ACEsplat: Accelerated 3D Gaussian Scene Regression via RGB and Poses Only
Pith reviewed 2026-06-26 11:57 UTC · model grok-4.3
The pith
ACEsplat reconstructs 3D Gaussian scenes from RGB images and camera poses alone without external geometric priors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
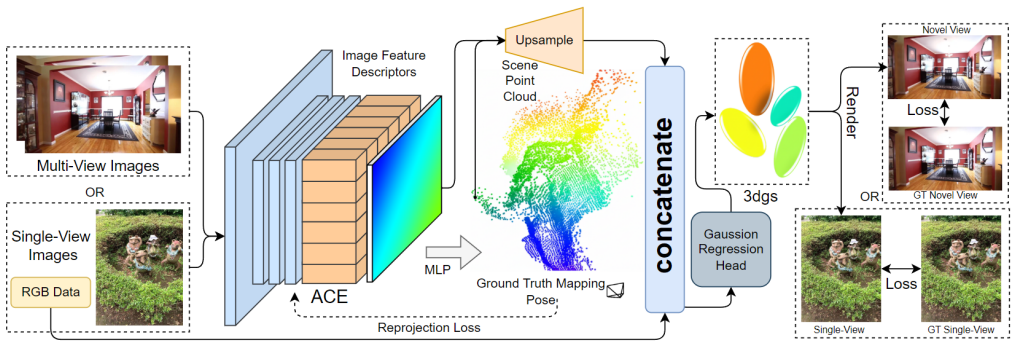
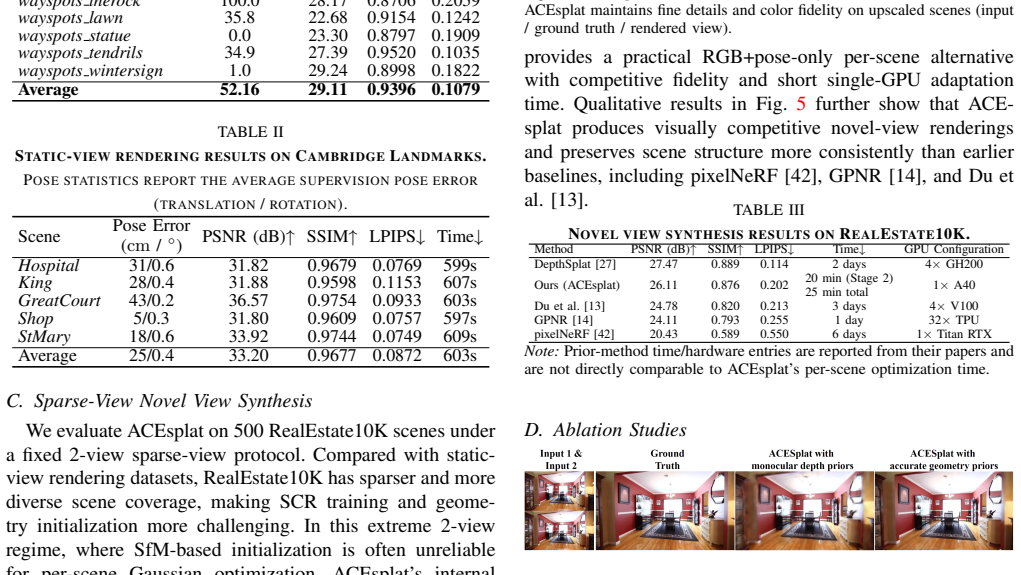
ACEsplat uses a two-stage pipeline where a self-supervised scene coordinate regression module first builds an internal geometry prior from RGB images and poses in 4-5 minutes, then fuses these with a lightweight Gaussian initialization head for per-scene 3DGS optimization, achieving 29.11 dB PSNR on Wayspots with real-time SLAM poses and 33.20 dB on Cambridge Landmarks with SfM-refined poses while completing the full reconstruction in 15-25 minutes without external 3D priors.
