Attacking UTMOS: Probing the Robustness of a Speech Quality Assessment Model
Pith reviewed 2026-07-01 04:06 UTC · model grok-4.3
The pith
UTMOS speech quality scores can be preserved even as the actual audio is made to sound worse through targeted input optimization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
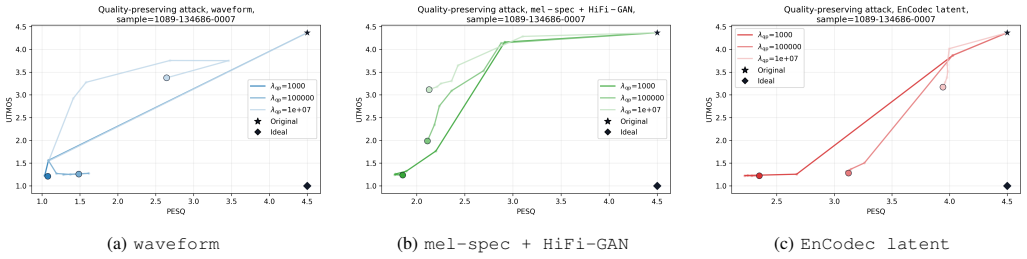
Starting from high-quality speech samples, optimization in the raw waveform, mel spectrogram with HiFi-GAN vocoder, and EnCodec latent space produces inputs where the UTMOS predicted score is decoupled from perceived quality: score-preserving attacks degrade listening quality while keeping the score unchanged, and quality-preserving attacks lower the score while keeping perceived quality unchanged. Score-preserving attacks prove effective across spaces, whereas quality-preserving attacks are more difficult yet achieve the best results in the EnCodec latent space.
What carries the argument
Score-preserving and quality-preserving adversarial optimization performed directly in the raw waveform, mel spectrogram, and EnCodec latent spaces to force divergence between model output and human perception.
If this is right
- Score-preserving attacks reliably degrade perceived quality without altering the UTMOS output.
- Quality-preserving attacks succeed more readily when the optimization occurs inside the EnCodec latent space than in waveform or mel-spectrogram spaces.
- The observed decoupling identifies concrete failure modes in how UTMOS maps audio to quality scores.
- Robustness testing should become standard practice for any new DNN-based speech quality assessment metric.
Where Pith is reading between the lines
- If UTMOS is used inside training objectives or automatic evaluation pipelines, an adversary could generate low-quality outputs that still receive high reported scores.
- Similar vulnerabilities may exist in other learned SQA models that were trained without explicit adversarial robustness constraints.
- Metrics that incorporate explicit checks against EnCodec-space perturbations could be more resistant to the attacks shown here.
Load-bearing premise
