Cross-Domain Query Translation for Network Troubleshooting: A Multi-Agent LLM Framework with Privacy Preservation and Self-Reflection
Pith reviewed 2026-05-21 01:01 UTC · model grok-4.3
The pith
A hierarchical multi-agent LLM framework classifies network queries, anonymizes personal data while retaining diagnostic utility, and translates expert responses into plain language.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
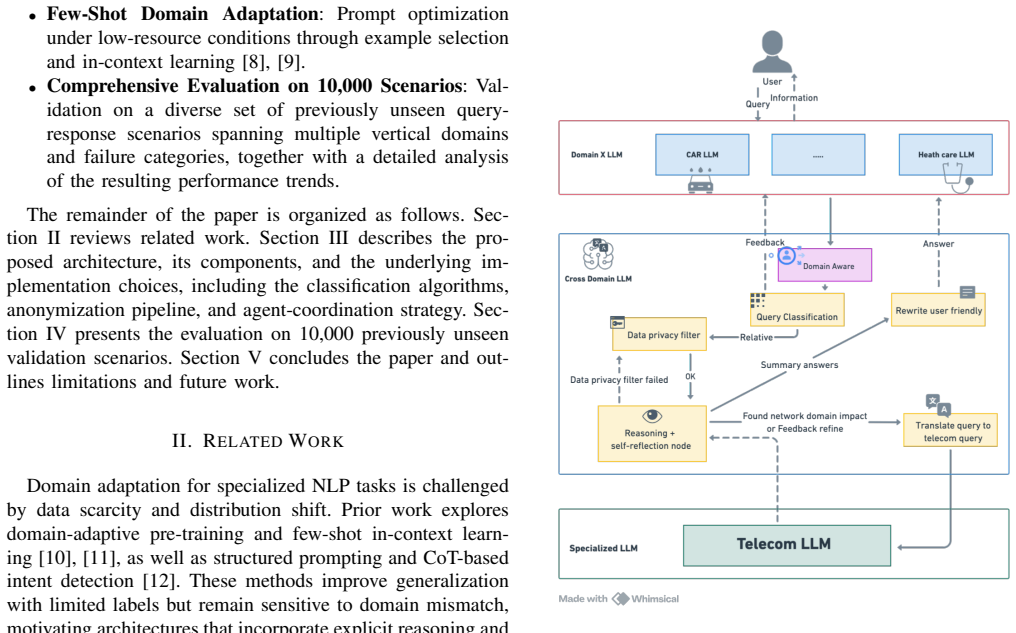
The authors establish that a dual-stage hierarchical multi-agent architecture employing ReAct-style agents with self-reflection, semantic-preserving anonymization respecting k-anonymity and differential privacy, and few-shot strategies enables accurate query classification, privacy-protected diagnostic utility retention, and cross-domain translation of responses, validated over 10,000 unseen scenarios.
What carries the argument
The hierarchical multi-agent LLM architecture coordinated through reflection-based reasoning, incorporating ReAct-style agents for iterative refinement and semantic-preserving anonymization techniques.
If this is right
- User queries about network issues can be classified correctly even with limited training data through few-shot learning strategies.
- Personally identifiable information can be removed while the remaining details still support accurate network troubleshooting.
- Technical responses from domain experts can be converted into language that non-technical users understand.
- The overall framework generalizes across different industries without needing per-domain model adjustments.
Where Pith is reading between the lines
- The same agent structure might apply to other fields where users describe technical problems to specialists, such as IT support or equipment repair.
- Connecting the system directly to live network sensors could let it generate initial anonymized diagnostics before an expert review.
- Extending the self-reflection loop to multi-turn dialogues might improve handling of follow-up questions from users.
Load-bearing premise
The load-bearing premise is that combining ReAct-style agents, self-reflection, and standard k-anonymity with differential privacy techniques maintains classification accuracy and diagnostic utility without requiring domain-specific fine-tuning or large labeled datasets.
What would settle it
A test set of queries where anonymization removes information essential to correct diagnosis, after which the system produces troubleshooting steps that fail to resolve the original issue at rates higher than the non-anonymized baseline.
