Simulating Unified Tensor Resharding in heterogeneous AI systems
Pith reviewed 2026-06-26 03:56 UTC · model grok-4.3
The pith
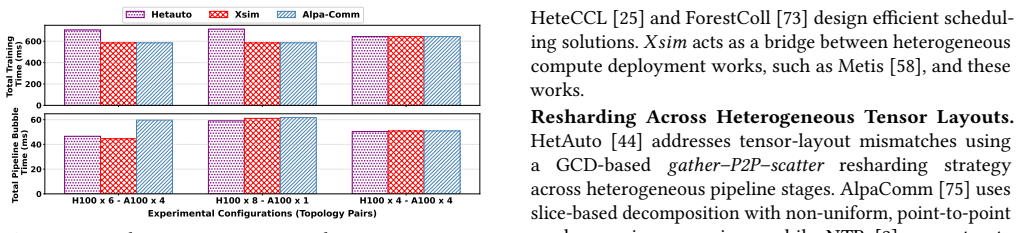
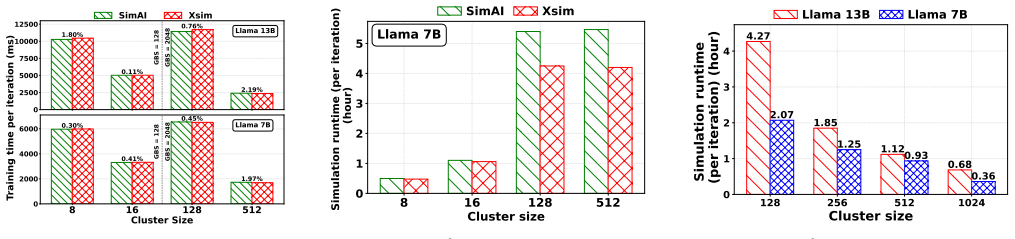
Xsim simulates heterogeneous LLM training and predicts times with under 5% error.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
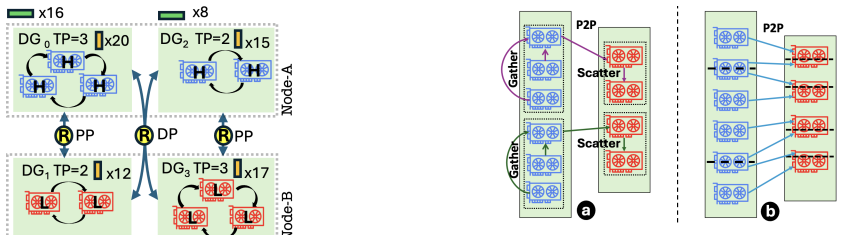
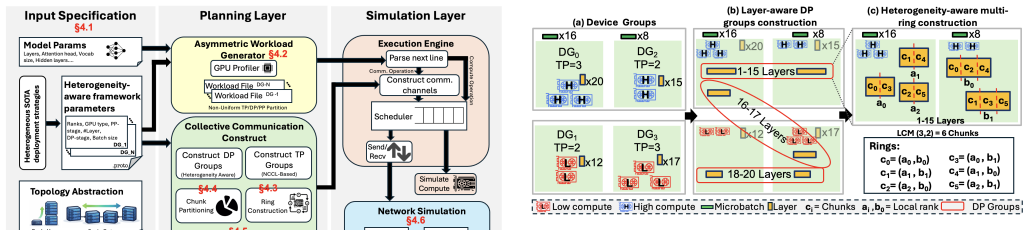
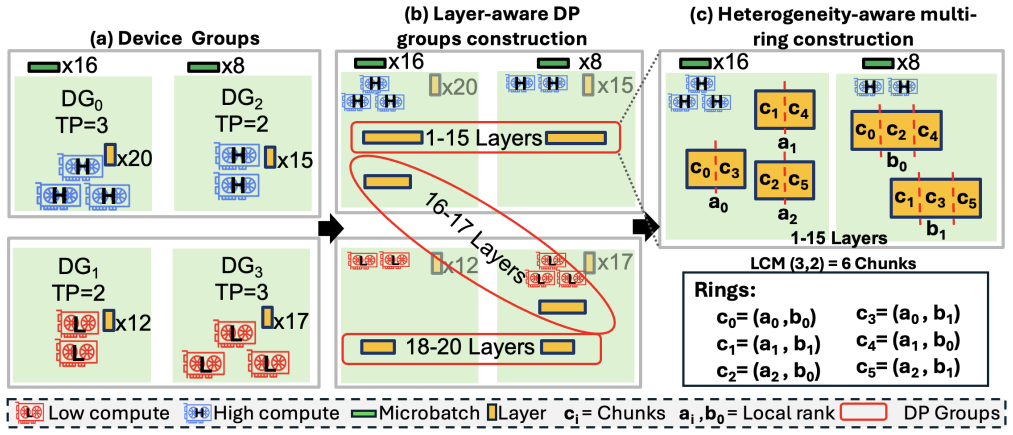
Xsim is a heterogeneity-aware simulator for distributed LLM training that supports load balancing through non-uniform workload partitioning across heterogeneous device groups, heterogeneity-aware collective communication via customized ring construction and chunk partitioning, reusable abstractions for emerging pipeline-parallel algorithms and non-uniform tensor resharding, flexible inputs for custom device groups and parallelism mappings, and pluggable integration with NS-3 and htsim, delivering training-time predictions with less than 5% error across most heterogeneous data-parallel and tensor-parallel configurations and around 2% error when modeling pipeline-parallel communication.