The optimization truly produces inputs where human listeners and the model disagree on quality, rather than the results being artifacts of the attack procedure, the listening test design, or the chosen samples.
What would settle it
A controlled listening test on a new set of samples in which independent raters consistently fail to report the claimed quality change (worse for score-preserving cases or unchanged for quality-preserving cases) while UTMOS reports the expected score behavior.
Figures


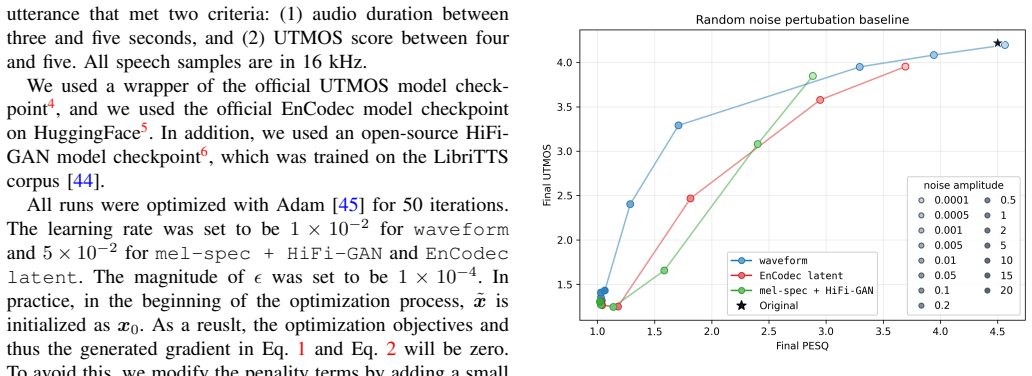
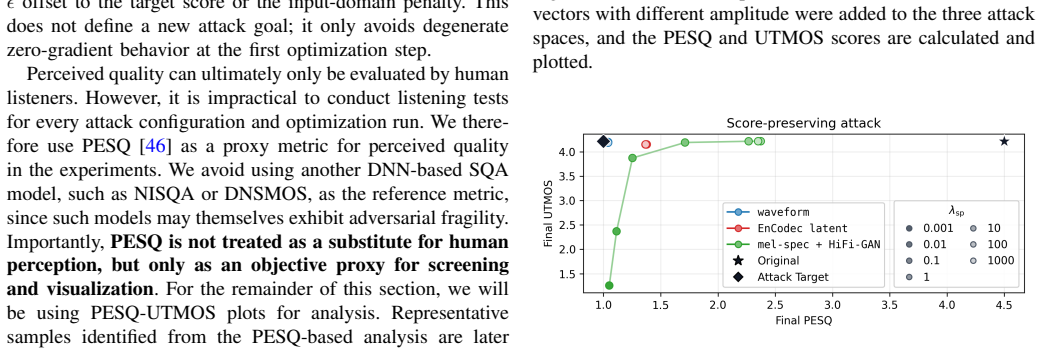
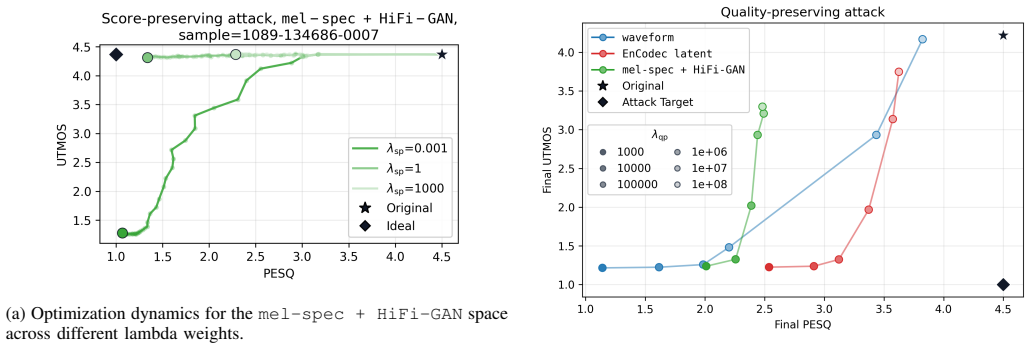
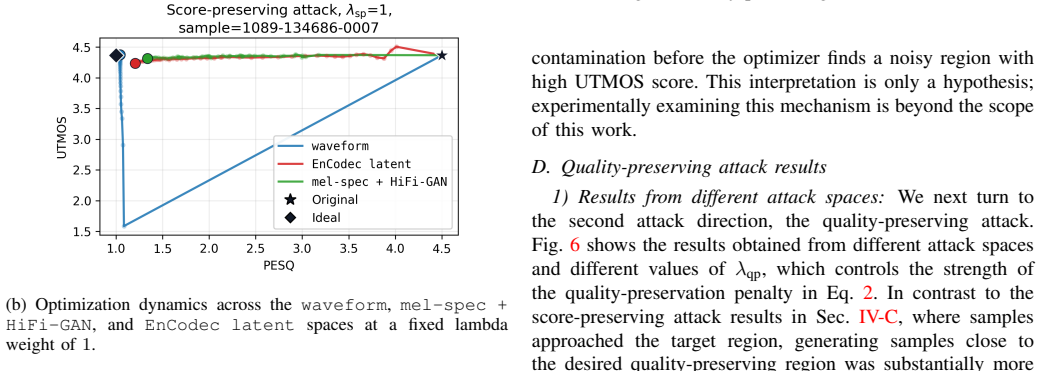
read the original abstract
UTMOS has become one of the most commonly used deep neural network-based speech quality assessment (SQA) metrics in speech processing research. In this paper, we attack UTMOS to probe its robustness. Starting from high-quality speech samples, we optimize the input in two directions: a score-preserving attack, which degrades perceived quality while maintaining the predicted score, and a quality-preserving attack, which lowers the predicted score while maintaining perceived quality. We consider three input spaces: raw waveform, mel spectrogram with a HiFi-GAN vocoder, and the latent space of EnCodec, a neural audio codec. Experimental results show that score-preserving attacks are effective against UTMOS. Although perfect quality-preserving attacks are more difficult, optimization in the EnCodec latent space provides the best chance of success. These results reveal failure modes of UTMOS and highlight the importance of robustness analysis for DNN-based SQA metrics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript attacks UTMOS, a widely used DNN-based speech quality assessment metric, via score-preserving attacks (degrade perceived quality while holding model score fixed) and quality-preserving attacks (lower model score while holding perceived quality fixed). Optimizations are performed in three input spaces—raw waveform, mel spectrogram + HiFi-GAN vocoder, and EnCodec latent space—with the conclusion that score-preserving attacks succeed while quality-preserving attacks are harder but most feasible in the EnCodec space, exposing failure modes in UTMOS.
