Inverse Suitability: Identifying Condition Difficulty and Rider Skill from Behavioural Outcomes via Continuous-Item Response Theory
Pith reviewed 2026-07-03 03:21 UTC · model grok-4.3
The pith
A continuous-item IRT model separates latent rider skill from condition difficulty using only binary behavioral outcomes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
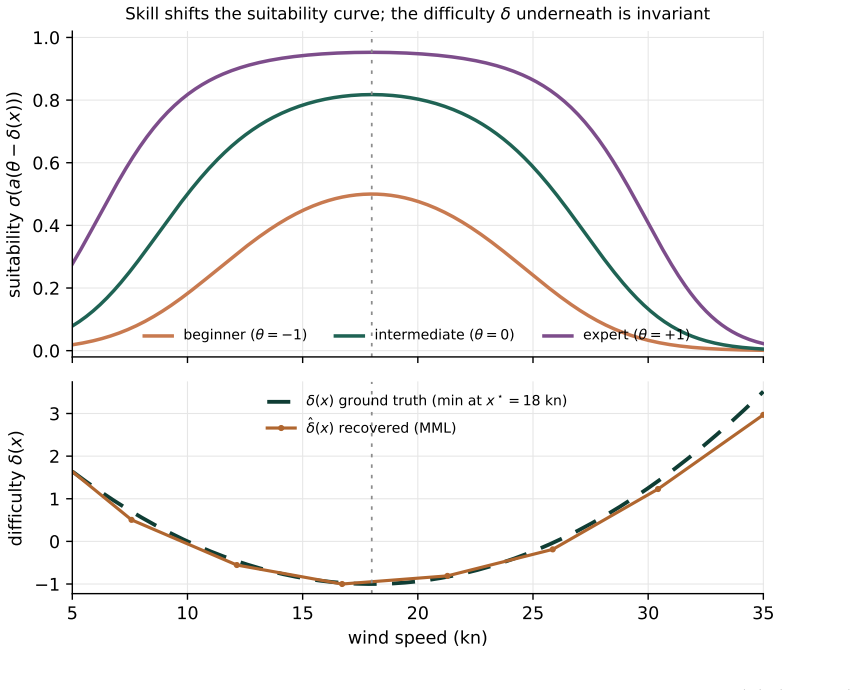
The central claim is that the model P(y=1) = sigma(a (theta_r - delta(x, s))), with delta(x, s) anchored to a physics-derived expert curve as prior and parameters fit by marginal maximum likelihood, identifies distinct latent skill theta_r and difficulty delta(x, s) from the rider-by-condition incidence graph when that graph is connected; the formulation is strictly more general than a single suitability curve and recovers it exactly when skill is integrated out under the population distribution.
What carries the argument
The continuous-item IRT likelihood with difficulty function delta(x, s) anchored to a physics-derived expert curve prior, estimated by marginal maximum likelihood with Gauss-Hermite quadrature.
If this is right
- The recovered difficulty function supplies a measurable intrinsic difficulty atlas at the site level.
- On a reference cohort of 80 riders and 30 outcomes the model recovers latent skill with correlation 0.96 and locates the difficulty minimum within 3 units of ground truth.
- The model improves held-out Brier Skill Score by +0.33 relative to the expert-curve baseline.
- When the incidence graph is not connected the method falls back to a single suitability curve.
Where Pith is reading between the lines
- The same separation of latent ability from task difficulty could be tested in other outcome-mixing domains such as medical procedure success rates or educational test performance.
- If the difficulty atlas proves stable across riders, it could support data-driven site recommendations without requiring new sensor deployments.
- Sparse incidence graphs in real deployments would likely trigger the single-curve fallback more often than the synthetic reference cohort.
Load-bearing premise
The rider-by-condition incidence graph must be connected to allow separate identification of skill and difficulty parameters.
What would settle it
On real rider outcome data the recovered difficulty minima fail to align within a few units of independent physical measurements of condition difficulty, or the Brier Skill Score improvement over the expert-curve baseline disappears on held-out observations.
