Robot Critics that Sweat the Small Stuff
Pith reviewed 2026-06-26 14:18 UTC · model grok-4.3
The pith
Fine-tuning a vision-language model on pairs of success and failure robot rollouts creates a critic that detects subtle failures and selects better actions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By constructing pairwise progress supervision using success and failure rollouts obtained from a policy, the fine-tuned critic excels at fine-grained progress reasoning and subtle failure detection, outperforming prior progress reasoning baselines. When the critic is used to identify successful candidates among actions sampled from a policy and forecasted by an action-conditioned video model, average policy success rate improves by 11 percent across real-world tasks and 5.9 percent across simulation tasks.
What carries the argument
A vision-language model critic fine-tuned on pairwise progress supervision drawn from success and failure policy rollouts, which learns to compare visual states for progress and failure signals.
If this is right
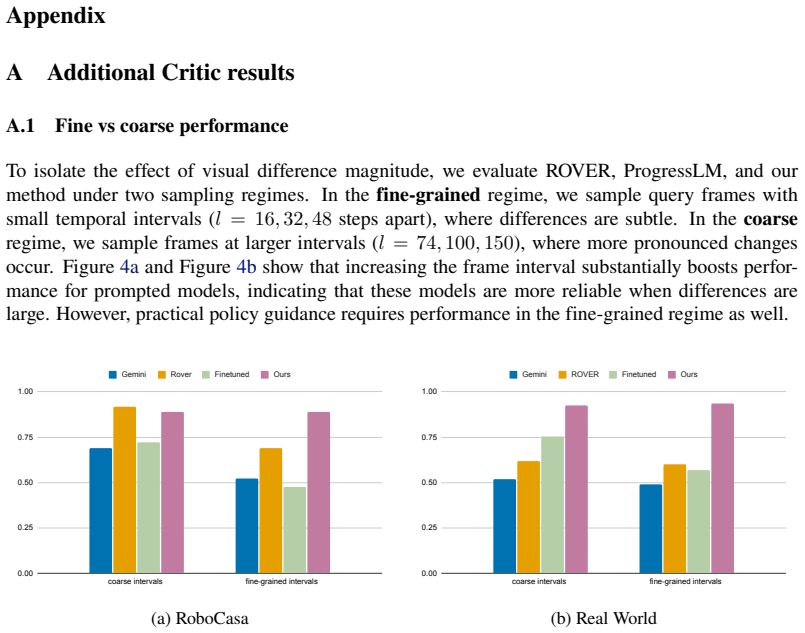
- The critic outperforms prior progress reasoning baselines at fine-grained tasks.
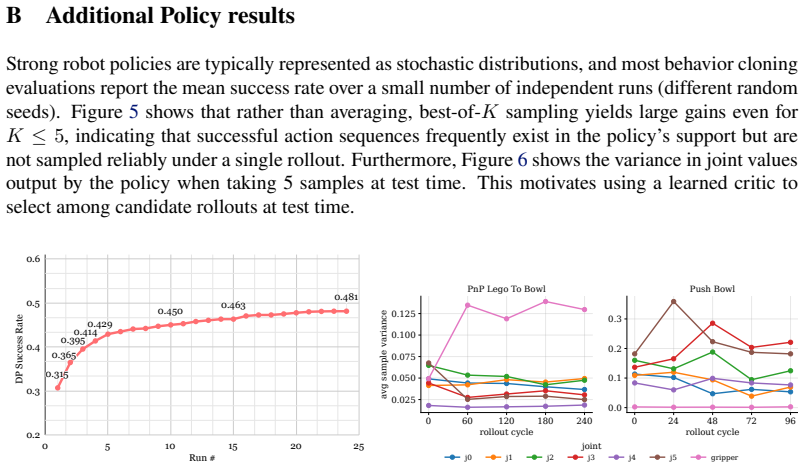
- The critic correctly identifies successful candidate actions among those forecasted by the video model.
- Using the critic to select actions raises average policy success by 11 percent in real-world tasks.
- Using the critic to select actions raises average policy success by 5.9 percent in simulation tasks.
