Social Media-based User Embedding: A Literature Review
Pith reviewed 2026-05-25 15:25 UTC · model grok-4.3
The pith
Social media user embeddings learned from text and images support scalable models of human traits and behaviors when ground truth labels are scarce.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
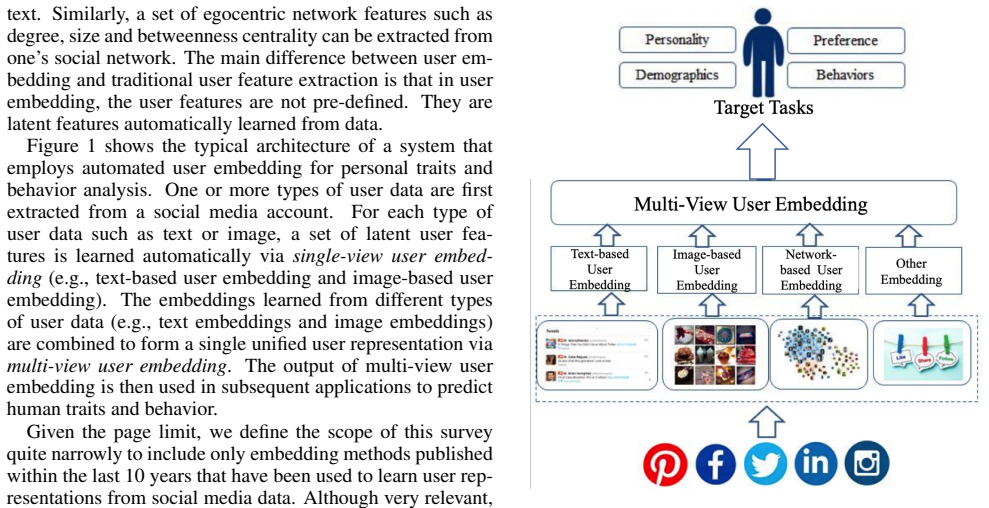
Automated representation learning can produce low-dimensional user embeddings from heterogeneous social media data such as texts and images. These embeddings enable high-performance models of latent human traits and behaviors because abundant unlabeled data can substitute for costly ground-truth labels at large scale. The review covers standard methods that integrate multiple data modalities into one representation and identifies current issues along with future directions.
What carries the argument
Learning unified user embeddings from heterogeneous social media data sources such as text and images.
If this is right
- Trait and behavior models can be built at larger scale by leveraging embeddings trained on abundant unlabeled social media data.
- Combining multiple modalities such as text and images into one embedding improves downstream prediction performance.
- Current embedding methods still face challenges around data heterogeneity, scalability, and evaluation that limit their reliability.
Where Pith is reading between the lines
- The same embedding approach could transfer to other domains where labeled examples of user attributes are expensive but public interaction data are plentiful.
- Wider adoption might raise new questions about how to protect sensitive attributes that become encoded in the embeddings.
- Extending the surveyed methods with explicit network structure from follower graphs could produce richer representations.
Load-bearing premise
The methods and issues covered in the review are representative of the main approaches in the literature without significant selection bias.
What would settle it
A systematic search that uncovers major user-embedding techniques or data-fusion strategies not discussed in the survey.
Figures
read the original abstract
Automated representation learning is behind many recent success stories in machine learning. It is often used to transfer knowledge learned from a large dataset (e.g., raw text) to tasks for which only a small number of training examples are available. In this paper, we review recent advance in learning to represent social media users in low-dimensional embeddings. The technology is critical for creating high performance social media-based human traits and behavior models since the ground truth for assessing latent human traits and behavior is often expensive to acquire at a large scale. In this survey, we review typical methods for learning a unified user embeddings from heterogeneous user data (e.g., combines social media texts with images to learn a unified user representation). Finally we point out some current issues and future directions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper is a literature review surveying recent methods for learning unified low-dimensional embeddings of social media users from heterogeneous data (e.g., text combined with images). It positions such embeddings as critical for downstream models of human traits and behavior, reviews 'typical methods,' and concludes by identifying current issues and future directions.
Significance. A representative survey of user-embedding techniques for social media would be useful for researchers working on transfer learning and behavioral modeling where labeled data is scarce. The central claim that the reviewed set captures the main approaches, however, cannot be evaluated without evidence of systematic selection.
major comments (1)
- [Abstract / Introduction] The manuscript states that it reviews 'typical methods' for unified user embeddings (abstract and introduction) but contains no methods section, no search strategy, no list of databases or keywords, no date range, and no inclusion/exclusion criteria. This directly undermines the representativeness claim required for the survey's central contribution.
minor comments (1)
- [Abstract] Abstract contains grammatical issues ('recent advance' should be 'advances'; 'unified user embeddings' is used inconsistently with singular/plural forms elsewhere).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The observation regarding the lack of explicit methodology is valid and we will address it by adding a dedicated section on the review process in the revised manuscript. This will clarify the scope without altering the narrative nature of the survey.
read point-by-point responses
-
Referee: [Abstract / Introduction] The manuscript states that it reviews 'typical methods' for unified user embeddings (abstract and introduction) but contains no methods section, no search strategy, no list of databases or keywords, no date range, and no inclusion/exclusion criteria. This directly undermines the representativeness claim required for the survey's central contribution.