What carries the argument
The two-stage pipeline of self-supervised scene coordinate regression that supplies geometry priors to a lightweight Gaussian initialization head before 3D Gaussian Splatting optimization.
Load-bearing premise
The self-supervised scene coordinate regression produces an internal geometry prior accurate enough to support effective Gaussian initialization and optimization.
What would settle it
Evaluating the full pipeline on a held-out scene collection where the scene coordinate regression outputs show average errors exceeding 10 cm and checking whether final PSNR drops below 25 dB would test the central claim.
Figures






read the original abstract
Per-scene 3D Gaussian Splatting (3DGS) enables high-fidelity rendering, but practical robotic and AR scene capture pipelines often depend on external geometric initialization (e.g., SfM point clouds or depth estimates), which can be slow and brittle in on-site deployment. We present ACEsplat, a fast per-scene optimization framework that reconstructs 3D Gaussian representations from RGB images and camera poses only, without requiring external 3D priors (e.g., precomputed SfM models or supervised depth maps). ACEsplat uses a two-stage pipeline: (1) a self-supervised scene coordinate regression (SCR) module builds an internal geometry prior within 4--5 minutes; (2) SCR features and coordinate priors are fused by a lightweight Gaussian initialization head, followed by per-scene 3DGS optimization. On static-view rendering, ACEsplat achieves 29.11 dB PSNR on Wayspots with real-time SLAM poses and 33.20 dB on Cambridge Landmarks with SfM-refined poses. On RealEstate10K sparse-view novel view synthesis, it achieves competitive image fidelity under a challenging 2-view setting. ACEsplat completes scene-specific SCR mapping and 3DGS reconstruction within 15--25 minutes on a single GPU, making it a practical RGB+pose-only solution for rapid scene setup in robotics and mixed-reality applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents ACEsplat, a two-stage per-scene optimization framework for 3D Gaussian Splatting (3DGS) reconstruction from RGB images and camera poses only, without external 3D priors. Stage 1 employs a self-supervised scene coordinate regression (SCR) module to build an internal geometry prior in 4-5 minutes. Stage 2 fuses SCR features and coordinate priors via a lightweight Gaussian initialization head, followed by 3DGS optimization. Reported results include 29.11 dB PSNR on Wayspots (real-time SLAM poses), 33.20 dB on Cambridge Landmarks (SfM-refined poses), competitive performance on RealEstate10K under 2-view settings, and total runtime of 15-25 minutes on a single GPU.
Significance. If the central results hold, the work offers a practical advance for robotic and AR scene capture by removing dependence on slow or brittle external geometric initializations such as SfM point clouds or supervised depth. The concrete PSNR and timing numbers on standard benchmarks, combined with the RGB+pose-only constraint, position the method as a potential enabler for rapid on-site deployment.
minor comments (2)
- Abstract: the reported PSNR figures (29.11 dB, 33.20 dB) would be strengthened by inclusion of per-scene standard deviations or error bars to convey variability.
- The manuscript should provide explicit details on the self-supervised loss terms and training schedule of the SCR module (e.g., in the methods section) to support reproducibility of the geometry prior.
Simulated Author's Rebuttal
We sincerely thank the referee for their careful review and for recommending minor revision. We appreciate the positive evaluation of the significance of our work on ACEsplat for practical robotic and AR applications. The referee summary accurately describes the method and results. Since the report does not list any major comments, we have no specific rebuttals to provide. We will incorporate any minor comments into the revised manuscript.
