A Jacobi-Type Eigensolver for Diagonally Dominant Symmetric Matrices
Pith reviewed 2026-06-29 20:38 UTC · model grok-4.3
The pith
A Jacobi-type iteration computes a specified eigenpair of significantly diagonally dominant symmetric matrices in quadratic time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The procedure is a Jacobi-type iteration for a given specified eigenpair of a symmetric matrix. For a certain class of diagonally dominant matrices, the procedure is shown to converge at a linear rate depending on how the matrix is significantly dominated. The cost per iteration is generally quadratic. Therefore, the proposed procedure can compute an approximation of the desired eigenpair in quadratic time.
What carries the argument
The Jacobi-type iteration that updates matrix entries to isolate the target eigenpair while maintaining symmetry.
If this is right
- Linear convergence holds precisely when the matrix satisfies the significant diagonal dominance condition.
- The convergence speed is governed by a quantity measuring the degree of dominance.
- Work per iteration scales quadratically with matrix dimension.
- An approximate eigenpair is obtained after a quadratic number of total operations.
Where Pith is reading between the lines
- The explicit dependence of the rate on dominance allows a priori estimates of the number of iterations needed.
- The method targets problems where only one eigenpair is required rather than the full spectrum.
- Quadratic overall cost makes the approach attractive for moderately large matrices arising in applications that produce diagonally dominant structure.
Load-bearing premise
The input symmetric matrix must belong to the class of significantly diagonally dominant matrices.
What would settle it
Apply the iteration to a symmetric matrix that is diagonally dominant but falls below the significance threshold and check whether the error reduction follows the claimed linear rate or fails to converge linearly.
Figures
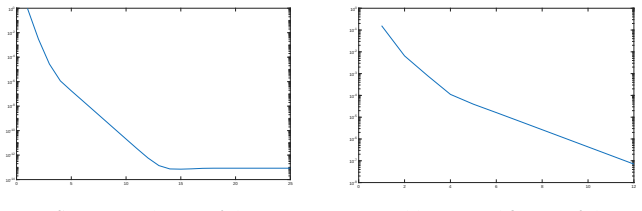
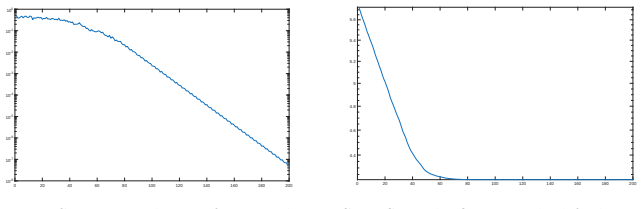
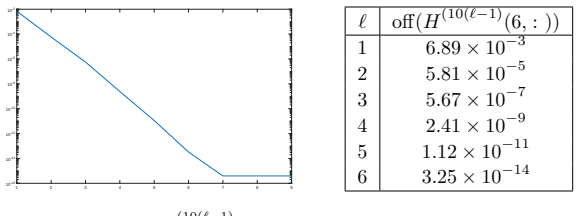
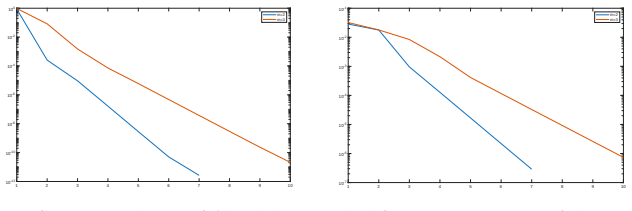
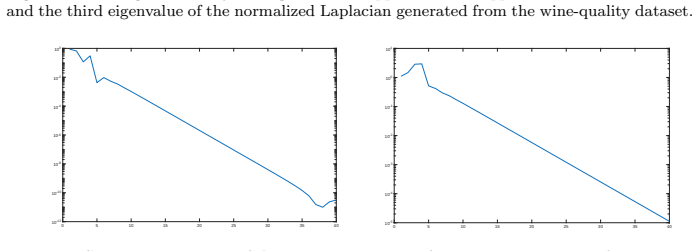
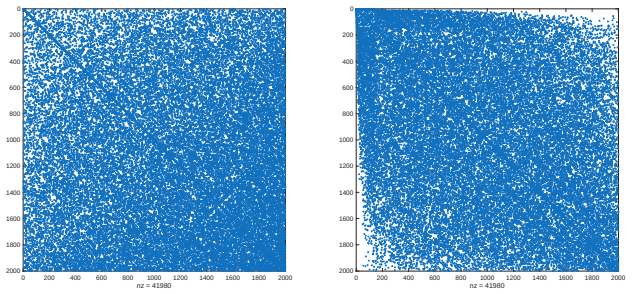
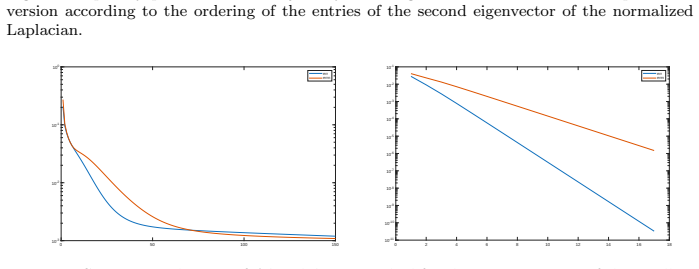
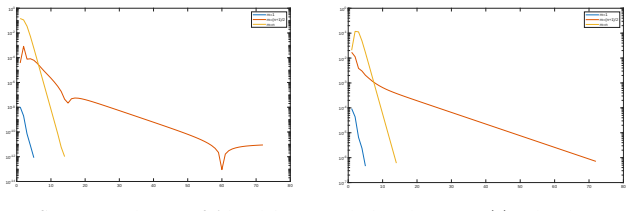
read the original abstract
