ShuntServe: Cost-Efficient LLM Serving on Heterogeneous Spot GPU Clusters
Pith reviewed 2026-06-26 19:52 UTC · model grok-4.3
The pith
ShuntServe optimizes LLM placement across mixed spot GPUs with a roofline estimator and dynamic programming to raise throughput and cut costs versus on-demand instances.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
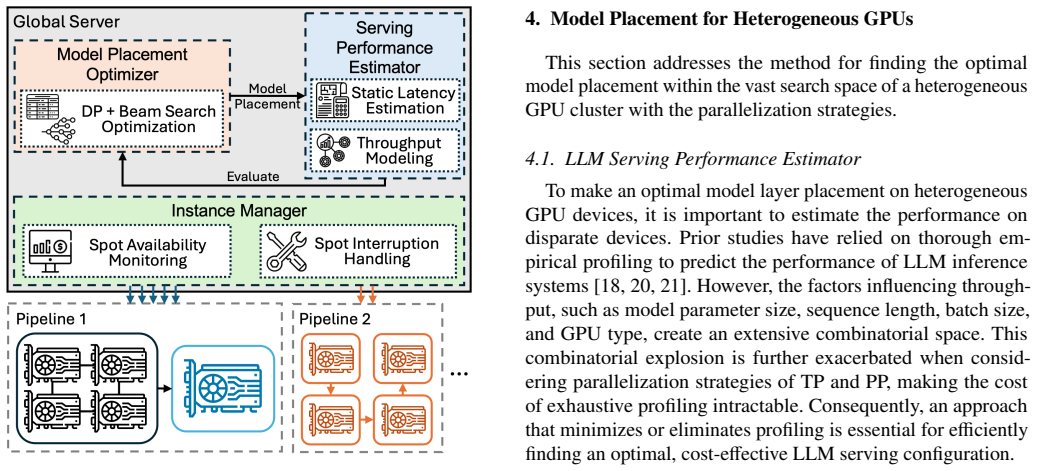
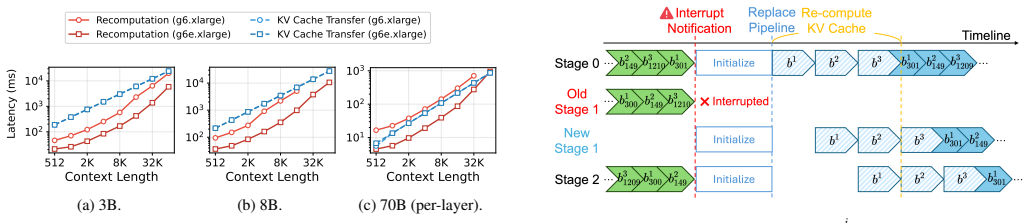
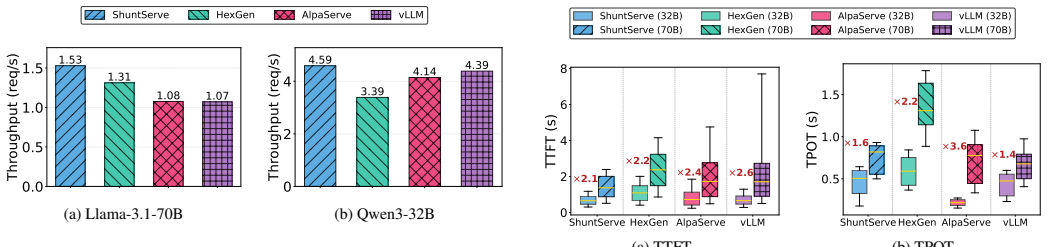
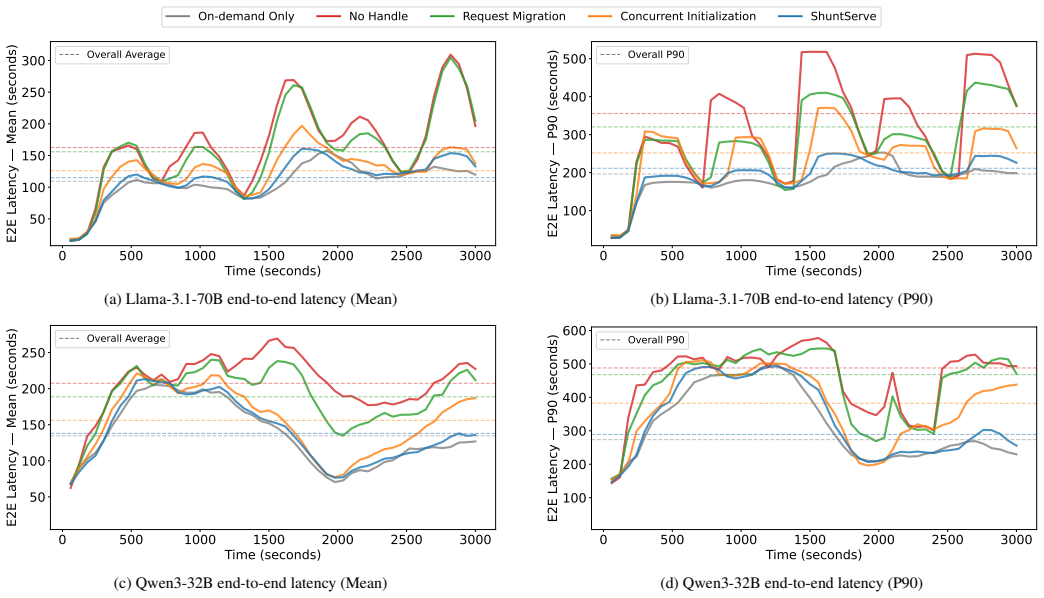
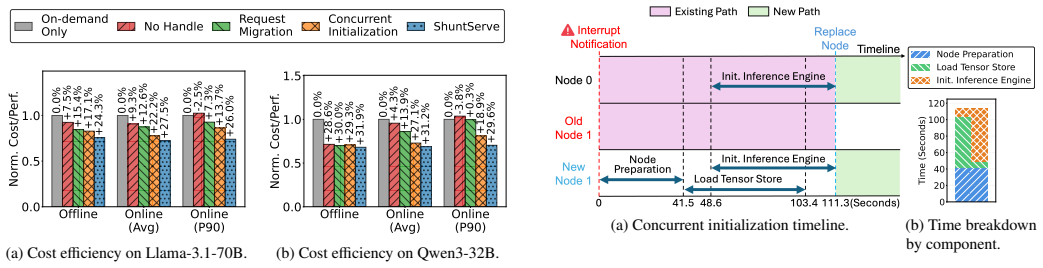
ShuntServe employs a roofline model-based analytical serving performance estimator and a dynamic programming-based model placement optimizer that jointly determines node configuration, parallelization strategy, and layer assignment to maximize throughput across heterogeneous GPUs. It combines output-preserving request migration with concurrent initialization via a shared tensor store to minimize migration downtime. Evaluation on Llama-3.1-70B and Qwen3-32B with a heterogeneous AWS cluster of L4, A10G, and L40S GPUs shows that ShuntServe achieves 1.42x and 1.35x higher throughput than state-of-the-art baselines and attains 31.9 percent and 31.2 percent cost efficiency improvements over on-dem
What carries the argument
Roofline model-based analytical serving performance estimator paired with dynamic programming optimizer that selects node configuration, parallelization strategy, and layer assignment for heterogeneous spot GPUs.
