SPACE: Enabling Learning from Cross-Robot Data Toward Generalist Policies
Pith reviewed 2026-06-26 00:47 UTC · model grok-4.3
The pith
SPACE lets robot policies learn from mixed data across different machines by predicting Cartesian state deltas instead of specific commands.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
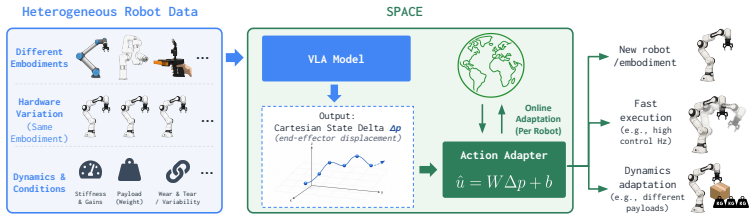
SPACE consists of a Cartesian state delta policy that predicts geometric end-effector displacement and an Action Adapter that converts the prediction into robot-specific control commands. This structure handles robot dynamics variation at three levels: across different embodiments, across hardware units of the same embodiment, and within a single robot during operation.
What carries the argument
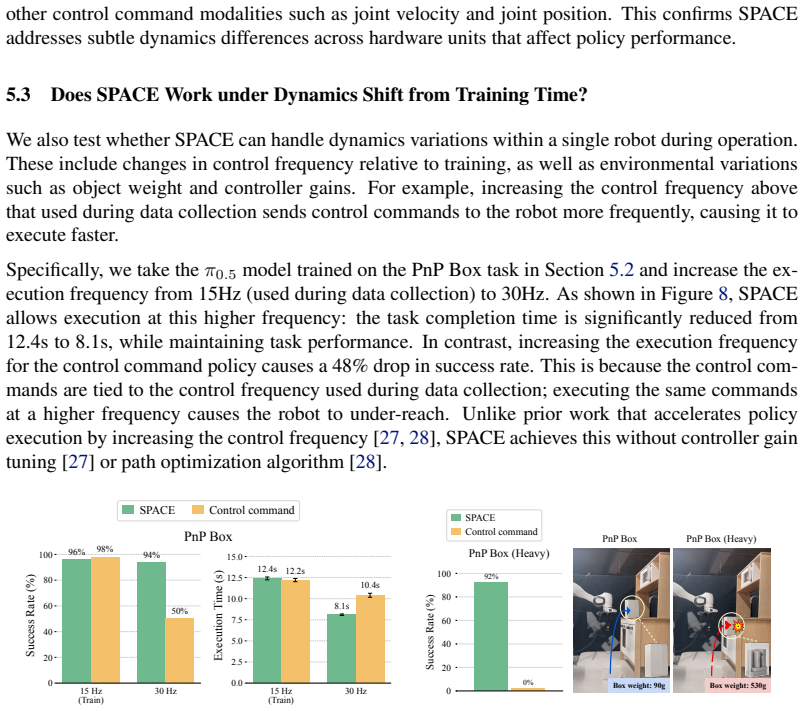
Cartesian state delta as a universal action representation, together with an Action Adapter that maps the predicted delta to embodiment-specific commands.
If this is right
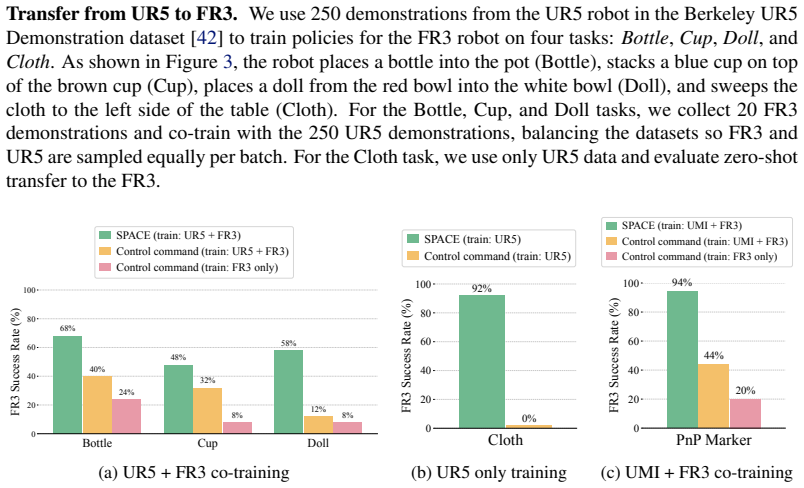
- Policies trained with SPACE substantially outperform those that directly predict control commands when using data collected across different embodiments and across hardware units of the same embodiment.
