ToolRec: Calibrated Preference Alignment for Query Recommendation in On-Device Assistants
Pith reviewed 2026-06-27 18:13 UTC · model grok-4.3
The pith
ToolRec calibrates click logs at two levels to align query recommendations with executable system tools in on-device assistants.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
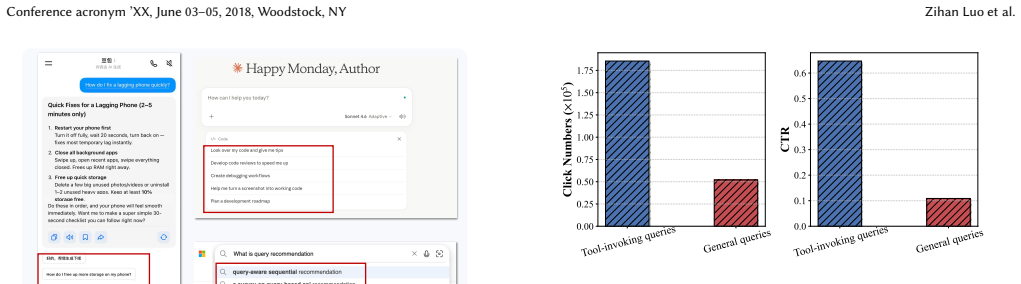
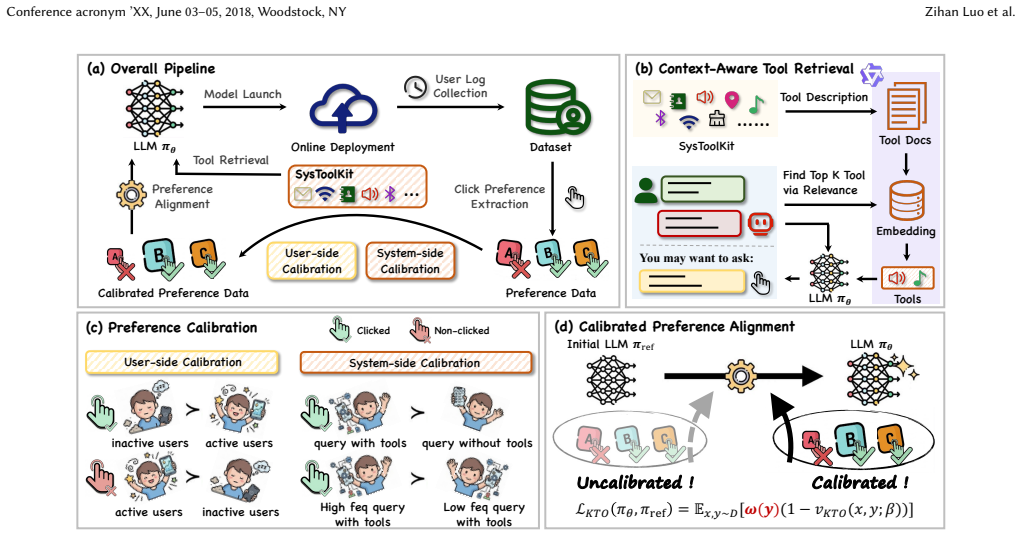
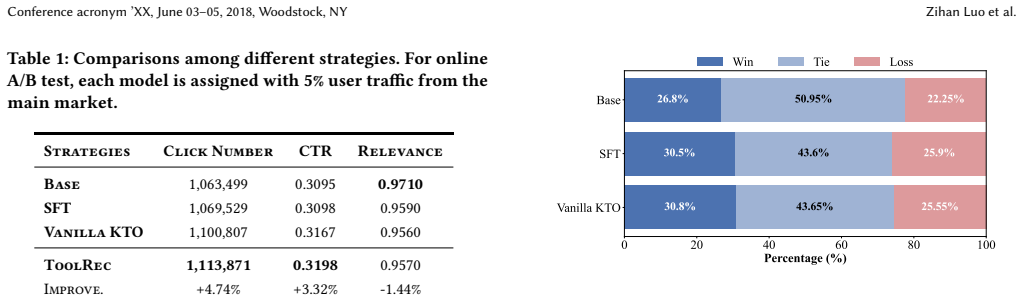
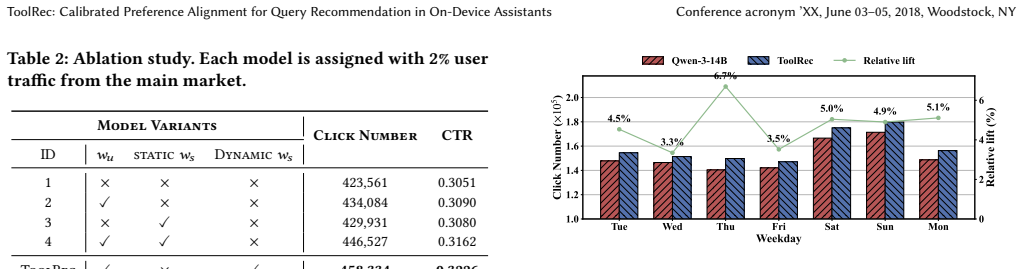
ToolRec constructs SysToolKit containing 708 system tools paired with context-aware retrieval, applies dual-level calibration to raw click logs that adjusts for varying user activity levels while up-weighting tool-invoking queries, and aligns the model via sample-level weighted Kahneman-Tversky Optimization, yielding higher click-through rates and click volumes in online A/B tests while preserving query relevance.
What carries the argument
Dual-level calibration on click logs that corrects for user activity levels and up-weights tool-invoking queries, used to supply preference signals for weighted KTO alignment.
Load-bearing premise
The dual-level calibration on raw click logs produces preference signals that accurately reflect user intent without introducing new selection biases or distorting the distribution of executable actions.
What would settle it
An A/B test on the OPPO Xiaobu platform in which the ToolRec model produces no statistically significant gain in CTR or total clicks relative to the uncalibrated baseline.
Figures

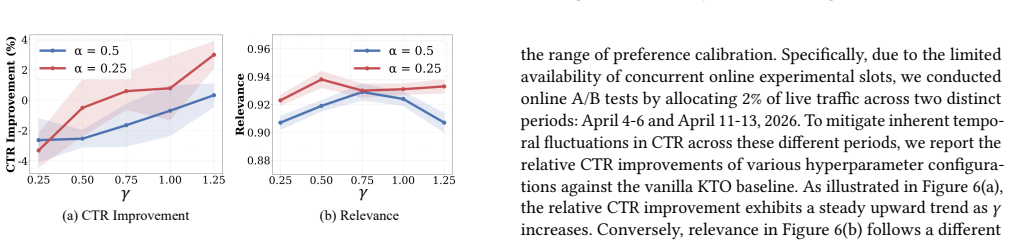

read the original abstract
