Do Generative Recommenders Deepen the Information Cocoon? A Closed-Loop Simulation with LLM-powered User Simulators
Pith reviewed 2026-06-26 22:43 UTC · model grok-4.3
The pith
Generative recommenders preserve more exposure diversity than traditional sequential baselines but still concentrate in semantic ID space under feedback loops.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
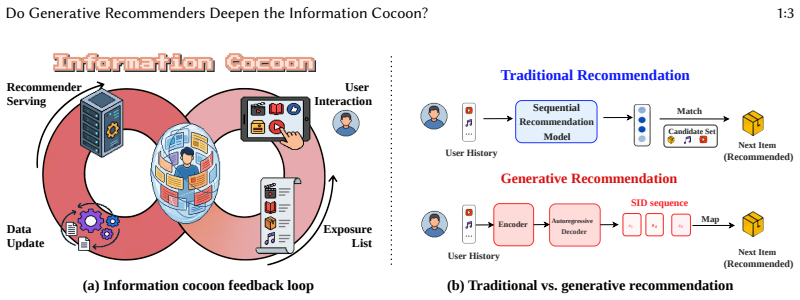
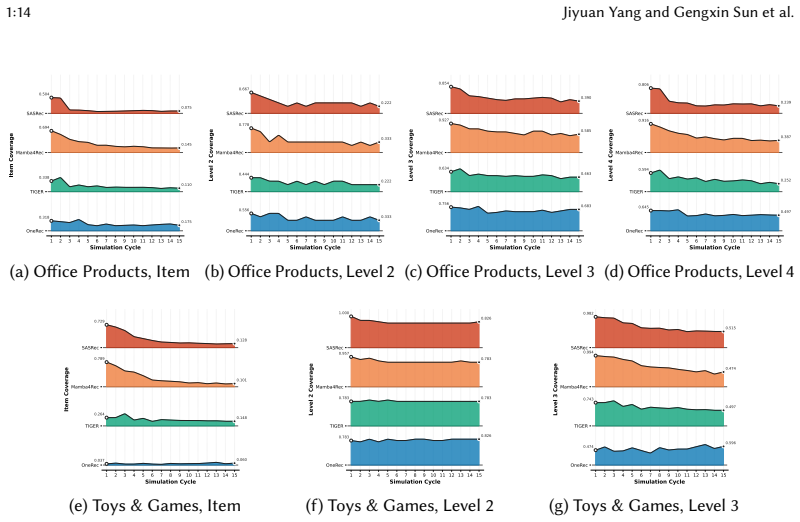
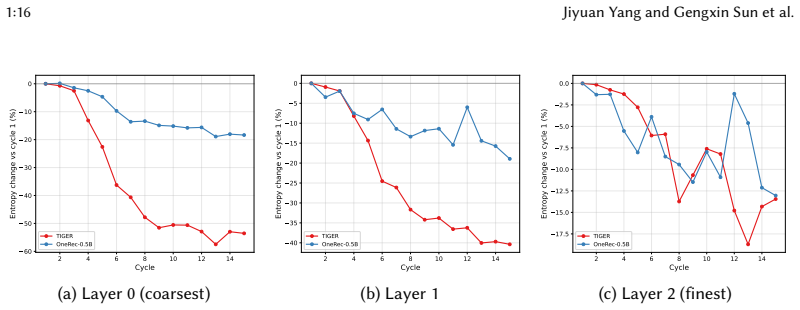
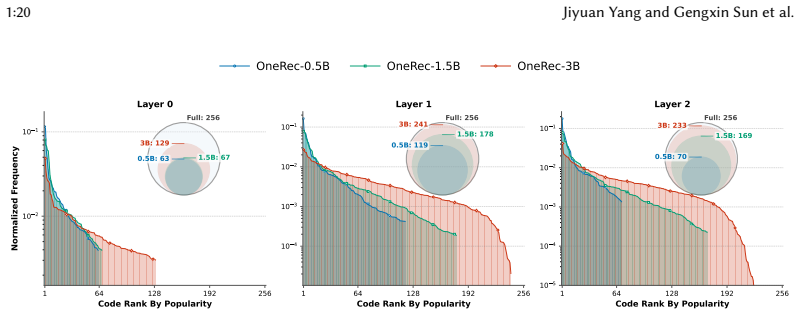
Generative recommenders are generally less prone to exposure-level cocoon formation than traditional baselines, preserving broader exposure diversity and slowing cross-user homogenization. Feedback loops can still induce concentration within the generated SID space. Cocoon severity depends strongly on tokenization strategy and model scale: collaborative-signal tokenization produces stronger cocoon effects than semantic tokenization, whereas larger models maintain greater code-space diversity and better retain access to niche content.