Where Pith is reading between the lines
- The same pairwise training signal could be collected from any policy that already runs in a target domain, lowering the cost of adapting critics to new robots or environments.
- If the critic generalizes across object instances, it may reduce the need for task-specific reward functions in long-horizon manipulation.
- Pairing the critic with more accurate future-prediction models would tighten the loop between action selection and visual verification.
Load-bearing premise
Success and failure rollouts collected from an existing policy already contain enough pairwise visual differences to train a critic that generalizes to new scenes and subtle failures not seen in the training rollouts.
What would settle it
Evaluating the trained critic on a new manipulation task whose failure modes produce visual differences absent from the original training rollouts and checking whether its detection accuracy falls to the level of an untrained baseline.
Figures
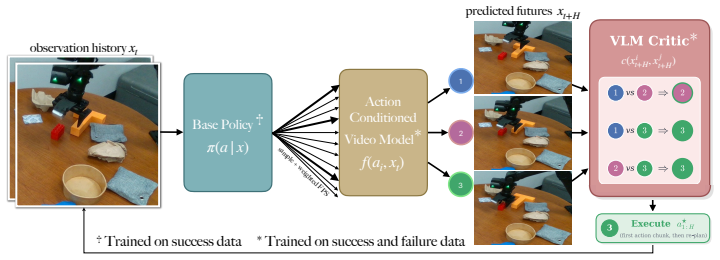
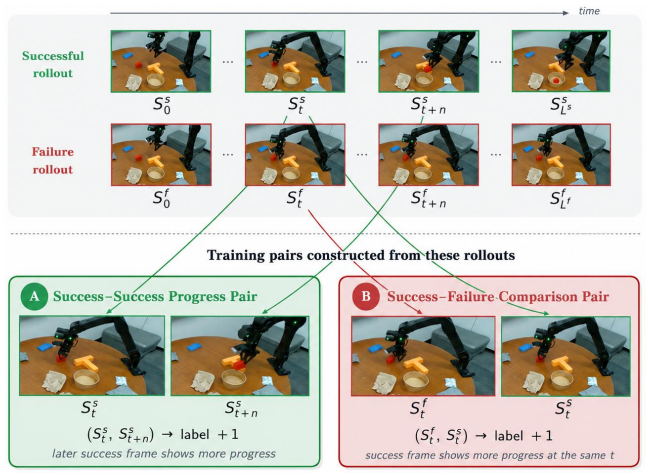

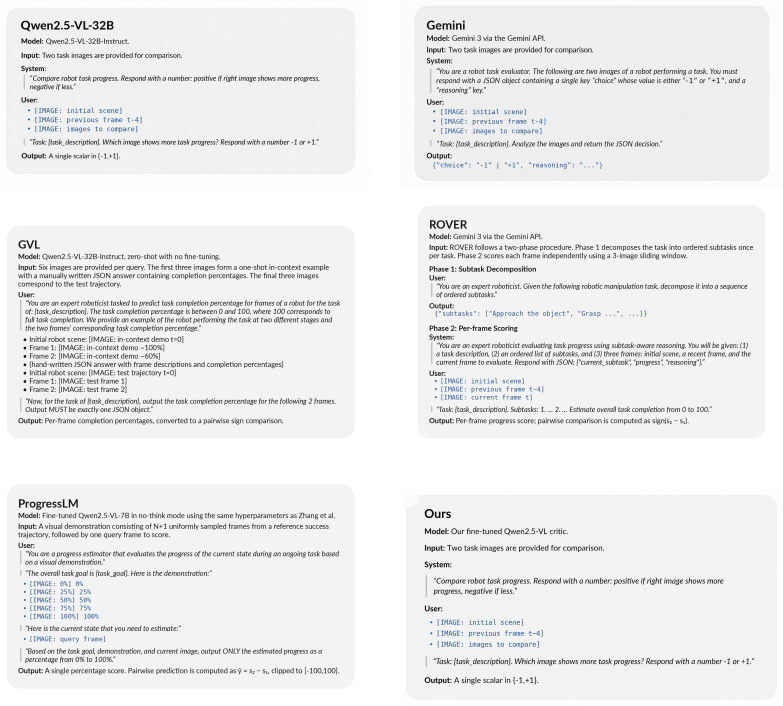
read the original abstract
Large vision-language models contain several priors about the world and object interactions, making them useful critics during inference to steer robot policies towards success. However, closed-loop robot manipulation requires judging small visual differences between success and failure, which remains a challenge for current VLMs. We introduce a method to fine-tune critics by constructing pairwise progress supervision using success and failure rollouts obtained from a policy. Our fine-tuned critic excels at fine-grained progress reasoning and subtle failure detection, outperforming prior progress reasoning baselines. Additionally, we use an action-conditioned video model to predict the visual effect of several candidate actions sampled from a policy, and show that our critic can correctly identify successful candidates to execute, improving the average policy success rate by 11% across real-world tasks and 5.9% across simulation tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes fine-tuning vision-language model critics for closed-loop robot manipulation by constructing pairwise progress supervision from success and failure rollouts collected from an existing policy. The fine-tuned critic is claimed to outperform prior progress reasoning baselines on fine-grained progress reasoning and subtle failure detection. The critic is further combined with an action-conditioned video model to predict effects of candidate actions and select successful ones, yielding reported average policy success rate gains of 11% on real-world tasks and 5.9% on simulation tasks.
