Elasticity in Parallel Sparse Triangular Solve
Pith reviewed 2026-07-03 05:42 UTC · model grok-4.3
The pith
Stale synchronous parallel execution overlaps synchronization with computation in parallel sparse triangular solves.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
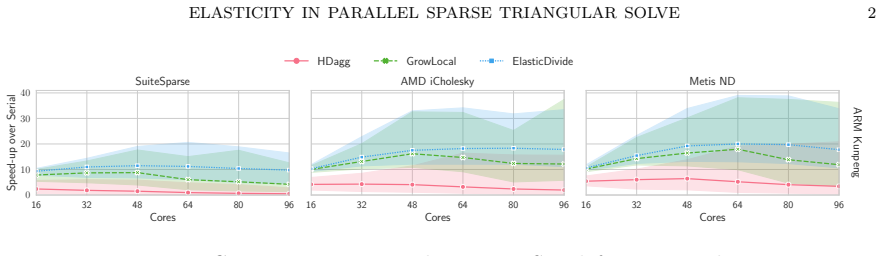
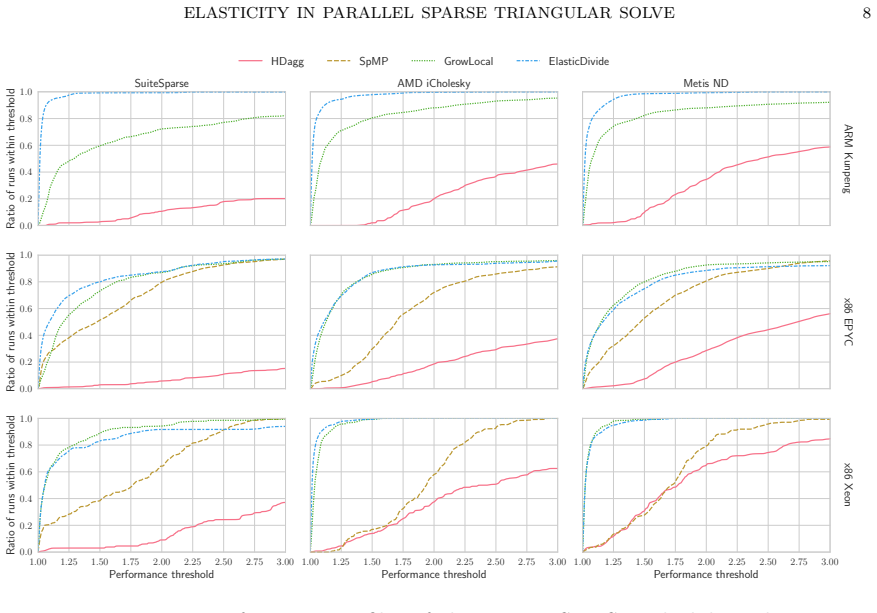
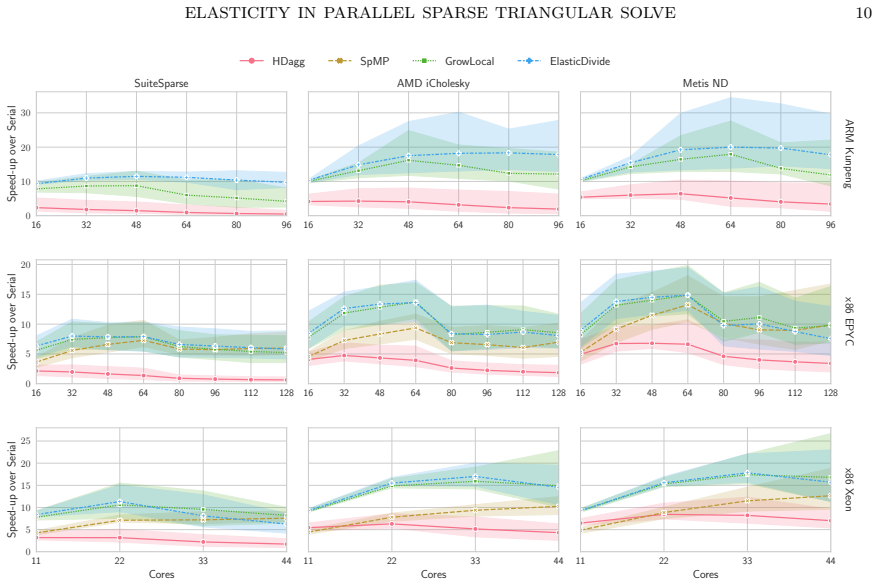
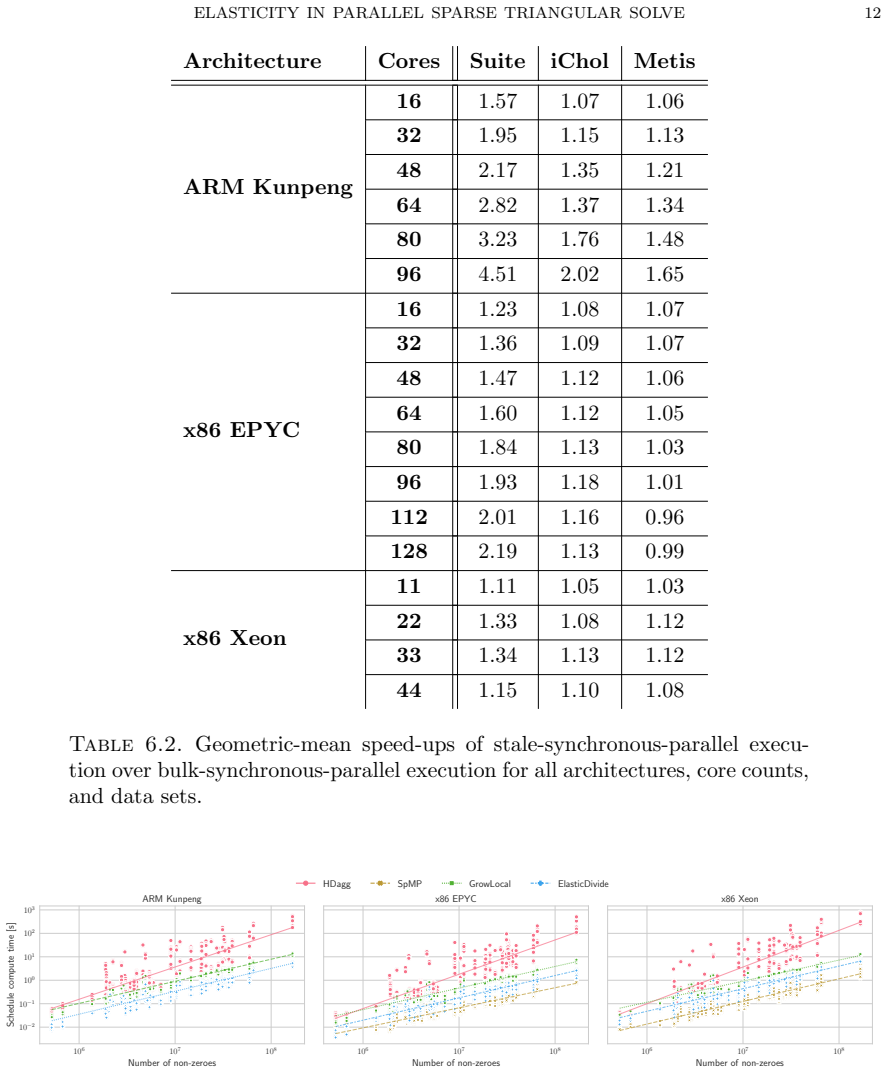
Stale synchronous parallel schedules for parallel sparse triangular solve permit the overlap of synchronization and compute. A general directed-acyclic-graph scheduler can produce such schedules, and the resulting ElasticDivide implementation delivers geometric-mean speed-ups of 7-30 percent versus the synchronous scheduler GrowLocal on an ARM machine with 48 cores and 19-60 percent versus SpMP on an x86 machine with 48 cores.
What carries the argument
Stale synchronous parallel execution mode, which allows tasks to proceed with values computed in earlier iterations rather than waiting for the current synchronization point.
If this is right
- Synchronization barriers in sparse triangular solve can be overlapped with useful computation.
- A single directed-acyclic-graph scheduler can generate both synchronous and stale-synchronous schedules.
- Speed-ups from this overlap appear on both ARM and x86 48-core platforms.
- The approach applies to existing state-of-the-art synchronous schedulers as a drop-in improvement.
