ELSA: Acoustic Event-Level Semantic Alignment for Fine-Grained Reference-Free Text-to-Audio Evaluation
Pith reviewed 2026-06-26 23:14 UTC · model grok-4.3
The pith
ELSA evaluates text-to-audio by aligning separate acoustic events from the prompt instead of matching entire clips.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ELSA is a reference-free evaluation metric for fine-grained text-audio alignment that decomposes generated audio guided by distinct acoustic events derived from the text query and assesses event-level alignment, revealing higher correlation with human subjective ratings than prior CLAP-based metrics across four TTA benchmarks.
What carries the argument
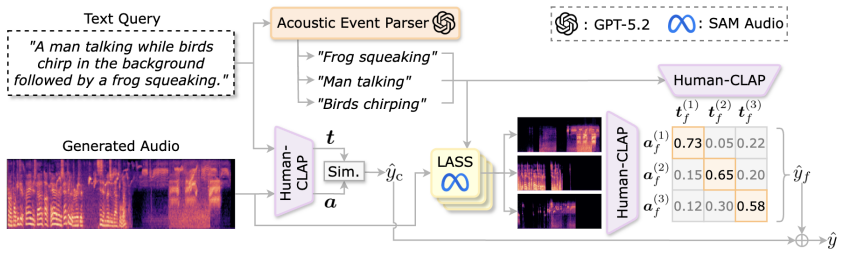
Acoustic event-level semantic alignment, which extracts distinct events from the text, decomposes the audio along those events, and computes separate alignment scores for each.
If this is right
- TTA models can be iterated using automatic scores that better reflect human perception of specific sound events.
- Evaluation can now flag mismatches at individual events rather than only reporting overall similarity.
- Reference-free assessment becomes viable for fine-grained intent capture without paired audio references.
- Development of TTA systems gains a tool that distinguishes precise event matches from coarse overall quality.
Where Pith is reading between the lines
- The same event-decomposition idea could be tested on text-to-video or text-to-music tasks where fine-grained alignment also matters.
- Performance may drop on prompts that lack clearly separable acoustic events, such as abstract or overlapping sounds.
- If the decomposition step proves stable, future work could explore learned rather than rule-based event extraction.
Load-bearing premise
Decomposing generated audio according to acoustic events taken from the text and scoring their individual alignments will produce numbers that track human judgments of fine-grained text-audio match.
What would settle it
New human ratings collected on the same four benchmarks where ELSA scores show lower or equal correlation compared with prior whole-clip metrics.
Figures


read the original abstract
Text-to-audio (TTA) generation, synthesizing audio from natural language, has been widely studied for its ability to capture precise user intent. To effectively advance TTA models, it is essential to reliably evaluate generated audio without relying on costly human subjective ratings, motivating the development of automatic evaluation metrics that correlate well with human judgments. While recent CLAP-based metrics provide practical reference-free solutions, their coarse-grained text-audio similarity matching often correlates poorly with human ratings. To address this, we propose ELSA, a reference-free evaluation metric for fine-grained text-audio alignment. ELSA decomposes generated audio guided by distinct acoustic events derived from the text query and assesses event-level alignment. Experiments across four TTA benchmarks show that ELSA reveals a higher correlation with human subjective ratings than prior metrics, highlighting its effectiveness for reliable TTA evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ELSA, a reference-free metric for fine-grained text-to-audio (TTA) evaluation. It decomposes generated audio guided by distinct acoustic events extracted from the text query and measures event-level semantic alignment. Experiments on four TTA benchmarks are claimed to demonstrate higher correlation with human subjective ratings than prior CLAP-based metrics.
Significance. If the central claim holds after detailed verification, ELSA could offer a practical improvement over coarse-grained reference-free metrics for TTA model development. However, the absence of any methodological, experimental, or statistical details in the abstract precludes assessment of whether the result is robust or reproducible.
major comments (2)
- [Abstract] Abstract: The claim that ELSA 'reveals a higher correlation with human subjective ratings than prior metrics' supplies no information on the correlation measure employed, the statistical tests performed, sample sizes, or data handling procedures. This information is load-bearing for the central empirical claim and its absence prevents verification that the data support the assertion.
- [Abstract] Abstract: No description is provided of the text-to-event extraction process, the audio decomposition method, or how event-level alignment is quantified. These steps are load-bearing for the weakest assumption that event-level decomposition will reliably track human judgments of fine-grained match.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We agree that greater specificity in the abstract would strengthen the presentation of the central claims and will revise the abstract accordingly while ensuring it remains concise.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that ELSA 'reveals a higher correlation with human subjective ratings than prior metrics' supplies no information on the correlation measure employed, the statistical tests performed, sample sizes, or data handling procedures. This information is load-bearing for the central empirical claim and its absence prevents verification that the data support the assertion.
