Refining Effect-Size Measures and Classification for Differential Item Functioning: Toward Unified Guidelines Across Methods
Pith reviewed 2026-06-26 13:21 UTC · model grok-4.3
The pith
Common effect-size measures for differential item functioning underestimate bias magnitude and produce inconsistent classifications that depend on study design.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
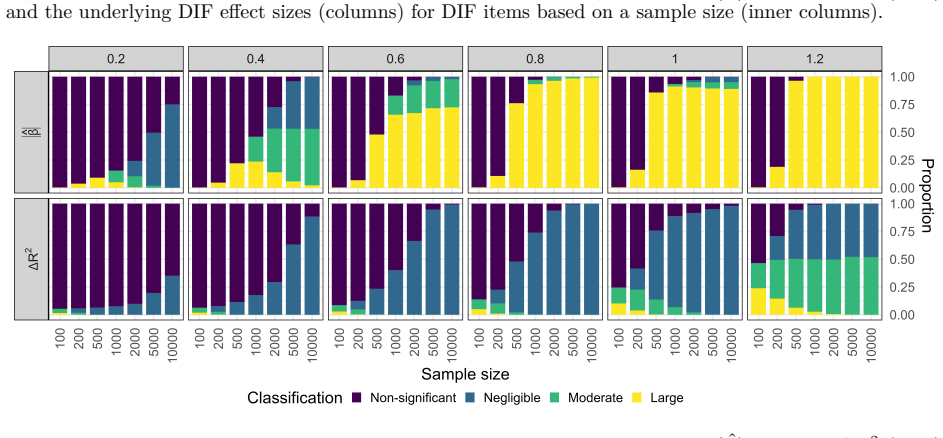
Some commonly used effect-size measures exhibit undesirable properties, including inconsistent classifications, systematic underestimation of the magnitude of the underlying DIF, and strong dependence on design factors. To address these issues, usage restrictions for some effect-size measures are introduced, cut-off values are revised to unify results across different methods, and new cut-off values for area-based effect-size measures are proposed.
What carries the argument
Effect-size measures and their magnitude classification cut-offs for DIF methods (Mantel-Haenszel, SIBTEST, model-based, and area-based).
If this is right
- Revised cut-offs produce consistent magnitude classifications for the same underlying DIF across Mantel-Haenszel, SIBTEST, and model-based methods.
- Usage restrictions remove measures whose values change markedly with sample size or ability distribution.
- New cut-offs for area-based measures reduce the systematic underestimation of DIF magnitude.
- The R implementation allows immediate application of the revised guidelines to new datasets.
Where Pith is reading between the lines
- Adoption of the unified cut-offs would change how many items are flagged as having negligible, moderate, or large DIF in existing testing programs.
- Area-based measures with the new cut-offs may become preferred when the goal is to estimate the practical size of bias rather than merely detect its presence.
- The same simulation framework could be reused to derive cut-offs for polytomous items or for other DIF methods not covered here.
Load-bearing premise
The simulation conditions and design factors examined are representative enough that the identified problems and proposed revised cut-offs will generalize to the range of real DIF applications and data structures encountered in practice.
What would settle it
A new simulation or real-data analysis under design conditions outside those examined in the study that produces materially different recommended cut-off values or different inconsistency patterns.
Figures


read the original abstract
Differential Item Functioning (DIF) analysis is used to identify potentially biased items in multi-item measurements. In addition to testing the statistical significance, it is essential to evaluate the practical significance of DIF through effect-size measures. We review existing DIF effect-size measures and cut-off values used to classify the effect-size magnitudes for the Mantel-Haenszel test, SIBTEST, and model-based methods for binary items, and introduce a refinement of area-based effect-size measures. A simulation study is conducted to investigate the properties of these effect-size measures and existing classification guidelines, and to assess their comparative performance. The results indicate that some commonly used effect-size measures exhibit undesirable properties, including inconsistent classifications, systematic underestimation of the magnitude of the underlying DIF, and strong dependence on design factors. To address these issues, we introduce usage restrictions for some effect-size measures, revise cut-off values that unify results across different methods, and propose new cut-off values for area-based effect-size measures. The methods are demonstrated using two real data examples. Implementation is provided in the R software.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reviews existing effect-size measures and cut-off values for the Mantel-Haenszel test, SIBTEST, and model-based methods applied to binary items in DIF analysis. It introduces refinements to area-based effect-size measures and reports a simulation study examining their properties, including inconsistent classifications across methods, systematic underestimation of DIF magnitude, and dependence on design factors. The authors propose usage restrictions for some measures, revised cut-offs to unify results across methods, and new cut-offs for area-based measures. These are illustrated with two real-data examples and implemented in R.