Where Pith is reading between the lines
- The same stale-synchronous technique could be tested on other sparse linear-algebra kernels that contain long dependency chains.
- If the scheduler is made parameter-free, it might reduce tuning effort for new matrix structures.
- Numerical stability under stale values could be verified on matrices with varying condition numbers.
Load-bearing premise
Stale synchronous parallel execution preserves the numerical correctness of the triangular solve while the measured speed-ups reflect comparable conditions without hidden overheads.
What would settle it
A run of ElasticDivide on a standard sparse triangular solve benchmark that produces results differing from the sequential solution by more than floating-point tolerance.
Figures
read the original abstract
We introduce stale synchronous parallel as a mode of execution in parallel sparse triangular linear system solve and present a general directed-acyclic-graph scheduler capable of producing such schedules. Stale-synchronous-parallel schedules allow the overlap of synchronisation and compute which results in a geometric-mean speed-up of $7$-$30\%$ of our scheduler, ElasticDivide, over state-of-the-art synchronous scheduler GrowLocal on an ARM machine using 48 cores. On an x86 machine using 48 cores, we report geometric-mean speed-ups of $19$-$60\%$ over SpMP.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces stale-synchronous-parallel (SSP) execution as a mode for parallel sparse triangular solve and presents a general DAG scheduler, ElasticDivide, that produces such schedules. It claims that SSP enables overlap of synchronization and compute, yielding geometric-mean speed-ups of 7-30% for ElasticDivide over the synchronous scheduler GrowLocal on an ARM 48-core machine and 19-60% over SpMP on an x86 48-core machine.
Significance. If numerical equivalence to synchronous execution is established, the work could provide a practical way to reduce synchronization costs in sparse triangular solves on multi-core systems. The general scheduler for SSP schedules is a positive contribution that may apply beyond the reported experiments.
major comments (2)
- [Abstract and §4] Abstract and experimental section: the central speed-up claims are load-bearing only if SSP produces a solution vector identical (to machine precision) to the synchronous case. No description of verification appears, such as residual norm checks against the synchronous result, direct vector comparison, or a proof that all dependency edges are respected before commit. Without this, the reported geometric means cannot be interpreted as performance gains on equivalent outputs.
- [§4] §4 (or equivalent experimental section): the abstract reports geometric-mean speed-ups but the provided text supplies no methodology details on matrix datasets, number of runs, error bars, or confirmation that overheads (e.g., extra communication for stale-value handling) were accounted for identically across schedulers. These omissions prevent assessment of whether the 7-60% figures are robust.
minor comments (2)
- [§3] Clarify the precise definition of 'stale' values and the conditions under which a task may proceed with them; a short example or pseudocode would help readers understand the departure from strict BSP semantics.
- The abstract mentions 'our scheduler, ElasticDivide' but does not state whether the implementation or experimental scripts are available; adding a reproducibility note would strengthen the contribution.
Simulated Author's Rebuttal
We thank the referee for their detailed review and for highlighting the need for explicit verification of numerical equivalence and fuller experimental methodology. We address each major comment below and will revise the manuscript accordingly to strengthen these aspects.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and experimental section: the central speed-up claims are load-bearing only if SSP produces a solution vector identical (to machine precision) to the synchronous case. No description of verification appears, such as residual norm checks against the synchronous result, direct vector comparison, or a proof that all dependency edges are respected before commit. Without this, the reported geometric means cannot be interpreted as performance gains on equivalent outputs.
Authors: We agree that numerical equivalence must be explicitly established for the speed-up claims to be interpretable. The manuscript as submitted does not contain a dedicated description of the verification procedure. We will add a new subsection to the experimental section (§4) that details the verification process, including: (i) computation of residual norms ||Ax - b|| for both SSP and synchronous results, (ii) direct element-wise comparison of solution vectors to machine precision, and (iii) confirmation that all dependency edges are respected prior to any commit of stale values. This revision will make the equivalence argument self-contained. revision: yes
-
Referee: [§4] §4 (or equivalent experimental section): the abstract reports geometric-mean speed-ups but the provided text supplies no methodology details on matrix datasets, number of runs, error bars, or confirmation that overheads (e.g., extra communication for stale-value handling) were accounted for identically across schedulers. These omissions prevent assessment of whether the 7-60% figures are robust.