Significance. If the empirical claims hold under proper controls, the work could provide a practical route to improving VLM-based critics for detecting subtle visual distinctions in manipulation without requiring new data collection beyond existing policy rollouts. The pairwise supervision approach and its integration with forward video prediction represent a concrete empirical contribution worth testing in the robotics community.
major comments (2)
- [Abstract] Abstract: The abstract states clear numerical gains (11% real-world, 5.9% simulation) but supplies no information on baselines, number of trials, statistical significance, rollout collection/filtering procedure, or evaluation protocol. These omissions are load-bearing for the central claim of outperformance and generalization.
- [Abstract] Abstract: The method's generalization to new scenes and subtle failures not seen in training rests on the unverified assumption that success/failure rollouts already contain sufficient pairwise visual differences; no analysis, diversity metrics, or ablation is supplied to substantiate this assumption, which directly underpins the reported gains outside the training distribution.
minor comments (1)
- [Abstract] The abstract refers to 'prior progress reasoning baselines' without naming or citing them.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the abstract requires expansion to better support the central claims and will revise it accordingly. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract states clear numerical gains (11% real-world, 5.9% simulation) but supplies no information on baselines, number of trials, statistical significance, rollout collection/filtering procedure, or evaluation protocol. These omissions are load-bearing for the central claim of outperformance and generalization.
Authors: We agree that the abstract would benefit from additional context. In the revised manuscript, we will expand the abstract to briefly specify the baselines (prior progress reasoning methods), number of trials, statistical significance testing, rollout collection and filtering procedure, and evaluation protocol, while remaining within standard length limits. revision: yes
-
Referee: [Abstract] Abstract: The method's generalization to new scenes and subtle failures not seen in training rests on the unverified assumption that success/failure rollouts already contain sufficient pairwise visual differences; no analysis, diversity metrics, or ablation is supplied to substantiate this assumption, which directly underpins the reported gains outside the training distribution.