If this is right
- LLM serving can use heterogeneous spot pools to reach higher throughput than homogeneous baselines while retaining fault tolerance.
- Cost efficiency for both offline and online workloads improves by roughly 31 percent relative to on-demand instances.
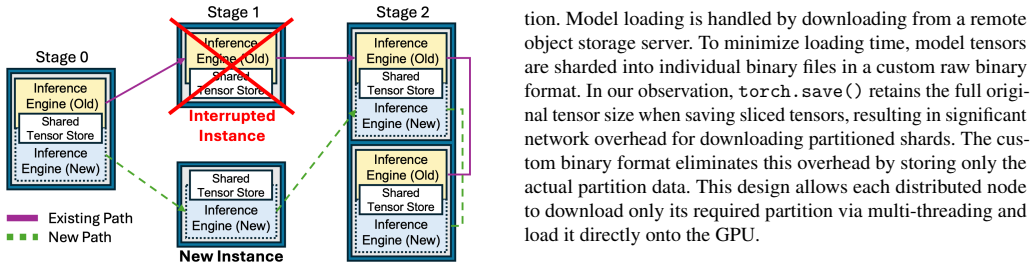
- Output-preserving migration overlapped with shared-tensor-store initialization keeps serving interruptions short when spot instances are reclaimed.
- Complementary availability across GPU types reduces exposure to correlated spot failures.
Where Pith is reading between the lines
- The same optimizer could be applied to other cloud regions whose spot pools exhibit different availability correlations.
- Extending the placement logic to co-locate multiple models on the same heterogeneous nodes might further raise utilization.
- Adding a lightweight predictor of upcoming spot reclamation events could let the migration logic act earlier and reduce tail latency.
Load-bearing premise
The roofline estimator combined with the dynamic programming optimizer can identify configurations that actually deliver the highest real-world throughput on heterogeneous spot GPUs.
What would settle it
Deploy ShuntServe on the L4-A10G-L40S AWS cluster, measure sustained throughput for Llama-3.1-70B under the optimizer's chosen placement, and compare it to the throughput the estimator predicted; a gap larger than measurement noise would falsify the claim.
