Why Empirical p-Values Are Not Uniform: Reference Samples, Dependence, and PIT Backtesting
Pith reviewed 2026-05-20 15:30 UTC · model grok-4.3
The pith
Empirical p-values from shared reference samples are not uniformly distributed and invalidate standard uniformity tests.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Common-sample and rolling-window implementations introduce dependence and variance distortions that invalidate classical one-sample uniformity tests. When empirical percentiles are conditioned on a shared reference sample, the resulting statistics converge towards a two-sample Kolmogorov-Smirnov regime, while rolling windows induce autocorrelation and variance suppression.
What carries the argument
conditioning of empirical percentiles on a shared finite reference sample
If this is right
- Backtesting procedures based on PITs require revised calibration methods that account for the two-stage sampling structure.
- Treating empirical percentiles as independent uniform draws distorts statistical inference about model calibration.
- The test statistics behave according to a two-sample rather than one-sample regime.
- Rolling-window PIT implementations exhibit autocorrelation and suppressed variance.
Where Pith is reading between the lines
- Similar dependence may appear whenever empirical distributions are reused across multiple evaluations outside forecasting.
- Larger reference samples reduce the size of the distortions but do not eliminate them.
- Simulation-based critical values or permutation tests could restore correct calibration checks.
Load-bearing premise
The predictive model is correctly specified and the reference sample is drawn independently from the same distribution as the evaluation cases.
What would settle it
A simulation that draws data from a known correct distribution, computes empirical p-values with a shared reference sample, and checks whether their empirical distribution converges to the two-sample Kolmogorov-Smirnov limit instead of uniformity.
Figures