Figures
read the original abstract
Suitability scoring for outdoor activities (kitesurfing, paragliding, ski touring) maps environmental conditions to a go/no-go verdict via expert-defined curves. These curves conflate two distinct quantities: the intrinsic difficulty of a condition and the skill of the person facing it. We introduce Inverse Suitability, a continuous-item Item Response Theory (IRT) model that identifies both from behavioural outcomes alone. Each outcome is a triple (rider r, condition metric x at site s, binary outcome y); we model P(y=1) = sigma(a (theta_r - delta(x, s))), where theta_r is latent rider skill, delta(x, s) is a latent difficulty function anchored to a physics-derived expert curve as its prior, and a is a discrimination parameter. The formulation is strictly more general than a single suitability curve, which it recovers exactly when skill is integrated out under the population distribution. Parameters are estimated by marginal maximum likelihood with Gauss-Hermite quadrature; identification holds when the rider-by-condition incidence graph is connected, with a documented single-curve fallback otherwise. We validate via synthetic recovery: on a reference cohort (80 riders times 30 outcomes) the model recovers latent skill at r = 0.96, locates the difficulty minimum within 3 units of ground truth, and improves held-out Brier Skill Score by +0.33 over the expert-curve baseline. The recovered difficulty function defines a measurable, site-level construct, an intrinsic difficulty atlas, that existing meteorological observation networks do not capture. All results reproduce from a single command on synthetic data, requiring no proprietary observations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Inverse Suitability, a continuous-item IRT model for separating latent rider skill (θ_r) and condition difficulty δ(x, s) from binary behavioral outcomes (rider r, condition metric x at site s, outcome y). It specifies P(y=1) = σ(a (θ_r - δ(x, s))), with δ anchored to a physics-derived expert curve as prior, a as discrimination, and estimation via marginal maximum likelihood with Gauss-Hermite quadrature. The model recovers the single suitability curve when skill is integrated out. Synthetic validation on 80 riders × 30 outcomes reports skill recovery r=0.96, difficulty minimum located within 3 units of ground truth, and +0.33 held-out Brier Skill Score improvement over the expert baseline. All results are reproducible from synthetic data with a single command.
Significance. If the separation holds beyond the anchored synthetic setting, the method would enable construction of measurable, site-level intrinsic difficulty atlases from behavioral data that existing meteorological networks do not capture, offering a data-driven alternative to expert-defined suitability curves for activities such as kitesurfing. The synthetic recovery metrics and explicit reproducibility statement are strengths that support the technical contribution. The extension of IRT to this continuous-outcome setting is a natural and potentially useful application.
major comments (2)
- [Abstract / model equation] Abstract / model equation: The central claim is identification of distinct θ_r and δ(x, s) 'from behavioural outcomes alone'. However, the formulation anchors δ(x, s) to a physics-derived expert curve as prior, and the skeptic note correctly observes that without this anchoring any additive shift between θ and δ preserves the same probabilities. The reported synthetic recovery (r=0.96) and Brier gain (+0.33) therefore demonstrate consistency under the anchored generative process rather than pure data-driven separation. An ablation that weakens or removes the expert-curve prior is needed to quantify how much of the reported improvement is attributable to the IRT structure versus the prior.
- [Abstract / identification paragraph] Abstract / identification paragraph: Identification is stated to require a connected rider-by-condition incidence graph, with an explicit single-curve fallback otherwise. This connectivity assumption is load-bearing for the separation claim. The manuscript should report the fraction of real-world incidence graphs expected to be connected and the performance degradation under the fallback; otherwise the advantage over the expert baseline is conditional on a data property that may not hold in typical cohorts.
minor comments (2)
- [Abstract] Abstract: The statement 'requiring no proprietary observations' is inconsistent with the use of a physics-derived expert curve as prior, which itself constitutes external information.
- [Methods (implied)] Methods (implied): No details are given on the number of Gauss-Hermite quadrature points, convergence criteria for marginal maximum likelihood, or sensitivity of the recovered parameters to the choice of quadrature.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on identification and the role of the expert-curve prior. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract / model equation] The central claim is identification of distinct θ_r and δ(x, s) 'from behavioural outcomes alone'. However, the formulation anchors δ(x, s) to a physics-derived expert curve as prior, and the skeptic note correctly observes that without this anchoring any additive shift between θ and δ preserves the same probabilities. The reported synthetic recovery (r=0.96) and Brier gain (+0.33) therefore demonstrate consistency under the anchored generative process rather than pure data-driven separation. An ablation that weakens or removes the expert-curve prior is needed to quantify how much of the reported improvement is attributable to the IRT structure versus the prior.
