RouteBalance: Fused Model Routing and Load Balancing for Heterogeneous LLM Serving
Pith reviewed 2026-06-26 22:45 UTC · model grok-4.3
The pith
RouteBalance fuses model routing and load balancing into one online assignment over concrete instances for heterogeneous LLM serving.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
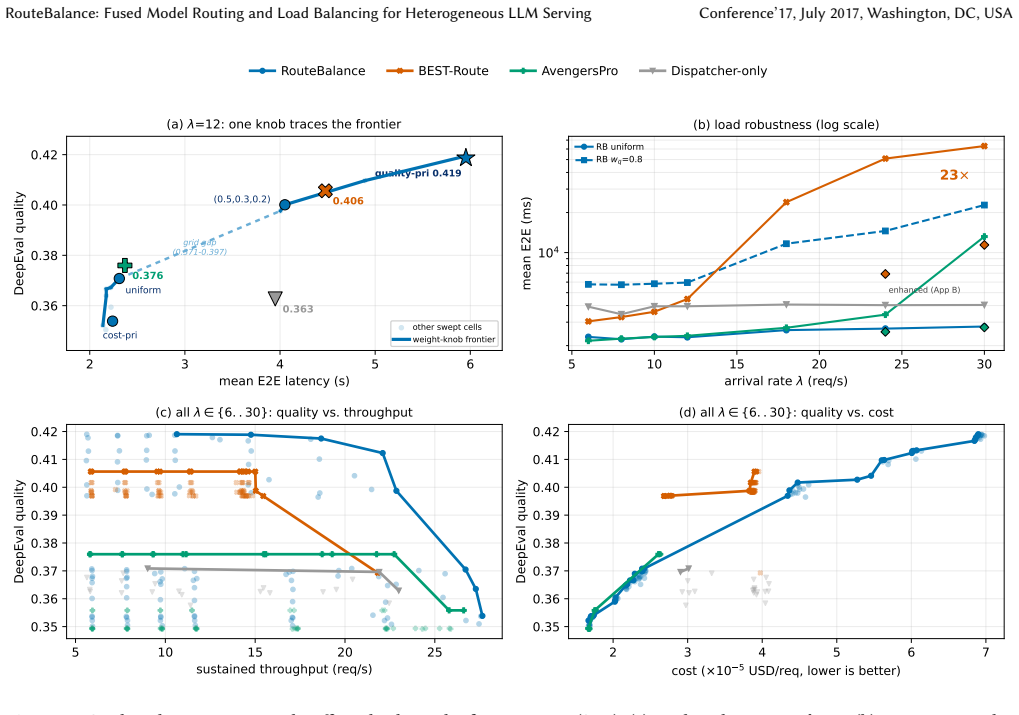
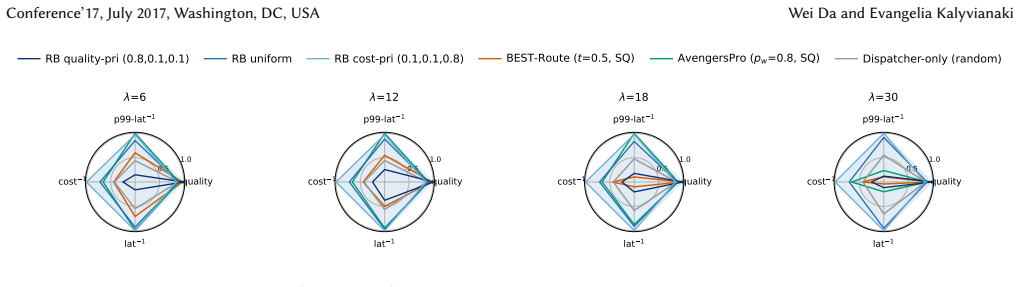
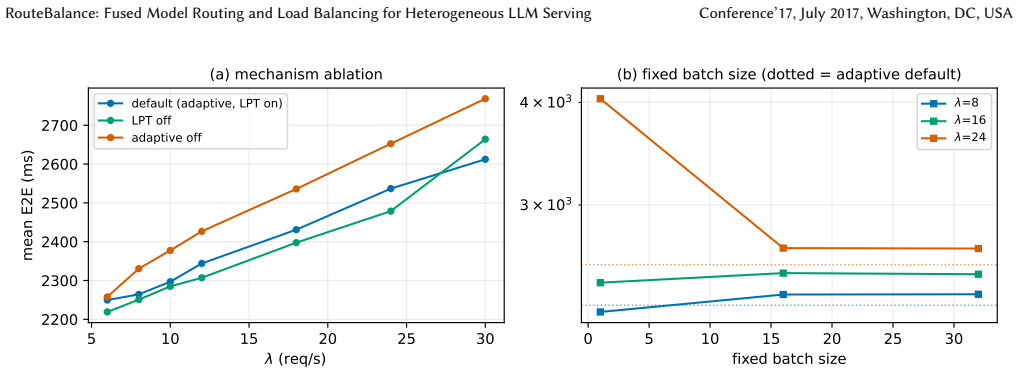
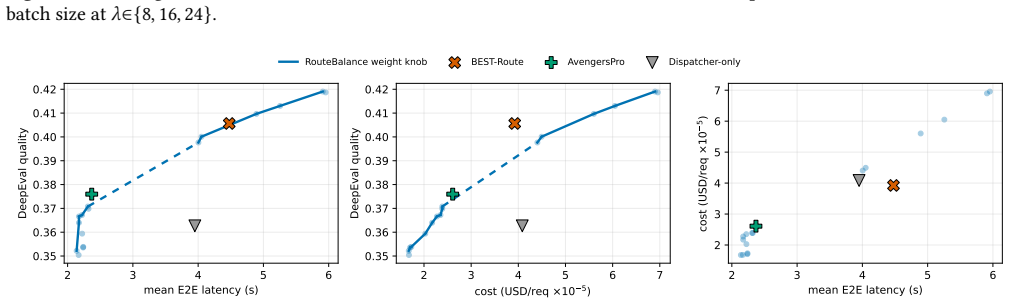
RouteBalance performs a single online assignment over concrete model instances that jointly trades off quality, latency, and cost. A batched in-process predictor stack and dead-reckoned instance state keep the decision cheap at approximately 32 ms per request at 12 req/s. On a 13-instance 28-GPU cluster serving four model sizes, one deployed stack reaches the upper region of the three-way frontier: highest DeepEval score of 0.419 and, at the cost corner, per-request cost matching the cheapest baseline, with the balanced setting leading baselines by 2.6 to 4.1 times at high load. The gain follows from pricing latency at model-selection time; the learned predictors add calibration and SLO head
What carries the argument
The fused online assignment over concrete model instances that prices latency at model-selection time using a batched predictor stack and dead-reckoned state.
If this is right
- Sweeping one weight vector reaches both the highest routing quality (DeepEval 0.419) and, at its cost corner, per-request cost that ties the cheapest baseline.
- The balanced preset serves at 2.8 s and 30 req/s, leading enhanced baselines by 2.6 to 4.1 times at high load.
- The performance gain follows from pricing latency during model selection rather than from the predictors alone.
- A four-arm isolation isolates the benefit to the joint decision; predictors mainly supply calibration and headroom.
Where Pith is reading between the lines
- The same collapsed-decision pattern could apply to other multi-objective serving problems that currently keep routing and placement in separate layers.
- Production use would require ongoing checks on predictor drift and state error to keep the reported frontier gains.
- The method could be extended to clusters with more model variants or different hardware mixes to test whether the single-weight-vector property scales.
- Operators might use the cost-priority corner to meet latency SLOs at lower total spend without running two separate tuning loops.
Load-bearing premise
The batched predictor stack and dead-reckoned instance state stay accurate and fast enough on the hot path when traffic patterns and model update rates match real production use.
What would settle it
A measurement showing that predictor error or state drift under sustained load causes the fused decisions to fall below the quality or cost of separately tuned router-plus-balancer baselines.