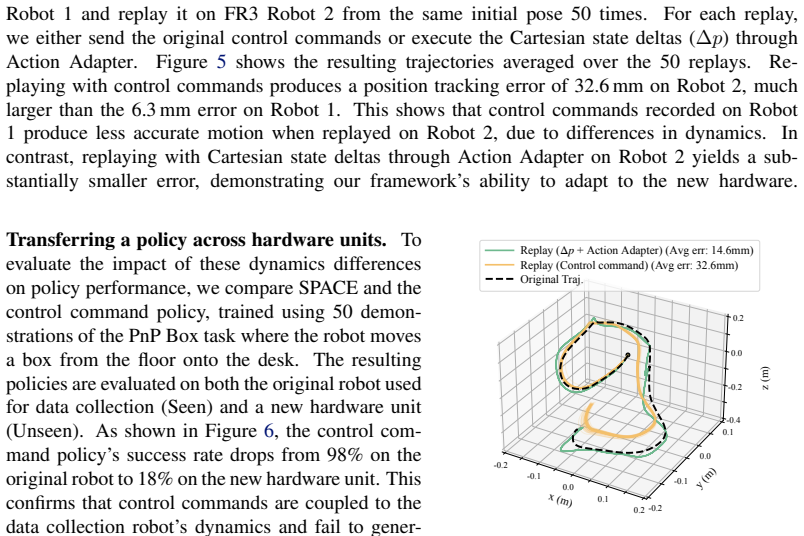
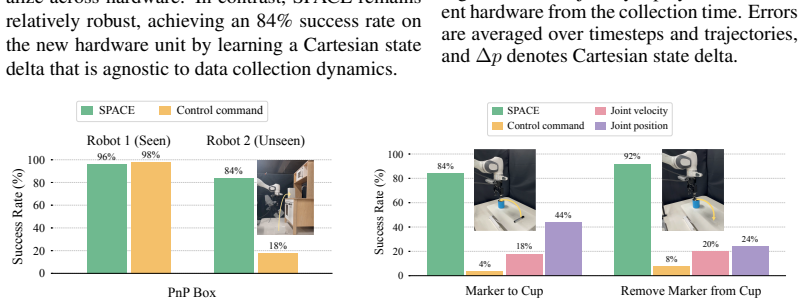
- SPACE remains robust under dynamics shifts at deployment, including changes in control frequency, object weight, and controller gains.
- The shared Cartesian representation enables effective behavior cloning from aggregated datasets that would otherwise be incompatible due to embodiment-specific actions.
Where Pith is reading between the lines
- The same delta-based separation could be tested with additional sensor modalities to further reduce embodiment dependence in policy training.
- If the adapter requires per-robot calibration data, the method's advantage would shrink for entirely novel hardware with no prior examples.
- Extending the approach to include visual or force observations as part of the shared state could address cases where end-effector position alone is insufficient.
Load-bearing premise
The assumption that an Action Adapter can reliably map a predicted Cartesian state delta into accurate robot-specific commands for any embodiment or hardware unit without introducing large errors that would negate the benefit of the shared representation.
What would settle it
A controlled test on a new robot embodiment where the Action Adapter produces large command errors, causing the full SPACE policy to achieve lower task success than a baseline that directly predicts control commands from the same mixed data.
Figures




read the original abstract
In robot learning, scaling training datasets across diverse embodiments and environments has become a dominant paradigm for learning generalizable robot policies. These policies are commonly trained via behavior cloning to imitate actions from pre-collected demonstrations. However, since robot actions are tied to the dynamics of the data collection robot, different robots may require different actions to achieve the same motion. This discrepancy hinders both policy training and deployment across diverse robots. To address this, we propose using Cartesian state delta as a universal action representation across robots, and introduce State Prediction and Adaptive Command Execution (SPACE) framework. SPACE handles robot dynamics variation at three levels: across different embodiments, across hardware units of the same embodiment, and within a single robot during operation. It consists of two components: (i) a Cartesian state delta policy that predicts geometric end-effector displacement, and (ii) Action Adapter, which converts the predicted Cartesian state delta into robot-specific control commands. Experiments show that SPACE substantially outperforms policies that directly predict control commands when learning from data collected across different embodiments and across hardware units of the same embodiment. SPACE also remains robust under dynamics shifts at deployment, including changes in control frequency, object weight, and controller gains. The project page is available at http://haeone.site/space-website/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the SPACE framework for learning generalist robot policies from cross-embodiment and cross-hardware-unit data. It replaces direct command prediction with a policy that outputs Cartesian state deltas (geometric end-effector displacements) as a universal representation, paired with an Action Adapter that converts these deltas into robot-specific control commands. The approach is intended to handle dynamics variation at three levels: across embodiments, across units of the same embodiment, and within a single robot at deployment. The abstract states that experiments demonstrate substantial outperformance over direct command prediction and robustness to shifts in control frequency, object weight, and controller gains.