Authors: We agree that the expert-curve prior is essential to resolve the additive invariance between θ_r and δ(x,s); without it the model is not identified from outcomes alone. The abstract phrasing 'from behavioural outcomes alone' is imprecise and will be revised to state that identification relies on both the behavioral data and the anchored prior. The synthetic experiments recover parameters when the data-generating process matches the full model (including prior); an ablation that removes the prior would simply reproduce the known non-identifiability, confirming rather than quantifying the prior's contribution. We will add a short paragraph clarifying the identifiability conditions. revision: yes
-
Referee: [Abstract / identification paragraph] Identification is stated to require a connected rider-by-condition incidence graph, with an explicit single-curve fallback otherwise. This connectivity assumption is load-bearing for the separation claim. The manuscript should report the fraction of real-world incidence graphs expected to be connected and the performance degradation under the fallback; otherwise the advantage over the expert baseline is conditional on a data property that may not hold in typical cohorts.
Authors: The manuscript already states the connectivity requirement and documents the single-curve fallback. Because validation uses only synthetic data, we cannot report the fraction of real-world incidence graphs that are connected. We will add synthetic-graph experiments that vary connectivity and quantify degradation under the fallback, but any claim about typical real-world cohorts remains outside the scope of the current study. revision: partial
- Empirical fraction of connected real-world rider-by-condition incidence graphs (no real-world data are analyzed).
Circularity Check
No significant circularity; model uses explicit prior anchoring and graph connectivity for identification but derivation remains self-contained
full rationale
The provided text states the model explicitly as P(y=1) = sigma(a (theta_r - delta(x, s))) with delta anchored to a physics-derived expert curve as prior, and notes identification requires connected incidence graph (with single-curve fallback). Synthetic recovery (r=0.96) and Brier gain are consistency checks under the anchored generative process, not reductions of outputs to inputs by construction. No self-citation chains, uniqueness theorems from authors, ansatz smuggling, or renaming of known results appear. The separation of theta and delta is not claimed to be purely data-driven without the stated prior and connectivity; the formulation recovers the expert curve as a special case when skill is integrated out. This is a standard IRT setup with documented assumptions, self-contained against the synthetic benchmark.
Axiom & Free-Parameter Ledger
free parameters (3)
- discrimination parameter a
- rider skill parameters theta_r
- difficulty function delta(x, s)
axioms (2)
- standard math Logistic (sigmoid) response function for P(y=1)
- domain assumption Rider-by-condition incidence graph is connected for unique identification
Reference graph
Works this paper leans on
-
[1]
and Novick, Melvin R
Lord, Frederic M. and Novick, Melvin R. , title =
-
[2]
Statistical Theories of Mental Test Scores , editor =
Birnbaum, Allan , title =. Statistical Theories of Mental Test Scores , editor =
-
[3]
1960 , note =
Rasch, Georg , title =. 1960 , note =
1960
-
[4]
Darrell and Aitkin, Murray , title =
Bock, R. Darrell and Aitkin, Murray , title =. Psychometrika , volume =. 1981 , doi =
1981
-
[5]
and Kim, Seock-Ho , title =
Baker, Frank B. and Kim, Seock-Ho , title =
-
[6]
and Reise, Steven P
Embretson, Susan E. and Reise, Steven P. , title =
-
[7]
, title =
Fischer, Gerhard H. , title =. Acta Psychologica , volume =. 1973 , doi =
1973
-
[8]
2004 , doi =
Explanatory Item Response Models: A Generalized Linear and Nonlinear Approach , series =. 2004 , doi =
2004
-
[9]
and Welsch, John H
Golub, Gene H. and Welsch, John H. , title =. Mathematics of Computation , volume =. 1969 , doi =
1969
-
[10]
The Canadian Geographer , volume =
Mieczkowski, Zbigniew , title =. The Canadian Geographer , volume =. 1985 , doi =
1985
-
[11]
Atmosphere , volume =