Large Language Models (LLMs) have significantly advanced generative query recommendation. However, existing alignment methods primarily focus on standard chatbot scenarios, falling short in on-device intelligent assistants where users predominantly expect the rapid invocation of system-level tools. Moreover, directly aligning LLMs with real-world click logs introduces severe noise due to varying user activity levels and the failure to emphasize execution-oriented queries. To address these challenges, we propose ToolRec, a calibrated preference alignment framework tailored for on-device query recommendation. To ground query recommendation with executable actions, we first construct SysToolKit, a comprehensive repository of 708 system tools, paired with a context-aware tool retrieval mechanism to ensure recommendation relevance. We then propose a dual-level calibration mechanism to refine raw click data, effectively mitigating user behavioral noise by calibrating signals based on user activity levels, while simultaneously up-weighting click signals on system-level tool-invoking queries. Guided by these refined preference signals, we then align the model using a sample-level weighted Kahneman-Tversky Optimization (KTO). Extensive online A/B tests on our mobile assistant platform OPPO Xiaobu, which has over 150 million monthly active users, demonstrate that ToolRec can significantly improve Click-Through Rate (CTR) and total clicks volume over strong baselines while maintaining high query relevance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ToolRec, a calibrated preference alignment framework for query recommendation in on-device assistants. It introduces SysToolKit (708 system tools with context-aware retrieval), applies dual-level calibration to raw click logs (activity-level adjustment plus up-weighting of tool-invoking queries) to reduce behavioral noise, and aligns an LLM via sample-level weighted KTO. Large-scale A/B tests on OPPO Xiaobu (150M+ MAU) report gains in CTR and total clicks over baselines while preserving relevance.