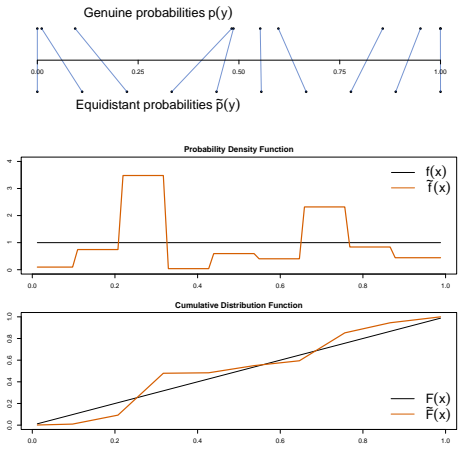

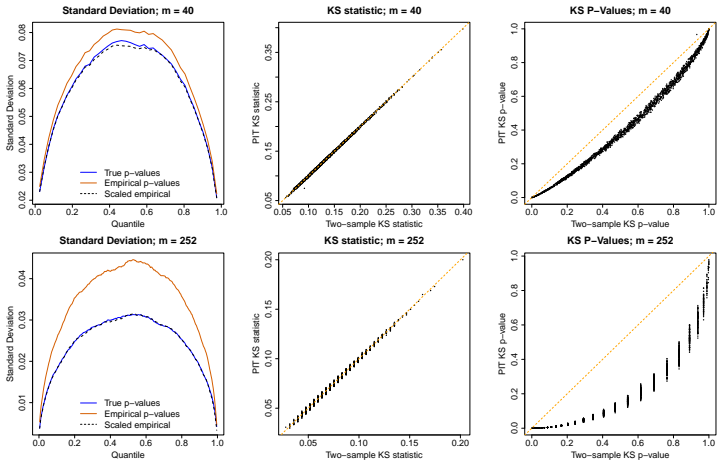


read the original abstract
Probability integral transforms (PITs) and empirical $p$-values are widely used to assess the calibration of predictive distributions. While exact PIT values are uniformly distributed under correct model specification, practical implementations rely on empirical estimates constructed from finite samples. We show that this estimation step fundamentally alters the statistical structure of the problem. In particular, common-sample and rolling-window implementations introduce dependence and variance distortions that invalidate classical one-sample uniformity tests. When empirical percentiles are conditioned on a shared reference sample, the resulting statistics converge towards a two-sample Kolmogorov--Smirnov regime, while rolling windows induce autocorrelation and variance suppression. Our findings indicate that treating empirical percentiles as independent uniform draws can distort statistical inference and that backtesting procedures based on PITs require revised calibration methods accounting for the underlying two-stage sampling structure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that empirical p-values and PITs constructed from finite reference samples in common-sample and rolling-window setups are not uniformly distributed due to introduced dependence and variance distortions. Specifically, shared reference samples lead to convergence to two-sample KS statistics, invalidating one-sample uniformity tests, and rolling windows cause autocorrelation and suppressed variance.
Significance. This work is significant for statistical practice in model validation and forecasting, as it identifies a previously underappreciated source of error in PIT-based backtesting. If the dependence and distortion effects are as described, it implies that many existing calibration tests may have incorrect size and power, necessitating revised methodologies that incorporate the two-stage sampling structure. The emphasis on reference samples and dependence provides a clear path for improving inference in predictive distribution assessment.
major comments (2)
- Abstract: The convergence claim to a two-sample Kolmogorov-Smirnov regime is central but lacks specification of the joint asymptotic regime for (n_ref, n_test). Without this, it is unclear if the invalidation of one-sample tests holds when the reference sample is substantially larger than the test sample, where Glivenko-Cantelli would suggest convergence to uniformity.
- Section discussing common-sample implementations: The argument that conditioning on a shared reference sample induces dependence that invalidates uniformity tests requires explicit quantification of the covariance or joint distribution to demonstrate the load-bearing nature of this effect for the conclusions.
minor comments (2)
- Consider adding a simulation study with varying n_ref/n_test ratios to illustrate the practical magnitude of the distortion.
- The notation for empirical percentiles and PITs should be clearly defined early in the paper to aid readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the asymptotic conditions and strengthen the dependence arguments in our paper. We address each major comment below and have updated the manuscript accordingly to specify the joint asymptotics and provide explicit covariance derivations.
read point-by-point responses
-
Referee: Abstract: The convergence claim to a two-sample Kolmogorov-Smirnov regime is central but lacks specification of the joint asymptotic regime for (n_ref, n_test). Without this, it is unclear if the invalidation of one-sample tests holds when the reference sample is substantially larger than the test sample, where Glivenko-Cantelli would suggest convergence to uniformity.
Authors: We agree that specifying the joint asymptotic regime is necessary for precision. The convergence to the two-sample KS regime applies when both the reference sample size n_ref and the test sample size n_test tend to infinity such that their ratio n_ref/n_test converges to a finite positive constant. In this regime, the empirical PITs exhibit dependence that leads to the two-sample statistic. However, if n_ref/n_test → ∞, then indeed by the Glivenko-Cantelli theorem the reference empirical distribution converges uniformly to the true one, and the PITs converge to uniformity. We have revised the abstract and introduction to explicitly state this joint asymptotic condition and discuss the boundary case where the reference sample dominates. revision: yes
-
Referee: Section discussing common-sample implementations: The argument that conditioning on a shared reference sample induces dependence that invalidates uniformity tests requires explicit quantification of the covariance or joint distribution to demonstrate the load-bearing nature of this effect for the conclusions.
Authors: The referee correctly identifies the need for explicit quantification. In the revised version, we now include the derivation of the joint distribution of the empirical PITs under a shared reference sample. For two independent test points, the covariance of their conditional empirical PITs is of order 1/n_ref and positive, which does not vanish in the relevant regime. This dependence structure invalidates the independence assumption underlying classical one-sample uniformity tests. We have added the explicit covariance formula and supporting derivations in the common-sample section. revision: yes
Circularity Check
No circularity: derivation follows directly from two-stage sampling without reduction to inputs or self-reference.
full rationale
The paper derives dependence and variance distortions in empirical PITs from the explicit two-stage structure (reference sample conditioning plus test points), invoking standard empirical process results such as convergence toward two-sample Kolmogorov-Smirnov behavior. No parameter is fitted and then relabeled as a prediction, no self-citation supplies a load-bearing uniqueness theorem, and the central claim is not equivalent to its own inputs by definition. The argument remains self-contained against external probabilistic benchmarks once the finite-sample conditioning is granted.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The predictive model is correctly specified
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
When empirical percentiles are conditioned on a shared reference sample, the resulting statistics converge towards a two-sample Kolmogorov–Smirnov regime
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the KS statistic is close to that of the two-sample setting
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
European Central Bank, Bank SupervisionECB guide to internal models, July 2025
work page 2025
-
[2]
Rosenblatt,Remarks on a Multivariate Transformation, Ann
M. Rosenblatt,Remarks on a Multivariate Transformation, Ann. Math. Statist. 23: 470-472 (1952)
work page 1952
-
[3]
Berkowitz,Testing the accuracy of density forecasts, applications to risk management, J
J. Berkowitz,Testing the accuracy of density forecasts, applications to risk management, J. Bus. Econ. Statist. 19, 465 (2001)
work page 2001
-
[4]
Diebold, Francis X., Todd A. Gunther, and Anthony S. Tay,Evaluating density forecasts, International Economic Review 39, 863 (1998)
work page 1998
-
[5]
T. Gneiting, F. Balabdaoui, and A. E. Raftery,Probabilistic forecasts, cal- ibration and sharpness, Journal of the Royal Statistical Society B 69, 243- 268 (2007)
work page 2007
-
[6]
T. M. Hamill,Interpretation of Rank Histograms for Verifying Ensemble Forecasts, Monthly Weather Review 129, 550–560 (2001)
work page 2001
-
[7]
A. W. van der Vaart, and J. A. Wellner,Weak Convergence and Em- pirical Processes, Springer (1996). 16
work page 1996
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.