What carries the argument
RecLoop closed-loop simulation framework with LLM-driven user agents that runs repeated recommendation-interaction cycles and tracks both standard exposure metrics and the Code-Space Structural Cocoon metric measuring concentration inside generated semantic ID sequences.
If this is right
- Generative recommenders maintain higher exposure diversity across feedback cycles than traditional sequential models.
- Concentration can still appear inside the semantic ID space even when item-level exposure remains diverse.
- Collaborative-signal tokenization produces stronger code-space cocoon effects than semantic tokenization.
- Larger model scale preserves greater semantic-ID diversity and access to niche items.
Where Pith is reading between the lines
- Design choices around tokenization may offer a direct lever for limiting code-space narrowing without changing the underlying generative architecture.
- The observed scale dependence suggests that capacity constraints in deployed generative models could accelerate homogenization relative to the simulated larger models.
- Extending the simulation to non-LLM user models would help separate recommender-driven effects from simulator-specific artifacts.
Load-bearing premise
LLM-powered user agents accurately reproduce the preference evolution, choice behavior, and long-term interaction patterns of real human users under repeated recommendation feedback.
What would settle it
A live deployment in which real users interact repeatedly with both generative and traditional recommenders while exposure diversity and semantic-ID-space concentration are tracked over the same number of cycles.
Figures












read the original abstract
Recommender systems alleviate information overload, yet repeated feedback between recommendations and user interactions can reinforce existing preferences and narrow users' exposure, forming information cocoons. While this phenomenon has been widely studied in traditional sequential recommendation, its impact on generative recommendation remains unclear. By replacing atomic item IDs with Semantic ID (SID) sequences, generative recommenders introduce a different recommendation mechanism whose role in information cocoon formation is not yet understood. To investigate whether generative recommenders deepen information cocoons, we propose \textsc{RecLoop}, a closed-loop simulation framework with LLM-driven user agents. We compare two generative recommenders and two traditional sequential baselines on two Amazon datasets across multiple feedback cycles. In addition to standard exposure-level metrics, we introduce \emph{Code-Space Structural Cocoon}, a model-level metric that measures concentration in the generated SID space. Experimental results show that generative recommenders are generally less prone to exposure-level cocoon formation than traditional baselines, preserving broader exposure diversity and slowing cross-user homogenization. However, feedback loops can still induce concentration within the generated SID space. We further find that cocoon severity depends strongly on tokenization strategy and model scale: collaborative-signal tokenization produces stronger cocoon effects than semantic tokenization, whereas larger models maintain greater code-space diversity and better retain access to niche content. These findings suggest that information cocoons in generative recommendation are shaped not only by recommendation behavior, but also by item tokenization and model capacity. Our code is available at https://github.com/Dregen-Yor/RecLoop.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that generative recommenders (using Semantic ID sequences) are generally less prone to exposure-level information cocoon formation than traditional sequential baselines, as measured in the proposed RecLoop closed-loop simulation with LLM-powered user agents on Amazon datasets; they preserve broader exposure diversity and slow cross-user homogenization, though feedback loops can still induce concentration in the generated SID space, with effects modulated by tokenization strategy and model scale.
Significance. If the simulator fidelity holds, the work would provide actionable insights for generative recommender design by isolating the roles of tokenization and capacity in long-term diversity outcomes. The open-source code strengthens reproducibility. The Code-Space Structural Cocoon metric offers a model-level lens distinct from exposure metrics.
major comments (2)
- [Abstract and §3] Abstract and §3 (RecLoop framework): all comparative results on exposure diversity and homogenization depend on LLM-powered user agents, yet the manuscript provides no validation of these agents against real-user traces, preference evolution trajectories, or interaction dynamics (e.g., no human-in-the-loop calibration or artifact checks), which is load-bearing for interpreting the central claim that generative recommenders are less prone to cocoon formation.
