NeutronSparse: Coordinating Heterogeneous Engines for Sparse Matrix Multiplication on NPUs
Pith reviewed 2026-06-26 09:51 UTC · model grok-4.3
The pith
NeutronSparse accelerates sparse matrix multiplication on NPUs by coordinating heterogeneous engines and orchestrating data tiles.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
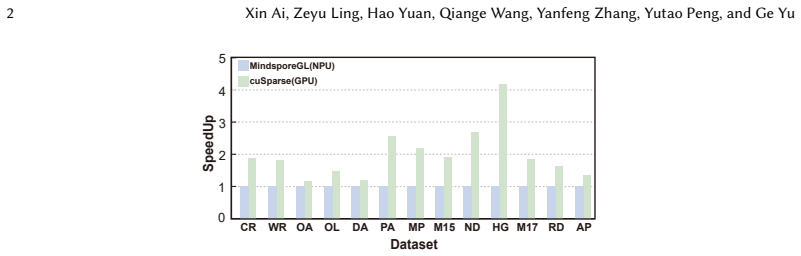
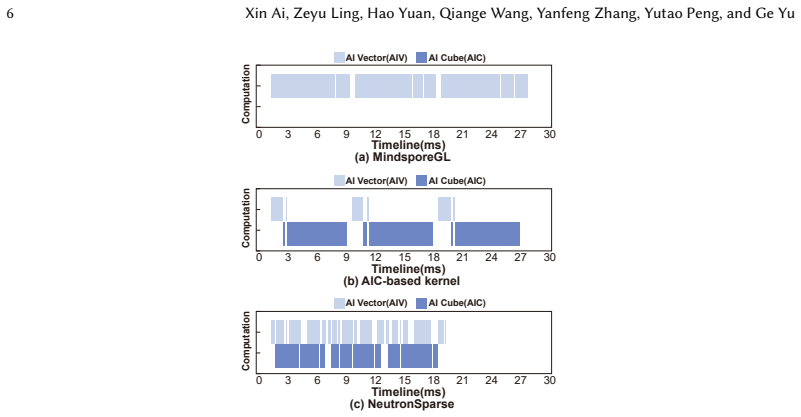
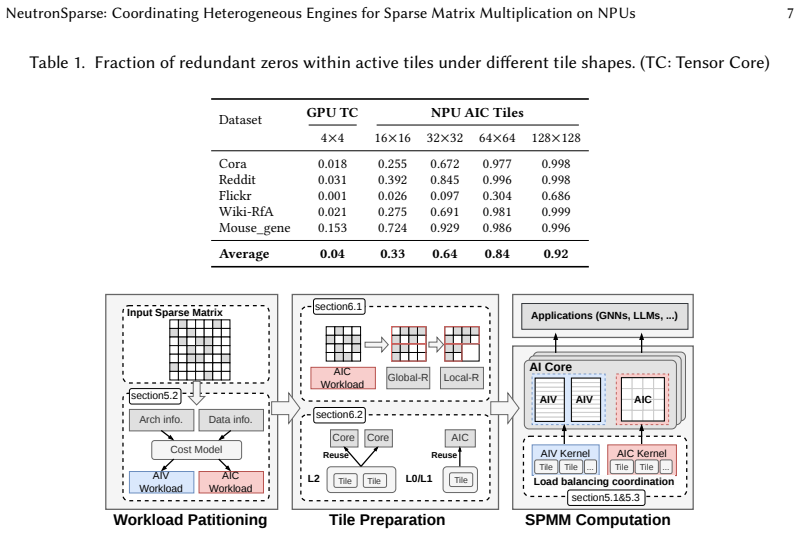
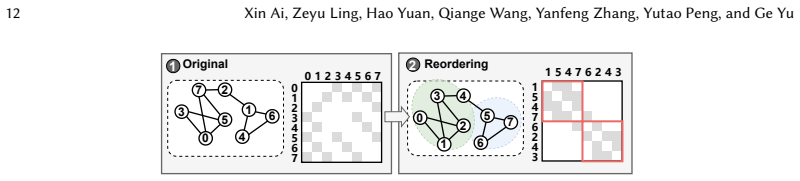
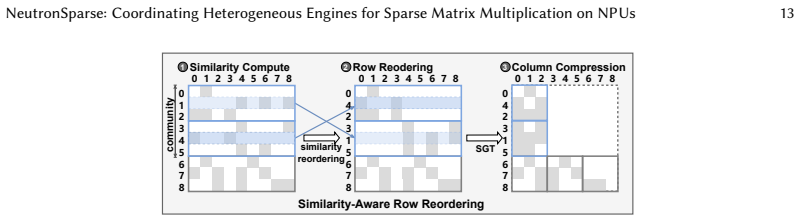
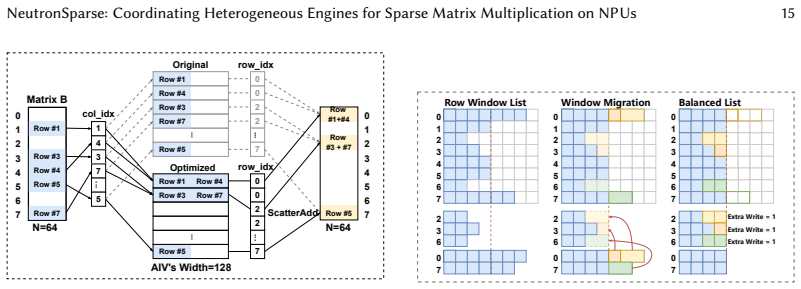
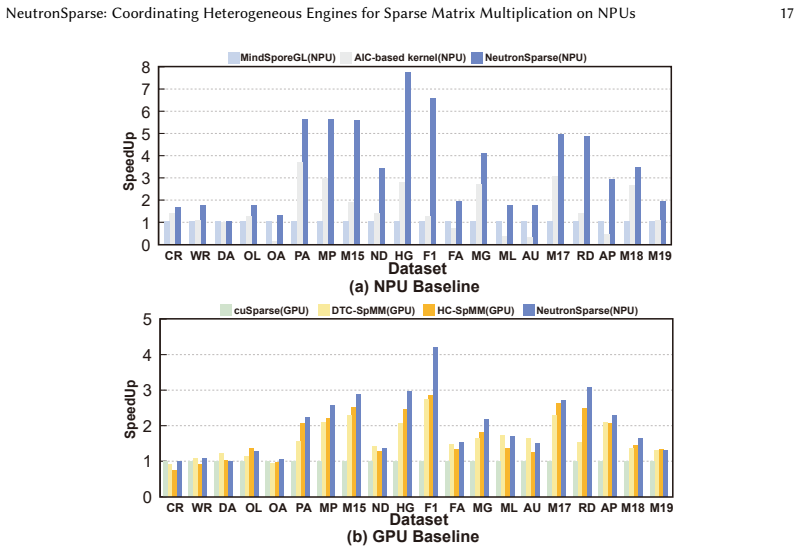
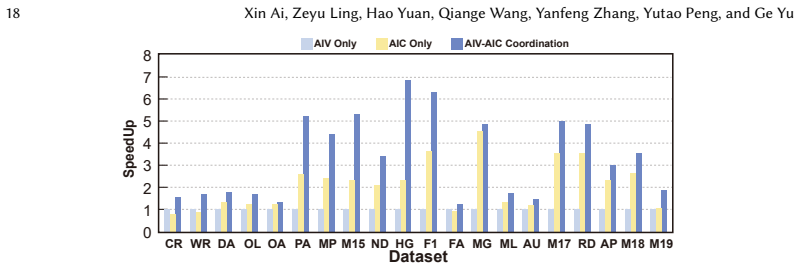