Significance. If the dual-level calibration demonstrably improves preference signal fidelity without new selection biases, the work would be significant for production on-device assistants, where tool invocation is central. The scale of the online evaluation is a clear strength, providing real-world evidence that is rare in alignment papers. However, the absence of isolated validation for the calibration step limits the ability to attribute gains specifically to the proposed mechanism.
major comments (3)
- [Abstract / Dual-level calibration section] Abstract and methods description of dual-level calibration: the central claim requires that activity-level adjustment plus tool-query up-weighting produces preference signals that more accurately reflect intent than raw logs. No ablation, offline relevance metric, or human judgment study isolates this step from SysToolKit retrieval or KTO weighting; A/B gains could arise from other components.
- [Online A/B test results] Results section on A/B tests: the manuscript reports CTR and click-volume improvements but supplies no error bars, statistical significance tests, data exclusion rules, or per-user activity stratification. This makes it impossible to verify whether the reported gains are robust or driven by the calibration.
- [Dual-level calibration mechanism] Calibration mechanism: if user activity levels correlate with query length, session depth, or device context, up-weighting tool-invoking clicks may shift the distribution away from the target on-device population, introducing rather than removing bias. No diagnostic comparing calibrated vs. raw signal distributions is provided.
minor comments (2)
- [Abstract] The abstract states 'maintaining high query relevance' but provides no offline or online metric (e.g., relevance score, human rating) to support this claim.
- [Alignment section] Notation for the weighted KTO objective and the exact calibration weights should be formalized with equations for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and detailed comments on our manuscript. We address each major comment point by point below, agreeing where the manuscript is incomplete and outlining specific revisions to strengthen the presentation of results and mechanisms.
read point-by-point responses
-
Referee: [Abstract / Dual-level calibration section] Abstract and methods description of dual-level calibration: the central claim requires that activity-level adjustment plus tool-query up-weighting produces preference signals that more accurately reflect intent than raw logs. No ablation, offline relevance metric, or human judgment study isolates this step from SysToolKit retrieval or KTO weighting; A/B gains could arise from other components.
Authors: We agree that the manuscript would benefit from explicit isolation of the dual-level calibration's contribution. The reported A/B gains reflect the full ToolRec pipeline, and the original submission did not include a dedicated ablation separating calibration from retrieval and alignment. In the revised version we will add an offline ablation comparing calibrated versus raw click signals on held-out relevance metrics to better attribute performance improvements. revision: yes
-
Referee: [Online A/B test results] Results section on A/B tests: the manuscript reports CTR and click-volume improvements but supplies no error bars, statistical significance tests, data exclusion rules, or per-user activity stratification. This makes it impossible to verify whether the reported gains are robust or driven by the calibration.
Authors: We acknowledge that the A/B test reporting lacks the requested statistical details. The original manuscript omitted error bars, significance tests, exclusion rules, and activity stratification, which limits verifiability. In the revision we will incorporate standard errors or confidence intervals, results of appropriate significance tests, explicit data exclusion criteria, and per-user activity stratification to demonstrate robustness of the observed CTR and click-volume gains. revision: yes
-
Referee: [Dual-level calibration mechanism] Calibration mechanism: if user activity levels correlate with query length, session depth, or device context, up-weighting tool-invoking clicks may shift the distribution away from the target on-device population, introducing rather than removing bias. No diagnostic comparing calibrated vs. raw signal distributions is provided.