Significance. If the empirical results hold with adequate controls, the work would be significant for the speech-processing community: it supplies concrete evidence that a popular SQA model can be fooled in both directions and thereby motivates routine robustness testing of DNN-based metrics. The multi-space comparison is a methodological strength.
major comments (2)
- [Abstract / §4 (Experiments)] The abstract states that the attacks succeeded but supplies no quantitative results (e.g., mean score deltas, perceptual MOS differences, success rates, or statistical tests). Without these numbers the central claim that UTMOS exhibits failure modes cannot be evaluated; the experimental section must report effect sizes, baselines, and listener-study details.
- [§4 (Experiments)] The weakest link is the assumption that the optimized examples truly decouple human perception from the model output rather than reflecting limitations of the attack implementation or the chosen test set. The manuscript must describe the exact perceptual evaluation protocol (listener pool size, rating scale, statistical power) and show that perceived quality was verifiably altered or preserved.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify how to better substantiate the central claims. We address each major comment below and will revise the manuscript to incorporate the requested details.
read point-by-point responses
-
Referee: [Abstract / §4 (Experiments)] The abstract states that the attacks succeeded but supplies no quantitative results (e.g., mean score deltas, perceptual MOS differences, success rates, or statistical tests). Without these numbers the central claim that UTMOS exhibits failure modes cannot be evaluated; the experimental section must report effect sizes, baselines, and listener-study details.
Authors: We agree that quantitative results are necessary to evaluate the claims. The revised abstract will report key effect sizes (e.g., mean UTMOS score deltas and perceptual MOS differences), success rates across the three input spaces, and statistical significance. Section 4 will be expanded with tables showing these metrics, baseline comparisons (e.g., unoptimized samples and random perturbations), and listener-study outcomes to demonstrate the decoupling. revision: yes
-
Referee: [§4 (Experiments)] The weakest link is the assumption that the optimized examples truly decouple human perception from the model output rather than reflecting limitations of the attack implementation or the chosen test set. The manuscript must describe the exact perceptual evaluation protocol (listener pool size, rating scale, statistical power) and show that perceived quality was verifiably altered or preserved.
Authors: We acknowledge that a full description of the perceptual protocol is required. The revised §4 will specify the listener pool size, rating scale (standard 5-point MOS), number of ratings per sample, and statistical tests (including power analysis and confidence intervals). We will also present the measured MOS differences confirming that perceived quality was degraded in score-preserving attacks and held constant in quality-preserving attacks, thereby addressing potential concerns about attack limitations or test-set artifacts. revision: yes
Circularity Check
No significant circularity
full rationale