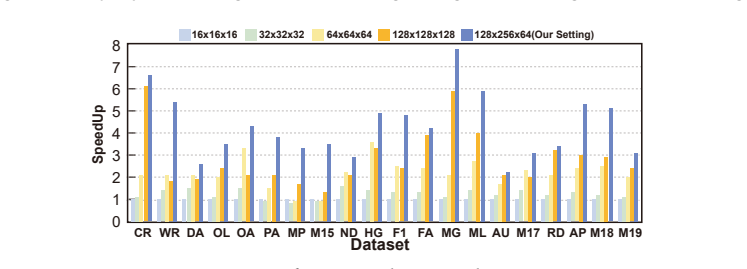
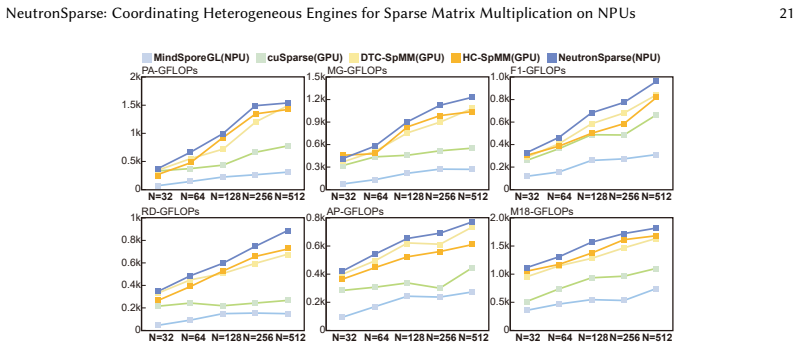
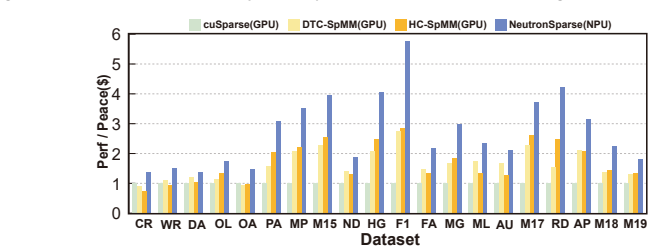
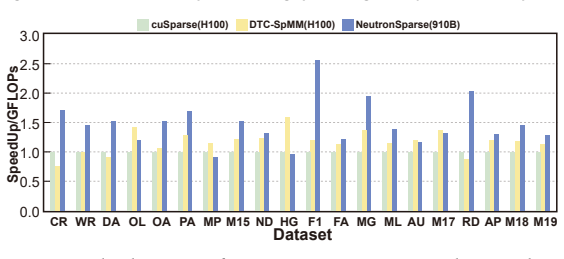
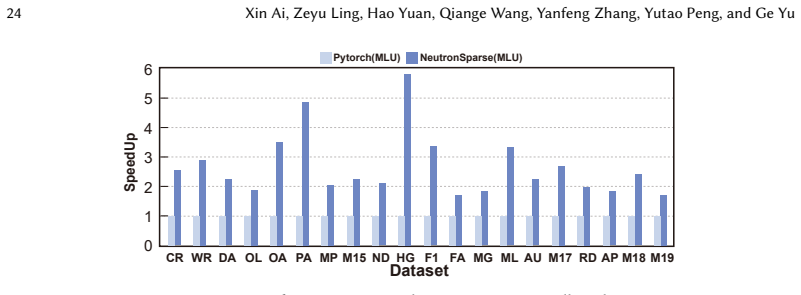
NeutronSparse is a coordination-first SpMM framework that combines sparsity-aware coordination of heterogeneous engines, which adaptively partitions and balances workloads between compute units, with locality-aware tile orchestrating, which reorganizes and reuses data tiles. On Ascend 910B the framework reaches 1.26x-7.78x speedup over NPU baselines and 1.03x-3.07x speedup over cuSPARSE on A100, while the vendor MindSpore implementation only attains 36.3 percent of the GPU library performance.