Significance. If the simulation-based findings on undesirable properties and the proposed revisions generalize, the work could improve consistency and accuracy in assessing practical significance of DIF, a key step beyond statistical significance testing in psychometrics and test validation. The provision of R code and real-data demonstrations adds reproducibility value.
major comments (2)
- [Simulation Study section] Simulation Study section: The manuscript does not enumerate the exact levels of all design factors (sample sizes, item parameters, DIF magnitudes, base rates) or include coverage checks against real DIF applications (e.g., polytomous items, extreme base rates, multilevel data), which is load-bearing for the claim that revised cut-offs will unify results and generalize beyond the simulated conditions.
- [Results section] Results section (tables reporting classification consistency): The reported inconsistencies and underestimation are tied to the specific simulation design; without sensitivity analyses varying unexamined factors, it is unclear whether the proposed revised cut-offs (e.g., for MH and SIBTEST) remain stable or merely reflect the chosen regimes.
minor comments (2)
- [Abstract] Abstract: The specific numerical values of the revised and new cut-offs are not stated, which would help readers immediately assess the practical changes proposed.
- [Real data examples] The real-data examples section would benefit from explicit comparison of classifications before and after applying the new guidelines to illustrate the impact.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on manuscript arXiv:2606.21531. We address each major comment below, with revisions planned where they strengthen clarity without altering the paper's stated scope to binary items.
read point-by-point responses
-
Referee: [Simulation Study section] Simulation Study section: The manuscript does not enumerate the exact levels of all design factors (sample sizes, item parameters, DIF magnitudes, base rates) or include coverage checks against real DIF applications (e.g., polytomous items, extreme base rates, multilevel data), which is load-bearing for the claim that revised cut-offs will unify results and generalize beyond the simulated conditions.
Authors: The simulation section describes the factors and levels drawn from the DIF literature for binary items, but we agree an explicit consolidated table would enhance transparency. We will insert this table in the revised version. The manuscript scope is limited to binary items (as stated in the abstract), so no coverage of polytomous or multilevel cases is claimed; we will add explicit language in the discussion and limitations sections to bound the generalizability of the proposed cut-offs and avoid implying broader applicability. revision: partial
-
Referee: [Results section] Results section (tables reporting classification consistency): The reported inconsistencies and underestimation are tied to the specific simulation design; without sensitivity analyses varying unexamined factors, it is unclear whether the proposed revised cut-offs (e.g., for MH and SIBTEST) remain stable or merely reflect the chosen regimes.
Authors: The design covers a range of realistic binary-item conditions; the observed inconsistencies are presented as evidence of limitations in existing measures under those conditions. We accept that additional sensitivity checks on unexamined factors would further test stability. In revision we will expand the discussion to note this limitation explicitly and frame the revised cut-offs as applicable within the simulated regimes, with a call for future work on broader sensitivity. revision: partial
Circularity Check
No significant circularity; recommendations derive from independent simulation results
full rationale
The paper reviews existing DIF effect-size measures, runs a simulation study to assess their properties (inconsistent classifications, underestimation, design dependence), and proposes usage restrictions plus revised/new cut-offs based on those simulation outcomes. No step reduces by construction to a fitted parameter renamed as prediction, self-definition of the target quantity, or a load-bearing self-citation chain. The central claims rest on the simulation design and observed performance metrics rather than tautological equivalence to inputs. This is the expected non-finding for a simulation-driven guideline paper.
