TopoRetarget: Interaction-Preserving Retargeting for Dexterous Manipulation
Pith reviewed 2026-06-27 04:17 UTC · model grok-4.3
The pith
TopoRetarget retargets human hand demonstrations to robot hands while preserving task-relevant contacts via a sparse interaction graph and distance-weighted Laplacian deformation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
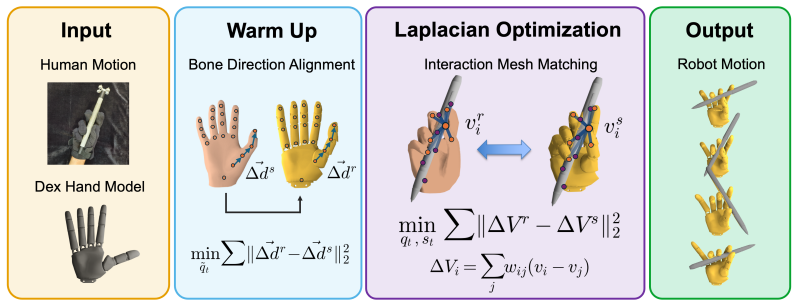
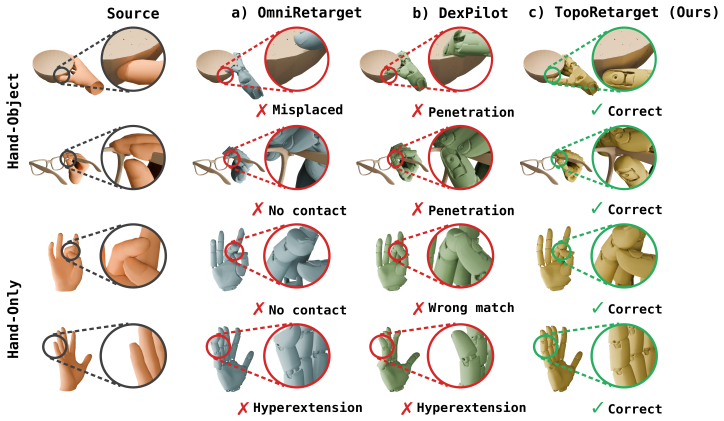
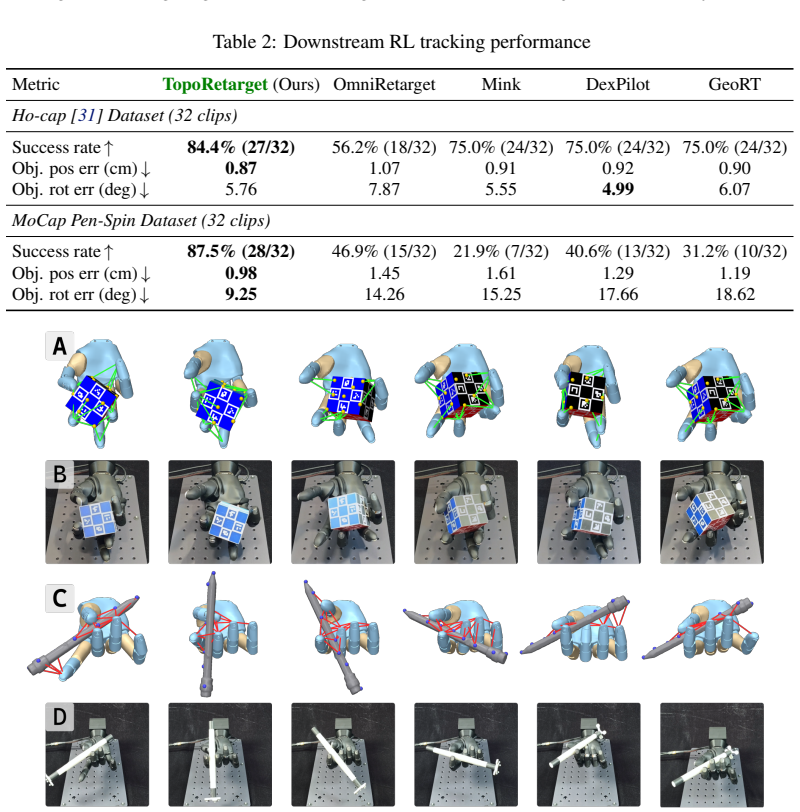
TopoRetarget constructs a sparse interaction graph over hand and object keypoints and optimizes distance-weighted Laplacian deformation with directional consistency, kinematic constraints, and penetration handling. This single-parameter framework adapts human demonstrations to dexterous robot hands while preserving task-relevant hand-object contact structure. On the ContactPose Dataset the generated references achieve the highest contact precision and alignment among compared methods; on pen-spin tasks they raise RL training success by 40.6 percentage points over existing baselines and support zero-shot transfer to Wuji Hand hardware for both cube reorientation and pen spinning.