Figures
read the original abstract
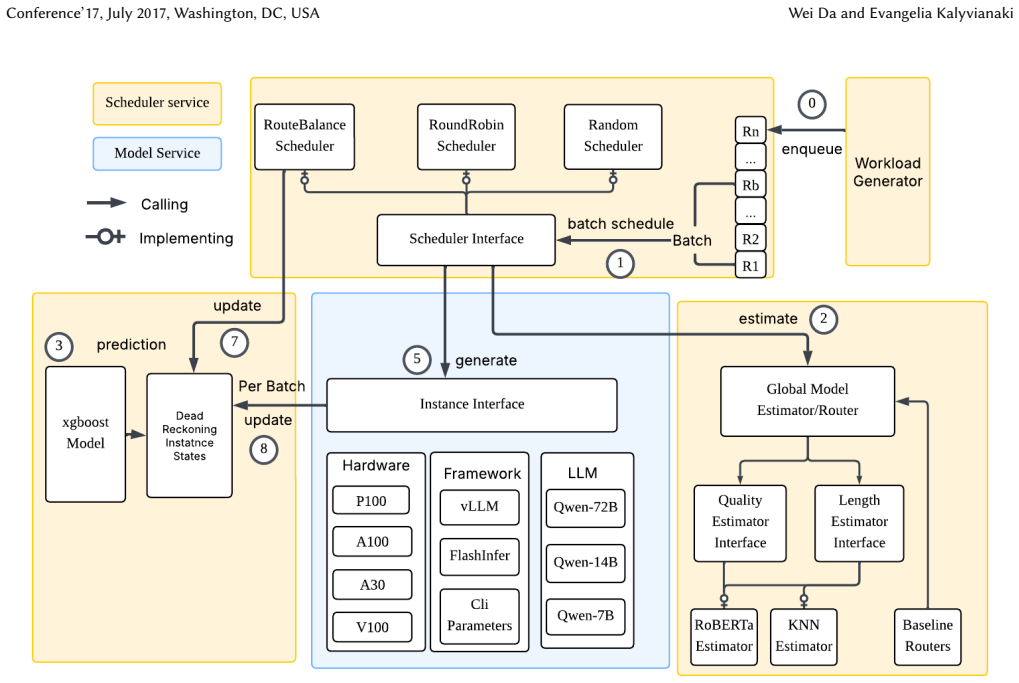
Heterogeneous LLM serving stacks split scheduling into two layers that optimize in isolation: model routers pick a model from quality and cost signals while ignoring instance load, and serving load balancers optimize queues while ignoring quality. We present RouteBalance, a serving-aware scheduling layer that fuses both into a single online assignment over concrete model instances, jointly trading off quality, latency, and cost. A batched in-process predictor stack and dead-reckoned instance state keep the joint decision cheap on the request hot path ($\approx$32 ms at 12 req/s). On a 13-instance, 28-GPU heterogeneous cluster serving four model sizes, a single deployed RouteBalance stack traces the upper region of the three-way quality-cost-throughput frontier. Sweeping one weight vector reaches both the highest routing-decision quality (DeepEval $0.419$, $+0.013$ over the strongest baseline, $95\%$ CI $[{+}0.005,{+}0.022]$; the ordering holds when a second judge re-scores the actually served text) and, at its cost-priority corner, per-request cost that ties the cheapest baseline. With router engineering equalized against concurrent-scoring baseline variants we build, its balanced preset serves at $2.8$ s and $30$ req/s, leading $2.6$ to $4.1\times$ ahead of enhanced BEST-Route at high load. (Deploying those routers as published, one serial scoring call per request, makes them collapse $23\times$ under load, a deployment-architecture effect we isolate separately, not the routing result.) A four-arm isolation shows the benefit follows from pricing latency at model-selection time; the learned predictors contribute calibration and SLO headroom rather than the headline frontier. Code: https://github.com/AKafakA/route-balance
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. RouteBalance fuses model routing and load balancing for heterogeneous LLM serving into a single online assignment over concrete instances. It uses a batched in-process predictor stack and dead-reckoned instance state to keep joint decisions cheap (~32 ms at 12 req/s). On a 13-instance, 28-GPU cluster serving four model sizes, sweeping one weight vector traces the upper region of the quality-cost-throughput frontier, reaching DeepEval 0.419 (+0.013 over strongest baseline, 95% CI [+0.005, +0.022]) at one corner and tying the cheapest baseline cost at the other; the balanced preset serves at 2.8 s and 30 req/s, leading enhanced baselines 2.6-4.1x at high load. A four-arm isolation attributes the benefit to pricing latency at model-selection time.
Significance. If the empirical frontier and hot-path claims hold under production conditions, the work offers a practical advance for multi-objective LLM serving by collapsing two isolated layers into one. The public code repository is a clear strength that supports reproducibility. The result is most relevant to systems papers on inference serving rather than theoretical scheduling; its impact would be strengthened by explicit validation of predictor accuracy beyond the single reported operating point.
major comments (2)
- [Abstract] Abstract: The central claim that a single deployed RouteBalance stack traces the upper frontier depends on the batched predictor stack and dead-reckoned state remaining accurate on the hot path. Only the 32 ms figure at 12 req/s is supplied; no measurements of predictor error, state drift, or behavior at the 30 req/s operating point, under varying traffic, or with model updates are reported. This is load-bearing for the feasibility assertion.
