckets by their distances to the query... reduces ranking costs and improves cache efficiency
-
IndisputableMonolith/Foundation/DimensionForcing.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
two re-ranking algorithms tailored for different types of quantization methods
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Efficient Graph Indexing for Interval-Aware Vector Search
URNG and UG enable a single graph index for diverse interval-aware ANN queries by preserving monotonic searchability and structural heredity.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.