TSD: A Physics-Inspired Trajectory Saliency Detector for Efficient Imitation Learning
Pith reviewed 2026-06-26 08:04 UTC · model grok-4.3
The pith
Trajectory Saliency Detector identifies precise and agile robot motions via entropy and acceleration to enable 25% data reduction in imitation learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TSD is a plug-and-play, training-free framework that detects trajectory saliency by combining spatial entropy for precise manipulation with centripetal acceleration for agile maneuvers, thereby supporting dataset compression that lowers training costs and dataset expansion that raises data collection efficiency.
What carries the argument
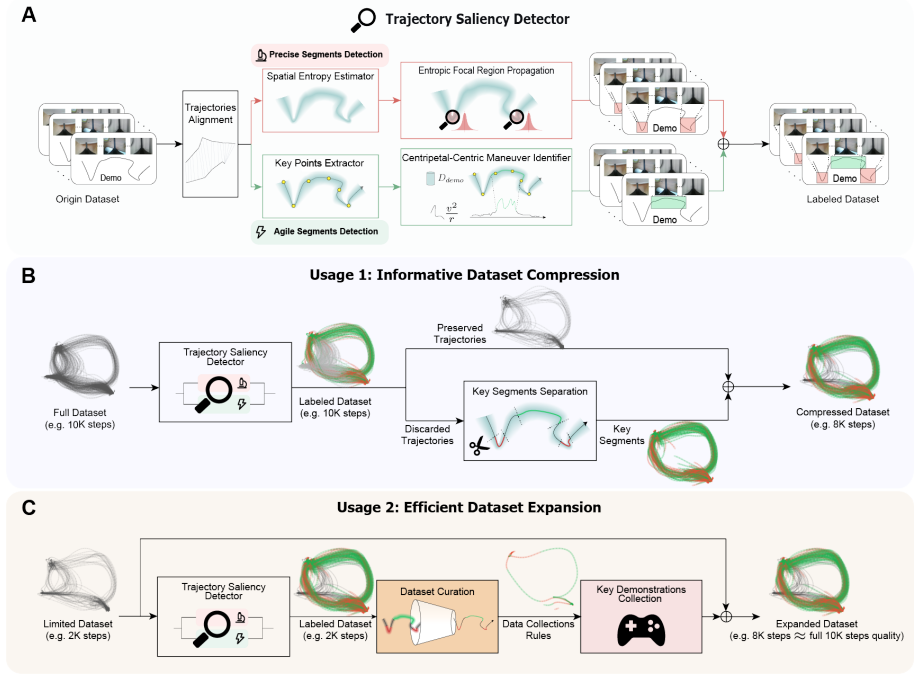
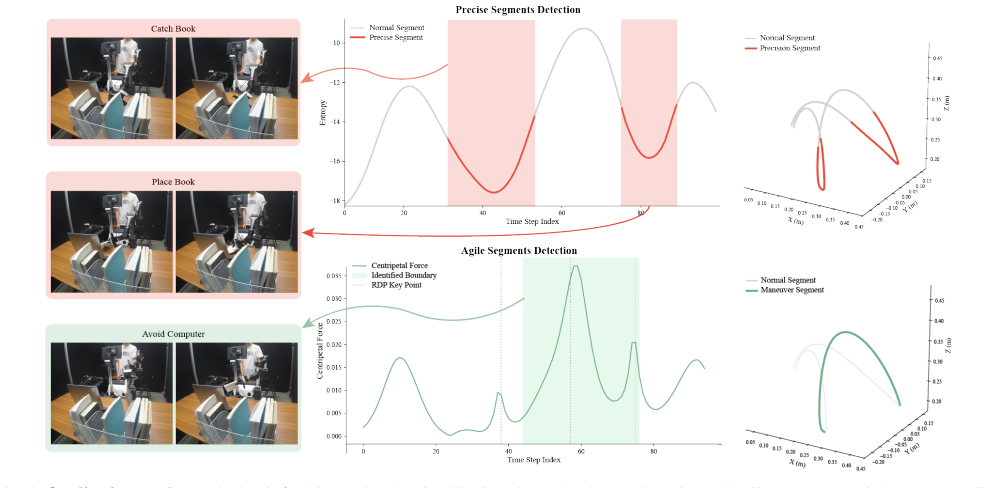
Trajectory Saliency Detector (TSD), which applies two physically-grounded metrics—spatial entropy and centripetal acceleration—to separate critical precise and agile motions from prevalent transitional motions.