- [Abstract] Abstract: The 95% CI on the DeepEval improvement is stated, yet the manuscript supplies no derivation of the joint objective, no error-bar methodology, and no raw data or full experimental protocol. The four-arm isolation is invoked to separate the contribution of latency pricing from the learned predictors, but the concrete arm definitions and statistical tests are not shown.
minor comments (1)
- [Abstract] Abstract: The parenthetical remark on serial-scoring collapse (23x) is presented as an architecture effect isolated separately; a brief pointer to the relevant section or figure would clarify that this is not part of the routing result itself.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for stronger validation of the hot-path claims and for more transparent experimental methodology. We address both points below with clarifications drawn from the existing experiments and will revise the manuscript to make the supporting evidence explicit.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that a single deployed RouteBalance stack traces the upper frontier depends on the batched predictor stack and dead-reckoned state remaining accurate on the hot path. Only the 32 ms figure at 12 req/s is supplied; no measurements of predictor error, state drift, or behavior at the 30 req/s operating point, under varying traffic, or with model updates are reported. This is load-bearing for the feasibility assertion.
Authors: The 30 req/s result is obtained with the deployed RouteBalance stack, so the hot path (including batched prediction and dead-reckoning) demonstrably sustains that rate for the duration of the reported runs. The 32 ms figure is the per-request latency at 12 req/s; at higher load the batching amortizes it. Predictor error was measured offline on held-out traces and remains below 12% relative error for latency; we will add the per-load-point breakdown and state-drift statistics from the cluster logs. Varying traffic and model-update scenarios are outside the static-deployment scope of the current evaluation; we will note this limitation explicitly. revision: partial
-
Referee: [Abstract] Abstract: The 95% CI on the DeepEval improvement is stated, yet the manuscript supplies no derivation of the joint objective, no error-bar methodology, and no raw data or full experimental protocol. The four-arm isolation is invoked to separate the contribution of latency pricing from the learned predictors, but the concrete arm definitions and statistical tests are not shown.
Authors: The joint objective is the weighted sum of normalized quality, cost, and latency defined in Section 3.2; the 95% CI is computed by bootstrap resampling across five independent cluster runs. The four arms are (1) full RouteBalance, (2) latency-unaware routing, (3) predictor-disabled routing, and (4) enhanced baseline; differences are tested with paired t-tests on per-request metrics. We will add the exact objective formula, bootstrap procedure, arm definitions, and test results to the experimental section and deposit the raw request logs in the public repository. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper's central claim rests on empirical evaluation of a fused scheduler whose weight-vector sweep is presented as an external tunable knob that traces the reported frontier. No equations, fitted parameters, or self-citations are shown that reduce the quality, cost, or throughput results to self-referential definitions or to inputs called predictions by construction. The batched predictor stack and dead-reckoned state are described as implementation mechanisms whose accuracy is asserted via a single latency figure, but this assertion is not derived from the result itself and does not create a circular reduction. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Agrawal, A., Kedia, N., Mohan, J., Panwar, A., Kwatra, N., Gula- vani, B. S., Ramjee, R., and Tumanov, A.Vidur: A large-scale simula- tion framework for llm inference.ArXiv abs/2405.05465(2024)
-
[2]
D., Williams, T., Sitaraman, R
Ahmad, S., Guan, H., Friedman, B. D., Williams, T., Sitaraman, R. K., and Woo, T.Proteus: A high-throughput inference-serving system with accuracy scaling. InProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), Volume 1(2024), pp. 318–334
2024
-
[3]
InSparsity in LLMs (SLLM): Deep Dive into Mixture of Experts, Quantization, Hardware, and Inference(2025)
Arango, I., Noori, A., Huang, Y., Shahout, R., and Yu, M.Prefix and output length-aware scheduling for efficient online LLM infer- ence. InSparsity in LLMs (SLLM): Deep Dive into Mixture of Experts, Quantization, Hardware, and Inference(2025)