- [§5] §5 (experimental results): the reported differences between generative and baseline models lack sensitivity checks or error bars on simulator parameters and LLM prompt variations, leaving open whether the observed preservation of exposure diversity is robust or an artifact of the unvalidated simulation setup.
minor comments (2)
- [§4] The definition and independence of the Code-Space Structural Cocoon metric should be stated explicitly in the main text before the results section to clarify how it complements exposure-level metrics.
- [Figures in §5] Figure captions and axis labels in the results figures could more clearly distinguish exposure-level versus code-space metrics.
Simulated Author's Rebuttal
We thank the referee for highlighting the critical issues of simulator validation and experimental robustness. These points are well-taken and directly affect the interpretability of our claims. We respond point-by-point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (RecLoop framework): all comparative results on exposure diversity and homogenization depend on LLM-powered user agents, yet the manuscript provides no validation of these agents against real-user traces, preference evolution trajectories, or interaction dynamics (e.g., no human-in-the-loop calibration or artifact checks), which is load-bearing for interpreting the central claim that generative recommenders are less prone to cocoon formation.
Authors: We agree that the lack of direct validation for the LLM-powered user agents is a substantive limitation, since the simulation fidelity is foundational to the exposure-level comparisons. The Amazon datasets supply only historical interaction sequences and lack the preference-evolution trajectories or human calibration data needed for full validation. In the revision we will expand §3 with an explicit discussion of agent design assumptions, prompt rationale, and acknowledged artifacts, plus proxy checks that compare simulated aggregate statistics (e.g., popularity distributions and session lengths) against held-out real data. We cannot, however, perform human-in-the-loop calibration without new data collection. revision: partial
-
Referee: [§5] §5 (experimental results): the reported differences between generative and baseline models lack sensitivity checks or error bars on simulator parameters and LLM prompt variations, leaving open whether the observed preservation of exposure diversity is robust or an artifact of the unvalidated simulation setup.
Authors: We concur that sensitivity analysis is required to establish robustness. In the revised §5 we will add experiments that vary LLM temperature, prompt phrasing, and random seeds, reporting means and standard deviations for the key diversity and homogenization metrics. These results will be included to show whether the relative advantage of generative recommenders remains stable under parameter variation. revision: yes
- Full human-in-the-loop calibration of the LLM user agents against real preference-evolution trajectories, which is not feasible with the public Amazon datasets used in the study.
Circularity Check
No circularity: metrics and simulation outcomes defined independently of each other
full rationale
The paper presents an empirical closed-loop simulation study whose reported differences between generative and sequential recommenders are produced by running the RecLoop framework on defined metrics (exposure diversity, Code-Space Structural Cocoon). These metrics are introduced as independent constructs measured on the simulation trajectories; no equation or derivation reduces the final comparative claims to quantities that were fitted from the same runs or defined in terms of the outcomes themselves. No self-citation chain, uniqueness theorem, or ansatz smuggling is invoked to justify the central results. The fidelity of the LLM user agents is an external modeling assumption rather than a self-referential step, so the derivation remains self-contained against the simulation benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM-driven agents can serve as valid proxies for human users in modeling repeated recommendation feedback loops
invented entities (1)
-
Code-Space Structural Cocoon metric
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Md Sanzeed Anwar, Grant Schoenebeck, and Paramveer S Dhillon. 2024. Filter bubble or homogenization? disentangling the long-term effects of recommendations on user consumption patterns. InProceedings of the ACM Web Conference
2024
-
[2]