Authors: We recognize the validity of this concern about possible distribution shift. The dual-level calibration is intended to reduce activity-level noise while emphasizing tool-invoking queries, yet the manuscript provides no explicit diagnostic comparing calibrated and raw distributions. In the revised manuscript we will add a diagnostic analysis section that compares key distributional properties (query length, session depth, device context, and activity correlations) before and after calibration to verify bias mitigation. revision: yes
Circularity Check
No circularity: framework relies on external A/B validation and standard KTO without self-referential reductions
full rationale
The provided abstract and description contain no equations, derivations, or parameter-fitting steps that reduce predictions to inputs by construction. The dual-level calibration is described as a preprocessing step on click logs, followed by KTO alignment and online A/B testing on 150M users; these are presented as empirical improvements rather than mathematical identities. No self-citations, uniqueness theorems, or ansatzes are invoked in the text. The central claims rest on external platform experiments, which are falsifiable outside the paper's fitted values. This is the common case of a self-contained applied method paper with no detectable circularity in its derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Zhuoxi Bai, Ning Wu, Fengyu Cai, Xinyi Zhu, and Yun Xiong. 2024. Aligning Large Language Model with Direct Multi-Preference Optimization for Recom- mendation. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management, CIKM 2024, Boise, ID, USA, October 21-25, 2024. ACM, 76–86. https://doi.org/10.1145/3627673.3679611
-
[2]
Keqin Bao, Jizhi Zhang, Wenjie Wang, Yang Zhang, Zhengyi Yang, Yanchen Luo, Chong Chen, Fuli Feng, and Qi Tian. 2025. A Bi-Step Grounding Paradigm for Large Language Models in Recommendation Systems.ACM Transactions on Recommender Systems3, 4, Article 53 (2025), 27 pages. https://doi.org/10.1145/ 3716393
2025
-
[3]
Keqin Bao, Jizhi Zhang, Yang Zhang, Wenjie Wang, Fuli Feng, and Xiangnan He. 2023. TALLRec: An Effective and Efficient Tuning Framework to Align Large Language Model with Recommendation. InProceedings of the 17th ACM Conference on Recommender Systems, RecSys 2023, Singapore, September 18-22,
2023
-
[4]
Proceedings of the 17th ACM Conference on Recommender Systems , pages =
ACM, 1007–1014. https://doi.org/10.1145/3604915.3608857
-
[5]
Fei Cai and Maarten de Rijke. 2016. Selectively Personalizing Query Auto- Completion. InProceedings of the 39th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2016, Pisa, Italy, July 17-21, 2016. ACM, 993–996. https://doi.org/10.1145/2911451.2914686
-
[6]
Jiaju Chen, Chongming Gao, Shuai Yuan, Shuchang Liu, Qingpeng Cai, and Peng Jiang. 2025. DLCRec: A Novel Approach for Managing Diversity in LLM-Based Recommender Systems. InProceedings of the 18th ACM International Conference on Web Search and Data Mining, WSDM 2025, Hannover, Germany, March 10-14,
2025
-
[7]
https://doi.org/10.1145/3701551.3703572
ACM, 857–865. https://doi.org/10.1145/3701551.3703572
-
[8]
Kawin Ethayarajh, Winnie Xu, Niklas Muennighoff, Dan Jurafsky, and Douwe Kiela. 2024. Model Alignment as Prospect Theoretic Optimization. InProceed- ings of the 41st International Conference on Machine Learning, ICML 2024, Vi- enna, Austria, July 21-27, 2024. PMLR / OpenReview.net, 12634–12651. https: //proceedings.mlr.press/v235/ethayarajh24a.html
2024
-
[9]
Chongming Gao, Ruijun Chen, Shuai Yuan, Kexin Huang, Yuanqing Yu, and Xiangnan He. 2025. SPRec: Self-Play to Debias LLM-based Recommendation. In Proceedings of the ACM Web Conference 2025, WWW 2025, Sydney, NSW, Australia, April 28-May 2, 2025. ACM, 5075–5084. https://doi.org/10.1145/3696410.3714524
-
[10]
Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. LoRA: Low-Rank Adaptation of Large Language Models. InProceedings of the 10th International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net. https: //openreview.net/forum?id=nZeVKeeFYf9
2022
-
[11]
Yunqi Li, Hanxiong Chen, Zuohui Fu, Yingqiang Ge, and Yongfeng Zhang. 2021. User-oriented Fairness in Recommendation. InProceedings of the ACM Web Conference 2021, Virtual Event / Ljubljana, Slovenia, April 19-23, 2021. ACM, 624–
2021
-
[12]
doi:10.1145/3442381.3449866
-
[13]
Jiayi Liao, Sihang Li, Zhengyi Yang, Jiancan Wu, Yancheng Yuan, Xiang Wang, and Xiangnan He. 2024. LLaRA: Large Language-Recommendation Assistant. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2024, Washington DC, USA, July 14-18,
2024
-
[14]
ACM, 1785–1795. https://doi.org/10.1145/3626772.3657690
-
[15]
Qidong Liu, Xian Wu, Yejing Wang, Zijian Zhang, Feng Tian, Yefeng Zheng, and Xiangyu Zhao. 2024. LLM-ESR: Large Language Models Enhancement for Long-tailed Sequential Recommendation. InAdvances in Neural Informa- tion Processing Systems, NeurIPS 2024, Vancouver, BC, Canada, December 10- 15, 2024. 26701–26727. http://papers.nips.cc/paper_files/paper/2024/h...