Significance. If the empirical claims are substantiated with quantitative results, the separation of a shared geometric policy from an embodiment-specific adapter could provide a practical route to scaling behavior-cloning datasets across heterogeneous robots. The core idea of using Cartesian deltas to decouple policy learning from robot dynamics is a clear conceptual contribution to cross-robot generalization.
major comments (2)
- [Abstract] Abstract: the central empirical claim that SPACE 'substantially outperforms policies that directly predict control commands' is presented without any reported metrics, baseline details, dataset sizes, number of trials, or statistical tests, preventing assessment of whether the data support the claim.
- [Abstract] Abstract: the load-bearing assumption that the Action Adapter maps predicted Cartesian state deltas to accurate robot-specific commands across embodiments, hardware units, and deployment shifts (frequency, mass, gains) receives no quantitative validation; no adapter command-error metrics, ablations isolating the adapter, or failure-case analysis are described.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and constructive feedback on the abstract. We agree that the abstract would benefit from additional quantitative details to better support the claims. We will revise the manuscript to address these points.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim that SPACE 'substantially outperforms policies that directly predict control commands' is presented without any reported metrics, baseline details, dataset sizes, number of trials, or statistical tests, preventing assessment of whether the data support the claim.
Authors: We agree that the abstract lacks specific metrics and details. In the revised version, we will update the abstract to include key quantitative results such as success rate improvements (e.g., average success rates across tasks), number of evaluation trials, and references to the experimental sections and tables that detail baselines, dataset sizes, and any statistical comparisons. This will make the empirical claims more self-contained while preserving the abstract's brevity. revision: yes
-
Referee: [Abstract] Abstract: the load-bearing assumption that the Action Adapter maps predicted Cartesian state deltas to accurate robot-specific commands across embodiments, hardware units, and deployment shifts (frequency, mass, gains) receives no quantitative validation; no adapter command-error metrics, ablations isolating the adapter, or failure-case analysis are described.
Authors: We acknowledge that the abstract does not provide quantitative validation or metrics for the Action Adapter. The full manuscript includes relevant ablations, command-error metrics under varying conditions, and robustness results in the experiments (Section 4). We will revise the abstract to briefly reference these adapter-specific results and the demonstrated robustness to shifts, ensuring the adapter's contribution is supported by evidence from the paper. revision: yes
Circularity Check
No circularity; empirical framework with no derivation chain
full rationale
The paper introduces SPACE as a two-component framework (Cartesian state delta policy + Action Adapter) and supports its claims exclusively via experimental comparisons on cross-embodiment and cross-unit data. No equations, fitted parameters, or first-principles derivations are present in the provided text. The central claims (outperformance and robustness) are statistical outcomes of training and evaluation, not quantities that reduce to their own inputs by construction. Self-citation patterns, ansatz smuggling, or uniqueness theorems are absent. This is a standard empirical robotics paper whose validity hinges on experimental design rather than any self-referential mathematical structure.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
R. Bommasani, D. A. Hudson, E. Adeli, R. Altman, S. Arora, S. von Arx, M. S. Bernstein, J. Bohg, A. Bosselut, E. Brunskill, et al. On the opportunities and risks of foundation models. arXiv preprint arXiv:2108.07258, 2021