Authors: We acknowledge that the current experimental section lacks sufficient methodological detail. In the revised manuscript we will expand §4 to report: the complete list of matrices with their sources and structural properties, the number of independent runs performed for each configuration, the use of error bars or standard deviations on the geometric means, and an explicit statement that all overheads (including any additional communication required for stale-value handling) were measured under identical conditions for ElasticDivide, GrowLocal, and SpMP. These additions will allow readers to assess the robustness of the reported speed-ups. revision: yes
Circularity Check
Empirical performance claims contain no derivation chain or self-referential reduction
full rationale
The paper introduces stale-synchronous-parallel execution and the ElasticDivide scheduler for sparse triangular solve, then reports measured geometric-mean speed-ups on specific hardware. No equations, fitted parameters, predictions, uniqueness theorems, or ansatzes appear in the provided text. The speed-up numbers are presented as direct experimental outcomes rather than derived quantities that reduce to the scheduler definition or prior self-citations by construction. The central claims therefore remain externally falsifiable via independent timing runs and do not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Thomas L. Adam, K. Mani Chandy, and J. R. Dickson. A comparison of list schedules for parallel processing systems. Communications of the ACM , 17(12):685--690, 1974
1974
-
[2]
Amestoy, Timothy A
Patrick R. Amestoy, Timothy A. Davis, and Iain S. Duff. An approximate minimum degree ordering algorithm. SIAM Journal on Matrix Analysis and Applications , 17(4):886--905, 1996
1996
-
[3]
U mit V. C ataly\
Cevdet Aykanat, Ali Pinar, and \" U mit V. C ataly\" u rek. Permuting sparse rectangular matrices into block-diagonal form. SIAM Journal on Scientific Computing , 25(6):1860--1879, 2004
2004
-
[4]
Solving sparse triangular linear systems on parallel computers
Edward Anderson and Youcef Saad. Solving sparse triangular linear systems on parallel computers. International Journal of High Speed Computing , 1(01):73--95, 1989
1989
-
[5]
A split execution model for sptrsv
Najeeb Ahmad, Buse Yilmaz, and Didem Unat. A split execution model for sptrsv. IEEE Transactions on Parallel and Distributed Systems , 32(11):2809--2822, 2021
2021
-
[6]
Bisseling, Bas Fagginger Auer, Tristan van Leeuwen, Wouter Meesen, Marco van Oort, Daan Pelt, Brendan Vastenhouw, and Albert-Jan N
Rob H. Bisseling, Bas Fagginger Auer, Tristan van Leeuwen, Wouter Meesen, Marco van Oort, Daan Pelt, Brendan Vastenhouw, and Albert-Jan N. Yzelman. Mondriaan (version 4.2.1). http://www.staff.science.uu.nl/ bisse101/Mondriaan/mondriaan_v4.2.1.tar.gz, 2019
2019
-
[7]
Matzoros, P\'al Andr\'as Papp, and Raphael S
Toni B\"ohnlein, Benjamin Lozes, Christos K. Matzoros, P\'al Andr\'as Papp, and Raphael S. Steiner. OneStopParallel . https://github.com/Algebraic-Programming/OneStopParallel, 2024
2024
-
[8]
Toni B \"o hnlein, P \'a l Andr \'a s Papp, Raphael S. Steiner, Christos K. Matzoros, and Albert-Jan N. Yzelman. Efficient parallel scheduling for sparse triangular solvers. arXiv preprint arXiv:2503.05408 , 2025
arXiv 2025
-
[9]
Steiner, and Albert-Jan N
Toni B \"o hnlein, P \'a l Andr \'a s Papp, Raphael S. Steiner, and Albert-Jan N. Yzelman. Efficient parallel scheduling for sparse triangular solvers. In 2025 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW) , pages 1263--1265, 2025
2025
-
[10]
Cleveland Ashcraft, Roger G
C. Cleveland Ashcraft, Roger G. Grimes, John G. Lewis, Barry W. Peyton, Horst D. Simon, and Petter E. Bj rstad. Progress in sparse matrix methods for large linear systems on vector supercomputers. The International Journal of Supercomputing Applications , 1(4):10--30, 1987
1987
-
[11]
Ganger, Phillip B
Henggang Cui, James Cipar, Qirong Ho, Jin Kyu Kim, Seunghak Lee, Abhimanu Kumar, Jinliang Wei, Wei Dai, Gregory R. Ganger, Phillip B. Gibbons, Garth A. Gibson, and Eric P. Xing. Exploiting bounded staleness to speed up big data analytics. In 2014 USENIX Annual Technical Conference (USENIX ATC 14) , pages 37--48, Philadelphia, PA, June 2014. USENIX Association