Circularity Check
No significant circularity detected
full rationale
The paper presents a two-stage pipeline: self-supervised SCR from RGB+poses to build an internal geometry prior, followed by fusion into a Gaussian initialization head and 3DGS optimization. No equations, fitted parameters, or self-citations are quoted that reduce any claimed prediction or result to its inputs by construction. Reported PSNR and timing figures are empirical outcomes on external benchmarks (Wayspots, Cambridge Landmarks, RealEstate10K), not forced equivalences. The central claim remains independent of the input data by the paper's own description.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
3d gaussian splatting for real-time radiance field rendering
B. Kerbl, G. Kopanas, T. Leimk ¨uhler, and G. Drettakis, “3d gaussian splatting for real-time radiance field rendering.”ACM Trans. Graph., vol. 42, no. 4, pp. 139–1, 2023
2023
-
[2]
A survey of augmented reality,
R. T. Azuma, “A survey of augmented reality,”Presence: teleoperators & virtual environments, vol. 6, no. 4, pp. 355–385, 1997
1997
-
[3]
Jerald,The VR book: Human-centered design for virtual reality
J. Jerald,The VR book: Human-centered design for virtual reality. Morgan & Claypool, 2015
2015
-
[4]
Augmented reality: An overview and five directions for ar in education,
S. C.-Y . Yuen, G. Yaoyuneyong, and E. Johnson, “Augmented reality: An overview and five directions for ar in education,”Journal of Educational Technology Development and Exchange (JETDE), vol. 4, no. 1, p. 11, 2011
2011
-
[5]
Sharednerf: Leveraging photorealistic and view-dependent rendering for real-time and remote collaboration,
M. Sakashita, B. Thoravi Kumaravel, N. Marquardt, and A. D. Wilson, “Sharednerf: Leveraging photorealistic and view-dependent rendering for real-time and remote collaboration,” inProceedings of the 2024 CHI Conference on Human Factors in Computing Systems, 2024, pp. 1–14
2024
-
[6]
The impact of virtual, augmented and mixed reality technologies on the customer experi- ence,
C. Flavi ´an, S. Ib ´a˜nez-S´anchez, and C. Or ´us, “The impact of virtual, augmented and mixed reality technologies on the customer experi- ence,”Journal of business research, vol. 100, pp. 547–560, 2019
2019
-
[7]
Online virtual exhibitions: Concepts and design consider- ations,
S. Foo, “Online virtual exhibitions: Concepts and design consider- ations,”DESIDOC Journal of Library & Information Technology, vol. 28, no. 4, pp. 22–34, 2008
2008
-
[8]
Structure-from-motion revisited,
J. L. Schonberger and J.-M. Frahm, “Structure-from-motion revisited,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 4104–4113
2016
-
[9]
Photo tourism: exploring photo collections in 3d,
N. Snavely, S. M. Seitz, and R. Szeliski, “Photo tourism: exploring photo collections in 3d,” inACM siggraph 2006 papers. ACM, 2006, pp. 835–846
2006
-
[10]
Visualsfm: A visual structure from motion system,
C. Wuet al., “Visualsfm: A visual structure from motion system,” Proceedings of the 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops), 2011
2011
-
[11]
Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images,
Y . Chen, H. Xu, C. Zheng, B. Zhuang, M. Pollefeys, A. Geiger, T.-J. Cham, and J. Cai, “Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 370–386
2024
-
[12]
pixelsplat: 3d gaussian splats from image pairs for scalable generalizable 3d recon- struction,
D. Charatan, S. L. Li, A. Tagliasacchi, and V . Sitzmann, “pixelsplat: 3d gaussian splats from image pairs for scalable generalizable 3d recon- struction,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 19 457–19 467
2024
-
[13]
Learning to render novel views from wide-baseline stereo pairs,
Y . Du, C. Smith, A. Tewari, and V . Sitzmann, “Learning to render novel views from wide-baseline stereo pairs,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 4970–4980