If this is right
- Models trained on TSD-condensed datasets achieve comparable or superior performance with 25% less data on average in both simulation and real-world settings.
- TSD enables a dataset compression method that reduces training costs while preserving task success.
- TSD supports a dataset expansion strategy that improves the efficiency of new data collection.
- The combination of compression and expansion yields information-dense datasets that support scalable robot learning.
Where Pith is reading between the lines
- TSD could be tested on non-manipulation sequential tasks such as navigation or locomotion to check whether the same motion categories and metrics remain predictive.
- Pairing TSD with online data collection policies might allow robots to prioritize recording only salient segments during live operation.
- Additional physical signals such as force or torque derivatives could be evaluated as extensions to the existing entropy and acceleration metrics.
Load-bearing premise
Motions in manipulation tasks reliably fall into three categories where precise and agile segments are both critical to success and consistently detectable by the chosen entropy and acceleration metrics across tasks.
What would settle it
A controlled comparison in which randomly subsampled datasets of equal size to TSD-condensed ones produce equal or better task performance than TSD-condensed ones across multiple manipulation tasks would falsify the claim.
Figures

read the original abstract
For imitation learning in robotic manipulation, high data collection costs result in the scarcity of high quality data. In this paper, we leverage the inherent heterogeneity of trajectories to address this challenge. Based on our observations of manipulation tasks, we categorize motions into transitional, precise, and agile types, defining the latter two as trajectory saliency due to their criticality to task success in contrast to the prevalent but less relevant transitional motions. Therefore, we propose the Trajectory Saliency Detector (TSD), a training-free and plug-and-play framework to identify trajectory saliency. TSD employs two physically-grounded metrics: spatial entropy to capture fine-grained manipulation and centripetal acceleration to detect agile maneuvering. We further leverage TSD to develop a dataset compression method that reduces training costs and a dataset expansion strategy that improves data collection efficiency. Extensive experiments in both simulation and real-world settings demonstrate that models trained on TSD-condensed datasets achieve comparable or even superior performance with 25% less data on average. These results validate the effectiveness of our dataset compression and expansion strategies, thereby confirming the utility of TSD. Consequently, TSD offers a scalable and cost-effective pathway to synthesize information-dense datasets for efficient robot learning. Project page: https://trajectory-saliency-detector.github.io/trajectory-saliency-detector/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Trajectory Saliency Detector (TSD), a training-free, plug-and-play framework that categorizes manipulation motions into transitional, precise, and agile types and uses two physics-inspired metrics—spatial entropy for fine-grained manipulation and centripetal acceleration for agile maneuvering—to identify salient (precise and agile) trajectory segments. TSD is applied to develop dataset compression and expansion strategies for imitation learning, with the central claim that models trained on TSD-condensed datasets achieve comparable or superior performance using 25% less data on average, validated through simulation and real-world experiments.
Significance. If the metrics reliably isolate task-critical segments across manipulation tasks, TSD could reduce data collection and training costs in imitation learning by focusing on information-dense trajectories without requiring additional model training. The training-free and physics-grounded design is a notable strength that distinguishes it from learned saliency methods.
major comments (3)
- [Introduction and Abstract] The three-way motion categorization (transitional/precise/agile) and the claim that only the latter two are critical are introduced based on observations rather than a task-independent derivation or cross-task ablation; no section provides a counter-example task where spatial entropy or centripetal acceleration fails to predict success when kinematics, object properties, or success criteria change. This assumption is load-bearing for both the compression method and the 25% data-reduction claim.
- [Abstract and Experiments] The headline experimental result (comparable/superior performance with 25% less data) requires evidence that TSD subsampling outperforms random subsampling to 75% on the same tasks, yet the abstract and experiments description supply no implementation equations for the metrics, baseline comparisons, statistical tests, or exclusion criteria, rendering the central performance claim unverifiable from the provided text.
