POEM: Partial-Order Enhanced Real-Time Sequential Modeling for Recommendation
Pith reviewed 2026-06-30 04:32 UTC · model grok-4.3
The pith
POEM constructs dynamic partial-order sequences from upstream ranking scores to capture instant user interest shifts in live recommendation systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
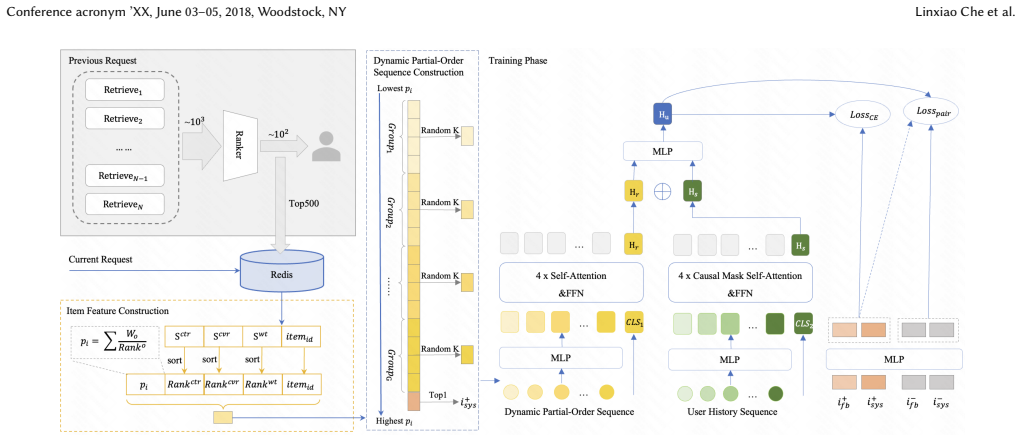
POEM takes real-time multi-task ranking scores as supervision to construct dynamic partial-order sequences, supporting fine-grained real-time interest modeling and consistent optimization between system ranking targets and user behavioral patterns through partial-order guided sequence construction, multi-objective score fusion into quintuples, and hierarchical sample learning that pairs high-ranked and long-duration items as positives with graph-mined hard negatives.
What carries the argument
Partial-order guided sequence construction paradigm that enriches chronological sequences via dynamic grouping and sampling conditioned on real-time ranking scores.
If this is right
- Dynamic grouping and sampling conditioned on ranking scores reassess user interests at each request.
- Normalized rank-aware weighting unifies heterogeneous signals into a compact quintuple representation.
- System-favored high-ranked items paired with long-duration watches serve as positives for pairwise training.
- Graph-mined hard negatives plus margin loss produce more robust training than standard sequential losses.
Where Pith is reading between the lines
- The same supervision-from-ranking approach could be tested in non-video domains where multi-stage cascades exist.
- Gains may depend on the maturity and calibration quality of the upstream ranking modules.
- Extending the quintuple representation to include additional tasks such as like or share prediction is a direct next step.
Load-bearing premise
Real-time multi-task ranking scores can be repurposed directly as reliable supervision to build sequences that reflect user patterns without introducing new biases or inconsistencies.
What would settle it
An online A/B test that disables only the partial-order sequence construction step while retaining the rest of the pipeline and measures whether watch-time lifts disappear.