This paper presents a Jacobi-type iteration for computing a given specified eigenpair of a symmetric matrix. For a certain class of diagonally dominant matrices, the procedure is shown to converge at a linear rate depending on how the matrix is significantly dominated. The cost per iteration is generally quadratic. Therefore, the proposed procedure can compute an approximation of the desired eigenpair in quadratic time.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a Jacobi-type iteration for computing a specified eigenpair of a symmetric matrix. For a certain class of diagonally dominant matrices, the procedure is shown to converge at a linear rate depending on how the matrix is significantly dominated. The cost per iteration is generally quadratic. Therefore, the proposed procedure can compute an approximation of the desired eigenpair in quadratic time.
Significance. If the convergence result holds for the stated matrix class and the complexity analysis is corrected, the method could offer a specialized, efficient approach for eigenpair computation in applications involving strongly diagonally dominant symmetric matrices. The linear convergence rate tied to the dominance parameter is a potentially useful feature, but the overall runtime claim requires adjustment to reflect standard iteration counts.
major comments (1)
- [Abstract] Abstract: The claim that the eigenpair can be computed 'in quadratic time' is not supported by the described linear convergence. Linear convergence reduces the error by a fixed factor ρ < 1 per iteration (with ρ depending on dominance), requiring Θ(log(1/ε)) iterations to reach accuracy ε. Combined with O(n²) work per iteration, the total cost is O(n² log(1/ε)), not quadratic, unless the number of iterations is bounded independently of ε (which is not stated).
Simulated Author's Rebuttal
We thank the referee for the careful review and for identifying the inconsistency between the stated linear convergence and the runtime claim in the abstract. We agree that the complexity statement requires correction and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that the eigenpair can be computed 'in quadratic time' is not supported by the described linear convergence. Linear convergence reduces the error by a fixed factor ρ < 1 per iteration (with ρ depending on dominance), requiring Θ(log(1/ε)) iterations to reach accuracy ε. Combined with O(n²) work per iteration, the total cost is O(n² log(1/ε)), not quadratic, unless the number of iterations is bounded independently of ε (which is not stated).