What carries the argument
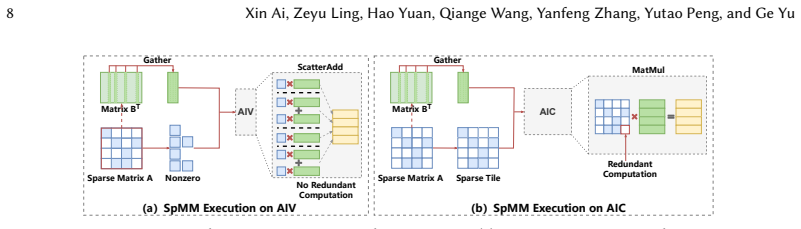
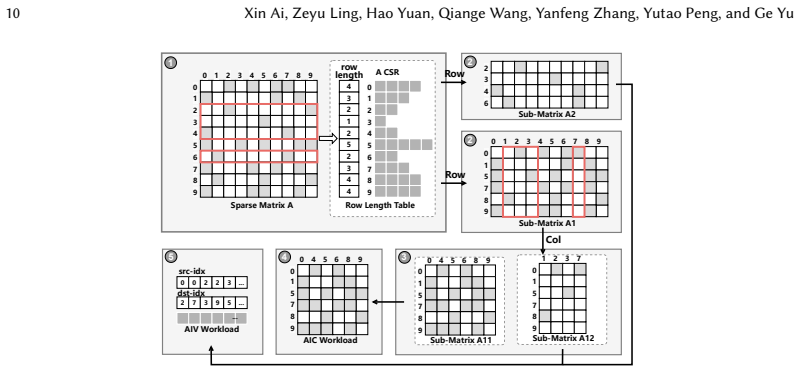
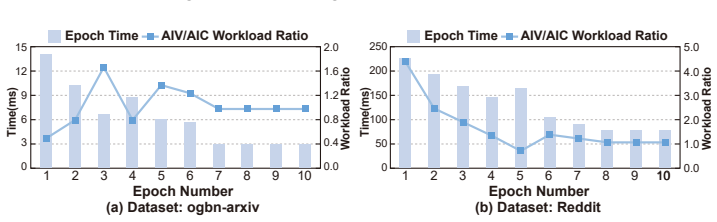
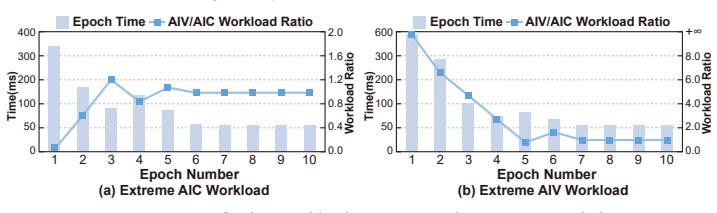
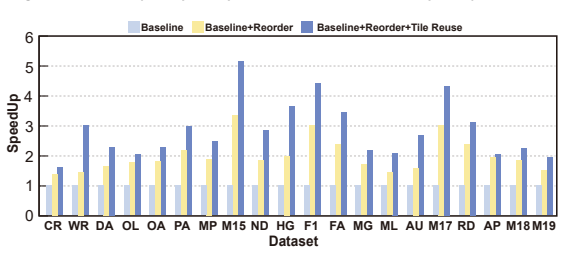
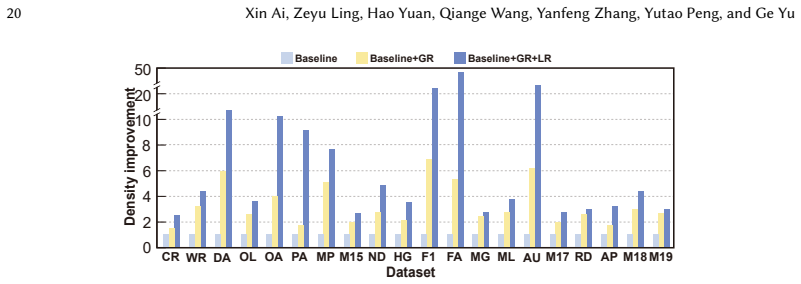
Sparsity-aware coordination of heterogeneous engines together with locality-aware tile orchestrating, which together balance workloads and reduce redundant data movement under the tile-based model.
If this is right
- Heterogeneous NPU units can reach high utilization on irregular sparse data when workloads are partitioned adaptively.
- Redundant computation and memory traffic in tile-based SpMM shrink when data tiles are reused across engines.
- NPUs can match or exceed current GPU sparse libraries for this workload on Ascend 910B hardware.
- The untapped potential of NPUs for sparse computation becomes usable once the coordination gap is closed.