Authors: The full manuscript contains held-out evaluations on new scenes and subtle failures plus ablations on the pairwise supervision. We will revise the abstract to note that rollouts are drawn from diverse policy executions and explicitly reference the experiments section for diversity metrics and ablations. Additional analysis can be added if specific metrics are suggested. revision: partial
Circularity Check
No circularity: empirical training and evaluation procedure is self-contained
full rationale
The paper presents an empirical pipeline: collect success/failure rollouts from an existing policy, construct pairwise progress supervision, fine-tune a VLM critic, and measure outperformance on held-out tasks plus downstream policy improvement via an action-conditioned video model. No equations, fitted parameters, or derivations are described that would reduce the reported 11%/5.9% success-rate gains or fine-grained reasoning claims to the training inputs by construction. The central results are measured outcomes on separate evaluation tasks, not predictions forced by the fitting process itself. No self-citation chains or uniqueness theorems are invoked as load-bearing premises.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Alayrac, J
J.-B. Alayrac, J. Donahue, P . Luc, A. Miech, I. Barr, Y . Hasson, K. Lenc, A. Mensch, K. Mil- lican, M. Reynolds, et al. Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35:23716–23736, 2022
2022
-
[2]
H. Liu, C. Li, Q. Wu, and Y . J. Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
2023
-
[3]
D. Driess, F. Xia, M. S. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu, et al. Palm-e: An embodied multimodal language model.arXiv preprint arXiv:2303.03378, 2023
Pith/arXiv arXiv 2023
-
[4]
Y . Wu, R. Tian, G. Swamy, and A. Bajcsy. From foresight to forethought: Vlm-in-the-loop policy steering via latent alignment.ArXiv, abs/2502.01828, 2025. URLhttps://api. semanticscholar.org/CorpusID:276107486
arXiv 2025
-
[5]
W . Zhao, J. Chen, Z. Meng, D. Mao, R. Song, and W . Zhang. Vlmpc: Vision-language model predictive control for robotic manipulation.ArXiv, abs/2407.09829, 2024. URLhttps:// api.semanticscholar.org/CorpusID:271212525
arXiv 2024
-
[6]
S. Bai, K. qin Chen, X. Liu, J. Wang, W . Ge, S. Song, K. Dang, P . Wang, S. Wang, J. Tang, H. Zhong, Y . Zhu, M. Y ang, Z. Li, J. Wan, P . Wang, W . Ding, Z. Fu, Y . Xu, J. Y e, X. Zhang, T. Xie, Z. Cheng, H. Zhang, Z. Y ang, H. Xu, and J. Lin. Qwen2.5-vl technical report. ArXiv, abs/2502.13923, 2025. URLhttps://api.semanticscholar.org/CorpusID: 276449796
Pith/arXiv arXiv 2025
-
[7]
G. C. et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.ArXiv, abs/2507.06261, 2025. URLhttps: //api.semanticscholar.org/CorpusID:280151524
Pith/arXiv arXiv 2025
-
[8]
P . Schroeder, O. Biza, T. Weng, H. Luo, and J. R. Glass. Rover: Recursive reasoning over videos with vision-language models for embodied tasks.ArXiv, abs/2508.01943, 2025. URL https://api.semanticscholar.org/CorpusID:280422750
arXiv 2025
-
[9]
Y . J. Ma, J. Hejna, A. Wahid, C. Fu, D. Shah, J. Liang, Z. Xu, S. Kirmani, P . Xu, D. Driess, T. Xiao, J. Tompson, O. Bastani, D. Jayaraman, W . Yu, T. Zhang, D. Sadigh, and F. Xia. Vision language models are in-context value learners.ArXiv, abs/2411.04549, 2024. URL https://api.semanticscholar.org/CorpusID:273877849
arXiv 2024
-
[10]
J. Zhang, C. Qian, H. Sun, H. Lu, D. Wang, L. Xue, and H. Liu. Progresslm: Towards progress reasoning in vision-language models.ArXiv, abs/2601.15224, 2026. URLhttps://api. semanticscholar.org/CorpusID:284917784
Pith/arXiv arXiv 2026
-
[11]
C. Chi, Z. Xu, C. Pan, E. Cousineau, B. Burchfiel, S. Feng, R. Tedrake, and S. Song. Universal manipulation interface: In-the-wild robot teaching without in-the-wild robots. ArXiv, abs/2402.10329, 2024. URLhttps://api.semanticscholar.org/CorpusID: 267740127. 10
Pith/arXiv arXiv 2024
-
[12]
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Ellis, P . Fagan, J. Hejna, M. Itkina, M. Lepert, Y . Ma, P . T. Miller, J. Wu, S. Belkhale, S. Dass, H. Ha, A. Jain, A. Lee, Y . Lee, M. Memmel, S. Y . Park, I. Radosavovic, K. Wang, A. Zhan, K. Black, C. Chi, K. B. Hatch, S. Lin, J. ...