Authors: We agree that the abstract would benefit from indicating the correlation measure, statistical testing approach, and evaluation scale. The manuscript body (experimental section) provides these details for the four benchmarks, including the specific correlation coefficient used, significance testing, and the number of rated samples per benchmark. We will revise the abstract to incorporate a brief statement of the correlation measure and evaluation scope. revision: yes
-
Referee: [Abstract] Abstract: No description is provided of the text-to-event extraction process, the audio decomposition method, or how event-level alignment is quantified. These steps are load-bearing for the weakest assumption that event-level decomposition will reliably track human judgments of fine-grained match.
Authors: The abstract is intentionally high-level, but the full methodology for text-to-event extraction, audio decomposition, and event-level alignment quantification is described in the dedicated methods section of the manuscript. We acknowledge that a short outline of these components in the abstract would improve accessibility and will revise the abstract to include one-sentence descriptions of each step. revision: yes
Circularity Check
No significant circularity identified
full rationale
The abstract presents ELSA as a proposed metric that decomposes generated audio using acoustic events extracted from the text query and evaluates event-level alignment, with the central claim being higher correlation to human ratings than prior CLAP-based metrics across four benchmarks. No equations, parameter-fitting procedures, self-citations, or derivations are described that would reduce the reported correlation or the metric itself to its inputs by construction. The human correlation serves as external validation on separate benchmarks rather than a fitted or self-defined quantity. The paper's claim is therefore self-contained against external benchmarks with no load-bearing circular steps detectable from the given text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction Audio generation conditioned on user intent, encompassing speech, sound effects, and music, has been widely studied [1, 2]. This interest is motivated by diverse applications such as aug- mented reality audio environments and media sound genera- tion [3, 4], with text-to-audio (TTA) generation gaining partic- ular attention for directly synth...
-
[2]
Related Works Automatic evaluation metrics for TTA generation [14, 11] have been comprehensively reviewed in Lan et al. [15] and Su et al. [16]. Among these, reference-free metrics such as PAM [9] and CLAPScore [12] have gained prominence due to their broad applicability, avoiding the need for reference audio by directly aligning text and audio representa...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
dog barking
Method An overview of the proposed metric is shown in Figure 2. ELSA is inspired by prior evaluation metrics for video and image cap- tioning [18, 23], particularly those that hierarchically assess vi- sual–language alignment [20, 19]. 3.1. Event-Level Representation Extraction Fine-grained text–audio comparison is achieved by hierarchi- cally extracting ...
-
[4]
Experiments 4.1. Datasets and Data Pre-processing We evaluated the correlation between the proposed metric and human subjective ratings using four TTA benchmarks: Audio- Caps [25], Clotho [26], MusicCaps [27], and RELATE [28]. For each benchmark, audio samples are generated from text queries using multiple TTA models (e.g., AudioLDM [29]) and anno- tated ...
-
[5]
text” in the table) and audio retrieval from text (“audio
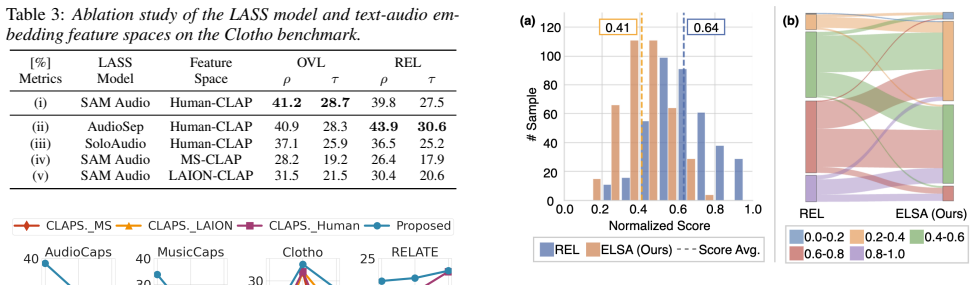
Results and Analysis 5.1. Correlation with Human Subjective Ratings Table 1 shows the correlation between human subjective rat- ings and the proposed metric, along with baseline metrics, across four benchmarks (AudioCaps [25], Clotho [26], Mus- 6https://github.com/soham97/PAM/tree/main 7https://github.com/lourson1091/audiobertscore Table 2:Performance com...