What carries the argument
Sparse interaction graph over hand and object keypoints, optimized via distance-weighted Laplacian deformation subject to directional consistency, kinematic constraints, and penetration handling.
If this is right
- Produces references with the highest contact precision and alignment on the ContactPose Dataset compared with all tested baselines.
- Raises pen-spin reinforcement learning training success by 40.6 percentage points relative to prior retargeting methods.
- Enables zero-shot transfer of trained policies to physical Wuji Hand hardware on cube reorientation and pen spinning.
- Operates with one fixed parameter set across diverse hand morphologies and demonstration conditions.
Where Pith is reading between the lines
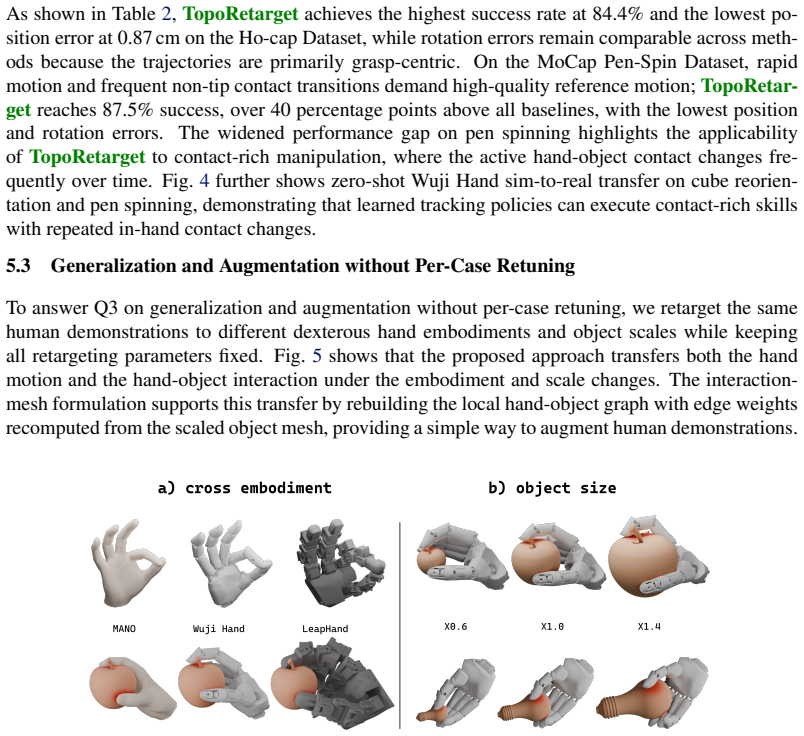
- The same graph construction could be reused to retarget demonstrations between entirely different robot hand designs without per-hand re-tuning.
- Contact-preserving references may reduce the amount of reward shaping needed when training manipulation policies from human data.
- The deformation approach might extend to retargeting full-body motions or scenes with multiple interacting objects.
Load-bearing premise
Optimizing the deformation on the sparse keypoint graph will keep exactly the contacts required for task success without creating new artifacts that reduce reinforcement learning performance.
What would settle it
Apply TopoRetarget and a baseline retargeting method to a new hand-object task, train identical RL policies on each set of references, and observe that the TopoRetarget version yields equal or lower success rate.
