Not Your Usual FFT: QFTrightarrowFFT via Classical Quantum-Circuit Simulation
Pith reviewed 2026-06-26 18:30 UTC · model grok-4.3
The pith
Classical simulation of QFT circuits computes the discrete Fourier transform as a drop-in FFT replacement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
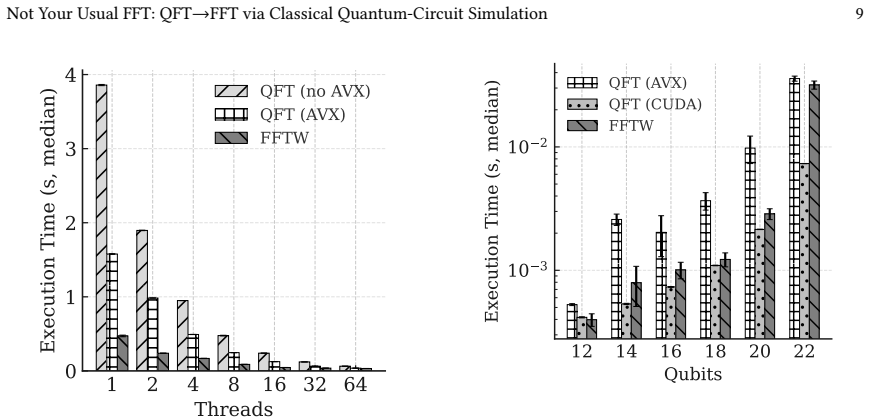
By mapping input arrays directly to normalized state amplitudes with explicit indexing and executing the QFT circuit through a fused-gate schedule on classical simulators, the QFT→FFT approach computes the discrete Fourier transform and delivers over 4× lower runtime on the CUDA backend than AVX or FFTW on AMD EPYC Zen2 at larger problem sizes.
What carries the argument
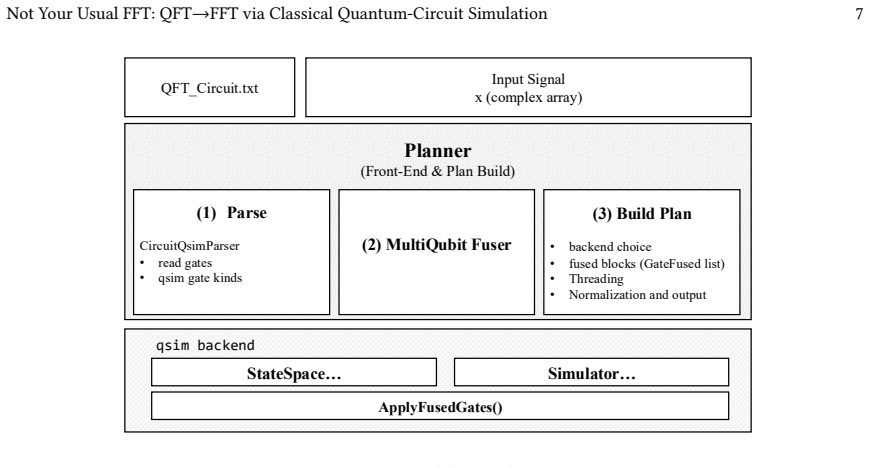
The QFT→FFT mapping that treats input arrays as quantum state amplitudes together with the backend-agnostic planner that builds fused-gate schedules and memory-layout adapters.
If this is right
- The AVX backend matches the performance of 64-thread FFTW on AMD EPYC Zen2.
- The CUDA backend achieves more than 4× lower time than both AVX and FFTW on AMD EPYC Zen2 at larger sizes.
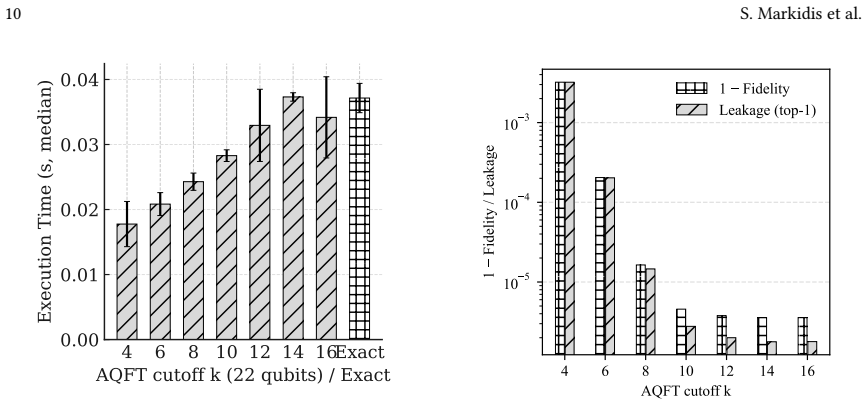
- Truncating small-angle controlled rotations in the approximate QFT reduces circuit depth and runtime while preserving accuracy.