2014
-
[12]
Transforming Sparse Matrix Computations
Kazem Cheshmi. Transforming Sparse Matrix Computations . PhD thesis, University of Toronto, Computer Science, 2022
2022
-
[13]
Ganger, Garth Gibson, Kimberly Keeton, and Eric P
James Cipar, Qirong Ho, Jin Kyu Kim, Seunghak Lee, Gregory R. Ganger, Garth Gibson, Kimberly Keeton, and Eric P. Xing. Solving the straggler problem with bounded staleness. In 14th Workshop on Hot Topics in Operating Systems (HotOS XIV) , Santa Ana Pueblo, NM, May 2013. USENIX Association
2013
-
[14]
Sympiler: Transforming sparse matrix codes by decoupling symbolic analysis
Kazem Cheshmi, Shoaib Kamil, Michelle Mills Strout, and Maryam Mehri Dehnavi. Sympiler: Transforming sparse matrix codes by decoupling symbolic analysis. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis , SC '17, pages 13:1--13:13, New York, NY, USA, 2017. ACM
2017
-
[15]
Davis and Yifan Hu
Timothy A. Davis and Yifan Hu. The U niversity of F lorida sparse matrix collection. ACM Transactions on Mathematical Software (TOMS) , 38(1):1--25, 2011
2011
-
[16]
Openmp: an industry standard api for shared-memory programming
Leonardo Dagum and Ramesh Menon. Openmp: an industry standard api for shared-memory programming. Computational Science & Engineering, IEEE , 5(1):46--55, 1998
1998
-
[17]
Dolan and Jorge J
Elizabeth D. Dolan and Jorge J. Mor \'e . Benchmarking optimization software with performance profiles. Mathematical programming , 91:201--213, 2002
2002
-
[18]
Kiril Dichev, Filip Pawlowski, and Albert-Jan N. Yzelman. Faster distributed inference-only recommender systems via bounded lag synchronous collectives. arXiv preprint arXiv:2512.19342 , 2025
arXiv 2025
-
[19]
Duff and Jennifer A
Iain S. Duff and Jennifer A. Scott. Stabilized bordered block diagonal forms for parallel sparse solvers. Parallel Computing , 31(3):275--289, 2005
2005
-
[20]
Pangulu: A scalable regular two-dimensional block-cyclic sparse direct solver on distributed heterogeneous systems
Xu Fu, Bingbin Zhang, Tengcheng Wang, Wenhao Li, Yuechen Lu, Enxin Yi, Jianqi Zhao, Xiaohan Geng, Fangying Li, Jingwen Zhang, Zhou Jin, and Weifeng Liu. Pangulu: A scalable regular two-dimensional block-cyclic sparse direct solver on distributed heterogeneous systems. In Proceedings of the International Conference for High Performance Computing, Networkin...
2023
-
[21]
Boman, Simplice Donfack, and Timothy A
Laura Grigori, Erik G. Boman, Simplice Donfack, and Timothy A. Davis. Hypergraph-based unsymmetric nested dissection ordering for sparse lu factorization. SIAM Journal on Scientific Computing , 32(6):3426--3446, 2010
2010
-
[22]
Nested dissection of a regular finite element mesh
Alan George. Nested dissection of a regular finite element mesh. SIAM Journal on Numerical Analysis , 10(2):345--363, 1973
1973
-
[23]
Eigen v3
Ga\" e l Guennebaud, Beno\^ i t Jacob, et al. Eigen v3. http://eigen.tuxfamily.org, 2010
2010
-
[24]
Ronald L. Graham. Bounds on multiprocessing timing anomalies. SIAM journal on Applied Mathematics , 17(2):416--429, 1969
1969
-
[25]
The fuzzy barrier: a mechanism for high speed synchronization of processors
Rajiv Gupta. The fuzzy barrier: a mechanism for high speed synchronization of processors. In Proceedings of the Third International Conference on Architectural Support for Programming Languages and Operating Systems , ASPLOS III, page 54–63, New York, NY, USA, 1989. Association for Computing Machinery
1989
-
[26]
Anger, and Chung-Yee Lee
Jing-Jang Hwang, Yuan-Chieh Chow, Frank D. Anger, and Chung-Yee Lee. Scheduling precedence graphs in systems with interprocessor communication times. siam journal on computing , 18(2):244--257, 1989
1989
-
[27]
Gibbons, Garth A
Qirong Ho, James Cipar, Henggang Cui, Jin Kyu Kim, Seunghak Lee, Phillip B. Gibbons, Garth A. Gibson, Gregory R. Ganger, and Eric P. Xing. More effective distributed ml via a stale synchronous parallel parameter server. In Proceedings of the 27th International Conference on Neural Information Processing Systems - Volume 1 , NIPS'13, page 1223–1231, Red Ho...