Figures

read the original abstract
Human hand-object demonstrations provide dense reference motions for training dexterous manipulation reinforcement learning (RL) policies through reference tracking. However, to use such demonstrations for RL policy learning, retargeting must preserve hand pose and task-relevant hand-object contact structure. Otherwise, contact and feasibility artifacts can degrade downstream RL policy performance. We introduce TopoRetarget, an interaction-preserving retargeting framework that uses a single set of parameters across diverse retargeting conditions while maintaining task-relevant hand-object interaction and adapting human demonstrations to dexterous robot hands. The method constructs a sparse interaction graph over hand and object keypoints and optimizes distance-weighted Laplacian deformation with directional consistency, kinematic constraints, and penetration handling. Evaluations show that the generated references improve both interaction fidelity and policy learning: TopoRetarget achieves the best contact precision and alignment over all baselines on the ContactPose Dataset, improves Pen-Spin training success by 40.6 percentage points over the existing baseline methods, and enables zero-shot transfer to Wuji Hand hardware on cube reorientation and pen spinning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TopoRetarget, a retargeting framework that constructs a sparse interaction graph over hand and object keypoints and optimizes distance-weighted Laplacian deformation subject to directional consistency, kinematic constraints, and penetration handling. The central claim is that this procedure preserves task-relevant hand-object contacts across retargeting conditions using a single parameter set, yielding improved contact fidelity on ContactPose and better downstream RL performance (including a 40.6 pp gain on Pen-Spin and zero-shot hardware transfer).
Significance. If the empirical results and optimization details hold, the work provides a practical tool for generating reference motions that improve both interaction fidelity and policy learning in dexterous manipulation. The reported gains on ContactPose contact metrics and the Pen-Spin RL task, together with hardware transfer, indicate utility for sim-to-real pipelines; the graph-based formulation with explicit penetration handling is a clear strength relative to purely kinematic baselines.
major comments (2)
- [§4.2, Eq. (7)] §4.2, Eq. (7): the directional consistency term is added to the Laplacian objective, but the manuscript does not derive or bound how this term interacts with the distance-weighting to guarantee preservation of contact normals rather than merely penalizing deviation; without this analysis the claim that the method is interaction-preserving rests on empirical outcomes alone.
- [Table 3] Table 3, Pen-Spin row: the 40.6 pp success-rate improvement is reported relative to an existing baseline, yet the table does not include an ablation that disables the penetration-handling constraint; this term is load-bearing for the claim that the full method avoids RL-degrading artifacts.
minor comments (2)
- [§4.3] The abstract states that the method uses 'a single set of parameters across diverse retargeting conditions,' but §4.3 does not tabulate the exact fixed values or demonstrate invariance under small perturbations of those values.
- [Figure 4] Figure 4 caption refers to 'qualitative results' but does not indicate whether the visualized contacts are ground-truth or predicted; adding this distinction would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the positive assessment, the recommendation of minor revision, and the constructive comments on the optimization details and experimental validation. We address each major comment below.
read point-by-point responses
-
Referee: [§4.2, Eq. (7)] §4.2, Eq. (7): the directional consistency term is added to the Laplacian objective, but the manuscript does not derive or bound how this term interacts with the distance-weighting to guarantee preservation of contact normals rather than merely penalizing deviation; without this analysis the claim that the method is interaction-preserving rests on empirical outcomes alone.
Authors: We acknowledge that the manuscript does not include a formal derivation or bound on the interaction between the directional consistency term and the distance-weighted Laplacian. The directional consistency term is motivated to preserve contact normals by penalizing angular deviations between the deformed and original vectors, with the distance-weighting ensuring that nearby contacts exert stronger influence on the optimization. The overall claim of interaction preservation is supported by the empirical results on ContactPose contact precision/alignment and the downstream RL gains. In revision we will add a short paragraph in §4.2 elaborating on this design rationale and its empirical grounding. revision: partial
-
Referee: Table 3, Pen-Spin row: the 40.6 pp success-rate improvement is reported relative to an existing baseline, yet the table does not include an ablation that disables the penetration-handling constraint; this term is load-bearing for the claim that the full method avoids RL-degrading artifacts.