- The planner produces a fused-gate schedule that increases arithmetic intensity and reduces memory data movement across backends.
Where Pith is reading between the lines
- The same amplitude-mapping technique could be applied to other quantum algorithms whose classical simulation might yield new classical primitives.
- Hybrid codes could switch between direct FFT calls and QFT simulation depending on hardware and problem size without changing the calling interface.
- Further reductions in simulation overhead might appear when the planner is extended to exploit additional GPU-specific memory hierarchies.
Load-bearing premise
Mapping input arrays directly to normalized state amplitudes lets the QFT circuit simulation act as an accurate and efficient drop-in replacement for classical FFT without hidden accuracy loss or prohibitive simulation overhead at the tested sizes.
What would settle it
Run the same input arrays through both the QFT→FFT CUDA implementation and a standard FFT library, then compare relative error and wall-clock time; the claim fails if relative error exceeds machine precision or if the 4× runtime advantage on A100 disappears.
Figures
read the original abstract
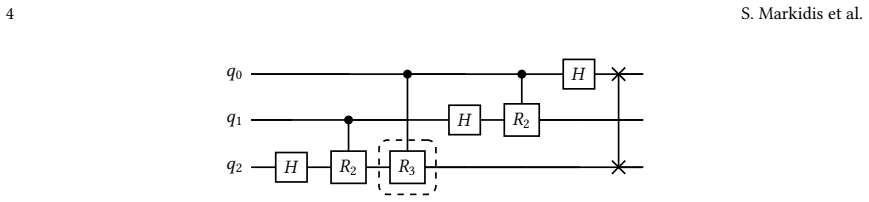
We introduce QFT$\rightarrow$FFT, a family of HPC FFT libraries that compute the discrete Fourier transform by executing a quantum Fourier transform (QFT) circuit on classical quantum computer simulators. Input arrays are mapped directly to state amplitudes with explicit normalization/indexing, making QFT a drop-in replacement for FFT primitives. A backend-agnostic planner builds a fused-gate schedule and memory layout adapters to increase arithmetic intensity and reduce memory data movement. We implement this design on top of Google's C++ \texttt{qsim} and evaluate OpenMP, AVX, and CUDA backends. On an AMD EPYC Zen2 processor, our AVX performance is on par with that of multithreaded FFTW, utilizing 64 threads. On an NVIDIA A100, the CUDA backend achieves more than $4\times$ lower time than both AVX and FFTW on AMD EPYC Zen2 at larger sizes. We also employ an approximate QFT (AQFT) that truncates small-angle controlled rotations beyond a cutoff $k$, reducing circuit depth and runtime while preserving accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces QFT→FFT, a family of HPC FFT libraries that compute the discrete Fourier transform by executing a quantum Fourier transform (QFT) circuit on classical quantum computer simulators. Input arrays are mapped directly to normalized state amplitudes, a backend-agnostic planner builds fused-gate schedules and memory adapters, and implementations on Google's qsim with OpenMP, AVX, and CUDA backends are evaluated. Performance claims include AVX on par with multithreaded FFTW on AMD EPYC Zen2 and CUDA on NVIDIA A100 achieving >4× lower time than AVX/FFTW at larger sizes; an approximate QFT (AQFT) variant is also presented that truncates small-angle rotations.
Significance. If the central claims hold after verification, the work would demonstrate a viable alternative FFT implementation route that reuses quantum-circuit simulation infrastructure, fused-gate planning, and approximation techniques (AQFT) for classical signal processing. The multi-backend design and explicit normalization/indexing mapping are concrete engineering contributions that could be of interest to both quantum simulation and HPC communities.
major comments (2)
- [Abstract] Abstract: the performance claim that 'the CUDA backend achieves more than 4× lower time than both AVX and FFTW on AMD EPYC Zen2 at larger sizes' compares a GPU platform (A100) against a CPU platform (EPYC Zen2), so it does not test whether the QFT-circuit approach incurs lower, equal, or higher overhead than a direct FFT when executed on the same device; this mismatch is load-bearing for the 'efficient drop-in replacement' thesis.