This is an empirical adversarial attack study on UTMOS. The abstract and described setup involve optimization experiments across input spaces (waveform, mel spectrogram, EnCodec latent) with reported success rates for score-preserving and quality-preserving attacks. No derivations, equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central claims rest on experimental outcomes rather than any reduction to inputs by construction. This matches the default expectation for non-circular empirical work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Speech Quality Estimation: Models and Trends,
S. M ¨oller, W.-Y . Chan, N. C ˆot´e, T. H. Falk, A. Raake, and M. W¨altermann, “Speech Quality Estimation: Models and Trends,”IEEE Signal Processing Magazine, vol. 28, no. 6, pp. 18–28, 2011
2011
-
[2]
A review on subjective and objective evaluation of synthetic speech,
E. Cooper, W.-C. Huang, Y . Tsao, H.-M. Wang, T. Toda, and J. Ya- magishi, “A review on subjective and objective evaluation of synthetic speech,”Acoustical Science and Technology, vol. 45, no. 4, pp. 161–183, 2024
2024
-
[3]
MOSNet: Deep Learning-Based Objective Assessment for V oice Conversion,
C.-C. Lo, S.-W. Fu, W.-C. Huang, X. Wang, J. Yamagishi, Y . Tsao, and H.-M. Wang, “MOSNet: Deep Learning-Based Objective Assessment for V oice Conversion,” inProc. Interspeech, 2019, pp. 1541–1545
2019
-
[4]
NISQA: A Deep CNN-Self-Attention Model for Multidimensional Speech Quality Pre- diction with Crowdsourced Datasets,
G. Mittag, B. Naderi, A. Chehadi, and S. M ¨oller, “NISQA: A Deep CNN-Self-Attention Model for Multidimensional Speech Quality Pre- diction with Crowdsourced Datasets,” inProc. Interspeech, 2021, pp. 2127–2131
2021
-
[5]
DNSMOS: A non-intrusive perceptual objective speech quality metric to evaluate noise suppressors,
C. K. Reddy, V . Gopal, and R. Cutler, “DNSMOS: A non-intrusive perceptual objective speech quality metric to evaluate noise suppressors,” inProc. ICASSP, 2021, pp. 6493–6497
2021
-
[6]
Generalization ability of MOS prediction networks,
E. Cooper, W.-C. Huang, T. Toda, and J. Yamagishi, “Generalization ability of MOS prediction networks,” inProc. ICASSP, 2022, pp. 8442– 8446
2022
-
[7]
UTMOS: UTokyo-SaruLab System for V oiceMOS Chal- lenge 2022,
T. Saeki, D. Xin, W. Nakata, T. Koriyama, S. Takamichi, and H. Saruwatari, “UTMOS: UTokyo-SaruLab System for V oiceMOS Chal- lenge 2022,” inProc. Interspeech, 2022, pp. 4521–4525
2022
-
[8]
The V oiceMOS Challenge 2022,
W.-C. Huang, E. Cooper, Y . Tsao, H.-M. Wang, T. Toda, and J. Yamag- ishi, “The V oiceMOS Challenge 2022,” inProc. Interspeech, 2022, pp. 4536–4540
2022
-
[9]
How do voices from past speech synthesis challenges compare today?
E. Cooper and J. Yamagishi, “How do voices from past speech synthesis challenges compare today?” inProc. 11th ISCA Speech Synthesis Workshop (SSW 11), 2021, pp. 183–188
2021
-
[10]
NaturalSpeech 3: Zero-shot speech synthesis with factorized codec and diffusion models,
Z. Ju, Y . Wang, K. Shen, X. Tan, D. Xin, D. Yang, E. Liu, Y . Leng, K. Song, S. Tang, Z. Wu, T. Qin, X. Li, W. Ye, S. Zhang, J. Bian, L. He, J. Li, and S. Zhao, “NaturalSpeech 3: Zero-shot speech synthesis with factorized codec and diffusion models,” inProc. ICML, 21–27 Jul 2024, pp. 22 605–22 623
2024
-
[11]
CMGAN: Conformer-Based Metric- GAN for Monaural Speech Enhancement,
S. Abdulatif, R. Cao, and B. Yang, “CMGAN: Conformer-Based Metric- GAN for Monaural Speech Enhancement,”IEEE/ACM TASLP, vol. 32, pp. 2477–2493, 2024
2024
-
[12]
WavTokenizer: an Efficient Acoustic Discrete Codec Tokenizer for Audio Language Modeling,
S. Ji, Z. Jiang, W. Wang, Y . Chen, M. Fang, J. Zuo, Q. Yang, X. Cheng, Z. Wang, R. Li, Z. Zhang, X. Yang, R. Huang, Y . Jiang, Q. Chen, S. Zheng, and Z. Zhao, “WavTokenizer: an Efficient Acoustic Discrete Codec Tokenizer for Audio Language Modeling,” inICLR, 2025
2025
-
[13]