Authors: We agree that an ablation disabling the penetration-handling constraint would strengthen the evidence that this component is responsible for avoiding artifacts that degrade RL performance. We will add this ablation (reporting success rate on Pen-Spin with the constraint removed) to Table 3 or a supplementary table in the revised manuscript. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes TopoRetarget as a procedural optimization framework that constructs a sparse interaction graph over keypoints and solves a distance-weighted Laplacian deformation subject to directional consistency, kinematic, and penetration constraints. No equations, fitted parameters, or predictions are presented that reduce by construction to the inputs (no self-definitional mappings, no fitted-input-called-prediction, and no load-bearing self-citations or uniqueness theorems). The central claims rest on empirical metrics from ContactPose, Pen-Spin RL training, and hardware transfer, which constitute independent external validation rather than internal re-derivation. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
O. M. Andrychowicz, B. Baker, M. Chociej, R. Jozefowicz, B. McGrew, J. Pachocki, A. Petron, M. Plappert, G. Powell, A. Ray, et al. Learning dexterous in-hand manipulation. The International Journal of Robotics Research, 39(1):3–20, 2020
2020
-
[2]
Handa, A
A. Handa, A. Allshire, V . Makoviychuk, A. Petrenko, R. Singh, J. Liu, D. Makoviichuk, K. Van Wyk, A. Zhurkevich, B. Sundaralingam, et al. Dextreme: Transfer of agile in-hand manipulation from simulation to reality. In2023 IEEE International Conference on Robotics and Automation (ICRA), pages 5977–5984. IEEE, 2023
2023
-
[3]
J. Wang, Y . Yuan, H. Che, H. Qi, Y . Ma, J. Malik, and X. Wang. Lessons from learning to spin” pens”.arXiv preprint arXiv:2407.18902, 2024
arXiv 2024
-
[4]
X. Liu, J. Adalibieke, Q. Han, Y . Qin, and L. Yi. Dextrack: Towards generalizable neu- ral tracking control for dexterous manipulation from human references.arXiv preprint arXiv:2502.09614, 2025
arXiv 2025
-
[5]
Xu, Y .-W
S. Xu, Y .-W. Chao, L. Bian, A. Mousavian, Y .-X. Wang, L. Gui, and W. Yang. Dexplore: Scalable neural control for dexterous manipulation from reference scoped exploration. InCon- ference on Robot Learning, pages 2184–2199. PMLR, 2025
2025
- [6]
-
[7]
K. Li, P. Li, T. Liu, Y . Li, and S. Huang. Maniptrans: Efficient dexterous bimanual manipula- tion transfer via residual learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6991–7003, 2025
2025
-
[8]
Handa, K
A. Handa, K. Van Wyk, W. Yang, J. Liang, Y .-W. Chao, Q. Wan, S. Birchfield, N. Ratliff, and D. Fox. Dexpilot: Vision-based teleoperation of dexterous robotic hand-arm system. In2020 IEEE International Conference on Robotics and Automation (ICRA), pages 9164–9170. IEEE, 2020
2020
-
[9]
Y . Qin, W. Yang, B. Huang, K. Van Wyk, H. Su, X. Wang, Y .-W. Chao, and D. Fox. Anyteleop: A general vision-based dexterous robot arm-hand teleoperation system.arXiv preprint arXiv:2307.04577, 2023
arXiv 2023
-
[10]
A. Sivakumar, K. Shaw, and D. Pathak. Robotic telekinesis: Learning a robotic hand imitator by watching humans on youtube.arXiv preprint arXiv:2202.10448, 2022
arXiv 2022
-
[11]
Y . Qin, H. Su, and X. Wang. From one hand to multiple hands: Imitation learning for dexterous manipulation from single-camera teleoperation.IEEE Robotics and Automation Letters, 7(4): 10873–10881, 2022
2022
-
[12]
C. Xin, M. Yu, Y . Jiang, Z. Zhang, and X. Li. Analyzing key objectives in human-to-robot retargeting for dexterous manipulation.IEEE Robotics and Automation Practice, 2026
2026
-
[13]
Z.-H. Yin, C. Wang, L. Pineda, K. Bodduluri, T. Wu, P. Abbeel, and M. Mukadam. Geometric retargeting: A principled, ultrafast neural hand retargeting algorithm. In2025 IEEE/RSJ In- ternational Conference on Intelligent Robots and Systems (IROS), pages 17376–17382. IEEE, 2025
2025
-
[14]
Y . Chen, C. Wang, Y . Yang, and C. K. Liu. Object-centric dexterous manipulation from human motion data.arXiv preprint arXiv:2411.04005, 2024
arXiv 2024
-
[15]