Qazi Mohammad Areeb, Mohammad Nadeem, Shahab Saquib Sohail, Raza Imam, Faiyaz Doctor, Yassine Himeur, Amir Hussain, and Abbes Amira. 2023. Filter bubbles in recommender systems: Fact or fallacy—A systematic review.Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery13, 6 (2023), e1512
2023
-
[3]
Ricardo Baeza-Yates. 2018. Bias on the web.Commun. ACM61, 6 (2018), 54–61
2018
- [4]
-
[5]
Alejandro Bellogín, Iván Cantador, and Pablo Castells. 2013. A comparative study of heterogeneous item recommenda- tions in social systems.Information Sciences221 (2013), 142–169
2013
-
[6]
Keith Bradley and Barry Smyth. 2001. Improving recommendation diversity. InProceedings of the Twelfth Irish Conference on Artificial Intelligence and Cognitive Science, Maynooth, Ireland. Citeseer, 85–94
2001
-
[7]
Pablo Castells, Neil Hurley, and Saul Vargas. 2021. Novelty and diversity in recommender systems. InRecommender systems handbook. Springer, 603–646
2021
-
[8]
Luyu Chen, Quanyu Dai, Zeyu Zhang, Xueyang Feng, Mingyu Zhang, Pengcheng Tang, Xu Chen, Yue Zhu, and Zhenhua Dong. 2025. Recusersim: A realistic and diverse user simulator for evaluating conversational recommender systems. InCompanion Proceedings of the ACM on Web Conference 2025. 133–142
2025
-
[9]
Zhiyong Cheng, Yike Jin, Zhijie Zhang, Huilin Chen, Zhangling Duan, and Meng Wang. 2026. Modeling Stage-wise Evolution of User Interests for News Recommendation. InProceedings of the ACM Web Conference 2026. 6755–6764
2026
- [10]
-
[11]
Michela Del Vicario, Alessandro Bessi, Fabiana Zollo, Fabio Petroni, Antonio Scala, Guido Caldarelli, H Eugene Stanley, and Walter Quattrociocchi. 2016. The spreading of misinformation online.Proceedings of the national academy of Sciences113, 3 (2016), 554–559
2016
-
[12]
Jiaxin Deng, Shiyao Wang, Kuo Cai, Lejian Ren, Qigen Hu, Weifeng Ding, Qiang Luo, and Guorui Zhou. 2025. Onerec: Unifying retrieve and rank with generative recommender and iterative preference alignment.arXiv preprint arXiv:2502.18965(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Daniel Fleder and Kartik Hosanagar. 2009. Blockbuster culture’s next rise or fall: The impact of recommender systems on sales diversity.Management science55, 5 (2009), 697–712
2009
-
[14]
Shijie Geng, Shuchang Liu, Zuohui Fu, Yingqiang Ge, and Yongfeng Zhang. 2022. Recommendation as language processing (rlp): A unified pretrain, personalized prompt & predict paradigm (p5). InProceedings of the 16th ACM Conference on Recommender Systems. 299–315
2022
-
[15]
Hao Gu, Rui Zhong, Yu Xia, Wei Yang, Chi Lu, Peng Jiang, and Kun Gai. 2025. R 4ec: A reasoning, reflection, and refinement framework for recommendation systems. InProceedings of the Nineteenth ACM Conference on Recommender Systems. 411–421
2025
-
[16]
Ping He and Bo Yuan. 2024. On the Information Cocoon Effect in the TikTok Recommendation Algorithm. In2024 5th International Conference on Artificial Intelligence and Computer Engineering (ICAICE). IEEE, 94–98
2024
-
[17]
Ray Jiang, Silvia Chiappa, Tor Lattimore, András György, and Pushmeet Kohli. 2019. Degenerate feedback loops in recommender systems. InProceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society. 383–390
2019
-
[18]
Wang-Cheng Kang and Julian McAuley. 2018. Self-attentive sequential recommendation. InICDM. IEEE, 197–206
2018
- [19]
-
[20]
Nian Li, Chen Gao, Jinghua Piao, Xin Huang, Aizhen Yue, Liang Zhou, Qingmin Liao, and Yong Li. 2022. An exploratory study of information cocoon on short-form video platform. InProceedings of the 31st acm international conference on information & knowledge management. 4178–4182
2022
-
[21]
Xiaoxi Li, Jiajie Jin, Yujia Zhou, Yuyao Zhang, Peitian Zhang, Yutao Zhu, and Zhicheng Dou. 2025. From Matching to Generation: A Survey on Generative Information Retrieval.ACM Trans. Inf. Syst.43, 3, Article 83 (May 2025), 62 pages. https://doi.org/10.1145/3722552
-
[22]
Siyi Liang, Nurzat Alimu, Hanchi Si, Hong Li, and Chuanmin Mi. 2023. Influence of artificial intelligence recom- mendation on consumers’ purchase intention under the information cocoon effect. InInternational Conference on Human-Computer Interaction. Springer, 249–259
2023
-
[23]
Siyi Lin, Chongming Gao, Jiawei Chen, Sheng Zhou, Binbin Hu, Yan Feng, Chun Chen, and Can Wang. 2025. How do recommendation models amplify popularity bias? An analysis from the spectral perspective. InProceedings of the ACM Trans. Inf. Syst., Vol. 1, No. 1, Article 1. Publication date: January 2026. Do Generative Recommenders Deepen the Information Cocoon...
