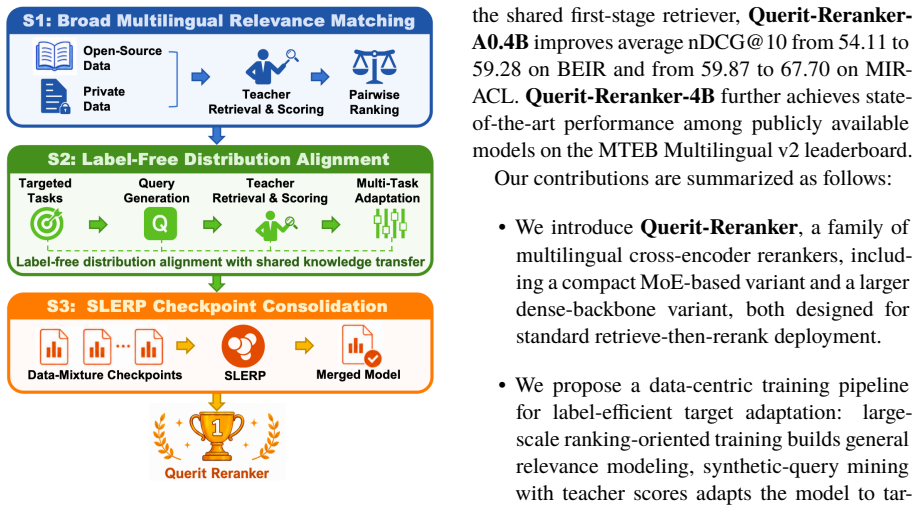
Querit-Reranker: Training Compact Multilingual Rerankers via Efficient Label-Free Distribution Adaptation
Pith reviewed 2026-06-26 19:25 UTC · model grok-4.3
The pith
A pipeline using synthetic queries and teacher soft labels trains compact multilingual rerankers that adapt to new distributions without task annotations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that multilingual cross-encoder rerankers can be effectively trained and adapted label-free by first learning general relevance from large-scale data, then performing distribution adaptation via synthetic query mining with continuous soft labels from a teacher, and finally consolidating models through spherical linear interpolation of checkpoints.
What carries the argument
The distribution adaptation pipeline based on synthetic-query mining with teacher-provided soft labels, followed by spherical linear interpolation merging of task-adapted checkpoints.
If this is right
- With a shared first-stage retriever, the 0.4B model increases average nDCG@10 from 54.11 to 59.28 on the BEIR benchmark.
- The 0.4B model raises average nDCG@10 from 59.87 to 67.70 on the MIRACL benchmark.
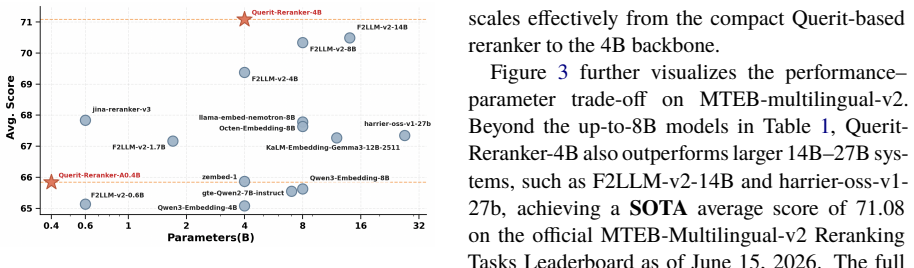
- The 4B variant achieves state-of-the-art results among publicly available models on MTEB Multilingual v2 Reranking.
- The adapted models outperform larger embedding-based baselines on multilingual reranking tasks.
Where Pith is reading between the lines
- This method suggests that synthetic data can substitute for human annotations in reranker training, potentially enabling faster iteration on new domains.
- Similar adaptation techniques might help in other areas of natural language processing where distribution shift is common but labels are scarce.
- The checkpoint merging step indicates that ensembling benefits can be captured in a single model for deployment efficiency.
Load-bearing premise
The synthetic queries and their teacher-assigned soft labels accurately capture the characteristics of real queries and relevance judgments in the target distribution.
What would settle it
Running the trained reranker on a collection of real human-labeled queries from one of the target distributions and observing no improvement or a decline relative to the first-stage retriever would indicate that the adaptation has not succeeded.