2023
-
[14]
Generalizable patch- based neural rendering,
M. Suhail, C. Esteves, L. Sigal, and A. Makadia, “Generalizable patch- based neural rendering,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 156–174
2022
-
[15]
Accelerated coordi- nate encoding: Learning to relocalize in minutes using rgb and poses,
E. Brachmann, T. Cavallari, and V . A. Prisacariu, “Accelerated coordi- nate encoding: Learning to relocalize in minutes using rgb and poses,” inCVPR, 2023
2023
-
[16]
Map-free visual relocalization: Metric pose relative to a single image,
E. Arnold, J. Wynn, S. Vicente, G. Garcia-Hernando, ´A. Monszpart, V . A. Prisacariu, D. Turmukhambetov, and E. Brachmann, “Map-free visual relocalization: Metric pose relative to a single image,” inECCV, 2022
2022
-
[17]
Posenet: A convolutional network for real-time 6-dof camera relocalization,
A. Kendall, M. Grimes, and R. Cipolla, “Posenet: A convolutional network for real-time 6-dof camera relocalization,” inProceedings of the IEEE international conference on computer vision, 2015, pp. 2938–2946
2015
-
[18]
Stereo magnification: Learning view synthesis using multiplane images,
T. Zhou, R. Tucker, J. Flynn, G. Fyffe, and N. Snavely, “Stereo magnification: Learning view synthesis using multiplane images,” arXiv preprint arXiv:1805.09817, 2018
Pith/arXiv arXiv 2018
-
[19]
Pointnet: Deep learning on point sets for 3d classification and segmentation,
C. R. Qi, H. Su, K. Mo, and L. J. Guibas, “Pointnet: Deep learning on point sets for 3d classification and segmentation,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 652–660
2017
-
[20]
Dust3r: Geometric 3d vision made easy,
S. Wang, V . Leroy, Y . Cabon, B. Chidlovskii, and J. Revaud, “Dust3r: Geometric 3d vision made easy,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 20 697–20 709
2024
-
[21]
Vggt: Visual geometry grounded transformer,
J. Wang, M. Chen, N. Karaev, A. Vedaldi, C. Rupprecht, and D. Novotny, “Vggt: Visual geometry grounded transformer,” inPro- ceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 5294–5306
2025
-
[22]
Scene coordinate regression forests for camera relocalization in rgb-d images,
J. Shotton, B. Glocker, C. Zach, S. Izadi, A. Criminisi, and A. Fitzgib- bon, “Scene coordinate regression forests for camera relocalization in rgb-d images,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2013, pp. 2930–2937
2013
-
[23]
Dsac-differentiable ransac for camera localization,
E. Brachmann, A. Krull, S. Nowozin, J. Shotton, F. Michel, S. Gumhold, and C. Rother, “Dsac-differentiable ransac for camera localization,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 6684–6692
2017
-
[24]
Visual camera re-localization from rgb and rgb-d images using dsac,
E. Brachmann and C. Rother, “Visual camera re-localization from rgb and rgb-d images using dsac,”IEEE transactions on pattern analysis and machine intelligence, vol. 44, no. 9, pp. 5847–5865, 2021
2021
-
[25]
Zoedepth: Zero-shot transfer by combining relative and metric depth,
S. F. Bhat, R. Birkl, D. Wofk, P. Wonka, and M. M ¨uller, “Zoedepth: Zero-shot transfer by combining relative and metric depth,”arXiv preprint arXiv:2302.12288, 2023
Pith/arXiv arXiv 2023
-
[26]
Depth anything: Unleashing the power of large-scale unlabeled data,
L. Yang, B. Kang, Z. Huang, X. Xu, J. Feng, and H. Zhao, “Depth anything: Unleashing the power of large-scale unlabeled data,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 10 371–10 381
2024
-
[27]
Depthsplat: Connecting gaussian splatting and depth,
A. Geiger, M. Pollefeys, D. Barath, H. Blum, F. Wang, S. Peng, and H. Xu, “Depthsplat: Connecting gaussian splatting and depth,” 2024
2024
-
[28]
Lgm: Large multi-view gaussian model for high-resolution 3d content creation,
