CTseg: A Tool for Brain CT Segmentation, Spatial Normalisation, and Volumetrics
Pith reviewed 2026-05-08 15:18 UTC · model grok-4.3
The pith
CTseg tool produces accurate brain tissue maps and volumes from routine CT scans
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CTseg applies a generative modelling approach to CT images to generate tissue probability maps, deformation fields for spatial normalisation, and estimates of total brain and intracranial volume in a format compatible with established MRI analysis chains, and validation on paired MR/CT scans shows significantly higher segmentation accuracy, sharper group-average normalisation, lower voxelwise variability, and stronger agreement on total brain volume than direct application of the MRI pipeline to CT.
What carries the argument
The CTseg pipeline that generates CT-specific tissue maps and deformation fields from raw head CT images without preprocessing or resampling
If this is right
- Volumetric measurements of total brain volume from CT become more reliable and can be compared directly with MRI-derived values.
- Group-level spatial normalisation of CT images reaches consistency levels previously available only for MRI cohorts.
- Tissue maps produced by CTseg support downstream classification tasks such as sex prediction at levels comparable to MRI-based maps.
- Routine clinical CT scans can be fed into the same analysis workflows used for MRI without additional image preparation steps.
Where Pith is reading between the lines
- Hospital CT databases could be mined retrospectively for brain morphometry at scales not feasible with MRI alone.
- The same modelling strategy might be adapted to produce quantitative outputs from other CT body regions or modalities that currently lack dedicated segmentation tools.
- Integration of CTseg into existing hospital PACS systems would allow automated volumetrics to appear alongside standard radiological reports.
Load-bearing premise
The MRI-derived reference labels accurately mark the true tissue boundaries visible on CT, and the paired scans used for testing represent ordinary clinical CT data.
What would settle it
Independent manual tracings of tissue boundaries on the same CT scans that show lower overlap with CTseg outputs than with the MRI silver standard, or a drop in performance when the tool is run on unpaired CT scans from varied scanners and protocols.
Figures





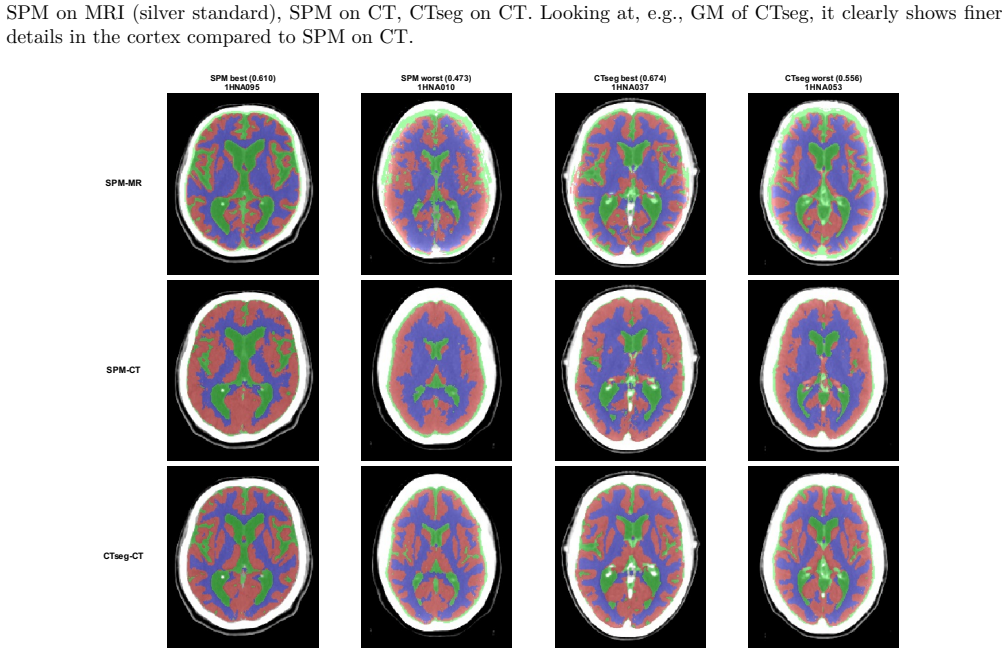




read the original abstract
This paper presents and validates CTseg, a freely available software for brain CT segmentation, spatial normalisation, and volumetrics. CTseg builds on the Multi-Brain generative modelling framework, providing a CT-specific pipeline that produces tissue maps, deformation fields, and brain volume estimates in the same format as SPM's unified segmentation, thereby extending SPM's established analysis chain from MRI to CT. CTseg is designed for routine hospital CT scans without requiring preprocessing or resampling in deployment. Although CTseg has been adopted in clinical research spanning, among other things, stroke, dementia, and brain morphometry, a systematic validation against an independent reference standard has been lacking. Using paired MR/CT head scans, we evaluate CTseg across four dimensions: segmentation accuracy against an MRI-derived silver standard; spatial normalisation consistency through group-average sharpness and voxelwise coefficient of variation; brain volume agreement via intraclass correlation and Bland-Altman analysis; and downstream sex classification performance from normalised tissue maps. As a baseline, we apply SPM's MRI-based unified segmentation directly to the CT images. CTseg significantly outperformed this baseline for segmentation and normalisation, showed stronger TBV agreement, and achieved comparable TIV agreement. CTseg is freely available at https://github.com/WCHN/CTseg, and all experiment code is included in the repository for full reproducibility.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents CTseg, a freely available tool extending the Multi-Brain generative modelling framework to provide CT-specific brain segmentation, spatial normalisation, and volumetrics in SPM-compatible format. It is designed for routine clinical CT scans without preprocessing. Validation uses paired MR/CT head scans to compare against SPM's MRI-based unified segmentation baseline across segmentation accuracy (vs. MRI-derived silver standard), normalisation consistency (group-average sharpness and voxelwise CoV), brain volume agreement (ICC and Bland-Altman for TBV/TIV), and downstream sex classification from normalised maps. The abstract reports that CTseg significantly outperformed the baseline on segmentation and normalisation, showed stronger TBV agreement, and comparable TIV agreement.