Figures

read the original abstract
Deployable multilingual rerankers must generalize across languages, domains, and target ranking tasks while remaining efficient enough for second-stage reranking. However, adapting them to new target distributions typically requires extensive task-specific relevance annotations, which are costly to obtain. We present Querit-Reranker, a family of multilingual cross-encoder rerankers trained with a data-centric pipeline for label-efficient adaptation. We instantiate it as Querit-Reranker-A0.4B, initialized from an in-house MoE backbone with 0.4B activated parameters, and Querit-Reranker-4B, initialized from Qwen3-Embedding-4B. Our pipeline first learns general relevance modeling from large-scale ranking-oriented data, then adapts to target distributions through synthetic-query mining with teacher scores as continuous soft labels. To consolidate complementary task-adapted strengths, we further merge checkpoints via spherical linear interpolation, obtaining a single deployable model without runtime ensembling overhead. Using Qwen3-Embedding-0.6B as the shared first-stage retriever, Querit-Reranker-A0.4B improves average nDCG@10 from 54.11 to 59.28 on BEIR and from 59.87 to 67.70 on MIRACL. On MTEB Multilingual v2 Reranking, it also substantially outperforms larger embedding-based baselines, while Querit-Reranker-4B further achieves state-of-the-art performance among publicly available models. We release both models on Hugging Face.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Querit-Reranker, a family of compact multilingual cross-encoder rerankers. It describes a data-centric pipeline that first trains on large-scale ranking data for general relevance modeling, then adapts to target distributions via synthetic query mining using a teacher model's continuous scores as soft labels. Checkpoints are merged with spherical linear interpolation. Using Qwen3-Embedding-0.6B as first-stage retriever, the 0.4B variant reports nDCG@10 gains from 54.11 to 59.28 on BEIR and 59.87 to 67.70 on MIRACL; the 4B variant reaches SOTA among public models on MTEB Multilingual v2 Reranking. Models are released on Hugging Face.
Significance. If the synthetic adaptation step holds, the work provides a practical route to label-efficient multilingual reranker adaptation, reducing reliance on costly annotations while maintaining deployable sizes. The concrete benchmark lifts and public model release strengthen reproducibility and potential impact in cross-lingual IR.
major comments (1)
- [Method section (synthetic-query mining and soft-label adaptation)] Method section (synthetic-query mining and soft-label adaptation): The reported nDCG@10 lifts on BEIR and MIRACL rest on the assumption that mined synthetic queries and teacher scores faithfully represent real query distributions and relevance patterns. No quantitative validation (e.g., lexical/intent overlap statistics, human evaluation of synthetic relevance, or ablation replacing synthetic labels with real annotations) is described, leaving the gains vulnerable to distribution shift or label noise.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for validation of the synthetic-query mining and soft-label adaptation steps. We address this point below and commit to revisions that strengthen the empirical grounding of our claims.
read point-by-point responses
-
Referee: Method section (synthetic-query mining and soft-label adaptation): The reported nDCG@10 lifts on BEIR and MIRACL rest on the assumption that mined synthetic queries and teacher scores faithfully represent real query distributions and relevance patterns. No quantitative validation (e.g., lexical/intent overlap statistics, human evaluation of synthetic relevance, or ablation replacing synthetic labels with real annotations) is described, leaving the gains vulnerable to distribution shift or label noise.
Authors: We agree that the manuscript would benefit from explicit validation of the synthetic data quality. The current results rely on downstream performance as the primary indicator of adaptation success. In the revised version we will add: (i) lexical and embedding-based overlap statistics between synthetic and held-out real queries on MIRACL subsets, (ii) an ablation that substitutes synthetic soft labels with available real annotations on a subset of tasks, and (iii) a short discussion of observed distribution-shift risks. These additions will appear in Sections 3 and 4. revision: yes
Circularity Check
No circularity: empirical pipeline with benchmark measurements
full rationale
The paper presents a training pipeline (general relevance pretraining followed by synthetic-query mining using teacher soft labels, then checkpoint merging) and reports direct nDCG@10 measurements on BEIR and MIRACL. No mathematical derivations, equations, or fitted parameters are described that could reduce to the inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The central claims are empirical improvements on external benchmarks rather than quantities derived inside the same model or equations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Synthetic queries mined from the target distribution plus teacher soft labels accurately capture real query relevance patterns without bias or shift
Reference graph
Works this paper leans on
-
[1]
Arcee’s mergekit: A toolkit for merging large language models. Preprint, arXiv:2403.13257. Jiafeng Guo, Yixing Fan, Liang Pang, Liu Y ang, Qingyao Ai, Hamed Zamani, Chen Wu, W. Bruce Croft, and Xueqi Cheng. 2020. A deep look into neu- ral ranking models for information retrieval . Infor- mation Processing & Management, 57(6):102067. Sebastian Hofstätter, ...