Figures


read the original abstract
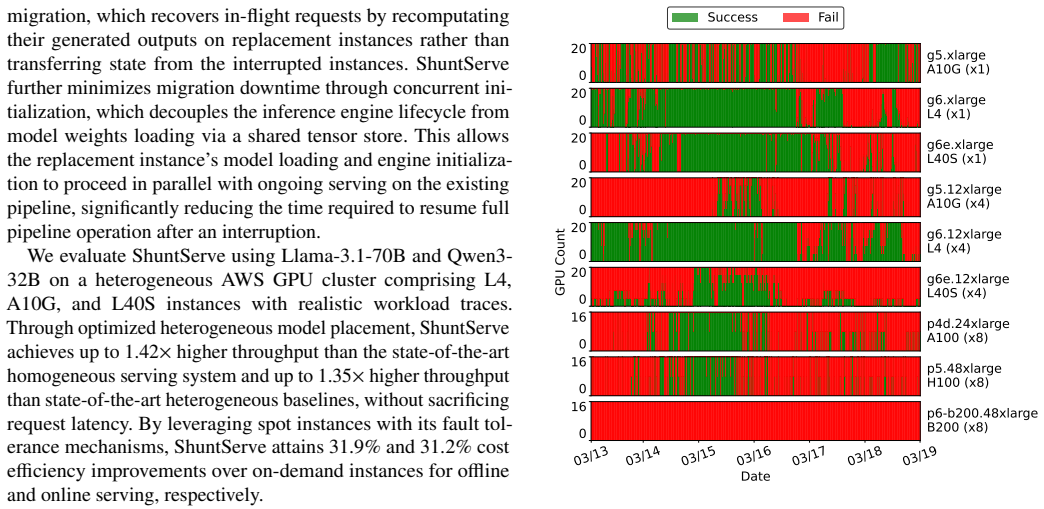
As large language model (LLM) services become widely adopted, the cost of GPU resources for serving these models in cloud environments has emerged as a critical concern. Spot instances offer up to 90% cost savings over on-demand instances, but their frequent interruptions and limited availability pose significant challenges for continuous LLM serving. GPU spot instances, in particular, exhibit lower and more volatile availability than CPU-based instances, making homogeneous clusters that depend on a single GPU type vulnerable to correlated failures. Heterogeneous clusters spanning multiple GPU types can address this by leveraging complementary availability patterns across diverse spot pools, yet existing LLM serving systems are designed for homogeneous environments and suffer from load imbalance when deployed on heterogeneous GPUs. This paper presents ShuntServe, a cost-efficient LLM serving system for heterogeneous spot GPU clusters. ShuntServe employs a roofline model-based analytical serving performance estimator and a dynamic programming-based model placement optimizer that jointly determines node configuration, parallelization strategy, and layer assignment to maximize throughput across heterogeneous GPUs. To enhance fault tolerance when using spot instances, ShuntServe combines output-preserving request migration with concurrent initialization via a shared tensor store, minimizing migration downtime by overlapping replacement node preparation with ongoing serving. Evaluation on Llama-3.1-70B and Qwen3-32B with a heterogeneous AWS cluster of L4, A10G, and L40S GPUs shows that ShuntServe achieves 1.42x and 1.35x higher throughput than state-of-the-art baselines and attains 31.9% and 31.2% cost efficiency improvements over on-demand instances for offline and online serving, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ShuntServe, a system for cost-efficient LLM serving on heterogeneous spot GPU clusters. It uses a roofline model-based analytical serving performance estimator combined with a dynamic programming optimizer to jointly select node configurations, parallelization strategies, and layer assignments across GPU types (L4, A10G, L40S). Fault tolerance is provided via output-preserving request migration overlapped with concurrent initialization through a shared tensor store. On Llama-3.1-70B and Qwen3-32B, the system reports 1.42× and 1.35× higher throughput than state-of-the-art baselines together with 31.9% and 31.2% cost-efficiency gains versus on-demand instances for offline and online workloads.
Significance. If the empirical claims hold after proper validation, the work is significant because it directly targets the tension between the high cost of on-demand GPUs and the unreliability of spot instances for continuous LLM inference. By exploiting complementary availability across heterogeneous spot pools and providing an analytical placement optimizer, the approach could materially lower production serving costs while maintaining service continuity; the combination of roofline modeling and DP optimization is a concrete technical contribution worth disseminating if the predictions are shown to be accurate.
major comments (3)
- [Evaluation section] Evaluation section (presumably §5): the reported 1.42×/1.35× throughput gains and 31.9%/31.2% cost improvements are presented without any description of the exact baselines, workload traces (request rates, input/output lengths, batching policy), number of experimental repetitions, or error bars. This absence prevents assessment of whether the gains are statistically robust or sensitive to particular test conditions.