Figures


read the original abstract
This paper presents a hierarchical multi-agent LLM architecture to bridge communication gaps between non-technical end users and telecommunications domain experts in private network environments. We propose a cross-domain query translation framework that leverages specialized language models coordinated through multi-agent reflection-based reasoning. The resulting system addresses three critical challenges: (1) accurately classify user queries related to telecommunications network issues using a dual-stage hierarchical approach, (2) preserve user privacy through the anonymization of semantically relevant personally identifiable information (PII) while maintaining diagnostic utility, and (3) translate technical expert responses into user-comprehensible language. Our approach employs ReAct-style agents enhanced with self-reflection mechanisms for iterative output refinement, semantic-preserving anonymization techniques respecting $k$-anonymity and differential privacy principles, and few-shot learning strategies designed for limited training data scenarios. The framework was comprehensively evaluated on 10,000 previously unseen validation scenarios across various vertical industries.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a hierarchical multi-agent LLM framework for cross-domain query translation in telecommunications network troubleshooting. It uses ReAct-style agents with self-reflection to classify user queries, applies semantic-preserving anonymization via k-anonymity and differential privacy to protect PII while retaining diagnostic utility, and translates expert responses into user-comprehensible language. The system is described as evaluated on 10,000 previously unseen validation scenarios across vertical industries, with few-shot learning for limited-data settings.
Significance. If the performance and utility-preservation claims were substantiated with quantitative evidence, the work could address a practical gap in private-network diagnostics by enabling non-experts to interact with technical systems without exposing sensitive data. The combination of multi-agent coordination and privacy techniques aligns with emerging needs in AI-assisted network management, but the absence of results, ablations, or baselines currently limits its contribution to the field.
major comments (3)
- [Abstract] Abstract: The central claim that the framework 'accurately classifies user queries... preserves diagnostic utility... and translates technical responses' across 10,000 unseen scenarios is unsupported, as the manuscript provides no quantitative metrics (accuracy, F1, expert success rate), error rates, ablation studies, or baseline comparisons.
- [Abstract] The semantic-preserving anonymization step (k-anonymity + differential privacy) is asserted to maintain diagnostic utility for telecom-specific signals such as IP addresses, device IDs, and log timestamps, yet no concrete procedure, utility metric (e.g., downstream classification accuracy delta), or ablation with vs. without the privacy layer is described; this is load-bearing for the privacy-utility claim.
- [Abstract] No details are given on how the hierarchical coordination layer or self-reflection mechanisms are implemented beyond standard LLM prompting, nor on any domain-specific adaptation or labeled data used, leaving the weakest assumption (that off-the-shelf ReAct + DP suffices without fine-tuning) untested.
minor comments (1)
- [Abstract] The abstract mentions 'various vertical industries' but provides no breakdown or examples of the scenario distribution.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and describe the revisions we will undertake to strengthen the presentation of results and implementation details.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the framework 'accurately classifies user queries... preserves diagnostic utility... and translates technical responses' across 10,000 unseen scenarios is unsupported, as the manuscript provides no quantitative metrics (accuracy, F1, expert success rate), error rates, ablation studies, or baseline comparisons.
Authors: We agree that the abstract would benefit from explicit quantitative support. We will revise the abstract to report key metrics from our evaluation on the 10,000 scenarios, including query classification accuracy, F1-score, response translation success rate, and reference to ablation and baseline results presented in the evaluation section. revision: yes
-
Referee: [Abstract] The semantic-preserving anonymization step (k-anonymity + differential privacy) is asserted to maintain diagnostic utility for telecom-specific signals such as IP addresses, device IDs, and log timestamps, yet no concrete procedure, utility metric (e.g., downstream classification accuracy delta), or ablation with vs. without the privacy layer is described; this is load-bearing for the privacy-utility claim.
Authors: We acknowledge the need for greater specificity on this load-bearing component. We will add a detailed description of the k-anonymity and differential privacy procedure, including parameter choices and how they are applied to telecom signals, along with utility metrics and an explicit ablation comparing downstream classification performance with and without the privacy mechanisms. revision: yes
-
Referee: [Abstract] No details are given on how the hierarchical coordination layer or self-reflection mechanisms are implemented beyond standard LLM prompting, nor on any domain-specific adaptation or labeled data used, leaving the weakest assumption (that off-the-shelf ReAct + DP suffices without fine-tuning) untested.