What carries the argument
Xsim simulator and its abstractions for non-uniform workload partitioning, customized ring construction, and chunk partitioning that enable heterogeneity-aware collective communication and tensor resharding.
If this is right
- Training time can be predicted within 5% error for heterogeneous data-parallel and tensor-parallel setups.
- Pipeline-parallel communication modeling reaches around 2% error.
- Metrics such as pipeline bubble time and straggler waiting time become available for inspection.
- Deployment plans with custom device groups and device-to-parallelism mappings can be specified and evaluated.
- Users can trade simulation fidelity for speed by choosing between NS-3 and htsim backends.
Where Pith is reading between the lines
- Teams could iterate on mixed-hardware allocation strategies entirely in simulation before committing physical resources.
- The same abstractions might be reused to compare alternative ring constructions or chunk sizes without new code.
- Applying the simulator to MoE or multimodal workloads that deliberately exploit device differences would test its generality.
- Comparing simulated versus measured times on a geographically distributed cluster would check whether network heterogeneity is captured at scale.
Load-bearing premise
The implemented abstractions for non-uniform workload partitioning, customized ring construction, and chunk partitioning will produce predictions that match actual hardware behavior.
What would settle it
Run Xsim on a specific heterogeneous data-parallel or tensor-parallel configuration, measure the real training time on the corresponding hardware cluster, and observe whether the absolute percentage error exceeds 5%.
Figures




read the original abstract
State-of-the-art AI training simulators assume homogeneous compute and network infrastructure. However, real-world training infrastructure is becoming increasingly heterogeneous since: (a) Model architectures such as multimodal and MoE exploit heterogeneity to improve device utilization, (b) Public cloud platforms often provide limited availability of homogeneous hardware due to fast hardware evolution, and (c) Large enterprises frequently deploy geographically distributed infrastructure that is both diverse and heterogeneous. In this paper, we present Xsim, a heterogeneity-aware simulator for distributed LLM training. Xsim supports: (i) Load balancing through non-uniform workload partitioning across heterogeneous device groups, (ii) Heterogeneity-aware collective communication via customized ring construction and chunk partitioning, (iii) Reusable heterogeneity-aware abstractions for emerging pipeline-parallel algorithms and non-uniform tensor resharding technique, (iv) Flexible input abstractions for specifying deployment plans with custom device groups and custom device-to-parallelism mappings, and (v) Pluggable integration with NS-3 and htsim, allowing users to trade off simulation fidelity for performance and scalability. Our evaluation demonstrates that Xsim accurately predicts training time for real-world heterogeneous deployments, with an error of less than 5% across most heterogeneous data-parallel/tensor-parallel configurations and around 2% error with pipeline-parallel communication modeling. We expose actionable metrics such as pipeline bubble time and straggler waiting time.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Xsim, a heterogeneity-aware simulator for distributed LLM training. It supports non-uniform workload partitioning across device groups, heterogeneity-aware collective communication via customized ring construction and chunk partitioning, reusable abstractions for pipeline-parallel algorithms and non-uniform tensor resharding, flexible input for custom device-to-parallelism mappings, and pluggable backends (NS-3, htsim). The central claim is that Xsim predicts training times for real heterogeneous deployments with <5% error on most data-parallel/tensor-parallel configurations and ~2% error on pipeline-parallel communication modeling, while exposing metrics such as pipeline bubble time and straggler waiting time.