Scott, Daniel and Rutty, Michelle and Amelung, Bas and Tang, Mantao , title =. Atmosphere , volume =. 2016 , doi =
2016
-
[12]
de Freitas, C. R. and Scott, Daniel and McBoyle, Geoff , title =. International Journal of Biometeorology , volume =. 2008 , doi =
2008
-
[13]
and Nichols, James D
MacKenzie, Darryl I. and Nichols, James D. and Lachman, Gideon B. and Droege, Sam and Royle, J. Andrew and Langtimm, Catherine A. , title =. Ecology , volume =. 2002 , doi =
2002
-
[14]
and Blanchet, F
Warton, David I. and Blanchet, F. Guillaume and O'Hara, Robert B. and Ovaskainen, Otso and Taskinen, Sara and Walker, Steven C. and Hui, Francis K. C. , title =. Trends in Ecology & Evolution , volume =. 2015 , doi =
2015
-
[15]
, title =
Brier, Glenn W. , title =. Monthly Weather Review , volume =. 1950 , doi =
1950
-
[16]
Baker and Seock-Ho Kim
Frank B. Baker and Seock-Ho Kim. Item Response Theory: Parameter Estimation Techniques. Marcel Dekker, New York, 2 edition, 2004
2004
-
[17]
Some latent trait models and their use in inferring an examinee's ability
Allan Birnbaum. Some latent trait models and their use in inferring an examinee's ability. In Frederic M. Lord and Melvin R. Novick, editors, Statistical Theories of Mental Test Scores, pages 397--479. Addison-Wesley, Reading, MA, 1968
1968
-
[18]
Darrell Bock and Murray Aitkin
R. Darrell Bock and Murray Aitkin. Marginal maximum likelihood estimation of item parameters: Application of an EM algorithm. Psychometrika, 46 0 (4): 0 443--459, 1981. doi:10.1007/BF02293801
-
[19]
Glenn W. Brier. Verification of forecasts expressed in terms of probability. Monthly Weather Review, 78 0 (1): 0 1--3, 1950. doi:10.1175/1520-0493(1950)078<0001:VOFEIT>2.0.CO;2
-
[20]
Explanatory Item Response Models: A Generalized Linear and Nonlinear Approach
Paul De Boeck and Mark Wilson, editors. Explanatory Item Response Models: A Generalized Linear and Nonlinear Approach. Statistics for Social and Behavioral Sciences. Springer, New York, NY, 2004. doi:10.1007/978-1-4757-3990-9
-
[21]
C. R. de Freitas, Daniel Scott, and Geoff McBoyle. A second generation climate index for tourism ( CIT ): Specification and verification. International Journal of Biometeorology, 52 0 (5): 0 399--407, 2008. doi:10.1007/s00484-007-0134-3
-
[22]
Embretson and Steven P
Susan E. Embretson and Steven P. Reise. Item Response Theory for Psychologists. Lawrence Erlbaum Associates, Mahwah, NJ, 2000
2000
-
[23]
Gerhard H. Fischer. The linear logistic test model as an instrument in educational research. Acta Psychologica, 37 0 (6): 0 359--374, 1973. doi:10.1016/0001-6918(73)90003-6
-
[24]
Gene H. Golub and John H. Welsch. Calculation of G auss quadrature rules. Mathematics of Computation, 23 0 (106): 0 221--230, 1969. doi:10.1090/S0025-5718-69-99647-1
-
[25]
Lord and Melvin R
Frederic M. Lord and Melvin R. Novick. Statistical Theories of Mental Test Scores. Addison-Wesley, Reading, MA, 1968
1968
-
[26]
Darryl I. MacKenzie, James D. Nichols, Gideon B. Lachman, Sam Droege, J. Andrew Royle, and Catherine A. Langtimm. Estimating site occupancy rates when detection probabilities are less than one. Ecology, 83 0 (8): 0 2248--2255, 2002. doi:10.1890/0012-9658(2002)083[2248:ESORWD]2.0.CO;2
-
[27]
The tourism climatic index: A method of evaluating world climates for tourism
Zbigniew Mieczkowski. The tourism climatic index: A method of evaluating world climates for tourism. The Canadian Geographer, 29 0 (3): 0 220--233, 1985. doi:10.1111/j.1541-0064.1985.tb00365.x
-
[28]
Probabilistic Models for Some Intelligence and Attainment Tests
Georg Rasch. Probabilistic Models for Some Intelligence and Attainment Tests. Danmarks Paedagogiske Institut, Copenhagen, 1960. Reprinted 1980, University of Chicago Press
1960
-
[29]
Daniel Scott, Michelle Rutty, Bas Amelung, and Mantao Tang. An inter-comparison of the holiday climate index ( HCI ) and the tourism climate index ( TCI ) in E urope. Atmosphere, 7 0 (6): 0 80, 2016. doi:10.3390/atmos7060080
-
[30]
David I. Warton, F. Guillaume Blanchet, Robert B. O'Hara, Otso Ovaskainen, Sara Taskinen, Steven C. Walker, and Francis K. C. Hui. So many variables: Joint modeling in community ecology. Trends in Ecology & Evolution, 30 0 (12): 0 766--779, 2015. doi:10.1016/j.tree.2015.09.007
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.