Pith/arXiv arXiv 2024
-
[13]
Padalkar, A
A. Padalkar, A. Pooley, A. Jain, A. Bewley, A. Herzog, A. Irpan, A. Khazatsky, A. Rai, A. Singh, A. Brohan, A. Raffin, A. Wahid, B. Burgess-Limerick, B. Kim, B. Sch ¨olkopf, B. Ichter, C. Lu, C. Xu, C. Finn, C. Xu, C. Chi, C. Huang, C. Chan, C. Pan, C. Fu, C. Devin, D. Driess, D. Pathak, D. Shah, D. B ¨uchler, D. Kalashnikov, D. Sadigh, E. Johns, F. Ce- o...
2024
-
[14]
W . Pumacay, I. Singh, J. Duan, R. Krishna, J. Thomason, and D. Fox. The colosseum: A benchmark for evaluating generalization for robotic manipulation.ArXiv, abs/2402.08191,
-
[15]
URLhttps://api.semanticscholar.org/CorpusID:267636930
-
[16]
H. Kress-Gazit, K. Hashimoto, N. Kuppuswamy, P . Shah, P . Horgan, G. Richardson, S. Feng, and B. Burchfiel. Robot learning as an empirical science: Best practices for policy evaluation. ArXiv, abs/2409.09491, 2024. URLhttps://api.semanticscholar.org/CorpusID: 272689744
arXiv 2024
-
[17]
P . Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner, Q. ...
Pith/arXiv arXiv 2025
-
[18]
K. Black, M. Y . Galliker, and S. Levine. Real-time execution of action chunking flow policies. arXiv preprint arXiv:2506.07339, 2025
Pith/arXiv arXiv 2025
-
[19]
W . Wu, F. Lu, Y . Wang, S. Y ang, S. Liu, F. Wang, Q. Zhu, H. Sun, Y . Wang, S. Ma, et al. A pragmatic vla foundation model.arXiv preprint arXiv:2601.18692, 2026
Pith/arXiv arXiv 2026
-
[20]
H. Xie, B. Wen, J. Zheng, Z. Chen, F. Hong, H. Diao, and Z. Liu. Dynamicvla: A vision- language-action model for dynamic object manipulation.arXiv preprint arXiv:2601.22153, 2026
arXiv 2026
-
[21]
L. Beyer, A. Steiner, A. S. Pinto, A. Kolesnikov, X. Wang, D. Salz, M. Neumann, I. Alabdul- mohsin, M. Tschannen, E. Bugliarello, et al. Paligemma: A versatile 3b vlm for transfer.arXiv preprint arXiv:2407.07726, 2024
Pith/arXiv arXiv 2024
-
[22]
Liang, R
J. Liang, R. Liu, E. Ozguroglu, S. Sudhakar, A. Dave, P . Tokmakov, S. Song, and C. Vondrick. Dreamitate: Real-world visuomotor policy learning via video generation, 2024
2024
-
[23]
J. Liang, P . Tokmakov, R. Liu, S. Sudhakar, P . Shah, R. Ambrus, and C. Vondrick. Video generators are robot policies, 2025. URLhttps://arxiv.org/abs/2508.00795
Pith/arXiv arXiv 2025
-
[24]
Y . Wang, L. Wang, Y . Du, B. Sundaralingam, X. Y ang, Y .-W . Chao, C. Pérez-D’ Arpino, D. Fox, and J. A. Shah. Inference-time policy steering through human interactions.2025 IEEE Inter- national Conference on Robotics and Automation (ICRA), pages 15626–15633, 2024. URL https://api.semanticscholar.org/CorpusID:274280942
2025
- [25]
-
[26]
M. Nakamoto, O. Mees, A. Kumar, and S. Levine. Steering your generalists: Improving robotic foundation models via value guidance, 2025. URLhttps://arxiv.org/abs/2410.13816
arXiv 2025
-
[27]
S. Jang, D. Kim, C. Kim, Y . Kim, and J. Shin. Verifier-free test-time sampling for vision language action models.arXiv preprint arXiv:2510.05681, 2025
arXiv 2025
-
[28]