Authors: We agree with the referee's observation. The abstract's claim of quadratic time is incorrect because the convergence is linear with rate depending on the dominance parameter, leading to a total complexity of O(n² log(1/ε)). We will revise the abstract (and any similar statements in the introduction or conclusion) to accurately report the complexity as O(n² log(1/ε)). This change does not affect the convergence theorem or the per-iteration cost analysis, which remain the core contributions. revision: yes
Circularity Check
No circularity: convergence rate and complexity derived from explicit proof and cost analysis
full rationale
The paper states that linear convergence is shown (proven) for a defined class of significantly diagonally dominant symmetric matrices, with per-iteration cost generally quadratic, yielding the quadratic-time claim. No equations reduce a claimed result to a fitted parameter, self-definition, or self-citation chain; the derivation chain is self-contained via standard analysis of the iteration without importing load-bearing uniqueness or ansatzes from prior author work. The skeptic's log-factor observation concerns completeness of the complexity statement rather than any definitional circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Altafini
C. Altafini. Stability analysis of diagonally equipotent matrices.Automat- ica, 49(9):2780–2785, 2013
2013
-
[2]
Barlow and J
J. Barlow and J. Demmel. Computing accurate eigensystems of scaled diagonally dominant matrices.SIAM Journal on Numerical Analysis, 27(3):762–791, 1990
1990
-
[3]
R. P. Brent and F. T. Luk. The solution of singular-value and symmet- ric eigenvalue problems on multiprocessor arrays.SIAM J. Scientific and Statistical Computing, 6:69–84, 1985
1985
-
[4]
Bunch and C.P
J.R. Bunch and C.P. Nielsen. Updating the singular value decomposition. Numerische Mathematik, 31(2):111–129, 1978/79
1978
-
[5]
Drmaˇ c and K
Z. Drmaˇ c and K. Veseli´ c. Approximate eigenvectors as preconditioner. Linear Algebra and its Applications, 309(1):191–215, 2000
2000
-
[6]
Eidelman, L
Y. Eidelman, L. Gemignani, and I. Gohberg. Efficient eigenvalue computa- tion for quasiseparable Hermitian matrices under low rank perturbations. Numerical Algorithms, 47:253–273, 2008
2008
-
[7]
G. H. Golub and H. A. van der Vorst. Eigenvalue computation in the 20th century.Journal of Computational and Applied Mathematics, 123(1):35–65,
-
[8]
Numerical Analysis 2000. Vol. III: Linear Algebra. 16
2000
-
[9]
G.H. Golub. Some modified matrix eigenvalue problems.SIAM Review, 15:318–334, 1973
1973
-
[10]
Golub, D.K
T.R. Golub, D.K. Slonim, P. Tamayo, C. Huard, M. Gaasenbeek, J.P. Mesirov, H. Coller, M.L. Loh, J.R. Downing, M.A. Caligiuri, C.D. Bloom- field, and E.S. Lander. Molecular classification of cancer: class dis- covery and class prediction by gene expression monitoring.Science, 286(5439):531–537, October 1999
1999
-
[11]
Hari and Z
V. Hari and Z. Drmac. On scaled almost-diagonal Hermitian matrix pairs. SIAM Journal on Matrix Analysis and Applications, 18(4):1000–1012, 1997
1997
-
[12]
Higham, G
D.J. Higham, G. Kalna, and M. Kibble. Spectral clustering and its use in bioinformatics.Journal of Computational and Applied Mathematics, 204(1):25–37, 2007. Special issue dedicated to Professor Shinnosuke Oharu on the occasion of his 65th birthday
2007
-
[13]
Limebeer
D.J.N. Limebeer. The application of generalized diagonal dominance to linear system stability theory.International Journal of Control, 36(2):185– 212, 1982
1982
-
[14]
Matejaˇ s
J. Matejaˇ s. Quadratic convergence of scaled matrices in Jacobi method. Numerische Mathematik, 87(1):171–199, Nov 2000
2000
-
[15]
Matejaˇ s
J. Matejaˇ s. Quadratic convergence bounds of scaled iterates by the serial Jacobi method for indefinite Hermitian matrices.Electronic Journal of Linear Algebra, 17:62–87, 2008
2008
-
[16]
A. Melman. A numerical comparison of methods for solving secular equa- tions.J. Comput. Appl. Math., 86(1):237–249, 1997. Special issue dedicated to William B. Gragg (Monterey, CA, 1996)
1997
-
[17]
A. Ng, M. Jordan, and Y. Weiss. On spectral clustering: Analysis and an algorithm. In T. Dietterich, S. Becker, and Z. Ghahramani, editors, Advances in Neural Information Processing Systems, volume 14. MIT Press, 2001
2001
-
[18]
N. Sebe. Diagonal dominance and integrity. InProceedings of 35th IEEE Conference on Decision and Control, volume 2, pages 1904–1909 vol.2, 1996
1904
-
[19]
P. Tilli. Polynomial root finding by means of continuation.Computing, 59(4):307–324, 1997. 17
1997
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.