X. Lin, K. Yao, L. Xu, X. Wang, X. Li, Y . Wang, and M. Li. Dexflow: A unified approach for dexterous hand pose retargeting and interaction.arXiv preprint arXiv:2505.01083, 2025. 10
arXiv 2025
-
[16]
Huang, H
L. Huang, H. Zhang, Z. Wu, S. Christen, and J. Song. Fungrasp: Functional grasping for diverse dexterous hands.IEEE Robotics and Automation Letters, 2025
2025
-
[17]
C. Pan, C. Wang, H. Qi, Z. Liu, H. Bharadhwaj, A. Sharma, T. Wu, G. Shi, J. Malik, and F. Hogan. Spider: Scalable physics-informed dexterous retargeting.arXiv preprint arXiv:2511.09484, 2025
arXiv 2025
-
[18]
L. Qi, O. Popoola, M. A. Imran, and W. Ahmad. Genhand: generalised human grasp kinematic retargeting.npj Robotics, 4(1):19, 2026
2026
-
[19]
H. Qi, A. Kumar, R. Calandra, Y . Ma, and J. Malik. In-hand object rotation via rapid motor adaptation. InConference on Robot Learning, pages 1722–1732. PMLR, 2023
2023
-
[20]
Y . Yao, U. Yoo, J. Oh, C. G. Atkeson, and J. Ichnowski. Soft robotic dynamic in-hand pen spinning. In2025 IEEE International Conference on Robotics and Automation (ICRA), 2025
2025
-
[21]
X. B. Peng, P. Abbeel, S. Levine, and M. Van de Panne. Deepmimic: Example-guided deep re- inforcement learning of physics-based character skills.ACM Transactions On Graphics (TOG), 37(4):1–14, 2018
2018
-
[22]
T. He, Z. Luo, X. He, W. Xiao, C. Zhang, W. Zhang, K. Kitani, C. Liu, and G. Shi. Omnih2o: Universal and dexterous human-to-humanoid whole-body teleoperation and learning.arXiv preprint arXiv:2406.08858, 2024
arXiv 2024
-
[23]
Qin, Y .-H
Y . Qin, Y .-H. Wu, S. Liu, H. Jiang, R. Yang, Y . Fu, and X. Wang. Dexmv: Imitation learning for dexterous manipulation from human videos. InEuropean Conference on Computer Vision, pages 570–587. Springer, 2022
2022
-
[24]
C. Wang, H. Shi, W. Wang, R. Zhang, L. Fei-Fei, and C. K. Liu. Dexcap: Scalable and portable mocap data collection system for dexterous manipulation.arXiv preprint arXiv:2403.07788, 2024
arXiv 2024
-
[25]
Jiang, Y
Z. Jiang, Y . Xie, K. Lin, Z. Xu, W. Wan, A. Mandlekar, L. Fan, and Y . Zhu. Dexmimicgen: Automated data generation for bimanual dexterous manipulation via imitation learning. In 2025 IEEE International Conference on Robotics and Automation (ICRA), 2025
2025
-
[26]
Brahmbhatt, C
S. Brahmbhatt, C. Tang, C. D. Twigg, C. C. Kemp, and J. Hays. Contactpose: A dataset of grasps with object contact and hand pose. InEuropean Conference on Computer Vision, pages 361–378. Springer, 2020
2020
-
[27]
L. Yang, X. Huang, Z. Wu, A. Kanazawa, P. Abbeel, C. Sferrazza, C. K. Liu, R. Duan, and G. Shi. Omniretarget: Interaction-preserving data generation for humanoid whole-body loco- manipulation and scene interaction.arXiv preprint arXiv:2509.26633, 2025
Pith/arXiv arXiv 2025
-
[28]
C. Lugaresi, J. Tang, H. Nash, C. McClanahan, E. Uboweja, M. Hays, F. Zhang, C.-L. Chang, M. G. Yong, J. Lee, et al. Mediapipe: A framework for building perception pipelines.arXiv preprint arXiv:1906.08172, 2019
Pith/arXiv arXiv 1906
-
[29]
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
Pith/arXiv arXiv 2017
-
[30]
K. Zakka. Mink: Python inverse kinematics based on MuJoCo, Feb. 2026. URLhttps: //github.com/kevinzakka/mink
2026
-
[31]
J. Wang, Q. Zhang, Y .-W. Chao, B. Wen, X. Guo, and Y . Xiang. Ho-cap: A capture system and dataset for 3d reconstruction and pose tracking of hand-object interaction.Advances in Neural Information Processing Systems, 38, 2026. 11 A Appendix A.1 Retargeting Details Implementation detail forE reg. In the implementation, the regularization term in the final...
2026
-
[32]
The reward weights and scales, together with the termination conditions, are summarized in Table 4
In practice, the largest weight is assigned to object tracking, followed by link, joint, and smoothness terms. The reward weights and scales, together with the termination conditions, are summarized in Table 4. 14 Table 4: Reference-tracking MDP. We defineψ(e;σ) = exp(−∥e/σ∥ 2). Term Expression / specification Weight Objectψ( 1 6 P6 m=1 ∥um −u ref m ∥2; 0...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.