- [Experiments] No independent validation set or sensitivity analysis is described that tests metric robustness when robot kinematics or task success criteria vary, which is required to support the general applicability asserted for the dataset compression and expansion strategies.
minor comments (2)
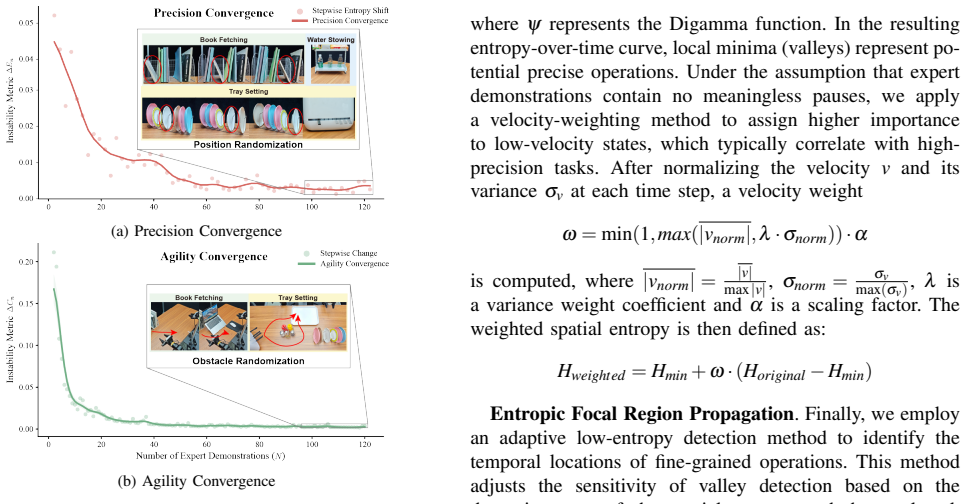
- [Abstract] The abstract states experimental outcomes but does not define the exact formulas for spatial entropy or centripetal acceleration, nor how thresholds for saliency detection are chosen.
- [Method] Notation for the two metrics should be introduced with explicit equations in the method section to allow reproduction.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed comments. We address each major comment below, indicating revisions where the manuscript will be updated to improve clarity, verifiability, and robustness.
read point-by-point responses
-
Referee: [Introduction and Abstract] The three-way motion categorization (transitional/precise/agile) and the claim that only the latter two are critical are introduced based on observations rather than a task-independent derivation or cross-task ablation; no section provides a counter-example task where spatial entropy or centripetal acceleration fails to predict success when kinematics, object properties, or success criteria change. This assumption is load-bearing for both the compression method and the 25% data-reduction claim.
Authors: The categorization is explicitly presented as observation-driven from common manipulation tasks, as stated in the introduction and abstract. The metrics themselves are grounded in general physics (spatial entropy over position distributions for precision, centripetal acceleration for curvature in agile segments) rather than task-specific learning. Experiments already span multiple simulation and real-world tasks with varying object properties and success criteria, providing cross-task support. We will add a dedicated limitations paragraph discussing scope and potential edge cases where the metrics may not align with success (e.g., tasks dominated by force rather than kinematics). revision: partial
-
Referee: [Abstract and Experiments] The headline experimental result (comparable/superior performance with 25% less data) requires evidence that TSD subsampling outperforms random subsampling to 75% on the same tasks, yet the abstract and experiments description supply no implementation equations for the metrics, baseline comparisons, statistical tests, or exclusion criteria, rendering the central performance claim unverifiable from the provided text.
Authors: Equations for spatial entropy (Eq. 1) and centripetal acceleration (Eq. 2) appear in Sections 3.2–3.3, with pseudocode for saliency detection in Algorithm 1; exclusion thresholds are defined in Section 4.1. The experiments section already reports comparisons against full datasets and alternative compression baselines, but does not explicitly include random subsampling at 75% or statistical tests. We will revise the abstract to reference the equations and add random-subsampling controls plus significance testing (e.g., paired t-tests) to the experimental results in the revised manuscript. revision: yes
-
Referee: [Experiments] No independent validation set or sensitivity analysis is described that tests metric robustness when robot kinematics or task success criteria vary, which is required to support the general applicability asserted for the dataset compression and expansion strategies.
Authors: The current evaluation uses multiple simulation environments (with differing kinematics) and real-robot tasks (with distinct success criteria), providing some implicit robustness evidence. However, a dedicated sensitivity analysis varying kinematics parameters or success thresholds is absent. We will add an ablation subsection quantifying metric stability under controlled kinematic perturbations and altered success definitions. revision: yes
Circularity Check
No significant circularity; metrics and claims rest on independent physics definitions and experimental outcomes
full rationale
The paper's core definitions (spatial entropy for fine-grained manipulation, centripetal acceleration for agile motion) are introduced as physically-grounded quantities chosen to match an observation-based categorization of motions. No equation or step reduces the reported performance gains (e.g., 25% less data) back to a fitted parameter or self-referential definition. The categorization itself is presented as an a-priori observation rather than a derived result, and no self-citation chains or uniqueness theorems are invoked in the abstract or described text. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Motions in manipulation tasks can be categorized into transitional, precise, and agile types, with the latter two being critical to task success.