arXiv 2020
-
[2]
Model soups: averaging weights of multi- ple fine-tuned models improves accuracy without in- creasing inference time . In Proceedings of the 39th International Conference on Machine Learning, vol- ume 162 of Proceedings of Machine Learning Re- search, pages 23965–23998. PMLR. Prateek Y adav, Derek Tam, Leshem Choshen, Colin Raffel, and Mohit Bansal. 2023....
Pith/arXiv arXiv 2023
-
[3]
Be a natural and realistic question that a K12 student could plausibly ask. ,→ ,→
-
[4]
Reflect the main information needed from the given document, without copying or restating its text. ,→ ,→
-
[5]
Use informal, everyday French rather than formal or academic language.,→
-
[6]
Output requirements: - Output exactly FIVE queries
Be concise, between 10 and 100 words. Output requirements: - Output exactly FIVE queries. - Wrap the query between the special tokens <|begin_of_query|> and <|end_of_query|>. ,→ ,→ - Do not output anything outside these tokens.,→ Document: {content} A.2 RuBQReranking RuBQReranking is a Russian factoid-style rerank- ing task based on Wikipedia-like documen...
-
[7]
Identify the main named entity the document is about.,→
-
[8]
If there exists ANY plausible alternative surface form for that entity across writing systems or common usage ,→ ,→ ,→ (Latin vs Cyrillic, phonetic transliteration, common colloquial form, mixed form), ,→ ,→ then the query MUST use a surface form DIFFERENT from the one appearing in the document. ,→ ,→
-
[9]
Do NOT use the exact entity surface form from the document when a reasonable alternative exists. ,→ ,→
-
[10]
- One entity, one fact, one question
If no alternative exists, use the canonical Russian form.,→ Query constraints: - Russian only. - One entity, one fact, one question. - Prefer: «Когда...», «Кто...», «В каком году...», «Где...».,→ - 5-20 words. - Do NOT copy or paraphrase any sentence from the document.,→ STRICT OUTPUT RULES (mandatory): - Output EXACTLY ONE LINE. - The line must be exactl...
-
[11]
҂ေФ HTMLՍ čೂ b,→ 4.a Ďđ ඔሳb ,→ ,→ 5.Ս Ďb,→ 6.໙ีč২ೂ ਔહpĎb,→ ൻԛေğ - ൻԛ่Ұ࿘b -ᄝ <|begin_of_query|> ބ|end_of_query|>b,→ -໓Чb Document: {content} A.4 VoyageMMarcoReranking VoyageMMarcoReranking is a Japanese MS MARCO-style reranking task. The prompt asks the generator to produce concise and realistic Japanese search queries, with special attention to concre...
-
[12]
Ask about one specific and concrete piece of information contained in the document. ,→ ,→
-
[13]
Reflect a single, clear information need (e.g., definition, fact, number, attribute, cause, person, etc.). ,→ ,→
-
[14]
Be concise and focused, typically short and direct rather than open-ended.,→
-
[15]
Closely align with the key entity or concept in the document (lexical overlap is acceptable). ,→ ,→
-
[16]
,→ ,→ ,→ ,→ Output requirements: - Output exactly FIVE queries
If the document contains an important number (e.g., phone number, routing number, price, temperature, quantity, date), at least ONE query should directly ask for that number. ,→ ,→ ,→ ,→ Output requirements: - Output exactly FIVE queries. - Each query must be wrapped between the special tokens <|begin_of_query|> and <|end_of_query|>. ,→ ,→ - Do not output...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.