-
[6]
Limitation As a primary limitation, ELSA does not explicitly model the temporal order of acoustic events. Although ELSA outperforms baseline metrics on order-sensitive benchmarks, such as OS on RELATE [28] and CompA-order on CompA [30] (Table 2), explicitly modeling event duration and sequential structure re- mains a promising direction for future improvement
-
[7]
Experimental results show that ELSA consistently outperforms existing metrics, including both reference-based and reference-free approaches
Conclusion In this paper, we proposed ELSA, a reference-free evaluation metric for TTA generation that enables fine-grained text–audio comparison. Experimental results show that ELSA consistently outperforms existing metrics, including both reference-based and reference-free approaches. Furthermore, ablation and sen- sitivity analyses show both component-...
-
[8]
Honda Bridge Project,
Acknowledgments Part of this study was executed in the “Honda Bridge Project,” a collaborative research and education program between the Fac- ulty of Science and Technology at Keio University and Honda Motor Co., Ltd
-
[9]
They were not involved in the research design, nor did they contribute to the development, im- plementation, or evaluation of the proposed methods
Generative AI Use Disclosure Generative AIs were used solely for auxiliary purposes, such as language refinement, manuscript formatting, and the imple- mentation of standard algorithms. They were not involved in the research design, nor did they contribute to the development, im- plementation, or evaluation of the proposed methods. Accord- ingly, Generati...
-
[10]
Conditional Sound Generation Using Neural Discrete Time-Frequency Representa- tion Learning,
X. Liu, T. Iqbal, J. Zhao, Q. Huanget al., “Conditional Sound Generation Using Neural Discrete Time-Frequency Representa- tion Learning,” inMLSP, 2021, pp. 1–6
2021
-
[11]
Full- band General Audio Synthesis with Score-based Diffusion,
S. Pascual, G. Bhattacharya, C. Yeh, J. Pons, and J. Serr `a, “Full- band General Audio Synthesis with Score-based Diffusion,” in ICASSP, 2023, pp. 1–5
2023
-
[12]
Sound synthesis for impact sounds in video games,
D. B. Lloyd, N. Raghuvanshi, and N. K. Govindaraju, “Sound synthesis for impact sounds in video games,” inI3D, 2011, pp. 55–62
2011
-
[13]
Riffusion: Stable Diffusion for Real-Time Music Generation,
S. Forsgren and H. Martiros, “Riffusion: Stable Diffusion for Real-Time Music Generation,” URL: https://riffusion.com/about, 2022
2022
-
[14]
AudioLDM 2: Learning Holistic Audio Generation With Self- Supervised Pretraining,
H. Liu, Y . Yuan, X. Liu, X. Mei, Q. Kong, Q. Tian, Y . Wanget al., “AudioLDM 2: Learning Holistic Audio Generation With Self- Supervised Pretraining,”TASLP, vol. 32, pp. 2871–2883, 2024
2024
-
[15]
AudioX: Diffusion Transformer for Anything-to-Audio Generation,
Z. Tian, Y . Jin, Z. Liu, R. Yuan, X. Tan, Q. Chen, W. Xue, and Y . Guo, “AudioX: Diffusion Transformer for Anything-to-Audio Generation,” inICLR, 2026
2026
-
[16]
TangoFlux: Text to Au- dio Generation with CLAP-Ranked Preference Optimization,
C.-Y . Hung, N. Majumder, Z. Kong, A. Mehrish, A. Zadeh, C. Li, R. Valle, B. Catanzaro, and S. Poria, “TangoFlux: Text to Au- dio Generation with CLAP-Ranked Preference Optimization,” in ICLR, 2026
2026
-
[17]
AudioGen: Tex- tually Guided Audio Generation,
F. Kreuk, G. Synnaeve, A. Polyak, U. Singer, A. D ´efossez, J. Copet, D. Parikh, Y . Taigman, and Y . Adi, “AudioGen: Tex- tually Guided Audio Generation,” inICLR, 2023
2023
-
[18]
PAM: Prompting Audio- Language Models for Audio Quality Assessment,
S. Deshmukh, D. Alharthi, B. Elizalde, H. Gamper, M. Al Is- mail, R. Singh, B. Raj, and H. Wang, “PAM: Prompting Audio- Language Models for Audio Quality Assessment,” inInterspeech, 2024, pp. 3320–3324
2024
-
[19]
AudioBERTScore: Objective Evaluation of Environmental Sound Synthesis Based on Similarity of Audio Embedding Se- quences,
M. Kishi, R. Sakai, S. Takamichi, Y . Kanamori, and Y . Okamoto, “AudioBERTScore: Objective Evaluation of Environmental Sound Synthesis Based on Similarity of Audio Embedding Se- quences,” inAAAI Audio-Centric AI Workshop, 2026
2026
-
[20]
SDR – Half-baked or Well Done?