invented entities (1)
-
Trajectory saliency
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Data scaling laws in imitation learning for robotic manipulation,
F. Lin et al., “Data scaling laws in imitation learning for robotic manipulation,”arXiv preprint arXiv:2410.18647, 2024
arXiv 2024
-
[2]
Libero: Benchmarking knowledge transfer for lifelong robot learning,
B. Liu et al., “Libero: Benchmarking knowledge transfer for lifelong robot learning,”Advances in Neural Information Processing Systems, vol. 36, pp. 44 776–44 791, 2023
2023
-
[3]
A pragmatic vla foundation model,
W. Wu et al., “A pragmatic vla foundation model,”arXiv preprint arXiv:2601.18692, 2026
Pith/arXiv arXiv 2026
-
[4]
Real2render2real: Scaling robot data without dynamics simulation or robot hardware,
J. Yu et al., “Real2render2real: Scaling robot data without dynamics simulation or robot hardware,”arXiv preprint arXiv:2505.09601, 2025
arXiv 2025
-
[5]
Anchordream: Repurposing video diffusion for embodiment-aware robot data synthesis,
J. Ye et al., “Anchordream: Repurposing video diffusion for embodiment-aware robot data synthesis,”arXiv preprint arXiv:2512.11797, 2025
arXiv 2025
-
[6]
Data quality in imitation learn- ing,
S. Belkhale, Y . Cui, and D. Sadigh, “Data quality in imitation learn- ing,”Advances in neural information processing systems, vol. 36, pp. 80 375–80 395, 2023
2023
-
[7]
From entropy to epiplexity: Rethinking infor- mation for computationally bounded intelligence,
M. Finzi et al., “From entropy to epiplexity: Rethinking infor- mation for computationally bounded intelligence,”arXiv preprint arXiv:2601.03220, 2026
arXiv 2026
-
[8]
Waypoint-based imitation learning for robotic manipulation,
L. X. Shi et al., “Waypoint-based imitation learning for robotic manipulation,” inConference on Robot Learning, PMLR, 2023, pp. 2195–2209
2023
-
[9]
Hydra: Hybrid robot actions for imitation learning,
S. Belkhale, Y . Cui, and D. Sadigh, “Hydra: Hybrid robot actions for imitation learning,” inConference on Robot Learning, PMLR, 2023, pp. 2113–2133
2023
-
[10]
Data retrieval with importance weights for few-shot imitation learning,
A. Xie et al., “Data retrieval with importance weights for few-shot imitation learning,” inConference on Robot Learning, PMLR, 2025, pp. 1–16
2025
-
[11]
Mimicgen: A data generation system for scalable robot learning using human demonstrations,
A. Mandlekar et al., “Mimicgen: A data generation system for scalable robot learning using human demonstrations,” inConference on Robot Learning, PMLR, 2023, pp. 1820–1864
2023
-
[12]
Demogen: Synthetic demonstration generation for data-efficient visuomotor policy learning,
Z. Xue et al., “Demogen: Synthetic demonstration generation for data-efficient visuomotor policy learning,”arXiv preprint arXiv:2502.16932, 2025
arXiv 2025
-
[13]
Dreamgen: Unlocking generalization in robot learning through video world models,
J. Jang et al., “Dreamgen: Unlocking generalization in robot learning through video world models,”arXiv preprint arXiv:2505.12705, 2025
Pith/arXiv arXiv 2025
-
[14]
Li* et al.,Momagen: Generating demonstrations under soft and hard constraints for multi-step bimanual mobile manipulation, 2025
C. Li* et al.,Momagen: Generating demonstrations under soft and hard constraints for multi-step bimanual mobile manipulation, 2025
2025
-
[15]
Curating demonstrations using online experience,
A. S. Chen et al., “Curating demonstrations using online experience,” arXiv preprint arXiv:2503.03707, 2025
arXiv 2025
-
[16]
Robot data curation with mutual information estimators,
J. Hejna et al., “Robot data curation with mutual information estimators,”arXiv preprint arXiv:2502.08623, 2025
arXiv 2025
-
[17]
Datamil: Selecting data for robot imitation learning with datamodels,
S. Dass et al., “Datamil: Selecting data for robot imitation learning with datamodels,”arXiv preprint arXiv:2505.09603, 2025
Pith/arXiv arXiv 2025
-
[18]