Authors: We will expand the methodology section with concrete implementation details, including prompt templates for the ReAct-style agents, the self-reflection loop, and the hierarchical coordination protocol. We will also clarify the few-shot examples drawn from telecommunications data and any domain-specific adaptations employed. revision: yes
Circularity Check
No significant circularity; framework uses standard techniques without self-referential reductions
full rationale
The paper describes a hierarchical multi-agent LLM system for cross-domain query translation, classification, and privacy-preserving anonymization in telecom troubleshooting. It relies on ReAct-style agents with self-reflection, few-shot learning, and established k-anonymity plus differential privacy principles, evaluated on 10,000 unseen scenarios. No mathematical derivations, equations, fitted parameters, or predictions that reduce to inputs by construction appear in the text. Claims build on cited standard methods rather than self-definitional loops or load-bearing self-citations that collapse the central results. The derivation chain is self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Large language models can perform accurate query classification and response translation when guided by ReAct-style reasoning and self-reflection.
- domain assumption Semantic-preserving anonymization can simultaneously satisfy k-anonymity, differential privacy, and retain diagnostic utility for network troubleshooting.
invented entities (1)
-
Hierarchical multi-agent LLM coordination layer
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
hierarchical multi-agent LLM architecture... ReAct-style agents enhanced with self-reflection... semantic-preserving anonymization techniques respecting k-anonymity and differential privacy
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery theorem unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
two-stage hierarchical classification... SetFit classifier... Chain-of-Thought reasoning
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Business models for local 5G micro operators,
P. Ahokangas, M. Matinmikko-Blue, S. Yrjola, V . Seppanen, H. Ham- mainen, R. Jurva, and M. Latva-aho, “Business models for local 5G micro operators,”IEEE Transactions on Cognitive Communications and Networking, vol. 5, no. 3, pp. 730–740, 2019
work page 2019
-
[2]
Efficient few-shot learning without prompts,
L. Tunstall, N. Reimers, U. E. S. Jo, L. Bates, D. Korat, M. Wasserblat, and O. Pereg, “Efficient few-shot learning without prompts,” inCon- ference on Neural Information Processing Systems (NeurIPS), New Orleans, USA, 2022, poster
work page 2022
-
[3]
Language models are few-shot learners,
T. Brown, B. Mann, N. Ryder, M. Subbiahet al., “Language models are few-shot learners,”Advances in Neural Information Processing Systems, vol. 33, pp. 1877–1901, 2020
work page 1901
-
[4]
k-anonymity: A model for protecting privacy,
L. Sweeney, “k-anonymity: A model for protecting privacy,”Interna- tional Journal of Uncertainty, Fuzziness and Knowledge-Based Systems, vol. 10, no. 05, pp. 557–570, 2002
work page 2002
-
[5]
ReAct: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao, “ReAct: Synergizing reasoning and acting in language models,” in International Conference on Learning Representations (ICLR), 2023, pp. 1 – 13
work page 2023
-
[6]
Reflexion: Language agents with verbal reinforcement learning,
N. Shinn, F. Cassano, A. Gopinath, K. Narasimhan, and S. Yao, “Reflexion: Language agents with verbal reinforcement learning,” in Advances in Neural Information Processing Systems (NIPS), 2023, pp. 8634 – 8652
work page 2023
-
[7]
Self-refine: Iterative refinement with self-feedback,
A. Madaanet al., “Self-refine: Iterative refinement with self-feedback,” inAdvances in Neural Information Processing Systems (NIPS), vol. 36, 2023
work page 2023
-
[8]
Chain-of-Thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. Chi, Q. Le, and D. Zhou, “Chain-of-Thought prompting elicits reasoning in large language models,” inAdvances in Neural Information Processing Systems (NIPS), vol. 35, 2022, pp. 24 824 – 24 837
work page 2022
-
[9]
Sentence-BERT: Sentence embeddings using siamese BERT-networks,
N. Reimers and I. Gurevych, “Sentence-BERT: Sentence embeddings using siamese BERT-networks,” inConference on Empirical Methods in Natural Language Processing and International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 2019, pp. 3982–3992
work page 2019
-
[10]
Neural unsupervised domain adaptation in nlp—a survey,