Figures

read the original abstract
Real-time recommendation systems suffer from the dynamic drift of user interests and varying contextual conditions. Conventional sequential recommendation models only exploit static historical click sequences, which fail to capture instant preference changes and overlook structured signals hidden within the multi-stage ranking pipeline of industrial recommendation systems. To tackle these limitations, we propose POEM (Partial-Order Enhanced Modeling), a new real-time sequential modeling framework built upon intrinsic partial-order relations from the recommendation cascade. POEM takes real-time multi-task ranking scores (including predicted CTR and predicted watch duration) generated by upstream ranking modules as supervision to construct dynamic partial-order sequences, supporting fine-grained real-time interest modeling and consistent optimization between system ranking targets and user behavioral patterns. We summarize our core contributions as three aspects: (1) a partial-order guided sequence construction paradigm, which enriches vanilla chronological sequences via dynamic grouping and sampling conditioned on real-time ranking scores to reassess user interests per request; (2) a multi-objective score fusion module that unifies heterogeneous ranking signals into a compact quintuple representation with normalized rank-aware weighting; (3) a hierarchical sample learning strategy, which adopts system-favored high-ranked items and user positive feedback (e.g., long-duration watched videos) as positive instances, paired with graph-mined hard negatives and a margin-based pairwise loss for robust training. Fully deployed on Kuaishou online traffic, POEM achieves significant online gains: average per-user watch time lifts by 0.249% on the KS Single Page and 0.213% on the KS Lite Page.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes POEM, a real-time sequential recommendation framework that constructs dynamic partial-order sequences by grouping and sampling items using upstream multi-task ranking scores (predicted CTR and watch duration), fuses these into a normalized quintuple representation via rank-aware weighting, and trains with hierarchical positives (high-ranked and long-watch items) plus graph-mined hard negatives under a margin-based pairwise loss. It reports online A/B lifts of 0.249% and 0.213% average per-user watch time on two Kuaishou pages.
Significance. If the online gains are reproducible and the partial-order sequences supply signal beyond the upstream policy, the method offers a deployable way to align sequential modeling with the multi-stage ranking cascade in industrial systems.
major comments (2)
- [Abstract] Abstract: the central claim that upstream CTR/watch-duration scores can be repurposed to construct sequences that 'better reflect user behavioral patterns' without new biases is load-bearing, yet the manuscript provides no comparison (e.g., overlap statistics or ranking correlation) between the constructed partial-order sequences and the original upstream ranking, leaving open the possibility that the reported lifts simply re-encode the production policy.
- [Abstract] Abstract: the online gains are presented without any mention of test duration, user count, statistical significance testing, or ablation isolating the partial-order construction from the fusion and loss components, making it impossible to assess whether the 0.2% lifts are robust or attributable to the proposed mechanisms.
minor comments (1)
- [Abstract] The abstract refers to 'graph-mined hard negatives' without defining the graph construction or mining procedure.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address each major comment below and will revise the manuscript accordingly where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that upstream CTR/watch-duration scores can be repurposed to construct sequences that 'better reflect user behavioral patterns' without new biases is load-bearing, yet the manuscript provides no comparison (e.g., overlap statistics or ranking correlation) between the constructed partial-order sequences and the original upstream ranking, leaving open the possibility that the reported lifts simply re-encode the production policy.
Authors: We agree that a quantitative comparison (e.g., overlap statistics or ranking correlation) between the constructed partial-order sequences and the upstream ranking would help substantiate that the sequences supply additional signal. Section 3.1 describes how dynamic grouping and sampling conditioned on real-time multi-task scores introduce context-dependent reordering not present in the static upstream policy. The online A/B lifts are measured against a baseline sequential model that does not use this construction. To directly address the concern, we will add an analysis of sequence overlap and correlation metrics in the revised manuscript. revision: yes
-
Referee: [Abstract] Abstract: the online gains are presented without any mention of test duration, user count, statistical significance testing, or ablation isolating the partial-order construction from the fusion and loss components, making it impossible to assess whether the 0.2% lifts are robust or attributable to the proposed mechanisms.