2024
-
[16]
Wenhan Liu, Ziliang Zhao, Yutao Zhu, and Zhicheng Dou. 2024. Mining Ex- ploratory Queries for Conversational Search. InProceedings of the ACM Web Conference 2024, WWW 2024, Singapore, May 13-17, 2024. ACM, 1386–1394. https://doi.org/10.1145/3589334.3645424
-
[17]
Yu Meng, Mengzhou Xia, and Danqi Chen. 2024. SimPO: Simple Pref- erence Optimization with a Reference-Free Reward. InAdvances in Neu- ral Information Processing Systems, NeurIPS 2024, Vancouver, BC, Canada, December 10-15, 2024. http://papers.nips.cc/paper_files/paper/2024/hash/ e099c1c9699814af0be873a175361713-Abstract-Conference.html
2024
-
[18]
Erxue Min, Hsiu-Yuan Huang, Xihong Yang, Min Yang, Xin Jia, Yunfang Wu, Hengyi Cai, Junfeng Wang, Shuaiqiang Wang, and Dawei Yin. 2025. CTR-Guided Generative Query Suggestion in Conversational Search. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, EMNLP 2025, Suzhou, China, November 4-9, 2025. Association for Com...
-
[19]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F Christiano, Jan Leike, and Ryan Lowe. 2022. Training Language Models to Follow Instructions with Human F...
2022
-
[20]
Dae Hoon Park and Rikio Chiba. 2017. A Neural Language Model for Query Auto-Completion. InProceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2017, Shinjuku, Tokyo, Japan, August 7-11, 2017. ACM, 1189–1192. https://doi.org/10.1145/3077136. 3080758
-
[21]
Manning, Ste- fano Ermon, and Chelsea Finn
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D. Manning, Ste- fano Ermon, and Chelsea Finn. 2023. Direct Preference Optimization: Your Language Model is Secretly a Reward Model. InAdvances in Neu- ral Information Processing Systems, NeurIPS 2023, New Orleans, LA, USA, December 10-16, 2023. http://papers.nips.cc/paper_files/paper/2023/hash/ a...
2023
-
[22]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. 2024. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models.CoRRabs/2402.03300 (2024). arXiv:2402.03300 doi:10.48550/ARXIV.2402.03300
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2402.03300 2024
-
[23]
Giulio Starace, Oliver Jaffe, Dane Sherburn, James Aung, Jun Shern Chan, Leon Maksin, Rachel Dias, Evan Mays, Benjamin Kinsella, Wyatt Thompson, Johannes Heidecke, Amelia Glaese, and Tejal Patwardhan. 2025. PaperBench: Evaluating AI’s Ability to Replicate AI Research. InProceedings of the 42nd International Conference on Machine Learning, ICML 2025, Vanco...