Demospeedup: Accelerating visuomotor poli- cies via entropy-guided demonstration acceleration,
L. Guo et al., “Demospeedup: Accelerating visuomotor poli- cies via entropy-guided demonstration acceleration,”arXiv preprint arXiv:2506.05064, 2025
arXiv 2025
-
[19]
Robosuite: A modular simulation framework and benchmark for robot learning,
Y . Zhu et al., “Robosuite: A modular simulation framework and benchmark for robot learning,”arXiv preprint arXiv:2009.12293, 2020
Pith/arXiv arXiv 2009
-
[20]
T. Chen et al., “Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation,”arXiv preprint arXiv:2506.18088, 2025
Pith/arXiv arXiv 2025
-
[21]
H. Fan et al., “Twinaligner: Visual-dynamic alignment empow- ers physics-aware real2sim2real for robotic manipulation,”arXiv preprint arXiv:2512.19390, 2025
arXiv 2025
-
[22]
M 3A policy: Mutable material manipulation aug- mentation policy through photometric re-rendering,
J. Li et al., “M 3A policy: Mutable material manipulation aug- mentation policy through photometric re-rendering,”arXiv preprint arXiv:2512.01446, 2025
arXiv 2025
-
[23]
Motus: A unified latent action world model,
H. Bi et al., “Motus: A unified latent action world model,”arXiv preprint arXiv:2512.13030, 2025
Pith/arXiv arXiv 2025
-
[24]
Behavior retrieval: Few-shot imitation learning by querying unlabeled datasets,
M. Du et al., “Behavior retrieval: Few-shot imitation learning by querying unlabeled datasets,”arXiv preprint arXiv:2304.08742, 2023
arXiv 2023
-
[25]
Flowretrieval: Flow-guided data retrieval for few- shot imitation learning,
L.-H. Lin et al., “Flowretrieval: Flow-guided data retrieval for few- shot imitation learning,” inConference on Robot Learning, PMLR, 2025, pp. 4084–4099
2025
-
[26]
Learning and retrieval from prior data for skill- based imitation learning,
S. Nasiriany et al., “Learning and retrieval from prior data for skill- based imitation learning,” inConference on Robot Learning, PMLR, 2023, pp. 2181–2204
2023
-
[27]
Ram: Retrieval-based affordance transfer for gen- eralizable zero-shot robotic manipulation,
Y . Kuang et al., “Ram: Retrieval-based affordance transfer for gen- eralizable zero-shot robotic manipulation,” inConference on Robot Learning, PMLR, 2025, pp. 547–565
2025
-
[28]
Learning to discern: Imitating heterogeneous human demonstrations with preference and representation learning,
S. Kuhar et al., “Learning to discern: Imitating heterogeneous human demonstrations with preference and representation learning,” inConference on Robot Learning, PMLR, 2023, pp. 1437–1449
2023
-
[29]
Computing and visualizing dynamic time warping alignments in r: The dtw package,
T. Giorgino, “Computing and visualizing dynamic time warping alignments in r: The dtw package,”Journal of statistical Software, vol. 31, pp. 1–24, 2009
2009
-
[30]
Dynamic time warping: Itakura vs sakoe-chiba,
Z. Geler et al., “Dynamic time warping: Itakura vs sakoe-chiba,” in 2019 IEEE International Symposium on INnovations in Intelligent SysTems and Applications (INISTA), IEEE, 2019, pp. 1–6
2019
-
[31]
Algorithms for the reduction of the number of points required to represent a digitized line or its caricature,
D. H. Douglas and T. K. Peucker, “Algorithms for the reduction of the number of points required to represent a digitized line or its caricature,”Cartographica: the international journal for geographic information and geovisualization, vol. 10, no. 2, pp. 112–122, 1973
1973
-
[32]
What matters in learning from offline hu- man demonstrations for robot manipulation,
A. Mandlekar et al., “What matters in learning from offline hu- man demonstrations for robot manipulation,” inarXiv preprint arXiv:2108.03298, 2021
Pith/arXiv arXiv 2021
-
[33]
Diffusion policy: Visuomotor policy learning via action diffusion,
C. Chi et al., “Diffusion policy: Visuomotor policy learning via action diffusion,”The International Journal of Robotics Research, vol. 44, no. 10-11, pp. 1684–1704, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.