2025
- [24]
-
[25]
Hongyang Liu, Zhu Sun, Tianjun Wei, Yan Wang, Jiajie Zhu, and Xinghua Qu. 2026. Diagnostic-Guided Dynamic Profile Optimization for LLM-based User Simulators in Sequential Recommendation. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 15306–15314
2026
-
[26]
Gabriel Machado Lunardi, Guilherme Medeiros Machado, Vinicius Maran, and José Palazzo M de Oliveira. 2020. A metric for filter bubble measurement in recommender algorithms considering the news domain.Applied Soft Computing 97 (2020), 106771
2020
-
[27]
Julian McAuley, Christopher Targett, Qinfeng Shi, and Anton Van Den Hengel. 2015. Image-based recommendations on styles and substitutes. InProceedings of the 38th international ACM SIGIR conference on research and development in information retrieval. 43–52
2015
-
[28]
2011.The filter bubble: What the Internet is hiding from you
Eli Pariser. 2011.The filter bubble: What the Internet is hiding from you. penguin UK
2011
-
[29]
O’Brien, Carrie J
Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. 2023. Generative Agents: Interactive Simulacra of Human Behavior. InIn the 36th Annual ACM Symposium on User Interface Software and Technology (UIST ’23)(San Francisco, CA, USA)(UIST ’23). Association for Computing Machinery, New York, NY, USA
2023
-
[30]
Hanqi Peng and Chang Liu. 2021. Breaking the information cocoon: when do people actively seek conflicting information?Proceedings of the Association for Information Science and Technology58, 1 (2021), 801–803
2021
-
[31]
Shashank Rajput, Nikhil Mehta, Anima Singh, Raghunandan Hulikal Keshavan, Trung Vu, Lukasz Heldt, Lichan Hong, Yi Tay, Vinh Tran, Jonah Samost, et al. 2023. Recommender systems with generative retrieval.Advances in Neural Information Processing Systems36 (2023), 10299–10315
2023
-
[32]
Karthik Shivaram, Ping Liu, Matthew Shapiro, Mustafa Bilgic, and Aron Culotta. 2022. Reducing cross-topic political homogenization in content-based news recommendation. InProceedings of the 16th ACM conference on Recommender Systems. 220–228
2022
-
[33]
Yubo Shu, Haonan Zhang, Hansu Gu, Peng Zhang, Tun Lu, Dongsheng Li, and Ning Gu. 2024. RAH! RecSys–assistant– human: A human-centered recommendation framework with LLM agents.IEEE Transactions on Computational Social Systems11, 5 (2024), 6759–6770
2024
- [34]
-
[35]
Nicholas Sukiennik, Chen Gao, and Nian Li. 2024. Uncovering the deep filter bubble: narrow exposure in short-video recommendation. InProceedings of the ACM Web Conference 2024. 4727–4735
2024
- [36]
-
[37]
Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang. 2019. BERT4Rec: Sequential recom- mendation with bidirectional encoder representations from transformer. InCIKM. 1441–1450
2019
-
[38]
2001.Echo chambers: Bush v
Cass R Sunstein. 2001.Echo chambers: Bush v. Gore, impeachment, and beyond. Princeton University Press Princeton, NJ
2001
-
[39]
Saúl Vargas and Pablo Castells. 2011. Rank and relevance in novelty and diversity metrics for recommender systems. InProceedings of the fifth ACM conference on Recommender systems. 109–116
2011
-
[40]
Wenjie Wang, Honghui Bao, Xinyu Lin, Jizhi Zhang, Yongqi Li, Fuli Feng, See-Kiong Ng, and Tat-Seng Chua. 2024. Learnable item tokenization for generative recommendation. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management. 2400–2409
2024
- [41]
-
[42]
Yidan Wang, Zhaochun Ren, Weiwei Sun, Jiyuan Yang, Zhixiang Liang, Xin Chen, Ruobing Xie, Su Yan, Xu Zhang, Pengjie Ren, et al. 2024. Content-based collaborative generation for recommender systems. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management. 2420–2430
2024
-
[43]
Longtao Xiao, Haozhao Wang, Cheng Wang, Linfei Ji, Yifan Wang, Jieming Zhu, Zhenhua Dong, Rui Zhang, and Ruixuan Li. 2025. UNGER: Generative Recommendation with A Unified Code via Semantic and Collaborative Integration.ACM Trans. Inf. Syst.44, 2, Article 31 (Dec. 2025), 31 pages. https://doi.org/10.1145/3773771
-
[44]
Jiyuan Yang, Yue Ding, Yidan Wang, Pengjie Ren, Zhumin Chen, Fei Cai, Jun Ma, Rui Zhang, Zhaochun Ren, and Xin Xin. 2024. Debiasing Sequential Recommenders through Distributionally Robust Optimization over System Exposure. InProceedings of the 17th ACM International Conference on Web Search and Data Mining. 882–890. ACM Trans. Inf. Syst., Vol. 1, No. 1, A...