Pith/arXiv arXiv 2021
-
[2]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
Pith/arXiv arXiv 2023
-
[3]
G. Comanici, E. Bieber, M. Schaekermann, I. Pasupat, N. Sachdeva, I. Dhillon, M. Blistein, O. Ram, D. Zhang, E. Rosen, et al. Gemini 2.5: Pushing the frontier with advanced rea- soning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
Pith/arXiv arXiv 2025
-
[4]
O’Neill, A
A. O’Neill, A. Rehman, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain, et al. Open x-embodiment: Robotic learning datasets and rt-x models. InInternational Conference on Robotics and Automation, 2024
2024
-
[5]
H.-S. Fang, H. Fang, Z. Tang, J. Liu, C. Wang, J. Wang, H. Zhu, and C. Lu. Rh20t: A compre- hensive robotic dataset for learning diverse skills in one-shot. InInternational Conference on Robotics and Automation, 2024
2024
-
[6]
K. Wu, C. Hou, J. Liu, Z. Che, X. Ju, Z. Yang, M. Li, Y . Zhao, Z. Xu, G. Yang, et al. Robomind: Benchmark on multi-embodiment intelligence normative data for robot manipulation.arXiv preprint arXiv:2412.13877, 2024
Pith/arXiv arXiv 2024
-
[7]
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Ellis, et al. Droid: A large-scale in-the-wild robot manipulation dataset.arXiv preprint arXiv:2403.12945, 2024
Pith/arXiv arXiv 2024
-
[8]
Q. Bu, J. Cai, L. Chen, X. Cui, Y . Ding, S. Feng, S. Gao, X. He, X. Hu, X. Huang, et al. Agibot world colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems.arXiv preprint arXiv:2503.06669, 2025
Pith/arXiv arXiv 2025
-
[9]
M. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
Pith/arXiv arXiv 2024
-
[10]
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al.π 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
Pith/arXiv arXiv 2024
-
[11]
K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fu- sai, et al.π 0.5: a vision-language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025
Pith/arXiv arXiv 2025
-
[12]
J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
Pith/arXiv arXiv 2025
-
[13]
Zheng, J
J. Zheng, J. Li, D. Liu, Y . Zheng, Z. Wang, Z. Ou, Y . Liu, J. Liu, Y .-Q. Zhang, and X. Zhan. Universal actions for enhanced embodied foundation models. InComputer Vision and Pattern Recognition Conference, 2025. 10
2025
-
[14]
A. Bronars, Y . Park, and P. Agrawal. Tune to learn: How controller gains shape robot policy learning.arXiv preprint arXiv:2604.02523, 2026
Pith/arXiv arXiv 2026
-
[15]
O. M. Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, T. Kreiman, C. Xu, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024
Pith/arXiv arXiv 2024
-
[16]
Brohan, N
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, et al. Rt-1: Robotics transformer for real-world control at scale. In Robotics: Science and Systems, 2023
2023
-
[17]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. In Conference on Robot Learning, 2023
2023
-
[18]
J. Wen, Y . Zhu, J. Li, Z. Tang, C. Shen, and F. Feng. Dexvla: Vision-language model with plug-in diffusion expert for general robot control. InConference on Robot Learning, 2025
2025
-
[19]
J. Zheng, J. Li, Z. Wang, D. Liu, X. Kang, Y . Feng, Y . Zheng, J. Zou, Y . Chen, J. Zeng, et al. X- vla: Soft-prompted transformer as scalable cross-embodiment vision-language-action model. arXiv preprint arXiv:2510.10274, 2025
Pith/arXiv arXiv 2025
-
[20]
S. Ye, J. Jang, B. Jeon, S. J. Joo, J. Yang, B. Peng, A. Mandlekar, R. Tan, Y .-W. Chao, B. Y . Lin, et al. Latent action pretraining from videos. InInternational Conference on Learning Representations, 2025
2025
-
[21]
X. B. Peng, M. Andrychowicz, W. Zaremba, and P. Abbeel. Sim-to-real transfer of robotic con- trol with dynamics randomization. InInternational Conference on Robotics and Automation, 2018
2018
-
[22]
Andrychowicz, B
M. Andrychowicz, B. Baker, M. Chociej, R. Jozefowicz, B. McGrew, J. Pachocki, A. Petron, M. Plappert, G. Powell, A. Ray, et al. Learning dexterous in-hand manipulation.The Interna- tional Journal of Robotics Research, 39(1):3–20, 2020