Axiom & Free-Parameter Ledger
free parameters (1)
- revised and new cut-off values for effect-size classification
axioms (1)
- domain assumption The statistical properties observed in the simulated DIF conditions reflect the behavior of the measures in applied settings.
Reference graph
Works this paper leans on
-
[1]
Agresti, A. (2002).Categorical data analysis(Seconded.). JohnWiley&Sons, Inc. doi: 10.1002/0471249688
-
[2]
Barton, M. A., & Lord, F. M. (1981). An upper asymptote for the three-parameter logistic item-response model.ETS Research Report Series,1981(1), i-8. doi: 10.1002/j.2333-8504.1981.tb01255.x
-
[3]
Birnbaum, A. (1968). Some latent trait models and their use in inferring an examinee’s ability. In F. M. Lord & M. R. Novick (Eds.),Statistical theories of mental test scores(pp. 397–479). Addison-Wesley,
1968
-
[4]
Camilli, G., & Congdon, P. (1999). Application of a method of estimating DIF for polytomous test items. Journal of Educational and Behavioral Statistics,24(4), 323–341. doi: 10.3102/10769986024004323
-
[5]
Camilli, G., & Shepard, L. A. (1994).Methods for identifying biased test items(Vol. 4). SAGE Publications, Inc
1994
-
[6]
Chalmers, R. P. (2018). Improving the crossing-SIBTEST statistic for detecting non-uniform DIF.Psy- chometrika,83(2), 376–386. doi: 10.1007/s11336-017-9583-8
-
[7]
Chalmers, R. P. (2023). A unified comparison of IRT-based effect sizes for DIF investigations.Journal of Educational Measurement,60(2), 318–350. doi: 10.1111/jedm.12347
-
[8]
Cohen, J. (1992). A power primer.Psychological Bulletin,112(1), 155–159. doi: 10.1037/0033-2909.112.1 .155 24 Toward Unified DIF Effect-Size GuidelinesA Preprint
-
[9]
B., Scott, D., Roosen, C., Magnusson, A., & Swinton, J
Dahl, D. B., Scott, D., Roosen, C., Magnusson, A., & Swinton, J. (2019). xtable: Export tables to LaTeX or HTML [Computer software manual]. Retrieved fromhttps://CRAN.R-project.org/package=xtable (R package version 1.8-4)
2019
-
[10]
Dorans, N. J., & Holland, P. W. (1993). DIF detection and description: Mantel-Haenszel and standard- ization. In P. W. Holland & H. Wainer (Eds.),Differential item functioning(pp. 35–66). Lawrence Erlbaum Associates, Inc. doi: 10.4324/9780203357811
-
[11]
Dorans, N. J., & Kulick, E. (1986). Demonstrating the utility of the standardization approach to assessing unexpected differential item performance on the Scholastic Aptitude Test.Journal of Educational Measurement,23(4), 355–368. doi: 10.1111/j.1745-3984.1986.tb00255.x
-
[12]
Dorans, N. J., & Schmitt, A. P. (1993). Constructed response and differential item functioning: A pragmatic approach. InW.C.Ward&R.E.Bennett(Eds.),Construction versus choice in cognitive measurement: Issues in constructed response, performance testing, and portfolio assessment(pp. 135–166). Lawrence Erlbaum Associates, Inc. Drabinová, A., & Martinková, P....
-
[13]
French, B. F., & Maller, S. J. (2007). Iterative purification and effect size use with logistic regression for differential item functioning detection.Educational and Psychological Measurement,67(3), 373–393. doi: 10.1177/0013164406294781
-
[14]
Garnier, S. (2024). Colorblind-friendly color maps for R [Computer software manual]. Retrieved from https://sjmgarnier.github.io/viridis/(viridis package version 0.6.5) doi: 10.32614/CRAN .package.viridis
-
[15]
Gilbert, J. B., Kim, J. S., & Miratrix, L. W. (2023). Modeling item-level heterogeneous treatment effects with the explanatory item response model: Leveraging large-scale online assessments to pinpoint the impact of educational interventions.Journal of Educational and Behavioral Statistics,48(6), 889–913. Gómez-Benito, J., Hidalgo, M. D., & Padilla, J.-L....