- Data-management challenges that currently limit SpMM on NPUs are addressed by explicit engine balancing and tile reuse.
Where Pith is reading between the lines
- The same coordination approach could be tested on other NPU designs that also expose multiple engine types.
- Extending the tile-orchestration logic to additional sparse kernels such as SpMV would be a direct next measurement.
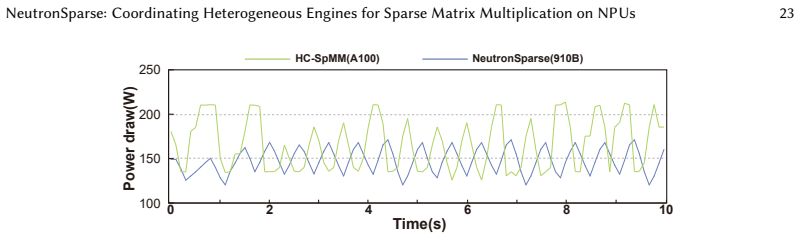
- Measuring energy per operation alongside throughput would show whether the coordination gains preserve the efficiency advantage of NPUs.
- Porting the scheduling logic into a higher-level framework would let application writers benefit without rewriting kernels.
Load-bearing premise
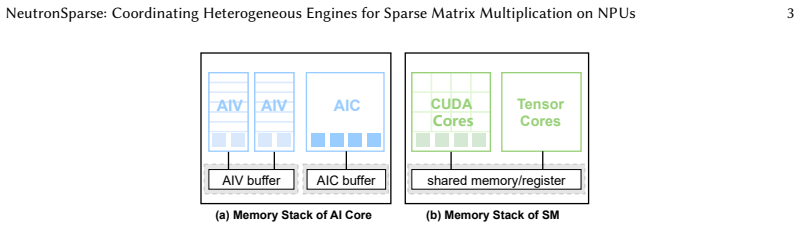
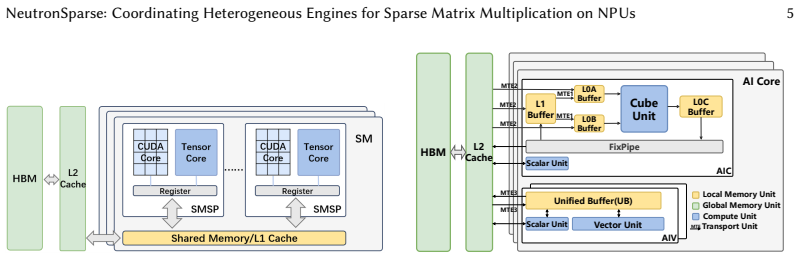
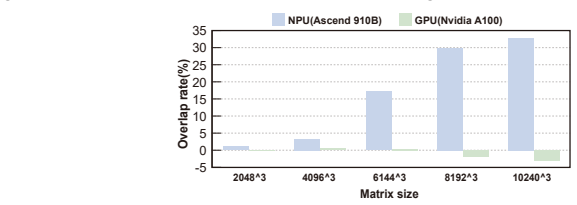
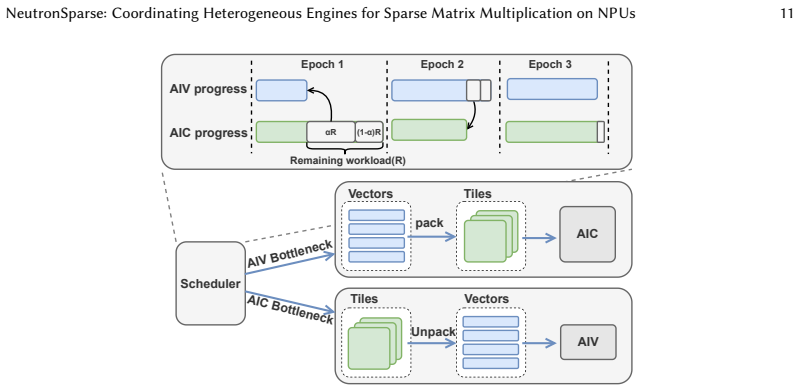
The key performance bottleneck for SpMM on NPUs lies in the lack of efficient coordination across heterogeneous compute units under the tile-based execution model.
What would settle it
A side-by-side timing of the same SpMM kernels on Ascend 910B with the coordination and tile-orchestration passes turned off versus turned on, to check whether the reported speedups appear.
Figures
read the original abstract
Sparse matrix-matrix multiplication (SpMM) is a fundamental data operation for large-scale sparse data processing. With NPUs increasingly deployed in data centers for their performance and energy efficiency, accelerating SpMM on these platforms is a natural choice. However, high-performance SpMM on NPUs poses a data management challenge, as irregular sparsity demands efficient data organization and scheduling. On Ascend 910B, the official MindSpore implementation achieves only 36.3% of the performance of GPU-based sparse libraries such as cuSPARSE on NVIDIA A100. To this end, we conduct an in-depth architectural analysis of SpMM execution on NPUs versus GPU and identify that the key performance bottleneck for SpMM on NPUs lies in the lack of efficient coordination across heterogeneous compute units under tile-based execution model. Therefore, we propose NeutronSparse, a coordination-first SpMM framework for NPUs. NeutronSparse integrates two key techniques: (i) Sparsity-aware coordination of heterogeneous engines, which adaptively partitions and balances workloads between heterogeneous compute units to keep them busy, and (ii) Locality-aware tile orchestrating, which reorganizes and reuses data tiles to reduce redundant computation and memory movement overhead. Evaluations on Ascend 910B show that NeutronSparse achieves 1.26x-7.78x speedup over NPU baselines and 1.03x-3.07x speedup over leading GPU libraries on NVIDIA A100, revealing untapped potential of NPUs for sparse computation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes NeutronSparse, a SpMM framework for NPUs that identifies the bottleneck in coordinating heterogeneous compute units under tile-based execution. It introduces two techniques: sparsity-aware coordination of heterogeneous engines and locality-aware tile orchestrating. The work reports speedups of 1.26x-7.78x over NPU baselines and 1.03x-3.07x over GPU libraries.
