RoBoSR: Structured Scene Representations for Embodied Robotic Reasoning
Pith reviewed 2026-06-26 00:16 UTC · model grok-4.3
The pith
Object-centric scene graphs let robots reason over state transitions instead of raw inputs for manipulation tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RoBoSR formulates manipulation as step-wise state transitions over semantically grounded, object-centric scene graphs. By placing this representation at the perception-action interface, the method disentangles high-level task reasoning from raw sensory data and supplies structured access to preconditions, effects, and goal states, thereby enabling causal reasoning, enforcement of subtask dependencies, and coherent planning across long horizons.
What carries the argument
Step-wise state transitions defined on object-centric scene graphs that track object states and spatial relations between perception and action.
If this is right
- Task planning can enforce explicit causal dependencies among subtasks rather than learning them only from demonstration order.
- The same intermediate graph supports both instruction interpretation and prediction of future states without retraining the entire policy.
- Zero-shot transfer improves because new tasks are expressed as changes to the same graph vocabulary rather than new end-to-end mappings.
- Long-horizon coherence increases because each transition updates only the affected objects and relations instead of regenerating an entire plan.
Where Pith is reading between the lines
- The same graph interface could be reused for navigation or mobile manipulation if the node and edge vocabulary is extended to include movable bases and free space.
- If reliable graph construction proves harder than expected, hybrid systems that fall back to raw-image reasoning only on uncertain nodes become a natural next design.
- The dataset construction method suggests that joint supervision of perception and planning can be scaled by mining existing robot logs rather than requiring new human annotations for every task.
Load-bearing premise
Object-centric scene graphs that are semantically accurate can be built and maintained from real-world sensor data despite lighting, occlusion, and viewpoint changes.
What would settle it
A controlled trial in which perception noise produces incorrect scene-graph edges or node attributes and task success collapses even though the downstream planner receives the correct high-level goal.
Figures


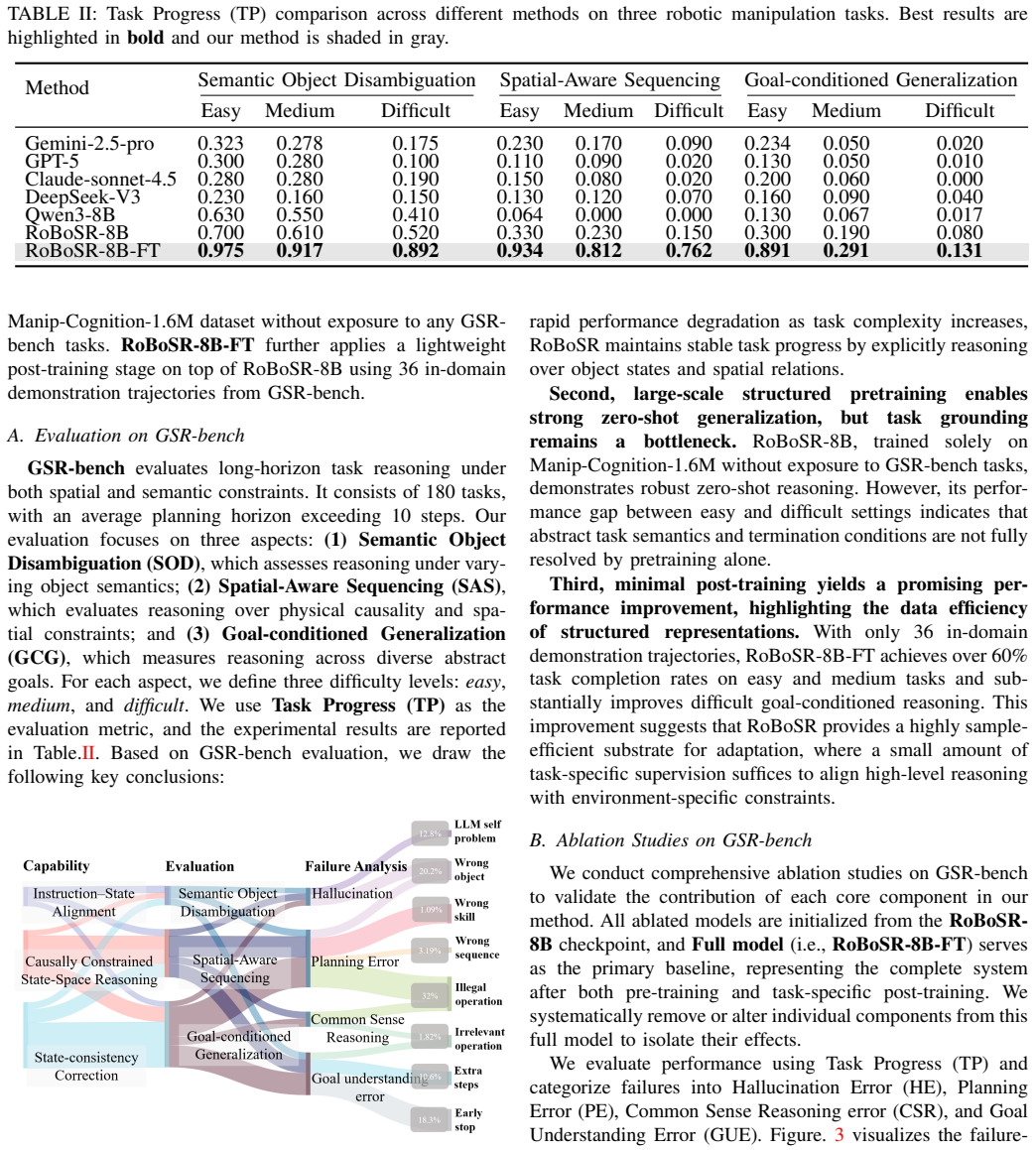
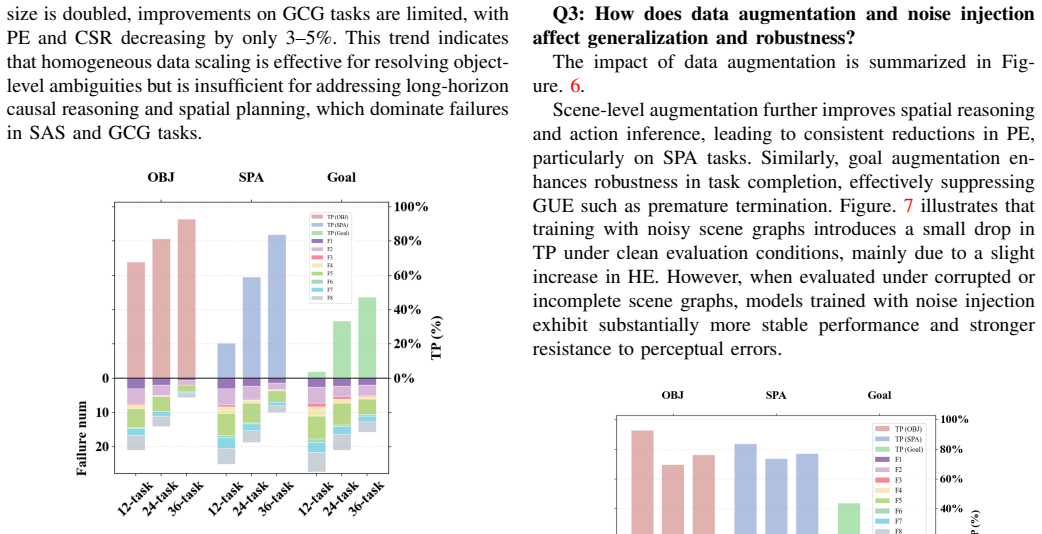

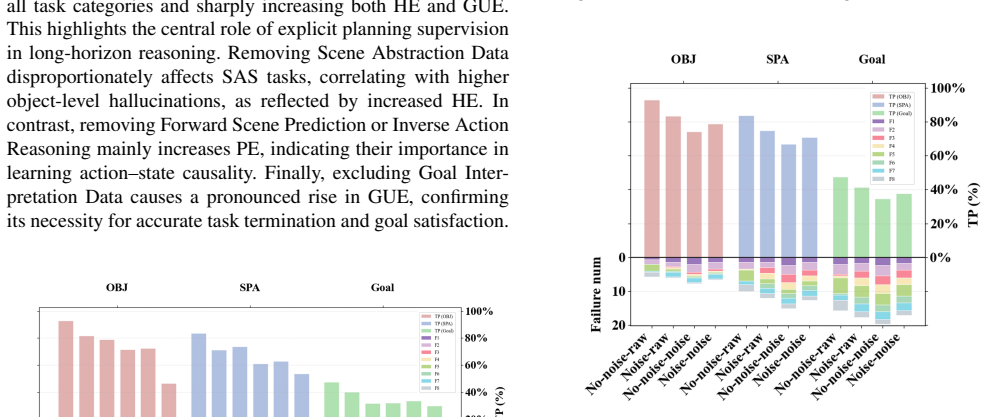
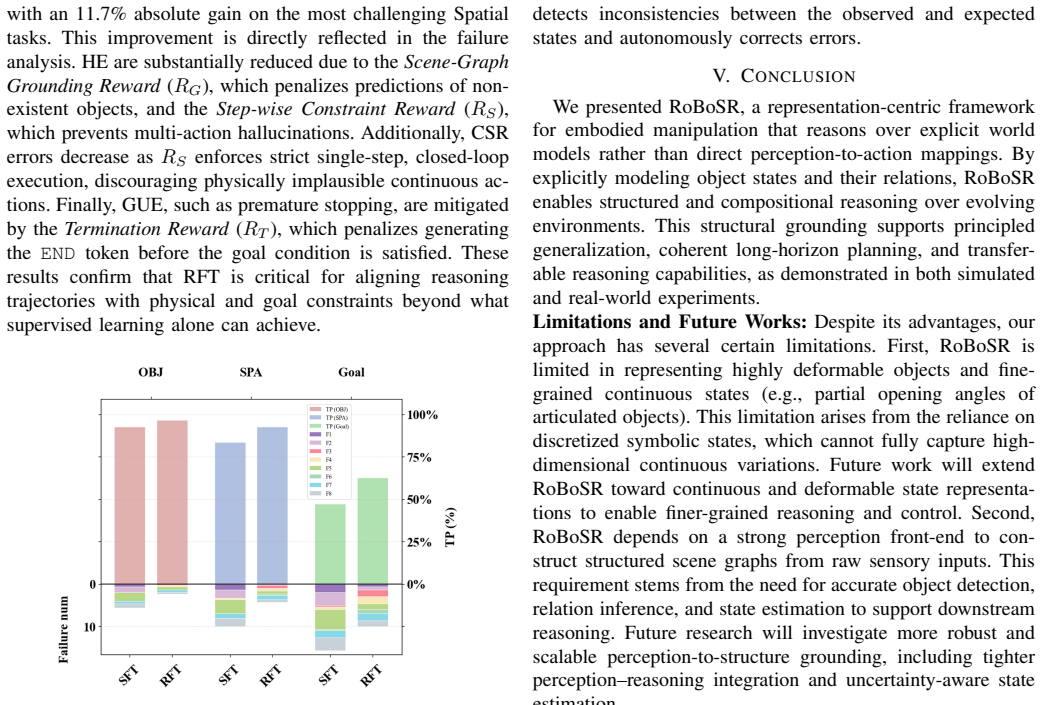

read the original abstract
Despite rapid progress, embodied reasoning under real-world variability remains challenging. Existing approaches rely on demonstration-driven sequential biases, limiting flexibility in open-ended and long-horizon tasks that require structured reasoning over evolving states. We introduce RoBoSR, an intermediate structural representation that formulates manipulation as step-wise state transitions over semantically grounded, object-centric scene graphs. By modeling object states and their spatial relations at the perception-action interface, RoBoSR disentangles high-level task reasoning from raw inputs and enables structured reasoning over preconditions, effects, and goal states. This representation endows the agent with causal reasoning capability, enforcing subtask dependencies and supporting coherent long-horizon task planning. To learn such structure-aware reasoning, we construct Manip-Cognition-1.6M, an open-world dataset that jointly supervises scene understanding, instruction interpretation, and subtask planning across diverse tasks. Across several benchmarks and real-world demonstrations, our method consistently outperforms prompting-based methods and classical TAMP baselines in zero-shot generalization and long-horizon tasks. The results underscore structured intermediate representations as a critical inductive bias for scalable embodied reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that by introducing RoBoSR, an intermediate structural representation based on semantically grounded, object-centric scene graphs for modeling manipulation as state transitions, it disentangles high-level task reasoning from raw inputs. This enables structured reasoning over preconditions, effects, and goal states. The authors construct the Manip-Cognition-1.6M dataset to supervise scene understanding, instruction interpretation, and subtask planning, and report that their method outperforms prompting-based methods and classical TAMP baselines in zero-shot generalization and long-horizon tasks across benchmarks and real-world demonstrations.