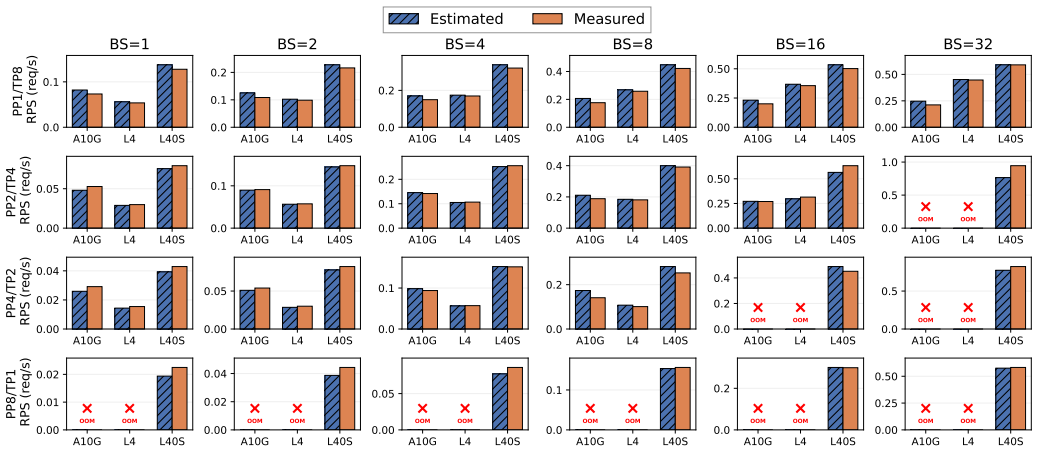
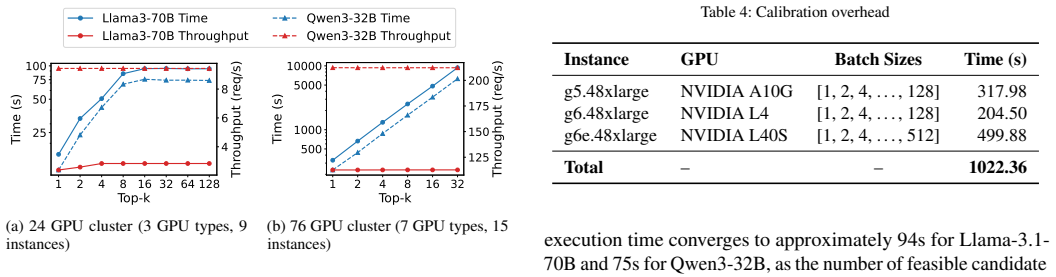
- [§3] §3 (roofline estimator and DP optimizer): the central claim that the joint analytical estimator + DP optimizer produces placements that maximize real throughput rests on the assumption that roofline predictions accurately reflect measured performance on heterogeneous GPUs. No explicit comparison of predicted versus observed throughput for the chosen heterogeneous configurations is described; if unmodeled effects (PCIe/NVLink variability, spot jitter, migration overhead) cause systematic over-prediction, the optimizer is optimizing the wrong objective and the headline gains may not generalize.
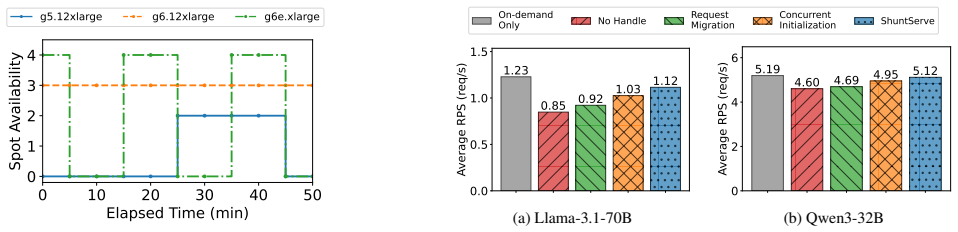
- [§4] Fault-tolerance mechanism (§4): the output-preserving migration and shared-tensor-store initialization are presented as minimizing downtime, yet no quantitative breakdown of migration latency, throughput degradation during replacement, or fraction of requests affected is provided. Without these numbers it is impossible to determine whether the fault-tolerance overhead offsets the reported throughput and cost advantages under realistic spot-interruption rates.
minor comments (2)
- [§3.1] Notation for the roofline parameters (compute intensity, memory bandwidth per GPU type) should be defined once in a table rather than scattered across equations.
- [Abstract] The abstract states evaluation results but omits any mention of baselines or statistical details; the same information should appear in the abstract for readers who stop there.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important areas for improving clarity and rigor in the evaluation and technical sections. We will revise the manuscript to provide the requested details on baselines, workloads, model validation, and fault-tolerance metrics. Our responses to each major comment follow.
read point-by-point responses
-
Referee: [Evaluation section] Evaluation section (presumably §5): the reported 1.42×/1.35× throughput gains and 31.9%/31.2% cost improvements are presented without any description of the exact baselines, workload traces (request rates, input/output lengths, batching policy), number of experimental repetitions, or error bars. This absence prevents assessment of whether the gains are statistically robust or sensitive to particular test conditions.