2025
-
[24]
https://openreview.net/forum?id=xF5PuTLPbn
PMLR / OpenReview.net. https://openreview.net/forum?id=xF5PuTLPbn
-
[25]
Qwen Team. 2025. Qwen3 Technical Report.CoRRabs/2505.09388 (2025). arXiv:2505.09388 doi:10.48550/ARXIV.2505.09388
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388 2025
-
[26]
Amos Tversky and Daniel Kahneman. 1992. Advances in Prospect Theory: Cumulative Representation of Uncertainty.Journal of Risk and Uncertainty5 (1992), 297–323
1992
-
[27]
Hangyu Wang, Jianghao Lin, Xiangyang Li, Bo Chen, Chenxu Zhu, Ruiming Tang, Weinan Zhang, and Yong Yu. 2024. FLIP: Fine-grained Alignment between ID- based Models and Pretrained Language Models for CTR Prediction. InProceedings of the 18th ACM Conference on Recommender Systems, RecSys 2024, Bari, Italy, October 14-18, 2024. ACM, 94–104. https://doi.org/10...
-
[28]
Zheng Wang, Bingzheng Gan, and Wei Shi. 2024. Multimodal Query Suggestion with Multi-Agent Reinforcement Learning from Human Feedback. InProceedings of the ACM Web Conference 2024, WWW 2024, Singapore, May 13-17, 2024, Tat- Seng Chua, Chong-Wah Ngo, Ravi Kumar, Hady W. Lauw, and Roy Ka-Wei Lee (Eds.). ACM, 1374–1385. https://doi.org/10.1145/3589334.3645365
-
[29]
Wei Wei, Xubin Ren, Jiabin Tang, Qinyong Wang, Lixin Su, Suqi Cheng, Junfeng Wang, Dawei Yin, and Chao Huang. 2024. LLMRec: Large Language Models with Graph Augmentation for Recommendation. InProceedings of the 17th ACM International Conference on Web Search and Data Mining, WSDM 2024, Merida, Mexico, March 4-8, 2024. ACM, 806–815. https://doi.org/10.1145...
-
[30]
Stewart Whiting and Joemon M. Jose. 2014. Recent and Robust Query Auto- Completion. InProceedings of the ACM Web Conference 2014, WWW 2014, Seoul, Republic of Korea, April 7-11, 2014. ACM, 971–982. https://doi.org/10.1145/2566486. 2568009
-
[31]
Yueqing Xuan, Kacper Sokol, Mark Sanderson, and Jeffrey Chan. 2025. Evalu- ating and Addressing Fairness Across User Groups in Negative Sampling for Recommender Systems. InProceedings of the 34th ACM International Conference on Information and Knowledge Management, CIKM 2025, Seoul, Republic of Korea, November 10-14, 2025. ACM, 3720–3729. doi:10.1145/3746...
-
[32]
Junhao Yin, Haolin Wang, Peng Bao, Ju Xu, and Yongliang Wang. 2026. From Clicks to Preference: A Multi-stage Alignment Framework for Generative Query Suggestion in Conversational System. InProceedings of the 32nd ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.1, KDD 2026, Jeju Island, Republic of Korea, August 09–13, 2026. ACM. https://doi...
-
[33]
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou. 2025. Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models.CoRRabs/2506.05176 (2025). arXiv:2506.05176 doi:10.48550/ARXIV.2506.05176
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.05176 2025
-
[34]
Jianling Zhong, Weiwei Guo, Huiji Gao, and Bo Long. 2020. Personalized Query Suggestions. InProceedings of the 43rd International ACM SIGIR Conference on Re- search and Development in Information Retrieval, SIGIR 2020, Virtual Event, China, July 25-30, 2020. ACM, 1645–1648. https://doi.org/10.1145/3397271.3401331
-
[35]
Lianghui Zhu, Xinggang Wang, and Xinlong Wang. 2025. JudgeLM: Fine-tuned Large Language Models are Scalable Judges. InProceedings of the 13th Interna- tional Conference on Learning Representations, ICLR 2025, Singapore, Apr 24–28,
2025
-
[36]
https://openreview.net/forum?id=xsELpEPn4A
OpenReview.net. https://openreview.net/forum?id=xsELpEPn4A
-
[37]
Yaochen Zhu, Harald Steck, Dawen Liang, Yinhan He, Vito Claudio Ostuni, Jundong Li, and Nathan Kallus. 2026. Rank-GRPO: Training LLM-based Conver- sational Recommender Systems with Reinforcement Learning. InProceedings of the 14th International Conference on Learning Representations, ICLR 2026, Rio de Janeiro, Brazil, April 23-27, 2026. https://openreview...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.