2024
-
[45]
Jiyuan Yang, Yuanzi Li, Jingyu Zhao, Hanbing Wang, Muyang Ma, Jun Ma, Zhaochun Ren, Mengqi Zhang, Xin Xin, Zhumin Chen, and Pengjie Ren. 2024. Uncovering Selective State Space Model’s Capabilities in Lifelong Sequential Recommendation. arXiv:2403.16371 [cs.IR] https://arxiv.org/abs/2403.16371
- [46]
-
[47]
An Zhang, Yuxin Chen, Leheng Sheng, Xiang Wang, and Tat-Seng Chua. 2024. On generative agents in recommendation. InProceedings of the 47th international ACM SIGIR conference on research and development in Information Retrieval. 1807–1817
2024
-
[48]
Junjie Zhang, Yupeng Hou, Ruobing Xie, Wenqi Sun, Julian McAuley, Wayne Xin Zhao, Leyu Lin, and Ji-Rong Wen
-
[49]
InProceedings of the ACM Web Conference 2024
Agentcf: Collaborative learning with autonomous language agents for recommender systems. InProceedings of the ACM Web Conference 2024. 3679–3689
2024
-
[50]
Lin Zhang, Yahong Lian, Haixia Wu, Chunyao Song, and Xiaojie Yuan. 2025. An Exploratory Study on Information Cocoon in Recommender Systems.Data Science and Engineering10, 3 (2025), 495–514
2025
-
[51]
Zijian Zhang, Shuchang Liu, Ziru Liu, Rui Zhong, Qingpeng Cai, Xiangyu Zhao, Chunxu Zhang, Qidong Liu, and Peng Jiang. 2025. Llm-powered user simulator for recommender system. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 13339–13347
2025
-
[52]
Wei Zhao, Benyou Wang, Jianbo Ye, Yongqiang Gao, Min Yang, and Xiaojun Chen. 2018. PLASTIC: Prioritize Long and Short-term Information in Top-n Recommendation using Adversarial Training. InProceedings of the Twenty- Seventh International Joint Conference on Artificial Intelligence, IJCAI-18. International Joint Conferences on Artificial Intelligence Organ...
-
[53]
Wayne Xin Zhao, Shanlei Mu, Yupeng Hou, Zihan Lin, Yushuo Chen, Xingyu Pan, Kaiyuan Li, Yujie Lu, Hui Wang, Changxin Tian, Yingqian Min, Zhichao Feng, Xinyan Fan, Xu Chen, Pengfei Wang, Wendi Ji, Yaliang Li, Xiaoling Wang, and Ji-Rong Wen. 2021. RecBole: Towards a Unified, Comprehensive and Efficient Framework for Recommendation Algorithms. InProceedings ...
-
[54]
Ziqi Zhao, Zhaochun Ren, Jiyuan Yang, Zuming Yan, Zihan Wang, Liu Yang, Pengjie Ren, Zhumin Chen, Maarten de Rijke, and Xin Xin. 2025. Improving Sequential Recommenders through Counterfactual Augmentation of System Exposure. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval(Padua, Italy)(SIGI...
-
[55]
Guorui Zhou, Jiaxin Deng, Jinghao Zhang, Kuo Cai, Lejian Ren, Qiang Luo, Qianqian Wang, Qigen Hu, Rui Huang, Shiyao Wang, et al. 2025. Onerec technical report.arXiv preprint arXiv:2506.13695(2025). ACM Trans. Inf. Syst., Vol. 1, No. 1, Article 1. Publication date: January 2026. Do Generative Recommenders Deepen the Information Cocoon? 1:27 8 APPENDIX Prom...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.