- [Abstract] Abstract: the manuscript states performance numbers and an approximate variant but supplies no error bars, no accuracy verification details (e.g., maximum relative error, L2 norm), no specific problem sizes (N values), and no description of how the explicit normalization/indexing mapping preserves the DFT property; these omissions make the soundness of both the exact and AQFT claims impossible to assess from the provided text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to strengthen clarity and verifiability while preserving the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the performance claim that 'the CUDA backend achieves more than 4× lower time than both AVX and FFTW on AMD EPYC Zen2 at larger sizes' compares a GPU platform (A100) against a CPU platform (EPYC Zen2), so it does not test whether the QFT-circuit approach incurs lower, equal, or higher overhead than a direct FFT when executed on the same device; this mismatch is load-bearing for the 'efficient drop-in replacement' thesis.
Authors: We agree the 4× claim is a cross-platform comparison and does not isolate the QFT-circuit overhead versus a native FFT on identical hardware. The AVX vs. FFTW comparison is performed on the same AMD EPYC Zen2 platform and shows parity. The CUDA result demonstrates the method's performance when leveraging GPU-accelerated qsim. To address the concern, we will revise the abstract and add text clarifying platform distinctions; we will also include same-device GPU comparisons (e.g., against cuFFT on A100) if space and new runs permit. revision: partial
-
Referee: [Abstract] Abstract: the manuscript states performance numbers and an approximate variant but supplies no error bars, no accuracy verification details (e.g., maximum relative error, L2 norm), no specific problem sizes (N values), and no description of how the explicit normalization/indexing mapping preserves the DFT property; these omissions make the soundness of both the exact and AQFT claims impossible to assess from the provided text.
Authors: The full manuscript contains the requested details: specific N values, accuracy metrics (maximum relative error and L2 norms) for both exact and AQFT cases, and an explicit description of the normalization/indexing mapping that preserves DFT equivalence. We acknowledge these elements are absent from the abstract. We will revise the abstract to include concise statements on example N values, error metrics, and a brief note on the mapping, making the claims more self-contained and verifiable. revision: yes
Circularity Check
No circularity; claims are empirical measurements of an implementation
full rationale
The paper describes a software implementation that maps arrays to QFT state amplitudes and measures runtime on specific backends (OpenMP, AVX, CUDA) against FFTW. No mathematical derivation, fitted parameters, or first-principles prediction is presented whose output reduces to the input by construction. Performance numbers are reported as direct timings rather than derived quantities. No self-citation chains, uniqueness theorems, or ansatzes are invoked to justify core results. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2015.Digital signal processing and spectral analysis for scientists: concepts and applications
Silvia Maria Alessio. 2015.Digital signal processing and spectral analysis for scientists: concepts and applications. Springer
2015
-
[2]
Ali Asadi and et al. 2024. Hybrid quantum programming with Pennylane lightning on HPC platforms.arXiv preprint arXiv:2403.02512(2024)
arXiv 2024
-
[3]
Ryo Asaka and et al. 2020. Quantum circuit for the fast Fourier transform.Quantum Information Processing19, 8 (2020), 277
2020
-
[4]
Alan Ayala and et al. 2020. heFFTe: Highly efficient FFT for exascale. InInternational Conference on Computational Science. Springer, 262–275
2020
-
[5]
Harun Bayraktar and et al. 2023. CuQuantum SDK: A high-performance library for accelerating quantum science. In2023 IEEE International Conference on Quantum Computing and Engineering (QCE), Vol. 1. IEEE, 1050–1061
2023
-
[6]
Aleksandr Berezutskii and et al. 2025. Tensor networks for quantum computing.Nature Reviews Physics(2025), 1–13
2025
-
[7]
Daan Camps and et al. 2021. Quantum Fourier transform revisited.Numerical Linear Algebra with Applications28, 1 (2021), e2331
2021
-
[8]
Jielun Chen and et al. 2023. Quantum Fourier transform has small entanglement.PRX Quantum4, 4 (2023), 040318
2023
-
[9]