Significance. If the accuracy claims are substantiated with concrete heterogeneous hardware validation, the simulator would address a practical gap in modeling real-world AI training infrastructure that is increasingly heterogeneous due to cloud availability, multimodal/MoE models, and geo-distributed deployments. The pluggable network backends and reusable abstractions for emerging parallelism patterns are potentially useful contributions to the distributed systems simulation literature.
major comments (1)
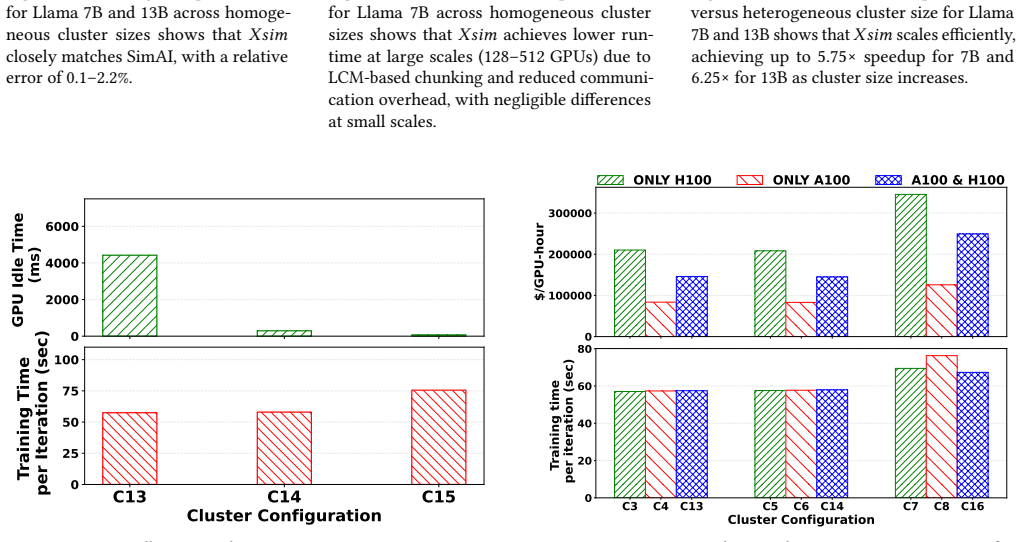
- [Abstract] Abstract: the claim that Xsim 'accurately predicts training time ... with an error of less than 5% across most heterogeneous data-parallel/tensor-parallel configurations' is load-bearing for the paper's contribution, yet the abstract (and the provided manuscript excerpt) supplies no list of tested device mixes, no description of ground-truth runtime collection on real heterogeneous clusters, no indication of how link bandwidths or device performance were measured, and no discussion of whether the NS-3/htsim backends were calibrated against the same hardware. This prevents assessment of whether the reported errors reflect actual hardware match or only internal consistency checks.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater clarity in the abstract regarding our accuracy claims. We address the comment below and will revise the manuscript to strengthen the presentation of our validation methodology.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that Xsim 'accurately predicts training time ... with an error of less than 5% across most heterogeneous data-parallel/tensor-parallel configurations' is load-bearing for the paper's contribution, yet the abstract (and the provided manuscript excerpt) supplies no list of tested device mixes, no description of ground-truth runtime collection on real heterogeneous clusters, no indication of how link bandwidths or device performance were measured, and no discussion of whether the NS-3/htsim backends were calibrated against the same hardware. This prevents assessment of whether the reported errors reflect actual hardware match or only internal consistency checks.
Authors: We agree that the abstract, constrained by length, omits key details needed to substantiate the central accuracy claim. The full manuscript's evaluation section describes the tested device mixes, ground-truth collection on physical heterogeneous clusters, bandwidth and performance measurements, and backend calibration against the same hardware. To directly address the concern and allow readers to evaluate the claims immediately, we will revise the abstract to include a concise statement on the validation approach and hardware configurations used. This change will clarify that the reported errors derive from hardware comparisons rather than solely internal checks. revision: yes
Circularity Check
No circularity: simulator validation relies on external hardware comparison, not self-referential fitting or definitions
full rationale
The paper introduces Xsim as a new simulator implementing heterogeneity-aware abstractions (non-uniform partitioning, customized rings, chunking, pluggable NS-3/htsim backends) and reports empirical prediction accuracy (<5% error on data/tensor-parallel configs, ~2% on pipeline) against real heterogeneous deployments. No equations, fitted parameters, or self-citations are presented that would make the accuracy claim equivalent to its inputs by construction. The load-bearing step is an external benchmark comparison, which is independent of the simulator's internal definitions. This matches the default case of a systems tool paper whose central claim does not reduce to tautology.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Meta AI. 2025. The LLaMA 4 Herd: The Beginning of a New Era of Natively Multimodal AI Innovation.https://ai .meta.com/blog/ llama-4-multimodal-intelligence/Accessed from Meta AI Blog on 2026-02-06. 12
2025
- [2]
-
[3]
ascentoptics. 2025. InfiniBand vs RoCE network fabrics: RDMA inter- connect comparisons.https://ascentoptics .com/blog/infiniband-vs- roce-which-is-better-suited-for-ai-data-center-networks/InfiniBand delivers engineered lossless RDMA fabrics with ultra-low latency and high throughput (up to 400 800 Gbps+ per port), while RoCE (espe- cially RoCEv2) brings...