J. Tang, Z. Chen, X. Chen, T. Wang, G. Zeng, and Z. Liu, “Lgm: Large multi-view gaussian model for high-resolution 3d content creation,” in European Conference on Computer Vision. Springer, 2024, pp. 1–18
2024
-
[29]
Grm: Large gaussian reconstruction model for efficient 3d reconstruction and generation,
Y . Xu, Z. Shi, W. Yifan, H. Chen, C. Yang, S. Peng, Y . Shen, and G. Wetzstein, “Grm: Large gaussian reconstruction model for efficient 3d reconstruction and generation,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 1–20
2024
-
[30]
Gs-lrm: Large reconstruction model for 3d gaussian splatting,
K. Zhang, S. Bi, H. Tan, Y . Xiangli, N. Zhao, K. Sunkavalli, and Z. Xu, “Gs-lrm: Large reconstruction model for 3d gaussian splatting,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 1– 19
2024
-
[31]
Colmap-free 3d gaussian splatting,
Y . Fu, S. Liu, A. Kulkarni, J. Kautz, A. A. Efros, and X. Wang, “Colmap-free 3d gaussian splatting,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[32]
No pose, no problem: Surprisingly simple 3d gaussian splats from sparse unposed images,
B. Ye, S. Liu, H. Xu, X. Li, M. Pollefeys, M.-H. Yang, and S. Peng, “No pose, no problem: Surprisingly simple 3d gaussian splats from sparse unposed images,” inInternational Conference on Learning Representations (ICLR), 2025
2025
-
[33]
U-net: Convolutional networks for biomedical image segmentation,
O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” inMedical image computing and computer-assisted intervention–MICCAI 2015: 18th international conference, Munich, Germany, October 5-9, 2015, pro- ceedings, part III 18. Springer, 2015, pp. 234–241
2015
-
[34]
Feature pyramid networks for object detection,
T.-Y . Lin, P. Doll´ar, R. Girshick, K. He, B. Hariharan, and S. Belongie, “Feature pyramid networks for object detection,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 2117–2125
2017
-
[35]
Pixel transposed convolutional networks,
H. Gao, H. Yuan, Z. Wang, and S. Ji, “Pixel transposed convolutional networks,”IEEE transactions on pattern analysis and machine intel- ligence, vol. 42, no. 5, pp. 1218–1227, 2019
2019
-
[36]
Checkerboard artifacts free convolutional neural networks,
Y . Sugawara, S. Shiota, and H. Kiya, “Checkerboard artifacts free convolutional neural networks,”APSIPA Transactions on Signal and Information Processing, vol. 8, p. e9, 2019
2019
-
[37]
Automatic differen- tiation in pytorch,
A. Paszke, S. Gross, S. Chintala, G. Chanan, E. Yang, Z. DeVito, Z. Lin, A. Desmaison, L. Antiga, and A. Lerer, “Automatic differen- tiation in pytorch,” 2017
2017
-
[38]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” arXiv preprint arXiv:1711.05101, 2017
Pith/arXiv arXiv 2017
-
[39]
Arkit and arcore in serve to augmented reality,
Z. Oufqir, A. El Abderrahmani, and K. Satori, “Arkit and arcore in serve to augmented reality,” in2020 international conference on intelligent systems and computer vision (ISCV). IEEE, 2020, pp. 1–7
2020
-
[40]
Image quality assessment: from error visibility to structural similarity,
Z. Wang, A. Bovik, H. Sheikh, and E. Simoncelli, “Image quality assessment: from error visibility to structural similarity,”IEEE Trans- actions on Image Processing, vol. 13, no. 4, pp. 600–612, 2004
2004
-
[41]
The unreasonable effectiveness of deep features as a perceptual metric,
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The unreasonable effectiveness of deep features as a perceptual metric,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 586–595
2018
-
[42]
pixelnerf: Neural radiance fields from one or few images,
A. Yu, V . Ye, M. Tancik, and A. Kanazawa, “pixelnerf: Neural radiance fields from one or few images,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 4578–4587
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.