Significance. If the results hold, this is a significant contribution to the field as it shows the potential of NPUs for sparse computation through better coordination, which could impact the design of future NPU software for data center workloads. The architectural analysis and proposed techniques provide a foundation for optimizing irregular workloads on heterogeneous accelerators.
minor comments (1)
- [Abstract] The abstract states performance numbers but supplies no methodology, dataset details, error bars, or verification steps. While the full manuscript likely contains these details in the evaluation section, the abstract would benefit from a high-level mention to allow readers to assess the claims at a glance.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and recommendation for minor revision. The report identifies the core contribution correctly. Since no specific major comments were raised, we have no points to address point-by-point at this stage. We will incorporate any minor suggestions during revision.
Circularity Check
No significant circularity
full rationale
The paper is an empirical systems contribution that identifies a performance bottleneck via architectural analysis of NPUs versus GPUs, then evaluates two proposed coordination techniques through direct hardware measurements on Ascend 910B. No equations, fitted parameters, self-citation chains, or definitional reductions appear in the provided text. The speedup claims follow from experimental results rather than any input-by-construction equivalence.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Khalid Ahmad, Cris Cecka, Michael Garland, and Mary Hall. 2024. Exploring Data Layout for Sparse Tensor Times Dense Matrix on GPUs.ACM Transactions on Architecture and Code Optimization21, 1 (2024), 1–20
2024
-
[2]
Xin Ai, Qiange Wang, Chunyu Cao, Yanfeng Zhang, Chaoyi Chen, Hao Yuan, Yu Gu, and Ge Yu. 2024. NeutronOrch: Rethinking Sample-based GNN Training under CPU-GPU Heterogeneous Environments.Proc. VLDB Endow.17, 8 (2024), 1995–2008. , Vol. 1, No. 1, Article . Publication date: June 2026. 26 Xin Ai, Zeyu Ling, Hao Yuan, Qiange Wang, Yanfeng Zhang, Yutao Peng, and Ge Yu
2024
-
[3]
Xin Ai, Hao Yuan, Zeyu Ling, Qiange Wang, Yanfeng Zhang, Zhenbo Fu, Chaoyi Chen, Yu Gu, and Ge Yu. 2024. NeutronTP: Load-Balanced Distributed Full-Graph GNN Training with Tensor Parallelism.Proceedings of the VLDB Endowment18, 2 (2024), 173–186
2024
-
[4]
Xin Ai, Bing Zhang, Qiange Wang, Yanfeng Zhang, Hao Yuan, Shufeng Gong, and Ge Yu. 2025. NeutronAscend: Optimizing GNN Training with Ascend AI Processors.ACM Transactions on Architecture and Code Optimization(2025)
2025
-
[5]
Junya Arai, Hiroaki Shiokawa, Takeshi Yamamuro, Makoto Onizuka, and Sotetsu Iwamura. 2016. Rabbit order: Just-in- time parallel reordering for fast graph analysis. In2016 IEEE International Parallel and Distributed Processing Symposium (IPDPS). 22–31
2016
-
[6]
Timothy A Davis and Yifan Hu. 2011. The University of Florida sparse matrix collection.ACM Transactions on Mathematical Software (TOMS)38, 1 (2011), 1–25
2011
-
[7]
Aritra Dhar, Clément Thorens, Lara Magdalena Lazier, and Lukas Cavigelli. 2024. Ascend-CC: Confidential Computing on Heterogeneous NPU for Emerging Generative AI Workloads. https://arxiv.org/abs/2407.11888
arXiv 2024
-
[8]
I. S. Duff. 1977. A Survey of Sparse Matrix Research.Proc. IEEE65, 4 (1977), 500–535
1977
-
[9]
Ruibo Fan, Wei Wang, and Xiaowen Chu. 2024. DTC-SpMM: Bridging the Gap in Accelerating General Sparse Matrix Multiplication with Tensor Cores. InProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), Volume 3. 253–267
2024
-
[10]
Trevor Gale, Matei Zaharia, Cliff Young, and Erich Elsen. 2020. Sparse GPU Kernels for Deep Learning. https: //arxiv.org/abs/2006.10901
arXiv 2020
-
[11]
Will Hamilton, Zhitao Ying, and Jure Leskovec. 2017. Inductive representation learning on large graphs.Advances in neural information processing systems30 (2017)
2017
-
[12]
Guseul Heo, Sangyeop Lee, Jaehong Cho, Hyunmin Choi, Sanghyeon Lee, Hyungkyu Ham, Gwangsun Kim, Divya Mahajan, and Jongse Park. 2024. NeuPIMs: NPU–PIM Heterogeneous Acceleration for Batched LLM Inferencing. InProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), Volume 3. 722–737