Authors: The abstract summarizes the online results without the requested experimental details. The full manuscript reports A/B test outcomes in Section 5, including duration, scale, and significance testing, along with component ablations in Section 4.3. We will revise the abstract to concisely reference test duration, user scale, statistical significance, and the ablation isolating the partial-order construction. This will make the robustness claims self-contained in the abstract while preserving the existing experimental evidence. revision: yes
Circularity Check
No circularity: framework uses upstream scores for sequence construction but validates via independent online A/B tests on watch time
full rationale
The paper describes a framework that constructs partial-order sequences from upstream multi-task ranking scores (CTR and watch duration predictions) and trains with margin-based pairwise loss on system-favored items plus user feedback. However, the central result is measured by online A/B test lifts in per-user watch time (0.249% and 0.213%), an external behavioral metric independent of the input scores. No equations or derivations are provided that reduce any claimed prediction or result to the inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems. The derivation chain is therefore self-contained against external benchmarks and receives score 0.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Sebastian Bruch, Shuguang Han, Michael Bendersky, and Marc Najork. 2020. A stochastic treatment of learning to rank scoring functions. InProceedings of the 13th international conference on web search and data mining. 61–69
2020
-
[2]
Christopher JC Burges. 2010. From ranknet to lambdarank to lambdamart: An overview.Learning11, 23-581 (2010), 81
2010
-
[3]
Jiangxia Cao, Pengbo Xu, Yin Cheng, Kaiwei Guo, Jian Tang, Shijun Wang, Dewei Leng, Shuang Yang, Zhaojie Liu, Yanan Niu, et al. 2025. Pantheon: Personalized multi-objective ensemble sort via iterative pareto policy optimization. InPro- ceedings of the 34th ACM International Conference on Information and Knowledge Management. 5575–5582
2025
-
[4]
Huifeng Guo, Ruiming Tang, Yunming Ye, Zhenguo Li, and Xiuqiang He. 2017. DeepFM: A Factorization-Machine based Neural Network for CTR Prediction. arXiv:1703.04247 [cs.IR] https://arxiv.org/abs/1703.04247
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [5]
-
[6]
Balázs Hidasi, Alexandros Karatzoglou, Linas Baltrunas, and Domonkos Tikk
-
[7]
Session-based recommendations with recurrent neural networks.arXiv preprint arXiv:1511.06939(2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[8]
Po-Sen Huang, Xiaodong He, Jianfeng Gao, Li Deng, Alex Acero, and Larry Heck. 2013. Learning deep structured semantic models for web search using clickthrough data. InProceedings of the 22nd ACM international conference on Information & Knowledge Management. 2333–2338
2013
-
[9]
SeongKu Kang, Wonbin Kweon, Dongha Lee, Jianxun Lian, Xing Xie, and Hwanjo Yu. 2023. Distillation from heterogeneous models for top-K recommendation. In Proceedings of the ACM Web Conference 2023. 801–811
2023
-
[10]
Wang-Cheng Kang and Julian McAuley. 2018. Self-attentive sequential recom- mendation. In2018 IEEE international conference on data mining (ICDM). IEEE, 197–206
2018
-
[11]
Nikhil Khani, Li Wei, Aniruddh Nath, Shawn Andrews, Shuo Yang, Yang Liu, Pendo Abbo, Maciej Kula, Jarrod Kahn, Zhe Zhao, et al. 2024. Bridging the gap: Unpacking the hidden challenges in knowledge distillation for online ranking systems. InProceedings of the 18th ACM Conference on Recommender Systems. 758–761
2024
-
[12]
Yehuda Koren, Robert Bell, and Chris Volinsky. 2009. Matrix factorization tech- niques for recommender systems.Computer42, 8 (2009), 30–37
2009
-
[13]
Jiacheng Li, Yujie Wang, and Julian McAuley. 2020. Time interval aware self- attention for sequential recommendation. InProceedings of the 13th international conference on web search and data mining. 322–330
2020
- [14]
-
[15]
Jianxun Lian, Xiaohuan Zhou, Fuzheng Zhang, Zhongxia Chen, Xing Xie, and Guangzhong Sun. 2018. xdeepfm: Combining explicit and implicit feature in- teractions for recommender systems. InProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 1754–1763
2018
- [16]
-
[17]
Hui Lu, Zheng Chai, Yuchao Zheng, Zhe Chen, Deping Xie, Peng Xu, Xun Zhou, and Di Wu. 2025. Large Memory Network for Recommendation. InCompanion Proceedings of the ACM on Web Conference 2025. 1162–1166