Significance. If the central claims hold after addressing validation details, the work is significant for extending established MRI analysis pipelines to CT, which is widely used in clinical settings for stroke, dementia, and morphometry research. The provision of all experiment code in the public repository is a clear strength supporting reproducibility and adoption.
major comments (2)
- [Abstract and Methods (validation)] Abstract and Methods (validation section): Segmentation accuracy is assessed against an MRI-derived silver standard transferred to paired CT images. CT has substantially lower soft-tissue contrast than MRI (particularly GM/WM boundaries and partial-volume effects), so the transferred labels may not reflect CT-visible anatomy; without reported quantification of MR-CT registration error, label uncertainty specific to CT, or sensitivity analysis, the reported significant outperformance over SPM on Dice/accuracy metrics is not yet secured.
- [Results (volume agreement and normalisation)] Results (volume agreement and normalisation): The claims of stronger TBV agreement and superior normalisation rest on ICC, Bland-Altman, sharpness, and CoV metrics, but the manuscript provides no details on statistical testing (e.g., p-values for outperformance), sample size after exclusions, or handling of outliers in the paired scans; these omissions are load-bearing for the superiority conclusions.
minor comments (2)
- [Abstract] The abstract states that CTseg 'significantly outperformed' the baseline but does not include effect sizes or exact p-values in the summary, which would improve clarity for readers.
- [Availability and Reproducibility] The GitHub repository link is given, but the manuscript could more explicitly state which validation datasets (if any) are included or how users can reproduce the exact paired-scan experiments.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive comments. The points raised identify opportunities to strengthen the reporting of our validation procedures. We address each major comment below and will incorporate the requested details into a revised manuscript.
read point-by-point responses
-
Referee: [Abstract and Methods (validation)] Abstract and Methods (validation section): Segmentation accuracy is assessed against an MRI-derived silver standard transferred to paired CT images. CT has substantially lower soft-tissue contrast than MRI (particularly GM/WM boundaries and partial-volume effects), so the transferred labels may not reflect CT-visible anatomy; without reported quantification of MR-CT registration error, label uncertainty specific to CT, or sensitivity analysis, the reported significant outperformance over SPM on Dice/accuracy metrics is not yet secured.
Authors: We agree that the MRI-derived silver standard is an imperfect reference for CT due to modality-specific contrast differences and potential registration inaccuracies. The paired MR/CT design was chosen precisely to enable this cross-modal comparison, with the silver standard generated via a multi-modal registration pipeline. To secure the outperformance claims, the revised Methods section will include: (i) quantitative assessment of MR-CT registration accuracy (e.g., landmark-based errors or overlap metrics on a subset of cases), (ii) explicit discussion of label uncertainty arising from partial-volume effects in CT, and (iii) a sensitivity analysis showing how variations in registration parameters affect the reported Dice and accuracy differences. These additions will allow readers to evaluate the robustness of the superiority findings. revision: yes
-
Referee: [Results (volume agreement and normalisation)] Results (volume agreement and normalisation): The claims of stronger TBV agreement and superior normalisation rest on ICC, Bland-Altman, sharpness, and CoV metrics, but the manuscript provides no details on statistical testing (e.g., p-values for outperformance), sample size after exclusions, or handling of outliers in the paired scans; these omissions are load-bearing for the superiority conclusions.
Authors: We acknowledge that the current Results section omits key statistical details supporting the superiority claims. In the revision we will add: (i) p-values from appropriate paired statistical tests (e.g., Wilcoxon signed-rank or paired t-tests) comparing CTseg versus baseline metrics, (ii) the exact sample size after any exclusions (with reasons for exclusion such as motion or failed registration), and (iii) a description of outlier handling together with sensitivity results obtained with and without outliers. These additions will make the evidence for stronger TBV agreement and superior normalisation fully transparent and reproducible. revision: yes
Circularity Check
Minor self-citation to Multi-Brain framework; validation chain remains independent
full rationale
The paper extends an existing generative modelling framework to CT images and validates performance on paired MR/CT scans using external metrics (Dice against MRI silver standard, group-average sharpness, ICC/Bland-Altman for volumes). No derivation reduces by construction to fitted parameters or self-defined quantities; the baseline (SPM applied to CT) and silver standard are independent references. Self-citation to the prior framework is present but not load-bearing for the reported superiority claims.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.