A. Ramponi and B. Plank, “Neural unsupervised domain adaptation in nlp—a survey,” inInternational Conference on Computational Linguis- tics (COLING), 2020, pp. 6838–6855
work page 2020
-
[11]
BERT: Pre-training of deep bidirectional transformers for language understanding,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of deep bidirectional transformers for language understanding,” inNorth American Chapter of the Association for Computational Linguistics: Human Language Technologies, vol. 1, Minneapolis, Minnesota, 2019, pp. 4171–4186
work page 2019
-
[12]
Llm-guided semantic relational reasoning for multimodal intent recognition,
Q. Zhou, H. Xu, Y . Wang, X. Dong, and H. Zhang, “Llm-guided semantic relational reasoning for multimodal intent recognition,”The 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP 2025), 2025
work page 2025
-
[13]
The emerged security and privacy of llm agent: A survey with case studies,
F. He, T. Zhu, D. Ye, B. Liu, W. Zhou, and P. Yu, “The emerged security and privacy of llm agent: A survey with case studies,”ACM Computing Surveys, 2024
work page 2024
-
[14]
Federated learning and privacy,
K. Bonawitz, P. Kairouz, B. McMahan, and D. Ramage, “Federated learning and privacy,”Communications of the ACM, vol. 65, no. 4, pp. 90–97, 2022
work page 2022
-
[15]
Privacy-preserving natural language processing,
I. Habernal, J. L. Leidner, and I. Rehbein, “Privacy-preserving natural language processing,” inProceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics: Tutorial Abstracts. Association for Computational Linguistics, 2023, pp. 23–29
work page 2023
-
[16]
Privacy-preservation in the context of natural language processing: An overview,
D. Mahendran, S. Mcdonagh, and D. Doyle, “Privacy-preservation in the context of natural language processing: An overview,”IEEE Access, vol. 9, pp. 147 198–147 213, 2021
work page 2021
-
[17]
Telecomgpt: A framework to build telecom-specific large language models,
H. Zou, Q. Zhao, Y . Tian, L. Bariah, F. Bader, T. Lestable, and M. Deb- bah, “Telecomgpt: A framework to build telecom-specific large language models,”IEEE Transactions on Machine Learning in Communications and Networking, 2025
work page 2025
-
[18]
Telco-RAG: Navigating the challenges of retrieval augmented language models for telecommunications,
A.-L. Bornea, F. Ayed, A. De Domenico, N. Piovesan, and A. Maatouk, “Telco-RAG: Navigating the challenges of retrieval augmented language models for telecommunications,” inIEEE Global Telecommunications Conference - GLOBECOM, 2024, pp. 2359–2364
work page 2024
-
[19]
A survey on llm- based multi-agent systems: workflow, infrastructure, and challenges,
X. Li, S. Wang, S. Zeng, Y . Wu, and Y . Yang, “A survey on llm- based multi-agent systems: workflow, infrastructure, and challenges,” Vicinagearth, vol. 1, no. 1, p. 9, 2024
work page 2024
-
[20]
Deep learning–based text classification: A comprehensive review,
S. Minaee, N. Kalchbrenner, E. Cambria, N. Nikzad, M. Chenaghlu, and J. Gao, “Deep learning–based text classification: A comprehensive review,”ACM Computing Surveys, vol. 54, no. 3, pp. 1–40, 2021
work page 2021
-
[21]
arXiv preprint arXiv:2209.11055 , year=
L. Tunstall, N. Reimers, U. E. S. Jo, L. Bates, D. Korat, M. Wasserblat, and O. Pereg, “Efficient few-shot learning without prompts,”arXiv preprint arXiv:2209.11055, 2022
-
[22]
FastFit: Fast and effective few-shot text classification with a multitude of classes,
A. Yehudai and E. Bandel, “FastFit: Fast and effective few-shot text classification with a multitude of classes,” inConference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 3: System Demonstrations), Mexico City, Mexico, 2024, pp. 174–184
work page 2024
-
[23]
Understanding readability of large language models output: an empirical analysis,
F. Marulli, L. Campanile, M. S. de Biase, S. Marrone, L. Verde, and M. Bifulco, “Understanding readability of large language models output: an empirical analysis,”Procedia Computer Science, vol. 246, pp. 5273– 5282, 2024
work page 2024
-
[24]
TeleQnA: A benchmark dataset to assess large language models telecommunications knowledge,
A. Maatouk, F. Ayed, N. Piovesan, A. De Domenico, M. Debbah, and Z.-Q. Luo, “TeleQnA: A benchmark dataset to assess large language models telecommunications knowledge,”IEEE Network, pp. 1 – 7, 2025
work page 2025
-
[25]
H. Wei, S. He, T. Xia, F. Liu, A. Wong, J. Lin, and M. Han, “Systematic evaluation of LLM-as-a-judge in LLM alignment tasks: Explainable metrics and diverse prompt templates,” inInternational Conference on Learning Representations (ICLR), 2025, pp. 1 – 13
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.