Significance. If the results hold, this work could be significant for embodied robotic reasoning by demonstrating the value of structured intermediate representations as an inductive bias for causal reasoning and better generalization in long-horizon tasks. The introduction of a large-scale dataset for joint supervision of multiple aspects of the task is a positive contribution that could benefit the community.
major comments (2)
- [Abstract] The central claim of outperformance and the ability to enforce subtask dependencies rests on the assumption that object-centric scene graphs can be reliably constructed and maintained from perception under real-world variability. However, the abstract provides no quantitative evidence or details on graph construction accuracy, robustness to sensor noise, lighting, or occlusion, or error accumulation over time. This is load-bearing for whether the claimed disentanglement and generalization gains follow.
- [Abstract] The Manip-Cognition-1.6M dataset is described as jointly supervising scene understanding, instruction interpretation, and subtask planning at sufficient scale and quality to produce the claimed improvements, but no details on dataset construction, annotation quality, or empirical validation of its effectiveness are provided in the abstract. Without this, the link between the dataset and the reported zero-shot and long-horizon performance is not established.
minor comments (1)
- [Abstract] The abstract refers to 'several benchmarks' without naming them, which would help readers assess the scope of the evaluation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments on the abstract point by point below, with proposed revisions to better support the claims.
read point-by-point responses
-
Referee: [Abstract] The central claim of outperformance and the ability to enforce subtask dependencies rests on the assumption that object-centric scene graphs can be reliably constructed and maintained from perception under real-world variability. However, the abstract provides no quantitative evidence or details on graph construction accuracy, robustness to sensor noise, lighting, or occlusion, or error accumulation over time. This is load-bearing for whether the claimed disentanglement and generalization gains follow.
Authors: We agree the abstract should more explicitly support this assumption. The manuscript body reports quantitative results on scene graph construction from perception, including accuracy metrics and real-world robustness evaluations across lighting, occlusion, and long-horizon sequences that demonstrate the representation's reliability and support the claimed generalization. We will revise the abstract to summarize these key supporting results. revision: yes
-
Referee: [Abstract] The Manip-Cognition-1.6M dataset is described as jointly supervising scene understanding, instruction interpretation, and subtask planning at sufficient scale and quality to produce the claimed improvements, but no details on dataset construction, annotation quality, or empirical validation of its effectiveness are provided in the abstract. Without this, the link between the dataset and the reported zero-shot and long-horizon performance is not established.