2013
-
[28]
A survey of barrier algorithms for coarse grained supercomputers
Torsten Hoefler, Torsten Mehlan, Frank Mietke, and Wolfgang Rehm. A survey of barrier algorithms for coarse grained supercomputers . Universit \"a tsbibliothek Chemnitz, 2005
2005
-
[29]
A fast and high quality multilevel scheme for partitioning irregular graphs
George Karypis and Vipin Kumar. A fast and high quality multilevel scheme for partitioning irregular graphs. SIAM Journal on scientific Computing , 20(1):359--392, 1998
1998
-
[30]
Patrick P. C. Lee, Tian Bu, and Girish Chandranmenon. A lock-free, cache-efficient shared ring buffer for multi-core architectures. In Proceedings of the 5th ACM/IEEE Symposium on Architectures for Networking and Communications Systems , ANCS '09, page 78–79, New York, NY, USA, 2009. Association for Computing Machinery
2009
-
[31]
Unified communication optimization strategies for sparse triangular solver on cpu and gpu clusters
Yang Liu, Nan Ding, Piyush Sao, Samuel Williams, and Xiaoye Sherry Li. Unified communication optimization strategies for sparse triangular solver on cpu and gpu clusters. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis , SC '23, New York, NY, USA, 2023. Association for Computing Machinery
2023
-
[32]
Xiaoye S. Li. An overview of superlu: Algorithms, implementation, and user interface. ACM Trans. Math. Softw. , 31(3):302–325, September 2005
2005
-
[33]
Duff, and Brian Vinter
Weifeng Liu, Ang Li, Jonathan Hogg, Iain S. Duff, and Brian Vinter. A synchronization-free algorithm for parallel sparse triangular solves. In Euro-Par 2016: Parallel Processing: 22nd International Conference on Parallel and Distributed Computing, Grenoble, France, August 24-26, 2016, Proceedings 22 , pages 617--630. Springer, 2016
2016
-
[34]
Efficient block algorithms for parallel sparse triangular solve
Zhengyang Lu, Yuyao Niu, and Weifeng Liu. Efficient block algorithms for parallel sparse triangular solve. In Proceedings of the 49th International Conference on Parallel Processing , pages 1--11, 2020
2020
-
[35]
Joseph W. H. Liu, Esmond G. Ng, and Barry W. Peyton. On finding supernodes for sparse matrix computations. SIAM Journal on Matrix Analysis and Applications , 14(1):242--252, 1993
1993
-
[36]
Lipton, Donald J
Richard J. Lipton, Donald J. Rose, and Robert Endre Tarjan. Generalized nested dissection. SIAM Journal on Numerical Analysis , 16(2):346--358, 1979
1979
-
[37]
Parallel algorithms for solving linear systems with sparse triangular matrices
Jan Mayer. Parallel algorithms for solving linear systems with sparse triangular matrices. Computing , 86:291--312, 2009
2009
-
[38]
An efficient parallel scheduling algorithm of dependent task graphs
Shang Mingsheng, Sun Shixin, and Wang Qingxian. An efficient parallel scheduling algorithm of dependent task graphs. In Proceedings of the Fourth International Conference on Parallel and Distributed Computing, Applications and Technologies , pages 595--598. IEEE, 2003
2003
-
[39]
P \'a l Andr \'a s Papp, Georg Anegg, Aikaterini Karanasiou, and Albert-Jan N. Yzelman. Efficient M ulti- P rocessor S cheduling in I ncreasingly R ealistic M odels. In Proceedings of the 36th ACM Symposium on Parallelism in Algorithms and Architectures . ACM, 2024
2024
-
[40]
Sparsifying synchronization for high-performance shared-memory sparse triangular solver
Jongsoo Park, Mikhail Smelyanskiy, Narayanan Sundaram, and Pradeep Dubey. Sparsifying synchronization for high-performance shared-memory sparse triangular solver. In Supercomputing: 29th International Conference, ISC 2014, Leipzig, Germany, June 22-26, 2014. Proceedings 29 , pages 124--140. Springer, 2014