2025
-
[4]
Bao, R., Xue, N., Sun, Y., and Chen, Z.Dynamic quality-latency aware routing for llm inference in wireless edge-device networks, 2025
2025
-
[5]
Small Language Models are the Future of Agentic AI
Belcak, P., Heinrich, G., Diao, S., Fu, Y., Dong, X., Muralidharan, S., Lin, Y. C., and Molchanov, P.Small language models are the future of agentic ai.arXiv preprint arXiv:2506.02153(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Bin, K., Choi, S., Son, J., Choi, J., Bae, D., Baek, D., Moon, K., Jang, M., and Lee, H.Fineserve: Precision-aware kv slab and two-level scheduling for heterogeneous precision llm serving, 2025
2025
-
[7]
InProceedings of the Twentieth European Confer- ence on Computer Systems(New York, NY, USA, 2025), EuroSys ’25, Association for Computing Machinery, p
Chang, T.-T., and Venkataraman, S.Eva: Cost-efficient cloud-based cluster scheduling. InProceedings of the Twentieth European Confer- ence on Computer Systems(New York, NY, USA, 2025), EuroSys ’25, Association for Computing Machinery, p. 1399–1416
2025
-
[8]
FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance
Chen, L., Zaharia, M., and Zou, J.Frugalgpt: How to use large language models while reducing cost and improving performance. arXiv preprint arXiv:2305.05176(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Chen, S., Jia, Z., Khan, S., Krishnamurthy, A., and Gibbons, P. B. Slos-serve: Optimized serving of multi-slo llms, 2025
2025
-
[10]
InProceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining(2016), pp
Chen, T., and Guestrin, C.Xgboost: A scalable tree boosting sys- tem. InProceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining(2016), pp. 785–794
2016
-
[11]
In2024 IEEE International Symposium on Workload Characteri- zation (IISWC)(Los Alamitos, CA, USA, Sept
Cho, J., Kim, M., Choi, H., Heo, G., and Park, J.LLMServingSim: A HW/SW Co-Simulation Infrastructure for LLM Inference Serving at Scale . In2024 IEEE International Symposium on Workload Characteri- zation (IISWC)(Los Alamitos, CA, USA, Sept. 2024), IEEE Computer Society, pp. 15–29
2024
-
[12]
Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., Hesse, C., and Schulman, J.Training verifiers to solve math word problems, 2021
2021
-
[13]
Da, W., and Kalyvianaki, E.Block: Balancing load in llm serving with context, knowledge and predictive scheduling, 2025
2025
-
[14]
InThe Thirty-ninth Annual Conference on Neural Information Processing Systems(2026)
Dexter, G., Tang, S., Fatahibaarzi, A., Song, Q., Dharamsi, T., and Gupta, A.LLM query scheduling with prefix reuse and latency con- straints. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems(2026)
2026
-
[15]
Ding, D., Mallick, A., Zhang, S., W ang, C., Madrigal, D., Garcia, M. D. C. H., Xia, M., Lakshmanan, L. V. S., Wu, Q., and Rühle, V. BEST-route: Adaptive LLM routing with test-time optimal compute. InForty-second International Conference on Machine Learning(2025)
2025
-
[16]
Douze, M., Guzhva, A., Deng, C., Johnson, J., Szilvasy, G., Mazaré, P.-E., Lomeli, M., Hosseini, L., and Jégou, H.The faiss library.IEEE Transactions on Big Data(2025)
2025
-
[17]
In 2019 USENIX Annual Technical Conference (USENIX ATC 19)(Renton, WA, July 2019), USENIX Association, pp
Duplyakin, D., Ricci, R., Maricq, A., Wong, G., Duerig, J., Eide, E., Stoller, L., Hibler, M., Johnson, D., Webb, K., Akella, A., Wang, K., Ricart, G., Landweber, L., Elliott, C., Zink, M., Cecchet, E., Kar, S., and Mishra, P.The design and operation of CloudLab. In 2019 USENIX Annual Technical Conference (USENIX ATC 19)(Renton, WA, July 2019), USENIX Ass...
2019
-
[18]
Fan, Q., Zou, A., and Ma, Y.Timebill: Time-budgeted inference for large language models, 2025
2025
-
[19]
Fang, J., Shen, Y., Wang, Y., and Chen, L.Improving the end-to- end efficiency of offline inference for multi-llm applications based on sampling and simulation, 2025
2025
-
[20]
L.Bounds on multiprocessing timing anomalies.SIAM Journal on Applied Mathematics 17, 2 (1969), 416–429
Graham, R. L.Bounds on multiprocessing timing anomalies.SIAM Journal on Applied Mathematics 17, 2 (1969), 416–429
1969
-
[21]
R., Mishra, C
Gunasekaran, J. R., Mishra, C. S., Thinakaran, P., Sharma, B., Kan- demir, M. T., and Das, C. R.Cocktail: A multidimensional optimiza- tion for model serving in cloud. InUSENIX Symposium on Networked Systems Design and Implementation (NSDI)(2022)
2022
-
[22]