W . Guo, G. Lu, H. Deng, Z. Wu, Y . Tang, and Z. Wang. Vla-reasoner: Empowering vision- language-action models with reasoning via online monte carlo tree search.arXiv preprint arXiv:2509.22643, 2025
arXiv 2025
-
[29]
J. Cao, Y . Huang, H. Guo, R. Zhang, M. Nan, W . Mai, J. Wang, H. Cheng, J. Sun, G. Han, et al. Compose your policies! improving diffusion-based or flow-based robot policies via test-time distribution-level composition.arXiv preprint arXiv:2510.01068, 2025
arXiv 2025
-
[30]
H. Qi, H. Yin, Y . Du, and H. Y ang. Strengthening generative robot policies through predictive world modeling.ArXiv, abs/2502.00622, 2025. URLhttps://api.semanticscholar. org/CorpusID:276095203
arXiv 2025
-
[31]
S. Gao, W . Liang, K. Zheng, A. Malik, S. Y e, S. Yu, W .-C. Tseng, Y . Dong, K. Mo, C.-H. Lin, et al. Dreamdojo: A generalist robot world model from large-scale human videos.arXiv preprint arXiv:2602.06949, 2026
Pith/arXiv arXiv 2026
-
[32]
Liang, W
J. Liang, W . Huang, F. Xia, P . Xu, K. Hausman, B. Ichter, P . R. Florence, and A. Zeng. Code as policies: Language model programs for embodied control.2023 IEEE Interna- tional Conference on Robotics and Automation (ICRA), pages 9493–9500, 2022. URL https://api.semanticscholar.org/CorpusID:252355542
2023
-
[33]
J. Gao, B. Sarkar, F. Xia, T. Xiao, J. Wu, B. Ichter, A. Majumdar, and D. Sadigh. Physi- cally grounded vision-language models for robotic manipulation.2024 IEEE International Conference on Robotics and Automation (ICRA), pages 12462–12469, 2023. URLhttps: //api.semanticscholar.org/CorpusID:261556939. 12
2024
-
[34]
Y . J. Ma, W . Liang, V . Som, V . Kumar, A. Zhang, O. Bastani, and D. Jayaraman. Liv: Language-image representations and rewards for robotic control. InInternational Confer- ence on Machine Learning, 2023. URLhttps://api.semanticscholar.org/CorpusID: 258999195
2023
-
[35]
Y . Du, K. Konyushkova, M. Denil, A. Raju, J. Landon, F. Hill, N. de Freitas, and S. Cabi. Vision-language models as success detectors.ArXiv, abs/2303.07280, 2023. URLhttps: //api.semanticscholar.org/CorpusID:257496810
arXiv 2023
-
[36]
W . Zhou, M. Tao, C. Zhao, H. Guo, H. Dong, M. Tang, and J. Wang. Physvlm: Enabling visual language models to understand robotic physical reachability.2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6940–6949, 2025. URLhttps: //api.semanticscholar.org/CorpusID:276929115
2025
-
[37]
S. Zhai, Q. Zhang, T. Zhang, F. Huang, H. Zhang, M. Zhou, S. Zhang, L. Liu, S. Lin, and J. Pang. A vision-language-action-critic model for robotic real-world reinforcement learn- ing.ArXiv, abs/2509.15937, 2025. URLhttps://api.semanticscholar.org/CorpusID: 281411120
arXiv 2025
-
[38]
M. Ahn, A. Brohan, N. Brown, Y . Chebotar, O. Cortes, B. David, C. Finn, K. Gopalakrishnan, K. Hausman, A. Herzog, D. Ho, J. Hsu, J. Ibarz, B. Ichter, A. Irpan, E. Jang, R. M. J. Ru- ano, K. Jeffrey, S. Jesmonth, N. J. Joshi, R. C. Julian, D. Kalashnikov, Y . Kuang, K.-H. Lee, S. Levine, Y . Lu, L. Luu, C. Parada, P . Pastor, J. Quiambao, K. Rao, J. Retti...