Authors: We agree that these details are essential for reproducibility and statistical assessment. The revised §5 will include: (1) explicit descriptions of all baselines (including their configurations on homogeneous vs. heterogeneous clusters); (2) workload traces with specific request rates, input/output length distributions, and batching policies used; (3) results from 5 independent repetitions with standard error bars. These additions will be incorporated without altering the reported gains. revision: yes
-
Referee: §3 (roofline estimator and DP optimizer): the central claim that the joint analytical estimator + DP optimizer produces placements that maximize real throughput rests on the assumption that roofline predictions accurately reflect measured performance on heterogeneous GPUs. No explicit comparison of predicted versus observed throughput for the chosen heterogeneous configurations is described; if unmodeled effects (PCIe/NVLink variability, spot jitter, migration overhead) cause systematic over-prediction, the optimizer is optimizing the wrong objective and the headline gains may not generalize.
Authors: The comment correctly identifies a gap: the manuscript does not present a direct predicted-vs-measured comparison for the heterogeneous configurations chosen by the DP optimizer. We will add this validation in the revised §3 (new subsection and figure) using the experimental data already collected during system development. This will quantify prediction error and discuss any observed impact from interconnect variability or jitter, allowing readers to assess the estimator's fidelity. revision: yes
-
Referee: Fault-tolerance mechanism (§4): the output-preserving migration and shared-tensor-store initialization are presented as minimizing downtime, yet no quantitative breakdown of migration latency, throughput degradation during replacement, or fraction of requests affected is provided. Without these numbers it is impossible to determine whether the fault-tolerance overhead offsets the reported throughput and cost advantages under realistic spot-interruption rates.
Authors: We agree that quantitative overhead measurements are required to substantiate the fault-tolerance claims. The revised §4 will include: measured migration latency, observed throughput degradation during node replacement, and the fraction of requests affected, obtained under controlled interruption rates matching AWS spot behavior. These metrics will be reported alongside the main results to allow direct comparison against the throughput and cost gains. revision: yes
Circularity Check
No significant circularity; empirical claims rest on measured throughput, not model self-reference
full rationale
The paper's central claims (1.42×/1.35× throughput gains and 31.9%/31.2% cost improvements) are presented as results of real-system evaluation on Llama-3.1-70B and Qwen3-32B across L4/A10G/L40S spot instances. The roofline estimator and DP optimizer are described as tools to select configurations, but the reported numbers derive from hardware measurements rather than any fitted parameter or analytical output being redefined as the result. No equations, self-citations, or uniqueness theorems are shown that would reduce the outcome to its own inputs by construction. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Llama Team, AI @ Meta, “The llama 3 herd of models,” 2024. [Online]. Available: https://arxiv.org/abs/2407.21783
Pith/arXiv arXiv 2024
-
[2]
C. Wang, Q. Liang, and B. Urgaonkar, “An empirical analysis of amazon ec2 spot instance features affecting cost-effective resource procurement,” inProceedings of the 8th ACM/SPEC on International Conference on Performance Engineering, ser. ICPE ’17. New York, NY , USA: Association for Computing Machinery, 2017, p. 63–74. [Online]. Available: https://doi.o...
-
[3]
Characterizing spot price dynamics in public cloud environments,
B. Javadi, R. K. Thulasiram, and R. Buyya, “Characterizing spot price dynamics in public cloud environments,”Future Generation Computer Systems, vol. 29, no. 4, pp. 988–999, 2013, special Section: Utility and Cloud Computing. [Online]. Available: https: //www.sciencedirect.com/science/article/pii/S0167739X12001483 16
2013
-
[4]
Multi-node spot in- stances availability score collection system,
S. Cheon, K. Kim, K. Kim, M. Song, and K. Lee, “Multi-node spot in- stances availability score collection system,” inProceedings of the 34th International Symposium on High-Performance Parallel and Distributed Computing, ser. HPDC ’25. New York, NY , USA: Association for Com- puting Machinery, 2025, pp. 33:1–33:2
2025
-
[5]
Making cloud spot instance interruption events visible,
K. Kim and K. Lee, “Making cloud spot instance interruption events visible,” inProceedings of the ACM on Web Conference 2024, ser. WWW ’24. New York, NY , USA: Association for Computing Machinery, 2024, p. 2998–3009. [Online]. Available: https://doi.org/10.1145/3589334.3645548
-
[6]
Spotlake: Diverse spot instance dataset archive service,
S. Lee, J. Hwang, and K. Lee, “Spotlake: Diverse spot instance dataset archive service,” in2022 IEEE International Symposium on Workload Characterization (IISWC). Los Alamitos, CA, USA: IEEE Computer Society, nov 2022, pp. 242–255. [Online]. Available: https://doi.ieeecomputersociety.org/10.1109/IISWC55918.2022.00029
-
[7]
Public spot instance dataset archive service,
K. Kim, S. Park, J. Hwang, H. Lee, S. Kang, and K. Lee, “Public spot instance dataset archive service,” inCompanion Proceedings of the ACM Web Conference 2023, ser. WWW ’23 Companion. New York, NY , USA: Association for Computing Machinery, 2023, p. 69–72. [Online]. Available: https://doi.org/10.1145/3543873.3587314
-
[8]
DistServe: Disaggregating prefill and decoding for goodput-optimized large language model serving,
Y . Zhong, S. Liu, J. Chen, J. Hu, Y . Zhu, X. Liu, X. Jin, and H. Zhang, “DistServe: Disaggregating prefill and decoding for goodput-optimized large language model serving,” in18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). Santa Clara, CA: USENIX Association, Jul. 2024, pp. 193–210. [Online]. Available: https://www.usenix...