Authors: We agree that the abstract would benefit from additional context on the dataset. The manuscript provides details on dataset construction, annotation procedures, quality controls, and empirical validation through ablations and downstream performance in the main text. We will revise the abstract to include a concise summary of these elements to strengthen the connection to the reported results. revision: yes
Circularity Check
No significant circularity in claimed derivation chain
full rationale
The paper introduces a new intermediate representation (RoBoSR) formulated as step-wise state transitions over object-centric scene graphs and a new dataset (Manip-Cognition-1.6M) for joint supervision of scene understanding, instruction interpretation, and planning. No equations, derivations, or fitted parameters are shown that reduce by construction to inputs. Outperformance claims rest on empirical benchmarks against prompting and TAMP baselines rather than self-definitional predictions or load-bearing self-citations. The central inductive bias is the proposed structured representation itself, which is externally falsifiable via the reported experiments and does not collapse to renaming or ansatz smuggling.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Object states and spatial relations can be accurately perceived and represented as semantically grounded scene graphs under real-world variability.
Reference graph
Works this paper leans on
-
[1]
Pi0: A vision-language-action flow model for general robot control,
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichteret al., “Pi0: A vision-language-action flow model for general robot control,”arXiv preprint arXiv:2410.24164, 2024
Pith/arXiv arXiv 2024
-
[2]
Cot-vla: Visual chain-of-thought reasoning for vision-language-action models,
Q. Zhao, Y . Lu, M. J. Kim, Z. Fu, Z. Zhang, Y . Wu, Z. Li, Q. Ma, S. Han, C. Finnet al., “Cot-vla: Visual chain-of-thought reasoning for vision-language-action models,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 1702–1713
2025
-
[3]
Roboscript: Code generation for free- form manipulation tasks across real and simulation,
J. Chen, Y . Mu, Q. Yu, T. Wei, S. Wu, Z. Yuan, Z. Liang, C. Yang, K. Zhang, W. Shaoet al., “Roboscript: Code generation for free- form manipulation tasks across real and simulation,”arXiv preprint arXiv:2402.14623, 2024
arXiv 2024
-
[4]
Robobrain: A unified brain model for robotic manipulation from abstract to concrete,
Y . Ji, H. Tan, J. Shi, X. Hao, Y . Zhang, H. Zhang, P. Wang, M. Zhao, Y . Mu, P. Anet al., “Robobrain: A unified brain model for robotic manipulation from abstract to concrete,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 1724–1734
2025
-
[5]
Rt-2: Vision-language-action models transfer web knowledge to robotic control,
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahidet al., “Rt-2: Vision-language-action models transfer web knowledge to robotic control,” inConference on Robot Learning. PMLR, 2023, pp. 2165–2183
2023
-
[6]
Openvla: An open- source vision-language-action model,
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketiet al., “Openvla: An open- source vision-language-action model,”arXiv preprint arXiv:2406.09246, 2024
Pith/arXiv arXiv 2024
-
[7]
A review of learning-based dynamics models for robotic manipulation,
B. Ai, S. Tian, H. Shi, Y . Wang, T. Pfaff, C. Tan, H. I. Christensen, H. Su, J. Wu, and Y . Li, “A review of learning-based dynamics models for robotic manipulation,”Science Robotics, vol. 10, no. 106, p. eadt1497, 2025
2025
-
[8]
Rt-1: Robotics transformer for real-world control at scale,
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Hausman, A. Herzog, J. Hsuet al., “Rt-1: Robotics transformer for real-world control at scale,”arXiv preprint arXiv:2212.06817, 2022. Fig. 9: Real-world demonstrations of RoBoSR on instruction-driven manipulation tasks.Top:Instruction–State Alignment for a language-gu...