LLaMA- Omni: Seamless Speech Interaction with Large Language Models,
Q. Fang, S. Guo, Y . Zhou, Z. Ma, S. Zhang, and Y . Feng, “LLaMA- Omni: Seamless Speech Interaction with Large Language Models,” in Proc. ICLR, Y . Yue, A. Garg, N. Peng, F. Sha, and R. Yu, Eds., 2025, pp. 57 607–57 624
2025
-
[14]
Learning to Maximize Speech Quality Directly Using MOS Prediction for Neural Text-to-Speech,
Y . Choi, Y . Jung, Y . Suh, and H. Kim, “Learning to Maximize Speech Quality Directly Using MOS Prediction for Neural Text-to-Speech,” IEEE Access, vol. 10, pp. 52 621–52 629, 2022
2022
-
[15]
Preference Alignment Improves Language Model-Based TTS,
J. Tian, C. Zhang, J. Shi, H. Zhang, J. Yu, S. Watanabe, and D. Yu, “Preference Alignment Improves Language Model-Based TTS,” inProc. ICASSP, 2025, pp. 1–5
2025
-
[16]
Improv- ing Speech Enhancement with Multi-Metric Supervision from Learned Quality Assessment,
W. Wang, W. Zhang, C. Li, J. Shi, S. Watanabe, and Y . Qian, “Improv- ing Speech Enhancement with Multi-Metric Supervision from Learned Quality Assessment,” inProc. ASRU, 2025, pp. 1–8
2025
-
[17]
The V oiceMOS Challenge 2023: Zero-Shot Subjective Speech Quality Prediction for Multiple Domains,
E. Cooper, W.-C. Huang, Y . Tsao, H.-M. Wang, T. Toda, and J. Yam- agishi, “The V oiceMOS Challenge 2023: Zero-Shot Subjective Speech Quality Prediction for Multiple Domains,” inProc. ASRU, 2023, pp. 1–7
2023
-
[18]
MOS-Bench: Benchmarking Generalization Abilities of Subjective Speech Quality Assessment Mod- els,
W.-C. Huang, E. Cooper, and T. Toda, “MOS-Bench: Benchmarking Generalization Abilities of Subjective Speech Quality Assessment Mod- els,”IEEE Transactions on Audio, Speech and Language Processing, vol. 34, pp. 2385–2397, 2026
2026
-
[19]
Good Practices for Evaluation of Synthesized Speech,
E. Cooper, S. L. Maguer, E. Klabbers, and J. Yamagishi, “Good Practices for Evaluation of Synthesized Speech,”arXiv preprint arXiv:2503.03250, 2025
-
[20]
Intriguing Properties of Neural Networks,
C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. J. Goodfellow, and R. Fergus, “Intriguing Properties of Neural Networks,” inProc. ICLR, 2014
2014
-
[21]
High fidelity neural audio compression,
A. D ´efossez, J. Copet, G. Synnaeve, and Y . Adi, “High fidelity neural audio compression,”TMLR, 2023
2023
-
[22]
HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis,
J. Kong, J. Kim, and J. Bae, “HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis,” inProc. NeurIPS, vol. 33, 2020, pp. 17 022–17 033
2020
-
[23]
Explaining and Harnessing Adversarial Examples,
I. J. Goodfellow, J. Shlens, and C. Szegedy, “Explaining and Harnessing Adversarial Examples,” inProc. ICLR, 2015
2015
-
[24]
Adversarial examples in the physical world
A. Kurakin, I. Goodfellow, and S. Bengio, “Adversarial Examples in the Physical World,”arXiv preprint arXiv:1607.02533, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[25]
DeepFool: A Simple and Accurate Method to Fool Deep Neural Networks,
S.-M. Moosavi-Dezfooli, A. Fawzi, and P. Frossard, “DeepFool: A Simple and Accurate Method to Fool Deep Neural Networks,” inProc. CVPR, June 2016
2016
-
[26]
The Limitations of Deep Learning in Adversarial Set- tings,
N. Papernot, P. McDaniel, S. Jha, M. Fredrikson, Z. B. Celik, and A. Swami, “The Limitations of Deep Learning in Adversarial Set- tings,” inProc. IEEE European Symposium on Security and Privacy (EuroS&P), 2016, pp. 372–387
2016
-
[27]
Towards Deep Learning Models Resistant to Adversarial Attacks,
A. Madry, A. Makelov, L. Schmidt, D. Tsipras, and A. Vladu, “Towards Deep Learning Models Resistant to Adversarial Attacks,” inProc. ICLR, 2018