Authors: We agree that transparency in selection is important. Although the review focuses on typical methods drawn from prominent recent works rather than asserting exhaustive coverage, we will revise by inserting a new 'Review Methodology' subsection. It will specify the primary sources (Google Scholar, arXiv, ACL Anthology), search terms (combinations of 'user embedding', 'social media', 'multimodal representation', 'heterogeneous data'), approximate time frame (2014-2019), and inclusion criteria (methods producing unified low-dimensional user vectors from multiple modalities). This addition will enable readers to evaluate scope while preserving the paper's emphasis on representative techniques and open issues. revision: yes
Circularity Check
Survey paper with no derivations or load-bearing claims exhibits no circularity
full rationale
This is a literature review summarizing existing methods for user embeddings from social media data. It presents no original mathematical derivations, predictions, first-principles results, or equations that could reduce to inputs by construction. No self-citations function as load-bearing justifications for any claimed uniqueness or ansatz, and the review structure contains no fitted parameters renamed as predictions. The absence of a methods section for paper selection is a methodological limitation but does not create circularity under the defined patterns.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
In this survey, we review typical methods for learning a unified user embeddings from heterogeneous user data (e.g., combines social media texts with images to learn a unified user representation).
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Table 1: Summary of User Embedding Methods (LDA, SVD, Word2Vec, DeepWalk, CCA, …)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
[Abel et al., 2013] F. Abel, E. Herder, G. Houben, N. Henze, and D. Krause. Cross-system user modeling and personalization on the social web. UMUAI,
work page 2013
-
[2]
Quantifying mental health from social media with neural user embeddings
[Amir et al., 2017] Silvio Amir, Glen Coppersmith, Paula Car- valho, Mario J Silva, and Bryon C Wallace. Quantifying mental health from social media with neural user embeddings. In Ma- chine Learning for Healthcare Conference,
work page 2017
- [3]
- [4]
-
[5]
Representation learning: A review and new perspec- tives
[Bengio et al., 2013] Yoshua Bengio, Aaron Courville, and Pascal Vincent. Representation learning: A review and new perspec- tives. IEEE Trans. Pattern Anal. Mach. Intell., 35(8),
work page 2013
- [6]
-
[7]
Predicting depression via social media
[De Choudhury et al., 2013] Munmun De Choudhury, Michael Ga- mon, Scott Counts, and Eric Horvitz. Predicting depression via social media. In ICWSM,
work page 2013
-
[8]
[Ding et al., 2017] T. Ding, W. Bickel, and S. Pan. Multi-view un- supervised user feature embedding for social media-based sub- stance use prediction. In EMNLP,
work page 2017
-
[9]
Twitter user ge- olocation using deep multiview learning
[Do et al., 2018] Tien Huu Do, Duc Minh Nguyen, Evaggelia Tsili- gianni, Bruno Cornelis, and Nikos Deligiannis. Twitter user ge- olocation using deep multiview learning. In ICASSP,
work page 2018
-
[10]
User profiling through deep multimodal fusion
[Farnadi et al., 2018] Golnoosh Farnadi, Jie Tang, Martine De Cock, and Marie-Francine Moens. User profiling through deep multimodal fusion. In WSDM,
work page 2018
-
[11]
[Gao et al., 2014] H. Gao, J. Mahmud, J. Chen, J. Nichols, and Michelle X. Zhou. Modeling user attitude toward controversial topics in online social media. In ICWSM,
work page 2014
-
[12]
Predicting personality with social media
[Golbeck et al., 2011] Jennifer Golbeck, Cristina Robles, and Karen Turner. Predicting personality with social media. In CHI,
work page 2011
-
[13]
node2vec: Scalable feature learning for networks
[Grover and Leskovec, 2016] Aditya Grover and Jure Leskovec. node2vec: Scalable feature learning for networks. InKDD,
work page 2016
-
[14]
[Hardoon et al., 2004] D. Hardoon, S. Szedmak, and J. Shawe- Taylor. Canonical correlation analysis: An overview with appli- cation to learning methods. Neural computation, 16(12),
work page 2004
-
[15]
[Hinton and Salakhutdinov, 2006] G. Hinton and R. Salakhutdinov. Reducing the dimensionality of data with neural networks. sci- ence, 313(5786),
work page 2006
-
[16]
[Hu et al., 2016] T. Hu, H. Xiao, J. Luo, and T. Nguyen. What the language you tweet says about your occupation. In ICWSM,
work page 2016
-
[17]
[Kilic ¸ and Pan, 2016] D. Kilic ¸ and S. Pan. Analyzing and prevent- ing bias in text-based personal trait prediction algorithms. In IC- TAI,
work page 2016
-
[18]