2014
-
[41]
Parallel ICCG on a hierarchical memory multiprocessor—addressing the triangular solve bottleneck
Edward Rothberg and Anoop Gupta. Parallel ICCG on a hierarchical memory multiprocessor—addressing the triangular solve bottleneck. Parallel Computing , 18(7):719--741, 1992
1992
-
[42]
SPSCQueue
Erik Rigtorp. SPSCQueue . https://github.com/rigtorp/SPSCQueue, 2020
2020
-
[43]
Andrei Radulescu and Arjan J. C. Van Gemund. Low-cost task scheduling for distributed-memory machines. IEEE Transactions on Parallel and Distributed Systems , 13(6):648--658, 2002
2002
-
[44]
Joel H. Saltz. Aggregation methods for solving sparse triangular systems on multiprocessors. SIAM journal on scientific and statistical computing , 11(1):123--144, 1990
1990
-
[45]
Solving unsymmetric sparse systems of linear equations with pardiso
Olaf Schenk and Klaus Gärtner. Solving unsymmetric sparse systems of linear equations with pardiso. Future Generation Computer Systems , 20(3):475--487, 2004. Selected numerical algorithms
2004
-
[46]
Pardiso: a high-performance serial and parallel sparse linear solver in semiconductor device simulation
Olaf Schenk, Klaus Gärtner, Wolfgang Fichtner, and Andreas Stricker. Pardiso: a high-performance serial and parallel sparse linear solver in semiconductor device simulation. Future Generation Computer Systems , 18(1):69--78, 2001. I. High Performance Numerical Methods and Applications. II. Performance Data Mining: Automated Diagnosis, Adaption, and Optimization
2001
-
[47]
Saltz, Ravi Mirchandaney, and Doug Baxter
Joel H. Saltz, Ravi Mirchandaney, and Doug Baxter. Run-time parallelization and scheduling of loops. Technical report, Institute for Computer Applications in Science and Engineering, NASA Langley Research Center, 1988
1988
-
[48]
Leslie G. Valiant. A bridging model for parallel computation. Communications of the ACM , 33(8):103--111, 1990
1990
-
[49]
Leslie G. Valiant. General purpose parallel architectures. In Algorithms and Complexity , pages 943--971. Elsevier, 1990
1990
-
[50]
Performance portable supernode-based sparse triangular solver for manycore architectures
Ichitaro Yamazaki, Sivasankaran Rajamanickam, and Nathan Ellingwood. Performance portable supernode-based sparse triangular solver for manycore architectures. In Proceedings of the 49th International Conference on Parallel Processing , pages 1--11, 2020
2020
-
[51]
Adaptive level binning: A new algorithm for solving sparse triangular systems
Buse Y lmaz, Bu g rra Sipahio g rlu, Najeeb Ahmad, and Didem Unat. Adaptive level binning: A new algorithm for solving sparse triangular systems. In Proceedings of the International Conference on High Performance Computing in Asia-Pacific Region , pages 188--198, 2020
2020
-
[52]
Dynamic stale synchronous parallel distributed training for deep learning
Xing Zhao, Aijun An, Junfeng Liu, and Bao Xin Chen. Dynamic stale synchronous parallel distributed training for deep learning. In 39th IEEE International Conference on Distributed Computing Systems, ICDCS 2019, Dallas, TX, USA, July 7-10, 2019 , pages 1507--1517. IEEE , 2019
2019
-
[53]
HDagg : hybrid aggregation of loop-carried dependence iterations in sparse matrix computations
Behrooz Zarebavani, Kazem Cheshmi, Bangtian Liu, Michelle Mills Strout, and Maryam Mehri Dehnavi. HDagg : hybrid aggregation of loop-carried dependence iterations in sparse matrix computations. In 2022 IEEE International Parallel and Distributed Processing Symposium (IPDPS) , pages 1217--1227. IEEE, 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.