RouterBench: A Benchmark for Multi-LLM Routing System
Hu, Q. J., Bieker, J., Li, X., Jiang, N., Keigwin, B., Ranganath, G., Keutzer, K., and Upadhyay, S. K.Routerbench: A benchmark for multi-llm routing system.arXiv preprint arXiv: 2403.12031(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
InAdvances in Neural Information Processing Systems(2023)
Ji, J., Liu, M., Dai, J., Pan, X., Zhang, C., Bian, C., Chen, B., Sun, R., Wang, Y., and Yang, Y.Beavertails: Towards improved safety alignment of llm via a human-preference dataset. InAdvances in Neural Information Processing Systems(2023)
2023
-
[24]
Y.Llm-blender: Ensembling large language models with pairwise ranking and generative fusion
Jiang, D., Ren, X., and Lin, B. Y.Llm-blender: Ensembling large language models with pairwise ranking and generative fusion. In Annual Meeting of the Association for Computational Linguistics (ACL) (2023)
2023
-
[25]
InForty-second International Conference on Machine Learning(2025)
JIANG, Y., Fu, F., Yao, X., HE, G., Miao, X., Klimovic, A., CUI, B., Yuan, B., and Yoneki, E.Demystifying cost-efficiency in LLM serving over heterogeneous GPUs. InForty-second International Conference on Machine Learning(2025)
2025
-
[26]
InEighth Conference on Machine Learning and Systems(2025)
JIANG, Y., Fu, F., Y ao, X., W ang, T., CUI, B., Klimovic, A., and Yoneki, E.Thunderserve: High-performance and cost-efficient LLM serving in cloud environments. InEighth Conference on Machine Learning and Systems(2025)
2025
-
[27]
InProceedings of the 41st International Conference on Machine Learning(2024), ICML’24, JMLR.org
Jiang, Y., Y an, R., Y ao, X., Zhou, Y., Chen, B., and Yuan, B.Hexgen: generative inference of large language model over heterogeneous environment. InProceedings of the 41st International Conference on Machine Learning(2024), ICML’24, JMLR.org
2024
-
[28]
InThe Thirteenth International Conference on Learning Representations(2025)
JIANG, Y., Y an, R., and Yuan, B.Hexgen-2: Disaggregated generative inference of LLMs in heterogeneous environment. InThe Thirteenth International Conference on Learning Representations(2025)
2025
-
[29]
Jitkrittum, W., Narasimhan, H., Rawat, A. S., Juneja, J., Wang, C., Wang, Z., Go, A., Lee, C.-Y., Shenoy, P., Panigrahy, R., et al. Universal model routing for efficient llm inference.arXiv preprint arXiv:2502.08773(2025)
-
[30]
S., Juneja, J., W ang, C., W ang, Z., Go, A., Lee, C.-Y., Shenoy, P., Panigrahy, R., Menon, A
Jitkrittum, W., Narasimhan, H., Rawat, A. S., Juneja, J., W ang, C., W ang, Z., Go, A., Lee, C.-Y., Shenoy, P., Panigrahy, R., Menon, A. K., and Kumar, S.Universal model routing for efficient LLM inference. InThe Fourteenth International Conference on Learning Representations (2026)
2026
-
[31]
H., Dean, J., and Polyzotis, N.The case for learned index structures
Kraska, T., Beutel, A., Chi, E. H., Dean, J., and Polyzotis, N.The case for learned index structures. InProceedings of the 2018 Interna- tional Conference on Management of Data(New York, NY, USA, 2018), SIGMOD ’18, Association for Computing Machinery, p. 489–504
2018
-
[32]
H., Gon- zalez, J., Zhang, H., and Stoica, I.Efficient memory management for large language model serving with pagedattention
Kwon, W., Li, Z., Zhuang, S., Sheng, Y., Zheng, L., Yu, C. H., Gon- zalez, J., Zhang, H., and Stoica, I.Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th Symposium on Operating Systems Principles(New York, NY, USA, 2023), SOSP ’23, Association for Computing Machinery, p. 611–626
2023
-
[33]
Y., Chandu, K., Dziri, N., Kumar, S., Zick, T., Choi, Y., Smith, N
Lambert, N., Pyatkin, V., Morrison, J., Miranda, L., Lin, B. Y., Chandu, K., Dziri, N., Kumar, S., Zick, T., Choi, Y., Smith, N. A., and Hajishirzi, H.Rewardbench: Evaluating reward models for language modeling, 2024
2024
-
[34]
Li, Y.Rethinking predictive LLM routing: When simple KNN beats complex learned routers, 2026
2026
-
[35]
City Research Online, 2013
Mai, L., et al.Exploiting replication for energy-efficient large-scale parallel batch scheduling. City Research Online, 2013
2013
-
[36]
Mei, K., Xu, W., Guo, M., Lin, S., and Zhang, Y.Omnirouter: Budget and performance controllable multi-llm routing.SIGKDD Explor. Newsl. 27, 2 (Dec. 2026), 107–116
2026
-
[37]
Mei, Y., Zhuang, Y., Miao, X., Y ang, J., Jia, Z., and Vinayak, R.Helix: 13 Conference’17, July 2017, Washington, DC, USA Wei Da and Evangelia Kalyvianaki Serving large language models over heterogeneous gpus and network via max-flow. InProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Sy...