2025
-
[18]
Xiao Ma, Liqin Zhao, Guan Huang, Zhi Wang, Zelin Hu, Xiaoqiang Zhu, and Kun Gai. 2018. Entire space multi-task model: An effective approach for estimating post-click conversion rate. InThe 41st International ACM SIGIR Conference on Research & Development in Information Retrieval. 1137–1140
2018
-
[19]
Chunyan Mao, Shuaishuai Huang, Mingxiu Sui, Haowei Yang, and Xueshe Wang
- [20]
-
[21]
Liang Pang, Jun Xu, Qingyao Ai, Yanyan Lan, Xueqi Cheng, and Jirong Wen
-
[22]
InProceedings of the 43rd international ACM SIGIR conference on research and development in information retrieval
Setrank: Learning a permutation-invariant ranking model for information retrieval. InProceedings of the 43rd international ACM SIGIR conference on research and development in information retrieval. 499–508
-
[23]
Qi Pi, Guorui Zhou, Yujing Zhang, Zhe Wang, Lejian Ren, Ying Fan, Xiaoqiang Zhu, and Kun Gai. 2020. Search-based user interest modeling with lifelong sequential behavior data for click-through rate prediction. InProceedings of the 29th ACM International Conference on Information & Knowledge Management. 2685–2692
2020
-
[24]
Steffen Rendle, Christoph Freudenthaler, and Lars Schmidt-Thieme. 2010. Factor- izing personalized markov chains for next-basket recommendation. InProceedings of the 19th international conference on World wide web. 811–820
2010
-
[25]
Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang
-
[26]
InProceedings of the 28th ACM international conference on information and knowledge management
BERT4Rec: Sequential recommendation with bidirectional encoder rep- resentations from transformer. InProceedings of the 28th ACM international conference on information and knowledge management. 1441–1450
-
[27]
Yijia Sun, Shanshan Huang, Linxiao Che, Haitao Lu, Qiang Luo, Kun Gai, and Guorui Zhou. 2025. MPFormer: Adaptive Framework for Industrial Multi-Task Personalized Sequential Retriever. InProceedings of the 34th ACM International Conference on Information and Knowledge Management. 2832–2841
2025
- [28]
-
[29]
Jiaxi Tang and Ke Wang. 2018. Personalized top-n sequential recommenda- tion via convolutional sequence embedding. InProceedings of the eleventh ACM international conference on web search and data mining. 565–573
2018
-
[30]
Jiaxi Tang and Ke Wang. 2018. Ranking distillation: Learning compact ranking models with high performance for recommender system. InProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 2289–2298
2018
-
[31]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need.Advances in neural information processing systems30 (2017)
2017
-
[32]
Timo Wilm, Philipp Normann, Sophie Baumeister, and Paul-Vincent Kobow
-
[33]
InProceedings of the 17th ACM conference on recommender systems
Scaling session-based transformer recommendations using optimized negative sampling and loss functions. InProceedings of the 17th ACM conference on recommender systems. 1023–1026
- [34]
-
[35]
Xu Xie, Fei Sun, Zhaoyang Liu, Shiwen Wu, Jinyang Gao, Jiandong Zhang, Bolin Ding, and Bin Cui. 2022. Contrastive learning for sequential recommendation. In 2022 IEEE 38th international conference on data engineering (ICDE). IEEE, 1259– 1273
2022
- [36]
-
[37]
Xinyang Yi, Ji Yang, Lichan Hong, Derek Zhiyuan Cheng, Lukasz Heldt, Aditee Kumthekar, Zhe Zhao, Li Wei, and Ed Chi. 2019. Sampling-bias-corrected neural modeling for large corpus item recommendations. InProceedings of the 13th ACM conference on recommender systems. 269–277
2019
-
[38]
Zhishan Zhao, Jingyue Gao, Yu Zhang, Shuguang Han, Siyuan Lou, Xiang-Rong Sheng, Zhe Wang, Han Zhu, Yuning Jiang, Jian Xu, et al. 2023. Copr: Consistency- oriented pre-ranking for online advertising. InProceedings of the 32nd ACM International Conference on Information and Knowledge Management. 4974–4980
2023
-
[39]
Guorui Zhou, Na Mou, Ying Fan, Qi Pi, Weijie Bian, Chang Zhou, Xiaoqiang Zhu, and Kun Gai. 2019. Deep interest evolution network for click-through rate prediction. InProceedings of the AAAI conference on artificial intelligence, Vol. 33. 5941–5948
2019
-
[40]
Guorui Zhou, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. 2018. Deep interest network for click-through rate prediction. InProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 1059–1068
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.