J. L. Roux, S. Wisdom, H. Erdogan, and J. R. Hershey, “SDR – Half-baked or Well Done?” inICASSP, 2019, pp. 626–630
2019
-
[21]
A Reference-free Metric for Language-Queried Audio Source Separation using Contrastive Language-Audio Pretraining,
F. Xiao, J. Guan, Q. Zhu, X. Liuet al., “A Reference-free Metric for Language-Queried Audio Source Separation using Contrastive Language-Audio Pretraining,” inDCASE Workshop, 2024
2024
-
[22]
Human-CLAP: Human-perception-based Con- trastive Language-audio Pretraining,
T. Takano, Y . Okamoto, Y . Kanamori, Y . Saito, R. Nagase, and H. Saruwatari, “Human-CLAP: Human-perception-based Con- trastive Language-audio Pretraining,” inAPSIPA ASC, 2025, pp. 131–136
2025
-
[23]
Performance measure- ment in blind audio source separation,
E. Vincent, R. Gribonval, and C. Fevotte, “Performance measure- ment in blind audio source separation,”TASLP, vol. 14, no. 4, pp. 1462–1469, 2006
2006
-
[24]
A Survey of Automatic Evaluation Methods on Text, Visual and Speech Generations,
T. Lan, Y .-H. Zhou, Z.-A. Ma, F. Sun, R.-Q. Sun, J. Luoet al., “A Survey of Automatic Evaluation Methods on Text, Visual and Speech Generations,”arXiv preprint arXiv:2506.10019, 2025
-
[25]
Audio-language models for audio-centric tasks: A survey,
Y . Su, J. Bai, Q. Xu, K. Xu, and Y . Dou, “Audio-Language Models for Audio-Centric Tasks: A survey,”arXiv preprint arXiv:2501.15177, 2025
-
[26]
CLAP Learning Audio Concepts from Natural Language Supervision,
B. Elizalde, S. Deshmukh, M. A. Ismail, and H. Wang, “CLAP Learning Audio Concepts from Natural Language Supervision,” inICASSP, 2023, pp. 1–5
2023
-
[27]
VELA: An LLM-hybrid-as-a-judge approach for evaluating long image captions,
K. Matsuda, Y . Wada, S. Hirano, S. Otsuki, and K. Sugiura, “VELA: An LLM-hybrid-as-a-judge approach for evaluating long image captions,” inEMNLP, 2025, pp. 8680–8696
2025
-
[28]
EMScore: Evaluating Video Captioning via Coarse-Grained and Fine-Grained Embedding Matching,
Y . Shi, X. Yang, H. Xu, C. Yuan, B. Li, W. Hu, and Z. Zha, “EMScore: Evaluating Video Captioning via Coarse-Grained and Fine-Grained Embedding Matching,” inCVPR, 2022
2022
-
[29]
HICEScore: A Hierarchical Metric for Image Caption- ing Evaluation,
Z. Zeng, J. Sun, H. Zhang, T. Wen, Y . Su, Y . Xie, Z. Wang, and B. Chen, “HICEScore: A Hierarchical Metric for Image Caption- ing Evaluation,” inACM-MM, 2024, p. 866–875
2024
-
[30]
Advancing multi-grained alignment for contrastive language-audio pre-training,
Y . Li, Z. Guo, X. Wang, and H. Liu, “Advancing multi-grained alignment for contrastive language-audio pre-training,” inACM MM, 2024, pp. 7356–7365
2024
-
[31]
Finelap: Taming heterogeneous supervision for fine-grained language-audio pretraining,
X. Li, X. Xu, Z. Ma, W. Chen, H. He, Q. Kong, and X. Chen, “Finelap: Taming heterogeneous supervision for fine-grained language-audio pretraining,”ACL, 2026
2026
-
[32]
LLM-Free Image Captioning Evaluation in Reference-Flexible Settings,
S. Hirano, Y . Wada, K. Matsuda, S. Otsuki, and K. Sugiura, “LLM-Free Image Captioning Evaluation in Reference-Flexible Settings,” inAAAI, 2026
2026
-
[33]
SAM Audio: Segment Anything in Audio,
B. Shi, A. Tjandra, J. Hoffman, H. Wang, Y .-C. Wu, L. Gao, J. Richter, M. Le, A. Vyas, S. Chenet al., “SAM Audio: Segment Anything in Audio,”arXiv preprint arXiv:2512.18099, 2025