Don Coppersmith. 2002. An approximate Fourier transform useful in quantum factoring.arXiv preprint quant-ph/0201067(2002)
Pith/arXiv arXiv 2002
-
[10]
Pedro MQ Cruz and et al. 2020. Optimizing quantum phase estimation for the simulation of Hamiltonian eigenstates.Quantum Science and Technology5, 4 (2020), 044005
2020
-
[11]
Artur Ekert and Richard Jozsa. 1998. Quantum algorithms: entanglement–enhanced information processing.Philosophical Transactions of the Royal Society of London. Series A: Mathematical, Physical and Engineering Sciences356, 1743 (1998), 1769–1782
1998
-
[12]
Franz Franchetti and et al. 2005. Efficient utilization of SIMD extensions.Proc. IEEE93, 2 (2005), 409–425
2005
-
[13]
Franz Franchetti and et al. 2006. FFT program generation for shared memory: SMP and multicore. InSC ’06: Proceedings of the 2006 ACM/IEEE Conference on Supercomputing. ACM, Article 115, 12 pages
2006
-
[14]
Franz Franchetti and Markus Puschel. 2003. Short vector code generation for the discrete Fourier transform. InProceedings International Parallel and Distributed Processing Symposium. IEEE, 10–pp
2003
-
[15]
Franz Franchetti and Markus Püschel. 2011. FFT (fast Fourier transform). InEncyclopedia of Parallel Computing. Springer, 658–671
2011
-
[16]
Matteo Frigo and Steven G Johnson. 1998. FFTW: An adaptive software architecture for the FFT. InProceedings of the 1998 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP’98 (Cat. No. 98CH36181), Vol. 3. IEEE, 1381–1384
1998
-
[17]
Amir Gholami and et al. 2015. AccFFT: A library for distributed-memory FFT on CPU and GPU architectures.arXiv preprint arXiv:1506.07933(2015)
Pith/arXiv arXiv 2015
-
[18]
Gian Giacomo Guerreschi and et al. 2020. Intel Quantum Simulator: A cloud-ready high-performance simulator of quantum circuits.Quantum Science and Technology5, 3 (2020), 034007
2020
-
[19]
Torsten Hoefler and et al. 2023. Disentangling hype from practicality: On realistically achieving quantum advantage.Commun. ACM66, 5 (2023), 82–87
2023
-
[20]
Sergei V Isakov and et al. 2021. Simulations of quantum circuits with approximate noise using qsim and Cirq.arXiv preprint arXiv:2111.02396(2021)
arXiv 2021
-
[21]
Nishant Jain and et al. 2024. Quantum Fourier networks for solving parametric PDEs.Quantum Science and Technology9, 3 (2024), 035026
2024
-
[22]
Tyson Jones and et al. 2019. QuEST and high performance simulation of quantum computers.Scientific reports9, 1 (2019), 10736
2019
-
[23]
Bastian Köpcke and et al. 2019. Generating efficient fft gpu code with lift. InProceedings of the 8th ACM SIGPLAN International Workshop on Functional High-Performance and Numerical Computing. 1–13
2019
-
[24]
Binrui Li and et al. 2021. tcfft: A fast half-precision FFT library for NVIDIA tensor cores. In2021 IEEE International Conference on Cluster Computing (CLUSTER). IEEE, 1–11
2021
-
[25]
Fang Xi Lin. 2014. Shor’s algorithm and the quantum Fourier transform.McGill University(2014)
2014
-
[26]
Stefano Markidis. 2024. What is quantum parallelism, anyhow?. InISC High Performance 2024 Research Paper Proceedings (39th International Conference). Prometeus GmbH, 1–12
2024
-
[27]
Damian R Musk. 2020. A comparison of quantum and traditional Fourier transform computations.Computing in Science & Engineering22, 6 (2020), 103–110
2020
-
[28]
Yunseong Nam and et al. 2020. Approximate quantum Fourier transform with O (n log (n)) T gates.NPJ Quantum Information6, 1 (2020), 26
2020
-
[29]
Thien Nguyen and et al. 2022. Tensor network quantum virtual machine for simulating quantum circuits at exascale.ACM Transactions on Quantum Computing4, 1 (2022), 1–21
2022
-
[30]
2010.Quantum computation and quantum information
Michael A Nielsen and Isaac L Chuang. 2010.Quantum computation and quantum information. Cambridge university press
2010
-
[31]
Dmitry Pekurovsky. 2012. P3DFFT: A framework for parallel computations of Fourier transforms in three dimensions.SIAM Journal on Scientific Computing34, 4 (2012), C192–C209
2012
-
[32]
Ben Rudiak-Gould. 2006. The sum-over-histories formulation of quantum computing.arXiv preprint quant-ph/0607151(2006)
Pith/arXiv arXiv 2006
-
[33]
1992.Computational frameworks for the fast Fourier transform
Charles Van Loan. 1992.Computational frameworks for the fast Fourier transform. SIAM
1992
-
[34]
Endong Wang and et al. 2014. Intel math kernel library. InHigh-Performance Computing on the Intel®Xeon Phi™: How to Fully Exploit MIC Architectures. Springer, 167–188
2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.