-
[16]
K., Clauser, B
Hambleton, R. K., Clauser, B. E., Mazor, K. M., & Jones, R. W. (1993).Advances in the detection of differentially functioning test items(Tech. Rep.). University of Massachusetts at Amherst
1993
-
[17]
Hidalgo, M. D., & LóPez-Pina, J. A. (2004). Differential item functioning detection and effect size: A comparison between logistic regression and mantel-haenszel procedures.Educational and Psychological Measurement,64(6), 903–915. doi: 10.1177/0013164403261769 Hladká, A., Martinková, P.,&Brabec, M. (2026). Newiterativealgorithmsforestimationofitemfunction...
-
[18]
Holland, P. W., & Thayer, D. T. (1985). An alternate definition of the ETS delta scale of item difficulty. ETS Research Report Series,1985(2), i–10. doi: 10.1002/j.2330-8516.1985.tb00128.x
-
[19]
W., & Thayer, D
Holland, P. W., & Thayer, D. T. (1988). Differential item performance and the Mantel-Haenszel procedure. In H. Wainer & H. I. Braun (Eds.),Test validity(pp. 129–145). Hillsdale, New Jersey: Lawrence Erlbaum Associates, Inc
1988
-
[20]
Jodoin, M. G., & Gierl, M. J. (2001). Evaluating type I error and power rates using an effect size measure with the logistic regression procedure for DIF detection.Applied Measurement in Education,14(4), 329–349. doi: 10.1207/S15324818AME1404_2
-
[21]
Kim, S.-H., Cohen, A. S., Alagoz, C., & Kim, S. (2007). DIF detection and effect size measures for polytomously scored items.Journal of Educational Measurement,44(2), 93–116. doi: 10.1111/j.1745 -3984.2007.00029.x
-
[22]
Li, H.-H., & Stout, W. (1996). A new procedure for detection of crossing DIF.Psychometrika,61(4), 647–677. doi: 10.1007/BF02294041
-
[23]
(1968).Statistical theories of mental test scores
Lord, F., Novick, M., & Birnbaum, A. (1968).Statistical theories of mental test scores. Addison-Wesley
1968
-
[24]
Magis, D., Beland, S., Tuerlinckx, F., & De Boeck, P. (2010). A general framework and an R package for the detection of dichotomous differential item functioning.Behavior Research Methods,42, 847–862. doi: 10.3758/BRM.42.3.847
-
[25]
Mantel, N., & Haenszel, W. (1959). Statistical aspects of the analysis of data from retrospective studies. Journal of the National Cancer Institute,22(4), 719–748. doi: 10.1093/jnci/22.4.719 25 Toward Unified DIF Effect-Size GuidelinesA Preprint Martinková, P., & Drabinová, A. (2018). ShinyItemAnalysis for teaching psychometrics and to enforce routine ana...
-
[26]
Monahan, P. O., McHorney, C. A., Stump, T. E., & Perkins, A. J. (2007). Odds ratio, delta, ETS classification, and standardization measures of DIF magnitude for binary logistic regression.Journal of Educational and Behavioral Statistics,32, 92–109. doi: 10.3102/1076998606298035
-
[27]
Narayanon, P., & Swaminathan, H. (1996). Identification of items that show nonuniform DIF.Applied Psychological Measurement,20(3), 257–274. doi: 10.1177/014662169602000306
-
[28]
J., & Everson, H
Osterlind, S. J., & Everson, H. T. (2009).Differential item functioning(Second ed.). Thousand Oaks, CA: SAGE Publications, Inc
2009
-
[29]
T., & Dorans, N
Potenza, M. T., & Dorans, N. J. (1995). DIF assessment for polytomously scored items: A framework for classification and evaluation.Applied Psychological Measurement,19(1), 23–37. doi: 10.1177/ 014662169501900104 R Core Team. (2023). R: A language and environment for statistical computing [Computer software manual]
1995
-
[30]
Raju, N. S. (1988). The area between two item characteristic curves.Psychometrika,53(4), 495–502. doi: 10.1007/BF02294403
-
[31]
W., De Looze, M., Nic Gabhainn, S.,