2024
-
[13]
Khoa Ho, Hui Zhao, Adwait Jog, and Saraju Mohanty. 2022. Improving GPU Throughput through Parallel Execution Using Tensor Cores and CUDA Cores. InIEEE Computer Society Annual Symposium on VLSI (ISVLSI). 223–228
2022
-
[14]
Sadayappan
Changwan Hong, Aravind Sukumaran-Rajam, Israt Nisa, Kunal Singh, and P. Sadayappan. 2019. Adaptive Sparse Tiling for Sparse Matrix Multiplication. InProceedings of the 24th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming (PPoPP). 300–314
2019
-
[15]
Weihua Hu, Matthias Fey, Marinka Zitnik, Yuxiao Dong, Hongyu Ren, Bowen Liu, Michele Catasta, and Jure Leskovec
-
[16]
Open graph benchmark: Datasets for machine learning on graphs.Advances in neural information processing systems33 (2020), 22118–22133
2020
-
[17]
Guyue Huang, Guohao Dai, Yu Wang, and Huazhong Yang. 2020. GE-SpMM: General-Purpose Sparse Matrix–Matrix Multiplication on GPUs for Graph Neural Networks. InSC20: International Conference for High Performance Computing, Networking, Storage and Analysis. 1–12
2020
-
[18]
Jouppi, Cliff Young, Nishant Patil, David A
Norman P. Jouppi, Cliff Young, Nishant Patil, David A. Patterson, Gaurav Agrawal, Raminder Bajwa, Sarah Bates, Suresh Bhatia, Nan Boden, Al Borchers, Rick Boyle, Pierre-luc Cantin, Clifford Chao, Chris Clark, Jeremy Coriell, Mike Daley, Matt Dau, Jeffrey Dean, Ben Gelb, Tara Vazir Ghaemmaghami, Rajendra Gottipati, William Gulland, Robert Hagmann, C. Richa...
-
[19]
InProceedings of the 44th Annual International Symposium on Computer Architecture, ISCA 2017, Toronto, ON, Canada, June 24-28, 2017
In-Datacenter Performance Analysis of a Tensor Processing Unit. InProceedings of the 44th Annual International Symposium on Computer Architecture, ISCA 2017, Toronto, ON, Canada, June 24-28, 2017. ACM, 1–12
2017
-
[20]
Hyeyoung Ko, Suyeon Lee, Yoonseo Park, and Anna Choi. 2022. A Survey of Recommendation Systems: Recommenda- tion Models, Techniques, and Application Fields.Electronics11, 1 (2022), 141
2022
-
[21]
Sadayyapan
Sureyya Emre Kurt, Aravind Sukumaran-Rajam, Fabrice Rastello, and P. Sadayyapan. 2020. Efficient Tiled Sparse Matrix Multiplication through Matrix Signatures. InSC20: International Conference for High Performance Computing, Networking, Storage and Analysis. 1–14
2020
-
[22]
Shigang Li, Kazuki Osawa, and Torsten Hoefler. 2022. Efficient Quantized Sparse Matrix Operations on Tensor Cores. InSC22: International Conference for High Performance Computing, Networking, Storage and Analysis. 1–15
2022
-
[23]
Zhonggen Li, Xiangyu Ke, Yifan Zhu, Yunjun Gao, and Yaofeng Tu. 2025. HC-SpMM: Accelerating Sparse Matrix-Matrix Multiplication for Graphs with Hybrid GPU Cores. In41st IEEE International Conference on Data Engineering, ICDE 2025, Hong Kong, May 19-23, 2025. IEEE, 501–514. , Vol. 1, No. 1, Article . Publication date: June 2026. NeutronSparse: Coordinating...
2025
-
[24]
Heng Liao, Jiajin Tu, Jing Xia, Hu Liu, Xiping Zhou, Honghui Yuan, and Yuxing Hu. 2021. Ascend: a Scalable and Unified Architecture for Ubiquitous Deep Neural Network Computing : Industry Track Paper. InIEEE International Symposium on High-Performance Computer Architecture, HPCA 2021, Seoul, South Korea, February 27 - March 3, 2021. IEEE, 789–801
2021
-
[25]
Heng Liao, Jiajin Tu, Jing Xia, and Xiping Zhou. 2019. DaVinci: A Scalable Architecture for Neural Network Computing. In2019 IEEE Hot Chips 31 Symposium (HCS), Cupertino, CA, USA, August 18-20, 2019. IEEE, 1–44
2019
-
[26]
Shaoli Liu, Zidong Du, Jinhua Tao, Dong Han, Tao Luo, Yuan Xie, Yunji Chen, and Tianshi Chen. 2016. Cambricon: An Instruction Set Architecture for Neural Networks. In43rd ACM/IEEE Annual International Symposium on Computer Architecture, ISCA 2016, Seoul, South Korea, June 18-22, 2016. IEEE Computer Society, 393–405
2016
-
[27]
Shengbai Luo, Bo Wang, Yihao Shi, Xueyi Zhang, Qingshan Xue, and Sheng Ma. 2024. Sparm: A Sparse Matrix Multiplication Accelerator Supporting Multiple Dataflows. InIEEE 35th International Conference on Application-specific Systems, Architectures and Processors (ASAP). 122–130
2024
-
[28]
Julian McAuley, Christopher Targett, Qinfeng Shi, and Anton Van Den Hengel. 2015. Image-based recommendations on styles and substitutes. InProceedings of the 38th international ACM SIGIR conference on research and development in information retrieval. 43–52