Pith/arXiv arXiv 2022
-
[9]
Rt-h: Action hierarchies using language,
S. Belkhale, T. Ding, T. Xiao, P. Sermanet, Q. Vuong, J. Tompson, Y . Chebotar, D. Dwibedi, and D. Sadigh, “Rt-h: Action hierarchies using language,”arXiv preprint arXiv:2403.01823, 2024
Pith/arXiv arXiv 2024
-
[10]
Foundation models for decision making: Problems, methods, and opportunities,
S. Yang, O. Nachum, Y . Du, J. Wei, P. Abbeel, and D. Schuurmans, “Foundation models for decision making: Problems, methods, and opportunities,”arXiv preprint arXiv:2303.04129, 2023
arXiv 2023
-
[11]
Scene graph generation: A comprehensive survey,
H. Li, G. Zhu, L. Zhang, Y . Jiang, Y . Dang, H. Hou, P. Shen, X. Zhao, S. A. A. Shah, and M. Bennamoun, “Scene graph generation: A comprehensive survey,”Neurocomputing, vol. 566, p. 127052, 2024
2024
-
[12]
Concept- graphs: Open-vocabulary 3d scene graphs for perception and planning,
Q. Gu, A. Kuwajerwala, S. Morin, K. M. Jatavallabhula, B. Sen, A. Agarwal, C. Rivera, W. Paul, K. Ellis, R. Chellappaet al., “Concept- graphs: Open-vocabulary 3d scene graphs for perception and planning,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 5021–5028
2024
-
[13]
Enact: Evaluating embodied cognition with world modeling of egocentric interaction,
Q. Wang, W. Huang, Y . Zhou, H. Yin, T. Bao, J. Lyu, W. Liu, R. Zhang, J. Wu, L. Fei-Feiet al., “Enact: Evaluating embodied cognition with world modeling of egocentric interaction,”arXiv preprint arXiv:2511.20937, 2025
arXiv 2025
-
[14]
V oxposer: Composable 3d value maps for robotic manipulation with language models,
W. Huang, C. Wang, R. Zhang, Y . Li, J. Wu, and L. Fei-Fei, “V oxposer: Composable 3d value maps for robotic manipulation with language models,”arXiv preprint arXiv:2307.05973, 2023
Pith/arXiv arXiv 2023
-
[15]
Rekep: Spatio- temporal reasoning of relational keypoint constraints for robotic manip- ulation,
W. Huang, C. Wang, Y . Li, R. Zhang, and L. Fei-Fei, “Rekep: Spatio- temporal reasoning of relational keypoint constraints for robotic manip- ulation,”arXiv preprint arXiv:2409.01652, 2024
Pith/arXiv arXiv 2024
-
[16]
The epic- kitchens dataset: Collection, challenges and baselines,
D. Damen, H. Doughty, G. M. Farinella, S. Fidler, A. Furnari, E. Kaza- kos, D. Moltisanti, J. Munro, T. Perrett, W. Priceet al., “The epic- kitchens dataset: Collection, challenges and baselines,”IEEE Transac- tions on Pattern Analysis and Machine Intelligence, vol. 43, no. 11, pp. 4125–4141, 2020
2020
-
[17]
Egoplan-bench: Benchmarking multimodal large language models for human-level planning,
Y . Chen, Y . Ge, Y . Ge, M. Ding, B. Li, R. Wang, R. Xu, Y . Shan, and X. Liu, “Egoplan-bench: Benchmarking multimodal large language models for human-level planning,”arXiv preprint arXiv:2312.06722, 2023
arXiv 2023
-
[18]
C. Li, R. Zhang, J. Wong, C. Gokmen, S. Srivastava, R. Mart ´ın-Mart´ın, C. Wang, G. Levine, W. Ai, B. Martinezet al., “Behavior-1k: A human- centered, embodied ai benchmark with 1,000 everyday activities and realistic simulation,”arXiv preprint arXiv:2403.09227, 2024
Pith/arXiv arXiv 2024
-
[19]
Qwen3: Think Deeper, Act Faster,
Qwen Team, “Qwen3: Think Deeper, Act Faster,” Apr. 2025, accessed: 2025-04-29. [Online]. Available: https://openai.com/zh-Hans-CN/index/ gpt-5-system-card/
2025
-
[20]
Skil: Semantic keypoint imitation learning for generalizable data-efficient manipulation,
S. Wang, J. You, Y . Hu, J. Li, and Y . Gao, “Skil: Semantic keypoint imitation learning for generalizable data-efficient manipulation,”arXiv preprint arXiv:2501.14400, 2025
arXiv 2025
-
[21]
Ground scene reasoning(GSR)-bench,
GSRbench, “Ground scene reasoning(GSR)-bench,” Apr. 2026. [Online]. Available: https://github.com/KLMmotion/GSR-bench/
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.