2020
-
[23]
A. Kumar, Z. Fu, D. Pathak, and J. Malik. Rma: Rapid motor adaptation for legged robots. arXiv preprint arXiv:2107.04034, 2021
Pith/arXiv arXiv 2021
-
[24]
H. Qi, A. Kumar, R. Calandra, Y . Ma, and J. Malik. In-hand object rotation via rapid motor adaptation. InConference on Robot Learning, 2023
2023
-
[25]
Torabi, G
F. Torabi, G. Warnell, and P. Stone. Behavioral cloning from observation. InInternational Joint Conference on Artificial Intelligence, 2018
2018
-
[26]
Radosavovic, X
I. Radosavovic, X. Wang, L. Pinto, and J. Malik. State-only imitation learning for dexterous manipulation. InInternational Conference on Intelligent Robots and Systems, 2021
2021
-
[27]
N. R. Arachchige, Z. Chen, W. Jung, W. C. Shin, R. Bansal, P. Barroso, Y . H. He, Y . C. Lin, B. Joffe, S. Kousik, et al. Sail: Faster-than-demonstration execution of imitation learning policies. InConference on Robot Learning, 2025
2025
-
[28]
S. Kim, J. Kim, and J. J. Lim. Time optimal execution of action chunk policies beyond demon- stration speed. InInternational Conference on Learning Representations, 2026
2026
-
[29]
C. Chi, Z. Xu, C. Pan, E. Cousineau, B. Burchfiel, S. Feng, R. Tedrake, and S. Song. Universal manipulation interface: In-the-wild robot teaching without in-the-wild robots. InRobotics: Science and Systems, 2024
2024
-
[30]
Zhaxizhuoma, K
Z. Zhaxizhuoma, K. Liu, C. Guan, Z. Jia, Z. Wu, X. Liu, T. Wang, S. Liang, P. Chen, P. Zhang, et al. Fastumi: A scalable and hardware-independent universal manipulation interface with dataset. InConference on Robot Learning, 2025. 11
2025
-
[31]
D. A. Pomerleau. Alvinn: An autonomous land vehicle in a neural network. InAdvances in Neural Information Processing Systems, 1988
1988
-
[32]
Y . Feng, J. Zheng, Z. Wang, D. Liu, J. Li, J. Pang, T. Wang, and X. Zhan. Demystifying action space design for robotic manipulation policies.arXiv preprint arXiv:2602.23408, 2026
Pith/arXiv arXiv 2026
-
[33]
O. Khatib. A unified approach for motion and force control of robot manipulators: The opera- tional space formulation.IEEE Journal on Robotics and Automation, 3(1):43–53, 1987
1987
-
[34]
L. Y . Chen, K. Hari, K. Dharmarajan, C. Xu, Q. Vuong, and K. Goldberg. Mirage: Cross- embodiment zero-shot policy transfer with cross-painting. InRobotics: Science and Systems, 2024
2024
-
[35]
L. Hao, R. Pagani, M. Beschi, and G. Legnani. Dynamic and friction parameters of an indus- trial robot: Identification, comparison and repetitiveness analysis.Robotics, 10(1):49, 2021
2021
-
[36]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipulation with low-cost hardware. InRobotics: Science and Systems, 2023
2023
-
[37]
Akgun, M
B. Akgun, M. Cakmak, J. W. Yoo, and A. L. Thomaz. Trajectories and keyframes for kinesthetic teaching: A human-robot interaction perspective. InInternational Conference on Human-Robot Interaction, 2012
2012
-
[38]
H. Li, Y . Cui, and D. Sadigh. How to train your robots? the impact of demonstration modality on imitation learning. InInternational Conference on Robotics and Automation, 2025
2025
-
[39]
Haykin and B
S. Haykin and B. Widrow. Least-mean-square adaptive filters. 2003
2003
-
[40]
S. Ye, Y . Ge, K. Zheng, S. Gao, S. Yu, G. Kurian, S. Indupuru, Y . L. Tan, C. Zhu, J. Xiang, et al. World action models are zero-shot policies.arXiv preprint arXiv:2602.15922, 2026
Pith/arXiv arXiv 2026
-
[41]
Atreya, K
P. Atreya, K. Pertsch, T. Lee, M. J. Kim, A. Jain, A. Kuramshin, C. Neary, E. S. Hu, K. Arora, K. Ellis, et al. Roboarena: Distributed real-world evaluation of generalist robot policies. In Conference on Robot Learning, 2025
2025
-
[42]
UMI data
L. Y . Chen, S. Adebola, and K. Goldberg. Berkeley UR5 demonstration dataset.https: //sites.google.com/view/berkeley-ur5/home. 12 Appendix A Pseudo Code Algorithm 1SPACE rollout with Action Adapter 1:Given:Cartesian state delta policyπ θ 2:Define:Action adapterˆu“W 0∆p`b 0 and its learning rateµ 3:CollectMcalibration trajectories with lengthK,D cal “ ttp0...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.