2024
-
[9]
Realizing the amd exascale heterogeneous processor vision,
P. Patel, E. Choukse, C. Zhang, A. Shah, I. n. Goiri, S. Maleki, and R. Bianchini, “Splitwise: Efficient generative llm inference using phase splitting,” inProceedings of the 51st Annual International Symposium on Computer Architecture, ser. ISCA ’24. IEEE Press, 2025, p. 118–132. [Online]. Available: https://doi.org/10.1109/ISCA59077.2024.00019
-
[10]
Thunderserve: High-performance and cost-efficient llm serving in cloud environments,
Y . Jiang, F. Fu, X. Yao, T. Wang, B. Cui, A. Klimovic, and E. Yoneki, “Thunderserve: High-performance and cost-efficient llm serving in cloud environments,” 2025. [Online]. Available: https://arxiv.org/abs/2502.09334
arXiv 2025
-
[11]
Demystifying cost-efficiency in LLM serving over heterogeneous GPUs,
Y . Jiang, F. Fu, X. Yao, G. He, X. Miao, A. Klimovic, B. Cui, B. Yuan, and E. Yoneki, “Demystifying cost-efficiency in LLM serving over heterogeneous GPUs,” inProceedings of the 42nd International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, A. Singh, M. Fazel, D. Hsu, S. Lacoste-Julien, F. Berkenkamp, T. Maharaj, K. Wag...
-
[12]
27 534–27 552
PMLR, 13–19 Jul 2025, pp. 27 534–27 552. [Online]. Available: https://proceedings.mlr.press/v267/jiang25c.html
2025
-
[13]
Scaling laws for neural language models,
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei, “Scaling laws for neural language models,” 2020. [Online]. Available: https: //arxiv.org/abs/2001.08361
Pith/arXiv arXiv 2020
-
[14]
Scaling laws for autoregressive generative modeling,
T. Henighan, J. Kaplan, M. Katz, M. Chen, C. Hesse, J. Jackson, H. Jun, T. B. Brown, P. Dhariwal, S. Gray, C. Hallacy, B. Mann, A. Radford, A. Ramesh, N. Ryder, D. M. Ziegler, J. Schulman, D. Amodei, and S. McCandlish, “Scaling laws for autoregressive generative modeling,”
-
[15]
Available: https://arxiv.org/abs/2010.14701
[Online]. Available: https://arxiv.org/abs/2010.14701
Pith/arXiv arXiv 2010
-
[16]
Efficient large-scale language model training on gpu clusters using megatron-lm
D. Narayanan, M. Shoeybi, J. Casper, P. LeGresley, M. Patwary, V . Korthikanti, D. Vainbrand, P. Kashinkunti, J. Bernauer, B. Catanzaro, A. Phanishayee, and M. Zaharia, “Efficient large-scale language model training on gpu clusters using megatron-lm,” inProceedings of the International Conference for High Performance Computing, Networking, Storage and Ana...
-
[17]
Huang, Y
Y . Huang, Y . Cheng, A. Bapna, O. Firat, M. X. Chen, D. Chen, H. Lee, J. Ngiam, Q. V . Le, Y . Wu, and Z. Chen,GPipe: efficient training of giant neural networks using pipeline parallelism. Red Hook, NY , USA: Curran Associates Inc., 2019
2019
-
[18]
Cutting the cost of hosting online services using cloud spot markets,
X. He, P. Shenoy, R. Sitaraman, and D. Irwin, “Cutting the cost of hosting online services using cloud spot markets,” inProceedings of the 24th International Symposium on High-Performance Parallel and Distributed Computing, ser. HPDC ’15. New York, NY , USA: Association for Computing Machinery, 2015, p. 207–218. [Online]. Available: https://doi.org/10.114...