2017
-
[38]
RouteLLM: Learning to Route LLMs with Preference Data
Ong, I., Almahairi, A., Wu, V., Chiang, W.-L., Wu, T., Gonzalez, J. E., Kadous, M. W., and Stoica, I.Routellm: Learning to route llms with preference data.arXiv preprint arXiv:2406.18665(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [39]
-
[40]
Patke, A., Reddy, D., Jha, S., Qiu, H., Pinto, C., Narayanaswami, C., Kalbarczyk, Z., and Iyer, R.Queue management for slo-oriented large language model serving, 2025
2025
-
[41]
Storage (Nov
Qin, R., Li, Z., He, W., Cui, J., Tang, H., Ren, F., Ma, T., Cai, S., Zhang, Y., Zhang, M., Wu, Y., Zheng, W., and Xu, X.Mooncake: A kvcache- centric disaggregated architecture for llm serving.ACM Trans. Storage (Nov. 2025). Just Accepted
2025
-
[42]
Qwen Team, Yang, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Li, C., Liu, D., Huang, F., Wei, H., Lin, H., Y ang, J., Tu, J., Zhang, J., Y ang, J., Y ang, J., Zhou, J., Lin, J., Dang, K., Lu, K., Bao, K., Y ang, K., Yu, L., Li, M., Xue, M., Zhang, P., Zhu, Q., Men, R., Lin, R., Li, T., Tang, T., Xia, T., Ren, X., Ren, X., Fan, Y., Su, Y., Zhang, ...
2025
-
[43]
InConference on Empir- ical Methods in Natural Language Processing (EMNLP)(2016)
Rajpurkar, P., Zhang, J., Lopyrev, K., and Liang, P.SQuAD: 100,000+ questions for machine comprehension of text. InConference on Empir- ical Methods in Natural Language Processing (EMNLP)(2016)
2016
-
[44]
R., Deshmukh, A., Tandon, K., Gandhi, R., Parayil, A., and Bhattacherjee, D.Bellman: Controlling llm congestion, 2025
Reddy, T. R., Deshmukh, A., Tandon, K., Gandhi, R., Parayil, A., and Bhattacherjee, D.Bellman: Controlling llm congestion, 2025
2025
-
[45]
J., and Kozyrakis, C.INFaaS: Automated model-less inference serving
Romero, F., Li, Q., Yadwadkar, N. J., and Kozyrakis, C.INFaaS: Automated model-less inference serving. InUSENIX Annual Technical Conference (ATC)(2021)
2021
-
[46]
In Proceedings of the 18th USENIX Conference on Operating Systems Design and Implementation(USA, 2024), OSDI’24, USENIX Association
Sun, B., Huang, Z., Zhao, H., Xiao, W., Zhang, X., Li, Y., and Lin, W.Llumnix: dynamic scheduling for large language model serving. In Proceedings of the 18th USENIX Conference on Operating Systems Design and Implementation(USA, 2024), OSDI’24, USENIX Association
2024
-
[47]
InThe Thirty-ninth Annual Conference on Neural Information Processing Systems(2026)
Sun, T., Wang, P., and Lai, F.Hygen: Efficient LLM serving via elastic online-offline request co-location. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems(2026)
2026
-
[48]
T., Wang, X., Fan, Y., and Lan, Z
Tao, Y., Zhang, Y., Dearing, M. T., Wang, X., Fan, Y., and Lan, Z. Prompt-aware scheduling for low-latency llm serving, 2025
2025
-
[49]
com/confident-ai/deepeval, 2024
Team, D.DeepEval: an LLM evaluation framework.https://github. com/confident-ai/deepeval, 2024
2024
-
[50]
Tian, J., Li, S., Cao, Y., Cui, W., Zhu, M., Wu, W., Zhang, J., Wang, Y., Xiao, Z., Hou, Z., and Shen, D.Staggered batch scheduling: Co- optimizing time-to-first-token and throughput for high-efficiency llm inference, 2025
2025
- [51]
-
[52]
InEuropean Conference on Computer Systems (EuroSys)(2023)
W ang, Y., Chen, K., Tan, H., and Guo, K.Tabi: An efficient multi-level inference system for large language models. InEuropean Conference on Computer Systems (EuroSys)(2023)
2023
-
[53]
Wen, H., Wu, X., Sun, Y., Zhang, F., Chen, L., W ang, J., Liu, Y., Liu, Y., Zhang, Y.-Q., and Li, Y.Budgetthinker: Empowering budget-aware llm reasoning with control tokens, 2025
2025
-
[54]