2018
-
[28]
Towards Evaluating the Robustness of Neural Networks,
N. Carlini and D. Wagner, “Towards Evaluating the Robustness of Neural Networks,” inProc. IEEE Symposium on Security and Privacy, 2017, pp. 39–57
2017
-
[29]
Hidden V oice Commands,
N. Carlini, P. Mishra, T. Vaidya, Y . Zhang, M. Sherr, C. Shields, D. Wagner, and W. Zhou, “Hidden V oice Commands,” inProc. 25th USENIX Security Symposium (USENIX Security), Austin, TX, Aug. 2016, pp. 513–530
2016
-
[30]
DolphinAt- tack: Inaudible V oice Commands,
G. Zhang, C. Yan, X. Ji, T. Zhang, T. Zhang, and W. Xu, “DolphinAt- tack: Inaudible V oice Commands,” inProc. ACM SIGSAC Conference on Computer and Communications Security, 2017, p. 103–117
2017
-
[31]
Practical Hidden V oice Attacks against Speech and Speaker Recognition Systems,
H. Abdullah, W. Garcia, C. Peeters, P. Traynor, K. R. Butler, and J. Wilson, “Practical Hidden V oice Attacks against Speech and Speaker Recognition Systems,” inNetwork and Distributed Systems Security (NDSS) Symposium, 2019
2019
-
[32]
ASVspoof 2019: Future Horizons in Spoofed and Fake Audio Detection,
M. Todisco, X. Wang, V . Vestman, M. Sahidullah, H. Delgado, A. Nautsch, J. Yamagishi, N. Evans, T. H. Kinnunen, and K. A. Lee, “ASVspoof 2019: Future Horizons in Spoofed and Fake Audio Detection,” inProc. Interspeech, 2019, pp. 1008–1012
2019
-
[33]
ASVspoof 2019: A large-scale public database of synthesized, con- verted and replayed speech,
X. Wang, J. Yamagishi, M. Todisco, H. Delgado, A. Nautsch, N. Evans, M. Sahidullah, V . Vestman, T. Kinnunen, K. A. Lee, L. Juvela, P. Alku, Y .-H. Peng, H.-T. Hwang, Y . Tsao, H.-M. Wang, S. L. Maguer, M. Becker, F. Henderson, R. Clark, Y . Zhang, Q. Wang, Y . Jia, K. Onuma, K. Mushika, T. Kaneda, Y . Jiang, L.-J. Liu, Y .-C. Wu, W.- C. Huang, T. Toda, K...
2019
-
[34]
Audio adversarial examples: Targeted attacks on speech-to-text,
N. Carlini and D. Wagner, “Audio adversarial examples: Targeted attacks on speech-to-text,” inProc. IEEE Security and Privacy Workshops (SPW), 2018, pp. 1–7
2018
-
[35]
Impercep- tible, Robust, and Targeted Adversarial Examples for Automatic Speech Recognition,
Y . Qin, N. Carlini, G. Cottrell, I. Goodfellow, and C. Raffel, “Impercep- tible, Robust, and Targeted Adversarial Examples for Automatic Speech Recognition,” inProc. ICML, 09–15 Jun 2019, pp. 5231–5240
2019
-
[36]
Robust audio adversarial example for a physical attack,
H. Yakura and J. Sakuma, “Robust audio adversarial example for a physical attack,” inProc. IJCAI, 7 2019, pp. 5334–5341
2019
-
[37]
Fooling End-To-End Speaker Verification With Adversarial Examples,
F. Kreuk, Y . Adi, M. Cisse, and J. Keshet, “Fooling End-To-End Speaker Verification With Adversarial Examples,” inProc. ICASSP, 2018, pp. 1962–1966
2018
-
[38]
Who is Real Bob? Adversarial Attacks on Speaker Recognition Systems,
G. Chen, S. Chenb, L. Fan, X. Du, Z. Zhao, F. Song, and Y . Liu, “Who is Real Bob? Adversarial Attacks on Speaker Recognition Systems,” in Proc. IEEE Symposium on Security and Privacy (SP), 2021, pp. 694– 711
2021
-
[39]
Matcha- TTS: A Fast TTS Architecture with Conditional Flow Matching,
S. Mehta, R. Tu, J. Beskow, ´E. Sz ´ekely, and G. E. Henter, “Matcha- TTS: A Fast TTS Architecture with Conditional Flow Matching,” in Proc. ICASSP, 2024, pp. 11 341–11 345
2024
-
[40]
XTTS: a Massively Multilingual Zero-Shot Text-to-Speech Model,
E. Casanova, K. Davis, E. G ¨olge, G. G ¨oknar, I. Gulea, L. Hart, A. Aljafari, J. Meyer, R. Morais, S. Olayemi, and J. Weber, “XTTS: a Massively Multilingual Zero-Shot Text-to-Speech Model,” inProc. Interspeech, 2024, pp. 4978–4982