2022
-
[39]
Y . Wang, Z. Sun, J. Zhang, Z. Xian, E. Biyik, D. Held, and Z. Erickson. Rl-vlm-f: Rein- forcement learning from vision language foundation model feedback. InInternational Confer- ence on Machine Learning, 2024. URLhttps://api.semanticscholar.org/CorpusID: 267499679
2024
-
[40]
Finn and S
C. Finn and S. Levine. Deep visual foresight for planning robot motion. In2017 IEEE inter- national conference on robotics and automation (ICRA), pages 2786–2793. IEEE, 2017
2017
-
[41]
Z. Xue, J. An, X. Y ang, and K. Grauman. Progress-aware video frame captioning.2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 13639– 13650, 2024. URLhttps://api.semanticscholar.org/CorpusID:274446032
2025
-
[42]
K.-H. Hung, P .-C. Lo, J.-F. Y eh, H.- Y . Hsu, Y .-T. Chen, and W . H. Hsu. Victor: Learning hierarchical vision-instruction correlation rewards for long-horizon manipulation. ArXiv, abs/2405.16545, 2024. URLhttps://api.semanticscholar.org/CorpusID: 270064037
arXiv 2024
- [43]
-
[44]
Agrawal, J
A. Agrawal, J. Lu, S. Antol, M. Mitchell, C. L. Zitnick, D. Parikh, and D. Batra. Vqa: Visual question answering.International Journal of Computer Vision, 123:4 – 31, 2015. URLhttps: //api.semanticscholar.org/CorpusID:3180429
2015
-
[45]
D. A. Hudson and C. D. Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering.2019 IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), pages 6693–6702, 2019. URLhttps://api.semanticscholar. org/CorpusID:152282269. 13
2019
-
[46]
X. Yue, Y . Ni, K. Zhang, T. Zheng, R. Liu, G. Zhang, S. Stevens, D. Jiang, W . Ren, Y . Sun, C. Wei, B. Yu, R. Yuan, R. Sun, M. Yin, B. Zheng, Z. Y ang, Y . Liu, W . Huang, H. Sun, Y . Su, and W . Chen. Mmmu: A massive multi-discipline multimodal understanding and rea- soning benchmark for expert agi.2024 IEEE/CVF Conference on Computer Vision and Patter...
2024
-
[47]
Liang, Y
A. Liang, Y . Korkmaz, J. Zhang, M. Hwang, A. Anwar, S. Kaushik, A. Shah, A. Huang, L. S. Zettlemoyer, D. Fox, Y . Xiang, A. Li, A. Bobu, A. Gupta, S. Tu, E. Biyik, and J. Zhang. Robometer: Scaling general-purpose robotic reward models via trajectory comparisons. 2026. URLhttps://api.semanticscholar.org/CorpusID:286223261
2026
-
[48]
C. Xu, T. K. Nguyen, E. Dixon, C. Rodriguez, P . Miller, R. Lee, P . Shah, R. Ambrus, H. Nishimura, and M. Itkina. Can we detect failures without failure data? uncertainty-aware runtime failure detection for imitation learning policies, 2025. URLhttps://arxiv.org/ abs/2503.08558
arXiv 2025
-
[49]
J. Duan, W . Pumacay, N. Kumar, Y . R. Wang, S. Tian, W . Yuan, R. Krishna, D. Fox, A. Mandlekar, and Y . Guo. Aha: A vision-language-model for detecting and reasoning over failures in robotic manipulation.ArXiv, abs/2410.00371, 2024. URLhttps://api. semanticscholar.org/CorpusID:273022765
arXiv 2024
-
[50]
Z. Lin, J. Duan, H. Fang, D. Fox, R. Krishna, C. Tan, and B. Wen. Failsafe: Reasoning and recovery from failures in vision-language-action models, 2025. URLhttps://arxiv.org/ abs/2510.01642
arXiv 2025
-
[51]
J. Park, J. Y oon, B. Jeon, J. Park, J. Shin, N. Cho, K. Lee, S. Yun, and S. Choi. Hierarchical vision language action model using success and failure demonstrations, 2025. URLhttps: //arxiv.org/abs/2512.03913