Weyssow, M., Kamanda, A., and Sahraoui, H.Codeultrafeedback: An llm-as-a-judge dataset for aligning large language models to coding preferences, 2024
2024
-
[55]
InThe Thirty-ninth Annual Confer- ence on Neural Information Processing Systems(2025)
Wu, F., and Silwal, S.PORT: Efficient training-free online routing for high-volume multi-LLM serving. InThe Thirty-ninth Annual Confer- ence on Neural Information Processing Systems(2025). arXiv:2509.02718
-
[56]
B., Narayanaswamy, B., Kraska, T., and Madden, S.Improving dbms scheduling decisions with accurate performance prediction on concurrent queries.Proc
Wu, Z., Markakis, M., Liu, C., Chen, P. B., Narayanaswamy, B., Kraska, T., and Madden, S.Improving dbms scheduling decisions with accurate performance prediction on concurrent queries.Proc. VLDB Endow. 18, 11 (July 2025), 4185–4198
2025
-
[57]
Xu, T., Liu, Y., Lu, X., Zhao, Y., Zhou, X., Feng, A., Chen, Y., Shen, Y., Zhou, Q., Chen, X., Sherstyuk, I., Li, H., Thakkar, R., Hamm, B., Li, Y., Huang, X., Wu, W., Shanbhag, A., Kim, H., Chen, C., and Lai, J.Aiconfigurator: Lightning-fast configuration optimization for multi-framework llm serving, 2026
2026
-
[58]
Yuan, Y., Zhao, C., Zhao, B., Cao, Z., He, Y., and Wu, W.Cascade- infer: Low-latency and load-balanced llm serving via length-aware scheduling.arXiv preprint arXiv:2512.19179(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[59]
InProceedings of the 2025 7th International Confer- ence on Distributed Artificial Intelligence(New York, NY, USA, 2025), DAI ’25, Association for Computing Machinery, p
Zhang, Y., Li, H., Chen, J., Zhang, H., Ye, P., Bai, L., and Hu, S.Be- yond gpt-5: Making llms cheaper and better via performance-efficiency optimized routing. InProceedings of the 2025 7th International Confer- ence on Distributed Artificial Intelligence(New York, NY, USA, 2025), DAI ’25, Association for Computing Machinery, p. 122–129
2025
-
[60]
InProceedings of the 21st European Conference on Computer Systems(New York, NY, USA, 2026), EUROSYS ’26, Association for Computing Machinery, p
Zhao, Z., Hu, Y., Chen, S., Ji, M., Y ang, W., Zhang, Y., Zhao, L., Li, W., Liu, X., Qu, W., and W ang, H.Pard: Enhancing goodput for inference pipeline via proactive request dropping. InProceedings of the 21st European Conference on Computer Systems(New York, NY, USA, 2026), EUROSYS ’26, Association for Computing Machinery, p. 423–438
2026
-
[61]
P., Gonzalez, J
Zheng, L., Chiang, W.-L., Sheng, Y., Li, T., Zhuang, S., Wu, Z., Zhuang, Y., Li, Z., Lin, Z., Xing, E. P., Gonzalez, J. E., Stoica, I., and Zhang, H.LMSYS-Chat-1M: A large-scale real-world LLM conversa- tion dataset. InInternational Conference on Learning Representations (ICLR)(2024)
2024
-
[62]
Zheng, W., Xu, M., Song, S., and Ye, K.Bucketserve: Bucket-based dynamic batching for smart and efficient llm inference serving, 2025
2025
-
[63]
InThirty-seventh Conference on Neural Information Processing Systems(2023)
Zheng, Z., Ren, X., Xue, F., Luo, Y., Jiang, X., and You, Y.Response length perception and sequence scheduling: An LLM-empowered LLM inference pipeline. InThirty-seventh Conference on Neural Information Processing Systems(2023)
2023
-
[64]
Zhong, Y., Liu, S., Chen, J., Hu, J., Zhu, Y., Liu, X., Jin, X., and Zhang, H.Distserve: Disaggregating prefill and decoding for goodput- optimized large language model serving, 2024
2024
-
[65]
Zhu, K., Shi, H., Xu, L., Shan, J., Krishnamurthy, A., Kasikci, B., and Xie, L.Polyserve: Efficient multi-slo serving at scale, 2025. 14
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.