2024
-
[41]
Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers,
S. Chen, C. Wang, Y . Wu, Z. Zhang, L. Zhou, S. Liu, Z. Chen, Y . Liu, H. Wang, J. Li, L. He, S. Zhao, and F. Wei, “Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers,”IEEE TASLP, vol. 33, pp. 705–718, 2025
2025
-
[42]
V oice- Craft: Zero-shot speech editing and text-to-speech in the wild,
P. Peng, P.-Y . Huang, S.-W. Li, A. Mohamed, and D. Harwath, “V oice- Craft: Zero-shot speech editing and text-to-speech in the wild,” inProc. ACL (Volume 1: Long Papers), L.-W. Ku, A. Martins, and V . Srikumar, Eds., Bangkok, Thailand, Aug. 2024, pp. 12 442–12 462
2024
-
[43]
LibriSpeech: An ASR corpus based on public domain audio books,
V . Panayotov, G. Chen, D. Povey, and S. Khudanpur, “LibriSpeech: An ASR corpus based on public domain audio books,” inProc. ICASSP, 2015, pp. 5206–5210
2015
-
[44]
LibriTTS: A Corpus Derived from LibriSpeech for Text- to-Speech,
H. Zen, V . Dang, R. Clark, Y . Zhang, R. J. Weiss, Y . Jia, Z. Chen, and Y . Wu, “LibriTTS: A Corpus Derived from LibriSpeech for Text- to-Speech,” inProc. Interspeech, 2019, pp. 1526–1530
2019
-
[45]
Adam: A Method for Stochastic Optimization,
D. P. Kingma and J. Ba, “Adam: A Method for Stochastic Optimization,” inProc. ICLR, 2015
2015
-
[46]
Perceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs,
A. W. Rix, J. G. Beerends, M. P. Hollier, and A. P. Hekstra, “Perceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs,” inProc. ICASSP, 2001, p. 749–752
2001
-
[47]
UrgentMOS: Unified Multi-Metric and Preference Learning for Robust Speech Quality Assessment,
W. Wang, W. Zhang, C. Li, J. Wang, S. Cornell, M. Sach, K. Saijo, Y . Fu, Z. Ni, B. Hanet al., “UrgentMOS: Unified Multi-Metric and Preference Learning for Robust Speech Quality Assessment,”arXiv preprint arXiv:2601.18438, 2026
-
[48]
Audio Large Language Models Can Be Descriptive Speech Quality Evaluators,
C. Chen, Y . Hu, S. Wang, H. Wang, Z. Chen, C. Zhang, C.-H. H. Yang, and E. Chng, “Audio Large Language Models Can Be Descriptive Speech Quality Evaluators,” inProc. ICLR, 2025
2025
-
[49]
QualiSpeech: A speech quality assessment dataset with natural language reasoning and descriptions,
S. Wang, W. Yu, X. Chen, X. Tian, J. Zhang, L. Lu, Y . Tsao, J. Yamagishi, Y . Wang, and C. Zhang, “QualiSpeech: A speech quality assessment dataset with natural language reasoning and descriptions,” inProc. ACL (Volume 1: Long Papers), Vienna, Austria, Jul. 2025, pp. 23 588–23 609
2025
-
[50]
SpeechLLM-as-Judges: Towards General and Interpretable Speech Quality Evaluation
H. Wang, J. Zhao, Y . Yang, S. Liu, J. Chen, Y . Zhang, S. Zhao, J. Li, J. Zhou, H. Sunet al., “SpeechLLM-as-Judges: Towards Gen- eral and Interpretable Speech Quality Evaluation,”arXiv preprint arXiv:2510.14664, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
Optimization-based Prompt Injection Attack to LLM-as-a-Judge,
J. Shi, Z. Yuan, Y . Liu, Y . Huang, P. Zhou, L. Sun, and N. Z. Gong, “Optimization-based Prompt Injection Attack to LLM-as-a-Judge,” in Proc. ACM SIGSAC Conference on Computer and Communications Security, 2024, p. 660–674
2024
-
[52]
Not What You’ve Signed Up For: Compromising Real-World LLM- Integrated Applications with Indirect Prompt Injection,
K. Greshake, S. Abdelnabi, S. Mishra, C. Endres, T. Holz, and M. Fritz, “Not What You’ve Signed Up For: Compromising Real-World LLM- Integrated Applications with Indirect Prompt Injection,” inProc. ACM Workshop on Artificial Intelligence and Security, 2023, p. 79–90
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.