arXiv 2025
-
[52]
H. Li, K. Lei, S. Zang, K. Hu, Y . Liang, B. An, X. Li, and H. Xu. Failure-aware rl: Reliable offline-to-online reinforcement learning with self-recovery for real-world manipulation, 2026. URLhttps://arxiv.org/abs/2601.07821
arXiv 2026
-
[53]
P . Christiano, J. Leike, T. B. Brown, M. Martic, S. Legg, and D. Amodei. Deep reinforcement learning from human preferences, 2023. URLhttps://arxiv.org/abs/1706.03741
Pith/arXiv arXiv 2023
-
[54]
R. A. Bradley and M. E. Terry. Rank analysis of incomplete block designs: I. the method of paired comparisons.Biometrika, 39(3/4):324–345, 1952
1952
-
[55]
C. Finn, I. J. Goodfellow, and S. Levine. Unsupervised learning for physical interaction through video prediction.ArXiv, abs/1605.07157, 2016. URLhttps://api.semanticscholar. org/CorpusID:2659157
Pith/arXiv arXiv 2016
-
[56]
Y ang, Y
S. Y ang, Y . Du, K. Ghasemipour, J. Tompson, L. Kaelbling, D. Schuurmans, and P . Abbeel. Learning interactive real-world simulators, 2024. URLhttps://arxiv.org/abs/2310. 06114
2024
-
[57]
B. Wu, C. Zou, C. Li, D. Huang, F. Y ang, H. Tan, J. Peng, J. Wu, J. Xiong, J. Jiang, Linus, Patrol, P . Zhang, P . Chen, P . Zhao, Q. Tian, S. Liu, W . Kong, W . Wang, X. He, X. Li, X. Deng, X. Zhe, Y . Li, Y . Long, Y . Peng, Y . Wu, Y . Liu, Z. Wang, Z. Dai, B. Peng, C. Li, G. Gong, G. Xiao, J. Tian, J. Lin, J. Liu, J. Zhang, J. Lian, K. Pan, L. Wang, ...
-
[58]
URLhttps://arxiv.org/abs/2511.18870. 14
- [59]
-
[60]
S. Nasiriany, A. Maddukuri, L. Zhang, A. Parikh, A. Lo, A. Joshi, A. Mandlekar, and Y . Zhu. Robocasa: Large-scale simulation of everyday tasks for generalist robots. ArXiv, abs/2406.02523, 2024. URLhttps://api.semanticscholar.org/CorpusID: 270226600
Pith/arXiv arXiv 2024
-
[61]
T. L. Team, J. Barreiros, A. Beaulieu, A. Bhat, R. Cory, E. Cousineau, H. Dai, C. Fang, K. Hashimoto, M. Z. Irshad, M. Itkina, N. Kuppuswamy, K.-H. Lee, K. Liu, D. Mcconachie, I. McMahon, H. Nishimura, C. Phillips-Grafflin, C. Richter, P . Shah, K. P . Srinivasan, B. Wulfe, C. Xu, M. Zhang, A. Alspach, M. Angeles, K. Arora, V . Guizilini, A. M. Cas- tro, ...
Pith/arXiv arXiv 2025
-
[62]
C. Chi, S. Feng, Y . Du, Z. Xu, E. Cousineau, B. Burchfiel, and S. Song. Diffusion pol- icy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44:1684 – 1704, 2023. URLhttps://api.semanticscholar.org/CorpusID: 257378658
2023
-
[63]
S. Nasiriany, S. Nasiriany, A. Maddukuri, and Y . Zhu. Robocasa365: A large-scale simulation framework for training and benchmarking generalist robots, 2026. URLhttps://arxiv. org/abs/2603.04356
arXiv 2026
-
[64]
Bjorck, N
NVIDIA, J. Bjorck, N. C. Fernando Casta ˜neda, X. Da, R. Ding, L. J. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, J. Jang, Z. Jiang, J. Kautz, K. Kundalia, L. Lao, Z. Li, Z. Lin, K. Lin, G. Liu, E. Llontop, L. Magne, A. Mandlekar, A. Narayan, S. Nasiriany, S. Reed, Y . L. Tan, G. Wang, Z. Wang, J. Wang, Q. Wang, J. Xiang, Y . Xie, Y . Xu, Z. Xu, S. Y e, Z. Yu,...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.