Roberts, C., Freeman, J., Samdal, O., Schnohr, C. W., De Looze, M., Nic Gabhainn, S., ... Group, I. H. S. (2009). The Health Behaviour in School-aged Children (HBSC) study: Methodological developments and current tensions.International Journal of Public Health,54, 140–150. doi: 10.1007/s00038-009 -5405-9
-
[32]
Roussos, L. A., & Stout, W. F. (1996). Simulation studies of the effects of small sample size and studied item parameters on SIBTEST and Mantel-Haenszel type I error performance.Journal of Educational Measurement,33(2), 215–230. doi: 10.1111/j.1745-3984.1996.tb00490.x
-
[33]
Rudner, L. M. (1977). An approach to biased item identification using latent trait measurement theory. ERIC. (Paper presented at the Annual Meeting of the American Educational Research Association, New York, New York)
1977
-
[34]
Shealy, R., & Stout, W. (1993). A model-based standardization approach that separates true bias/DIF from group ability differences and detects test bias/DTF as well as item bias/DIF.Psychometrika,58(2), 159–194. doi: 10.1007/BF02294572
-
[35]
Student, S. R. (2026). Causal parameter moderation: Applying moderated nonlinear factor analysis to causal inference with latent outcomes.Journal of Educational and Behavioral Statistics, 10769986251414869
2026
-
[36]
Suh, Y. (2016). Effect size measures for differential item functioning in a multidimensional IRT model. Journal of Educational Measurement,53(4), 403–430. doi: 10.1111/jedm.12123
-
[37]
Swaminathan, H., & Rogers, H. J. (1990). Detecting differential item functioning using logistic regression procedures.Journal of Educational Measurement,27(4), 361–370. doi: 10.1111/j.1745-3984.1990 .tb00754.x
-
[38]
Wainer, H. (1993). Model-based standardized measurement of an item’s differential impact. In P. W. Holland & H. Wainer (Eds.),Differential item functioning(pp. 123–135). Lawrence Erlbaum Associates, Inc
1993
-
[39]
Weese, J. D., Turner, R. C., Ames, A., Crawford, B., & Liang, X. (2022). Reevaluating the SIBTEST classification heuristics for dichotomous differential item functioning.Educational and Psychological Measurement,82(2), 307–329. doi: 10.1177/00131644211017267
-
[40]
(2016).ggplot2: Elegant graphics for data analysis
Wickham, H. (2016).ggplot2: Elegant graphics for data analysis. Springer-Verlag New York. Retrieved from https://ggplot2.tidyverse.org
2016
-
[41]
Wickham, H., François, R., Henry, L., Müller, K., & Vaughan, D. (2023). dplyr: A grammar of data manipulation [Computer software manual]. (R package version 1.1.4) doi: 10.32614/CRAN.package .dplyr
-
[42]
Wickham, H., Vaughan, D., & Girlich, M. (2024). tidyr: Tidy messy data [Computer software manual]. (R package version 1.3.1) doi: 10.32614/CRAN.package.tidyr 26 Toward Unified DIF Effect-Size GuidelinesA Preprint
-
[43]
Zumbo, B. D. (1999).A handbook on the theory and methods of differential item functioning (DIF): Logistic regression modeling as a unitary framework for binary and Likert-type (ordinal) item scores. Ottawa, ON: Directorate of Human Resources Research and Evaluation, Department of National Defense
1999
-
[44]
D., & Thomas, D
Zumbo, B. D., & Thomas, D. (1997).A measure of effect size for a model-based approach for studying DIF (Working paper of the Edgeworth laboratory for quantitative behavioral science).Prince George, Canada: University of Northern British Columbia
1997
-
[45]
Zwick, R., & Ercikan, K. (1989). Analysis of differential item functioning in the NAEP history assessment. Journal of Educational Measurement,26(1), 55–66. doi: 10.1111/j.1745-3984.1989.tb00318.x 27 Toward Unified DIF Effect-Size GuidelinesA Preprint Appendices A Supplementary tables Table A1: Item parameters of the 4PL IRT model used to generate non-DIF ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.