2015
-
[29]
Andrew Kachites McCallum, Kamal Nigam, Jason Rennie, and Kristie Seymore. 2000. Automating the construction of internet portals with machine learning.Information Retrieval3, 2 (2000), 127–163
2000
-
[30]
Eitan Medina and Eran Dagan. 2020. Habana Labs Purpose-Built AI Inference and Training Processor Architectures: Scaling AI Training Systems Using Standard Ethernet With Gaudi Processor.IEEE Micro40, 2 (2020), 17–24
2020
-
[31]
Nikolai Merkel, Pierre Toussing, Ruben Mayer, and Hans-Arno Jacobsen. 2024. Can Graph Reordering Speed Up Graph Neural Network Training? An Experimental Study.Proceedings of the VLDB Endowment18, 2 (2024), 293–307
2024
-
[32]
Salli Moustafa. 2023. Accelerating sparse matrix-matrix multiplication with the Ascend AI core. InProc. Workshop Accelerated Mach. Learn. 33–41
2023
-
[33]
NVIDIA. 2023. CUDA Sparse Matrix Library. https://developer.nvidia.com/cusparse. Accessed 2025-05-09
2023
-
[34]
NVIDIA. 2023. Dense Linear Algebra on GPUs. https://developer.nvidia.com/cublas. Accessed 2025-05-09
2023
-
[35]
Meng Pang, Xiang Fei, Peng Qu, Youhui Zhang, and Zhaolin Li. 2024. RoDe: A Row Decomposition–Based Approach for Sparse Matrix Multiplication on GPUs. InProceedings of the 29th ACM SIGPLAN Annual Symposium on Principles and Practice of Parallel Programming (PPoPP). 377–389
2024
-
[36]
Jingshu Peng, Zhao Chen, Yingxia Shao, Yanyan Shen, Lei Chen, and Jiannong Cao. 2022. SANCUS: Staleness-Aware Communication-Avoiding Full-Graph Decentralized Training in Large-Scale Graph Neural Networks.Proc. VLDB Endow.15, 9 (2022), 1937–1950
2022
-
[37]
Aurko Roy, Mohammad Saffar, Ashish Vaswani, and David Grangier. 2021. Efficient content-based sparse attention with routing transformers.Transactions of the Association for Computational Linguistics9 (2021), 53–68
2021
-
[38]
Rishov Sarkar, Stefan Abi-Karam, Yuqi He, Lakshmi Sathidevi, and Cong Hao. 2022. FlowGNN: A Dataflow Architecture for Real-Time Workload-Agnostic Graph Neural Network Inference. https://arxiv.org/abs/2204.13103
arXiv 2022
-
[39]
Jinliang Shi, Shigang Li, Youxuan Xu, Rongtian Fu, Xueying Wang, and Tong Wu. 2025. Flashsparse: Minimizing computation redundancy for fast sparse matrix multiplications on tensor cores. InProceedings of the 30th ACM SIGPLAN Annual Symposium on Principles and Practice of Parallel Programming. 312–325
2025
-
[40]
Jinliang Shi, Shigang Li, Youxuan Xu, Xueying Wang, Rongtian Fu, Zhi Ma, and Tong Wu. 2025. Libra: Synergizing CUDA and Tensor Cores for High-Performance Sparse Matrix Multiplication.arXiv preprint arXiv:2506.22714(2025)
arXiv 2025
-
[41]
Mingcong Song, Xinru Tang, Fengfan Hou, Jing Li, Wei Wei, Yipeng Ma, Runqiu Xiao, Hongjie Si, Dingcheng Jiang, Shouyi Yin, et al. 2026. XY-Serve: End-to-End Versatile Production Serving for Dynamic LLM Workloads. InProceedings of the 31st ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1. 314–329
2026
-
[42]
Nitish Srivastava, Hanchen Jin, Jie Liu, David Albonesi, and Zhiru Zhang. 2020. MatRaptor: A Sparse–Sparse Ma- trix Multiplication Accelerator Based on Row-Wise Product. In53rd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO). 766–780
2020
-
[43]
Patrick Walters and Regina Barzilay
W. Patrick Walters and Regina Barzilay. 2020. Applications of Deep Learning in Molecule Generation and Molecular Property Prediction.Accounts of Chemical Research54, 2 (2020), 263–270
2020
-
[44]
Xinchen Wan, Kaiqiang Xu, Xudong Liao, Yilun Jin, Kai Chen, and Xin Jin. 2023. Scalable and Efficient Full-Graph GNN Training for Large Graphs.Proc. ACM Manag. Data1, 2 (2023), 143:1–143:23
2023
-
[45]
Qiange Wang, Yao Chen, Weng-Fai Wong, and Bingsheng He. 2023. HongTu: Scalable Full-Graph GNN Training on Multiple GPUs.Proc. ACM Manag. Data1, 4 (2023), 246:1–246:27
2023
-
[46]
Qiange Wang, Yanfeng Zhang, Hao Wang, Chaoyi Chen, Xiaodong Zhang, and Ge Yu. 2022. NeutronStar: Distributed GNN Training with Hybrid Dependency Management. InInternational Conference on Management of Data, Philadelphia, SIGMOD’22, PA, USA. ACM, 1301–1315. , Vol. 1, No. 1, Article . Publication date: June 2026. 28 Xin Ai, Zeyu Ling, Hao Yuan, Qiange Wang,...