-
[19]
Spotweb: Running latency-sensitive distributed web services on transient cloud servers,
A. Ali-Eldin, J. Westin, B. Wang, P. Sharma, and P. Shenoy, “Spotweb: Running latency-sensitive distributed web services on transient cloud servers,” inProceedings of the 28th International Symposium on High-Performance Parallel and Distributed Computing, ser. HPDC ’19. New York, NY , USA: Association for Computing Machinery, 2019, p. 1–12. [Online]. Avai...
-
[20]
Helix: Serving large language models over heterogeneous gpus and network via max-flow,
Y . Mei, Y . Zhuang, X. Miao, J. Yang, Z. Jia, and R. Vinayak, “Helix: Serving large language models over heterogeneous gpus and network via max-flow,” inProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1, ser. ASPLOS ’25. New York, NY , USA: Association for Computing Mac...
-
[21]
Hexgen: gener- ative inference of large language model over heterogeneous environment,
Y . Jiang, R. Yan, X. Yao, Y . Zhou, B. Chen, and B. Yuan, “Hexgen: gener- ative inference of large language model over heterogeneous environment,” inProceedings of the 41st International Conference on Machine Learning, ser. ICML’24. JMLR.org, 2024
2024
-
[22]
Vidur: A large-scale simulation framework for llm inference,
A. Agrawal, N. Kedia, J. Mohan, A. Panwar, N. Kwatra, B. S. Gulavani, R. Ramjee, and A. Tumanov, “Vidur: A large-scale simulation framework for llm inference,” inProceedings of Machine Learning and Systems, P. Gibbons, G. Pekhimenko, and C. D. Sa, Eds., vol. 6, 2024, pp. 351–366. [Online]. Available: https://proceedings.mlsys.org/paper files/paper/2024/ f...
2024
-
[23]
AlpaServe: Statistical multiplexing with model parallelism for deep learning serving,
Z. Li, L. Zheng, Y . Zhong, V . Liu, Y . Sheng, X. Jin, Y . Huang, Z. Chen, H. Zhang, J. E. Gonzalez, and I. Stoica, “AlpaServe: Statistical multiplexing with model parallelism for deep learning serving,” in17th USENIX Symposium on Operating Systems Design and Implementation (OSDI 23). Boston, MA: USENIX Association, Jul. 2023, pp. 663–679. [Online]. Avai...
2023
-
[24]
S. Williams, A. Waterman, and D. Patterson, “Roofline: an insightful visual performance model for multicore architectures,”Commun. ACM, vol. 52, no. 4, p. 65–76, Apr. 2009. [Online]. Available: https://doi.org/10.1145/1498765.1498785
-
[25]
Hierarchical roofline performance analysis for deep learning applications,
C. Yang, Y . Wang, S. Farrell, T. Kurth, and S. Williams, “Hierarchical roofline performance analysis for deep learning applications,” 2020. [Online]. Available: https://arxiv.org/abs/2009.05257
arXiv 2020
-
[26]
The communication challenge for mpp: Intel paragon and meiko cs-2,
R. W. Hockney, “The communication challenge for mpp: Intel paragon and meiko cs-2,”Parallel Computing, vol. 20, no. 3, pp. 389–398, 1994. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0 167819106800219
1994
-
[27]
Improving the performance of collective operations in mpich,
R. Thakur and W. D. Gropp, “Improving the performance of collective operations in mpich,” inRecent Advances in Parallel Virtual Machine and Message Passing Interface, J. Dongarra, D. Laforenza, and S. Orlando, Eds. Berlin, Heidelberg: Springer Berlin Heidelberg, 2003, pp. 257–267
2003
-
[28]
Demystifying NCCL: An In-depth Analysis of GPU Communication Protocols and Algorithms,
Z. Hu, S. Shen, T. Bonato, S. Jeaugey, C. Alexander, E. Spada, J. Dinan, J. Hammond, and T. Hoefler, “Demystifying NCCL: An In-depth Analysis of GPU Communication Protocols and Algorithms,” inProceedings of the 32nd Annual Symposium on High-Performance Interconnects (HOTI’25). IEEE Press, 08 2025
2025
-
[29]
Habitat: A Runtime- Based computational performance predictor for deep neural network training,
G. X. Yu, Y . Gao, P. Golikov, and G. Pekhimenko, “Habitat: A Runtime- Based computational performance predictor for deep neural network training,” in2021 USENIX Annual Technical Conference (USENIX ATC 21). USENIX Association, Jul. 2021, pp. 503–521. [Online]. Available: https://www.usenix.org/conference/atc21/presentation/yu
2021
-
[30]
FlashAttention-2: Faster attention with better parallelism and work partitioning,
T. Dao, “FlashAttention-2: Faster attention with better parallelism and work partitioning,” inInternational Conference on Learning Representa- tions (ICLR), 2024
2024
-
[31]
Sequence transduction with recurrent neural networks,
A. Graves, “Sequence transduction with recurrent neural networks,” 2012. [Online]. Available: https://arxiv.org/abs/1211.3711
Pith/arXiv arXiv 2012
-
[32]
Sequence to sequence learning with neural networks,
I. Sutskever, O. Vinyals, and Q. V . Le, “Sequence to sequence learning with neural networks,” inProceedings of the 28th International Confer- ence on Neural Information Processing Systems - Volume 2, ser. NIPS’14. Cambridge, MA, USA: MIT Press, 2014, p. 3104–3112
2014
-
[33]
Proceedings of the 29th Symposium on Operating Systems Principles , pages =
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. Gonzalez, H. Zhang, and I. Stoica, “Efficient memory management for large language model serving with pagedattention,” inProceedings of the 29th Symposium on Operating Systems Principles, ser. SOSP ’23. New York, NY , USA: Association for Computing Machinery, 2023, p. 611–626. [Online]. Availabl...