-
[34]
AudioCaps: Generating Captions for Audios in The Wild,
C. D. Kim, B. Kim, H. Lee, and G. Kim, “AudioCaps: Generating Captions for Audios in The Wild,” inNAACL-HLT, 2019
2019
-
[35]
Clotho: an Audio Cap- tioning Dataset,
K. Drossos, S. Lipping, and T. Virtanen, “Clotho: an Audio Cap- tioning Dataset,” inICASSP, 2020, pp. 736–740
2020
-
[36]
MusicLM: Generating Music From Text
A. Agostinelli, T. I. Denk, Z. Borsos, J. Engel, M. Verzetti, A. Caillon, Q. Huang, A. Jansen, A. Roberts, M. Tagliasac- chiet al., “MusicLM: Generating Music From Text,” arXiv:2301.11325, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
RELATE: Subjective evaluation dataset for auto- matic evaluation of relevance between text and audio ,
Y . Kanamori, Y . Okamoto, T. Takano, S. Takamichi, Y . Saito, and H. Saruwatari, “RELATE: Subjective evaluation dataset for auto- matic evaluation of relevance between text and audio ,” inInter- speech, 2025, pp. 3155–3159
2025
-
[38]
AudioLDM: Text-to-audio generation with latent diffusion models,
H. Liu, Z. Chen, Y . Yuan, X. Mei, X. Liu, D. Mandic, W. Wang, and M. D. Plumbley, “AudioLDM: Text-to-audio generation with latent diffusion models,” inICML, vol. 202, 23–29 Jul 2023, pp. 21 450–21 474
2023
-
[39]
CompA: Addressing the Gap in Com- positional Reasoning in Audio-Language Models,
S. Ghosh, A. Seth, S. Kumar, U. Tyagi, C. K. R. Evuru, R. S, S. Sakshi, O. Nietoet al., “CompA: Addressing the Gap in Com- positional Reasoning in Audio-Language Models,” inICLR, 2024
2024
-
[40]
Fast Timing-Conditioned Latent Audio Diffusion,
Z. Evans, C. Carr, J. Taylor, S. H. Hawley, and J. Pons, “Fast Timing-Conditioned Latent Audio Diffusion,” inICML, 2024
2024
-
[41]
Efficient Training of Audio Transformers with Patchout,
Khaled Koutini and Jan Schl ¨uter and Hamid Eghbal-zadeh and Gerhard Widmer, “Efficient Training of Audio Transformers with Patchout,” inInterspeech, 2022, pp. 2753–2757
2022
-
[42]
Look, Lis- ten, and Learn More: Design Choices for Deep Audio Embed- dings,
A. L. Cramer, H.-H. Wu, J. Salamon, and J. P. Bello, “Look, Lis- ten, and Learn More: Design Choices for Deep Audio Embed- dings,” inICASSP 2019, 2019, pp. 3852–3856
2019
-
[43]
Large-Scale Contrastive Language-Audio Pretrain- ing with Feature Fusion and Keyword-to-Caption Augmentation,
Y . Wu, K. Chen, T. Zhang, Y . Hui, T. Berg-Kirkpatrick, and S. Dubnov, “Large-Scale Contrastive Language-Audio Pretrain- ing with Feature Fusion and Keyword-to-Caption Augmentation,” inICASSP, 2023, pp. 1–5
2023
-
[44]
Separate Anything You Describe,
X. Liu, Q. Kong, Y . Zhao, H. Liu, Y . Yuan, Y . Liu, R. Xia, Y . Wang, M. D. Plumbley, and W. Wang, “Separate Anything You Describe,”TASLP, 2024
2024
-
[45]
SoloAudio: Target Sound Extraction with Language-oriented Audio Diffusion Transformer,
H. Wang, J. Hai, Y .-J. Lu, K. Thakkar, M. Elhilali, and N. Dehak, “SoloAudio: Target Sound Extraction with Language-oriented Audio Diffusion Transformer,” inICASSP, 2025, pp. 1–5
2025
-
[46]
Tango 2: Aligning diffusion-based text-to-audio generations through direct preference optimization,
N. Majumder, C.-Y . Hung, D. Ghosal, W.-N. Hsuet al., “Tango 2: Aligning diffusion-based text-to-audio generations through direct preference optimization,” inACM MM, 2024, pp. 564–572
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.