[Kosinski et al., 2013] M. Kosinski, D. Stillwell, and T. Graepel. Private traits and attributes are predictable from digital records of human behavior. PNAS, 110(15),
work page 2013
-
[19]
Distributed representations of sentences and documents
[Le and Mikolov, 2014] Quoc Le and Tomas Mikolov. Distributed representations of sentences and documents. In ICML,
work page 2014
-
[20]
Attributed social network embedding
[Liao et al., 2018] Lizi Liao, Xiangnan He, Hanwang Zhang, and Tat-Seng Chua. Attributed social network embedding. TKDE,
work page 2018
-
[21]
[Liu et al., 2016] L. Liu, D. Preotiuc-Pietro, Z. Samani, M. Moghaddam, and L. Ungar. Analyzing personality through social media profile picture choice. In ICWSM,
work page 2016
-
[22]
Distributed representations of words and phrases and their compositionality
[Mikolov et al., 2013] Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado, and Jeffrey Dean. Distributed representations of words and phrases and their compositionality. In NIPS,
work page 2013
-
[23]
[Miura et al., 2017] Yasuhide Miura, Motoki Taniguchi, Tomoki Taniguchi, and Tomoko Ohkuma. Unifying text, metadata, and user network representations with a neural network for geoloca- tion prediction. In ACL,
work page 2017
-
[24]
[Pennacchiotti and Popescu, 2011] M. Pennacchiotti and A. Popescu. A machine learning approach to twitter user classification. ICWSM,
work page 2011
-
[25]
The development and psy- chometric properties of liwc2015
[Pennebaker et al., 2015] James W Pennebaker, Ryan L Boyd, Kayla Jordan, and Kate Blackburn. The development and psy- chometric properties of liwc2015. Technical report,
work page 2015
-
[26]
Deepwalk: Online learning of social representations
[Perozzi et al., 2014] Bryan Perozzi, Rami Al-Rfou, and Steven Skiena. Deepwalk: Online learning of social representations. In KDD,
work page 2014
-
[27]
[Preot ¸iuc-Pietroet al., 2015] D. Preot ¸iuc-Pietro, V . Lampos, and N. Aletras. An analysis of the user occupational class through twitter content. In ACL,
work page 2015
-
[28]
[Preot ¸iuc-Pietroet al., 2017] D. Preot ¸iuc-Pietro, Y . Liu, D. Hop- kins, and L. Ungar. Beyond binary labels: political ideology prediction of twitter users. In ACL,
work page 2017
-
[29]
Char- acterizing and detecting hateful users on twitter
[Ribeiro et al., 2018] Manoel Horta Ribeiro, Pedro H Calais, Yuri A Santos, Virg´ılio AF Almeida, and Wagner Meira Jr. Char- acterizing and detecting hateful users on twitter. In AAAI,
work page 2018
-
[30]
[Schwartz et al., 2013] A. Schwartz, J. Eichstaedt, M. Kern, L. Dz- iurzynski, S. Ramones, M. Agrawal, A. Shah, M. Kosinski, D. Stillwell, M. Seligman, et al. Personality, gender, and age in the language of social media: The open-vocabulary approach. PloS one, 8(9),
work page 2013
- [31]
-
[32]
Very Deep Convolutional Networks for Large-Scale Image Recognition
[Simonyan and Zisserman, 2014] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale im- age recognition. arXiv:1409.1556,
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[33]
[Song et al., 2015] X. Song, L. Nie, L. Zhang, M. Liu, and T. Chua. Interest inference via structure-constrained multi-source multi- task learning. In IJCAI,
work page 2015
-
[34]
[Song et al., 2016] X. Song, Z. Ming, L. Nie, Y . Zhao, and T. Chua. V olunteerism tendency prediction via harvesting multiple social networks. TOIS,
work page 2016
-
[35]
Modelling context with user em- beddings for sarcasm detection in social media
[Wallace et al., 2016] Silvio Amir Byron C Wallace, Hao Lyu, and Paula Carvalho M´ario J Silva. Modelling context with user em- beddings for sarcasm detection in social media. CoNLL,
work page 2016
-
[36]
Community preserving net- work embedding
[Wang et al., 2017] Xiao Wang, Peng Cui, Jing Wang, Jian Pei, Wenwu Zhu, and Shiqiang Yang. Community preserving net- work embedding. In AAAI,
work page 2017
-
[37]
[Yang et al., 2015] C. Yang, S. Pan, J. Mahmud, H. Yang, and P. Srinivasan. Using personal traits for brand preference predic- tion. In EMNLP,
work page 2015
-
[38]
Bi- ased random walk based social regularization for word embed- dings
[Zeng et al., 2018] Ziqian Zeng, Xin Liu, and Yangqiu Song. Bi- ased random walk based social regularization for word embed- dings. In IJCAI,
work page 2018
-
[39]
User profile preserving social network embed- ding
[Zhang et al., 2017] Daokun Zhang, Jie Yin, Xingquan Zhu, and Chengqi Zhang. User profile preserving social network embed- ding. In IJCAI,
work page 2017
-
[40]
Anrl: Attributed network representation learning via deep neural networks
[Zhang et al., 2018b] Zhen Zhang, Hongxia Yang, Jiajun Bu, Sheng Zhou, Pinggang Yu, Jianwei Zhang, Martin Ester, and Can Wang. Anrl: Attributed network representation learning via deep neural networks. In IJCAI, 2018
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.