-
[34]
Lean attention: Hardware-aware scalable attention mechanism for the decode- phase of transformers,
R. Sanovar, S. Bharadwaj, R. S. Amant, V . R¨uhle, and S. Rajmohan, “Lean attention: Hardware-aware scalable attention mechanism for the decode- phase of transformers,” inProceedings of Machine Learning and Systems, vol. 7, 2025. 17
2025
-
[35]
Characterizing power management opportunities for llms in the cloud,
P. Patel, E. Choukse, C. Zhang, I. n. Goiri, B. Warrier, N. Mahalingam, and R. Bianchini, “Characterizing power management opportunities for llms in the cloud,” inProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3, ser. ASPLOS ’24. New York, NY , USA: Association for Comp...
-
[36]
TensorRT-LLM: A library for accelerating large language model inference,
NVIDIA, “TensorRT-LLM: A library for accelerating large language model inference,” GitHub repository, 2023, accessed: 2025-10-30. [Online]. Available: https://github.com/NVIDIA/TensorRT-LLM
2023
-
[37]
Ray: a distributed framework for emerging ai applications,
P. Moritz, R. Nishihara, S. Wang, A. Tumanov, R. Liaw, E. Liang, M. Eli- bol, Z. Yang, W. Paul, M. I. Jordan, and I. Stoica, “Ray: a distributed framework for emerging ai applications,” inProceedings of the 13th USENIX Conference on Operating Systems Design and Implementation, ser. OSDI’18. USA: USENIX Association, 2018, p. 561–577
2018
-
[38]
Q. Team, “Qwen3 technical report,” 2025. [Online]. Available: https://arxiv.org/abs/2505.09388
Pith/arXiv arXiv 2025
-
[39]
X. Miao, C. Shi, J. Duan, X. Xi, D. Lin, B. Cui, and Z. Jia, “Spotserve: Serving generative large language models on preemptible instances,” inProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, ser. ASPLOS ’24. New York, NY , USA: Association for Computing Machinery, 202...
-
[40]
Skyserve: Serving ai models across regions and clouds with spot instances,
Z. Mao, T. Xia, Z. Wu, W.-L. Chiang, T. Griggs, R. Bhardwaj, Z. Yang, S. Shenker, and I. Stoica, “Skyserve: Serving ai models across regions and clouds with spot instances,” inProceedings of the Twentieth European Conference on Computer Systems, ser. EuroSys ’25. New York, NY , USA: Association for Computing Machinery, 2025, p. 159–175. [Online]. Availabl...
-
[41]
Bamboo: Making preemptible instances resilient for affordable training of large DNNs,
J. Thorpe, P. Zhao, J. Eyolfson, Y . Qiao, Z. Jia, M. Zhang, R. Netravali, and G. H. Xu, “Bamboo: Making preemptible instances resilient for affordable training of large DNNs,” in20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23). Boston, MA: USENIX Association, Apr. 2023, pp. 497–513. [Online]. Available: https://www.usenix.or...
2023
-
[42]
Parcae: Proactive, Liveput-Optimized DNN training on preemptible instances,
J. Duan, Z. Song, X. Miao, X. Xi, D. Lin, H. Xu, M. Zhang, and Z. Jia, “Parcae: Proactive, Liveput-Optimized DNN training on preemptible instances,” in21st USENIX Symposium on Networked Systems Design and Implementation (NSDI 24). Santa Clara, CA: USENIX Association, Apr. 2024, pp. 1121–1139. [Online]. Available: https://www.usenix.org/conference/nsdi24/p...
2024
-
[43]
D. Liakopoulos, P. Sinha, T. Hu, M. Lee, and N. J. Yadwadkar, “Maveriq: Fingerprint-guided extrapolation and fragmentation-aware layering for intent-based llm serving,” inProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, ser. SC ’25. New York, NY , USA: Association for Computing Machinery, 2025, ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.