2022
-
[47]
Xinliang Wang, Weifeng Liu, Wei Xue, and Li Wu. 2018. swSpTRSV: A Fast Sparse Triangular Solve with Sparse Level Tile Layout on Sunway Architectures. InProceedings of the 23rd ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming (PPoPP). 338–353
2018
-
[48]
Yuke Wang, Boyuan Feng, Zheng Wang, Guyue Huang, and Yufei Ding. 2021. TC-GNN: Bridging Sparse GNN Computation and Dense Tensor Cores on GPUs.IEEE Transactions on Parallel and Distributed Systems(2021)
2021
-
[49]
Zhen Xie, Guangming Tan, Weifeng Liu, and Ninghui Sun. 2022. A Pattern-Based SpGEMM Library for Multi-Core and Many-Core Architectures.IEEE Transactions on Parallel and Distributed Systems33, 1 (2022), 159–175
2022
-
[50]
Yi Xu, Licheng Yu, Hongteng Xu, Hao Zhang, and Truong Nguyen. 2015. Vector Sparse Representation of Color Image Using Quaternion Matrix Analysis.IEEE Transactions on Image Processing24, 4 (2015), 1315–1329
2015
-
[51]
Jiale Yan, Hiroaki Ito, Angel Lopez Garcia-Arias, Yasuyuki Okoshi, Hikari Otsuka, Kazushi Kawamura, Thiem Van Chu, and Masato Motomura. 2023. Multicoated and Folded Graph Neural Networks with Strong Lottery Tickets. Manuscript
2023
-
[52]
Jianrong Yan, Wenbin Jiang, Dongao He, Suyang Wen, Yang Li, Hai Jin, and Zhiyuan Shao. 2024. RT-GNN: Acceler- ating Sparse Graph Neural Networks by Tensor–CUDA Kernel Fusion.ACM Transactions on Architecture and Code Optimization(2024), 3702001
2024
-
[53]
Carl Yang, Aydin Buluc, and John D. Owens. 2018. Design Principles for Sparse Matrix Multiplication on the GPU. https://arxiv.org/abs/1803.08601
Pith/arXiv arXiv 2018
-
[54]
Orestis Zachariadis, Nitin Satpute, Juan Gómez-Luna, and Joaquín Olivares. 2020. Accelerating Sparse Matrix–Matrix Multiplication with GPU Tensor Cores.Computers & Electrical Engineering88 (2020), 106848
2020
-
[55]
Han Zhao, Weihao Cui, Quan Chen, Jieru Zhao, Jingwen Leng, and Minyi Guo. 2021. Exploiting Intra-SM Parallelism in GPUs via Persistent and Elastic Blocks. InIEEE International Conference on Computer Design (ICCD). 290–298
2021
-
[56]
Haisha Zhao, San Li, Jiaheng Wang, Chunbao Zhou, Jue Wang, Zhikuang Xin, Shunde Li, Zhiqiang Liang, Zhijie Pan, Fang Liu, Yan Zeng, Yangang Wang, and Xuebin Chi. 2025. Acc-SpMM: Accelerating General-Purpose Sparse Matrix–Matrix Multiplication with GPU Tensor Cores. InProceedings of the 30th ACM SIGPLAN Annual Symposium on Principles and Practice of Parall...
2025
-
[57]
Yuhang Zhou, Zhibin Wang, Guyue Liu, Shipeng Li, Xi Lin, Zibo Wang, Yongzhong Wang, Fuchun Wei, Jingyi Zhang, Zhiheng Hu, Yanlin Liu, Chunsheng Li, Ziyang Zhang, Yaoyuan Wang, Bin Zhou, Wanchun Dou, Guihai Chen, and Chen Tian. 2025. Squeezing Operator Performance Potential for the Ascend Architecture. InProceedings of the 30th ACM International Conference...
2025
-
[58]
Yuhang Zhou, Zibo Wang, Zhibin Wang, Ruyi Zhang, Chen Tian, Xiaoliang Wang, Wanchun Dou, Guihai Chen, Bingqiang Wang, Yonghong Tian, Yan Zhang, Hui Wang, Fuchun Wei, Boquan Sun, Jingyi Zhang, Bin She, Teng Su, Yifan Yao, Chunsheng Li, Ziyang Zhang, Yaoyuan Wang, Bin Zhou, and Guyue Liu. 2025. Accelerating Model Training on Ascend Chips: An Industrial Syst...
2025
-
[59]
Maohua Zhu, Tao Zhang, Zhenyu Gu, and Yuan Xie. 2019. Sparse Tensor Core: Algorithm and Hardware Co-Design for Vector-Wise Sparse Neural Networks on Modern GPUs. In52nd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO). 359–371
2019
-
[60]
Rong Zhu, Kun Zhao, Hongxia Yang, Wei Lin, Chang Zhou, Baole Ai, Yong Li, and Jingren Zhou. 2019. AliGraph: A Comprehensive Graph Neural Network Platform.Proc. VLDB Endow.12, 12 (2019), 2094–2105
2019
-
[61]
Zeling Zhu, Bangchuan Wang, Chuying Yang, Rui Zhu, Mingyao Zhou, and Nenggan Zheng. 2023. Performance Evaluation of MindSpore and PyTorch Based on Ascend NPU. InIEEE International Conference on Parallel and Distributed Systems (ICPADS). 1826–1832
2023
-
[62]
Xiaohan Zou. 2020. A Survey on Application of Knowledge Graph. InJournal of Physics: Conference Series, Vol. 1487. 012016. , Vol. 1, No. 1, Article . Publication date: June 2026
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.