2025
-
[4]
Songyuan Bai, Hao Zheng, Chen Tian, Xiaoliang Wang, Chang Liu, Xin Jin, Fu Xiao, Qiao Xiang, Wanchun Dou, and Guihai Chen. 2024. Unison: a parallel-efficient and user-transparent network simulation kernel. InProceedings of the Nineteenth European Conference on Com- puter Systems. 115–131
2024
-
[5]
Jehyeon Bang, Yujeong Choi, Myeongwoo Kim, Yongdeok Kim, and Minsoo Rhu. 2024. vtrain: A simulation framework for evaluating cost-effective and compute-optimal large language model training. In2024 57th IEEE/ACM International Symposium on Microarchitecture (MICRO). IEEE, 153–167
2024
-
[6]
Jaehong Cho, Minsu Kim, Hyunmin Choi, Guseul Heo, and Jongse Park
-
[7]
In2024 IEEE International Symposium on Workload Characterization (IISWC)
LLMServingSim: A HW/SW Co-Simulation Infrastructure for LLM Inference Serving at Scale. In2024 IEEE International Symposium on Workload Characterization (IISWC). IEEE, 15–29
-
[8]
2021.Apsara Conference 2021 | Alibaba Cloud Re- leased the Fourth-Generation SHENLONG Architecture.https:// www.alibabacloud.com/blog/598193Accessed: 2026-02-06
Alibaba Cloud. 2021.Apsara Conference 2021 | Alibaba Cloud Re- leased the Fourth-Generation SHENLONG Architecture.https:// www.alibabacloud.com/blog/598193Accessed: 2026-02-06
2021
-
[9]
2026.Heterogeneous Comput- ing.https://www .alibabacloud.com/en/product/ heterogeneous_computing?_p_lcAccessed: 2026-02-06
Alibaba Cloud. 2026.Heterogeneous Comput- ing.https://www .alibabacloud.com/en/product/ heterogeneous_computing?_p_lcAccessed: 2026-02-06
2026
-
[10]
2026.GPU networking overview.https: //docs.cloud.google.com/ai-hypercomputer/docs/networking- overviewAccessed: 2026-02-06
Google Cloud. 2026.GPU networking overview.https: //docs.cloud.google.com/ai-hypercomputer/docs/networking- overviewAccessed: 2026-02-06
2026
-
[11]
ConnectX-7 Datasheet.https: //www.nvidia.com/content/dam/en-zz/Solutions/networking/ ethernet-adapters/connectx-7-datasheet-Final .pdf
NVIDIA Corporation. ConnectX-7 Datasheet.https: //www.nvidia.com/content/dam/en-zz/Solutions/networking/ ethernet-adapters/connectx-7-datasheet-Final .pdf. Accessed: 2026-02-06
2026
-
[12]
2018.NCCL Developer Guide: Collec- tive Communication Primitives (Version 2.0.5)
NVIDIA Corporation. 2018.NCCL Developer Guide: Collec- tive Communication Primitives (Version 2.0.5). NVIDIA Corpora- tion.https://docs .nvidia.com/deeplearning/nccl/archives/nccl_205/ nccl-developer-guide/index.html
2018
-
[13]
NVIDIA Corporation. 2026. NVIDIA DGX B200: The Foundation for Your AI Factory.https://www .nvidia.com/en-in/data-center/dgx- b200/. Accessed: 2026-06-11
2026
-
[14]
NVIDIA Corporation. 2026. NVIDIA H200 GPU.https:// www.nvidia.com/en-in/data-center/h200/. Accessed: 2026-06-10
2026
-
[15]
HTSim Network Simulator.https://github .com/ Broadcom/csg-htsimAccessed from GitHub repository
Broadcom CSG. HTSim Network Simulator.https://github .com/ Broadcom/csg-htsimAccessed from GitHub repository. Accessed: 2026-02-06
2026
-
[16]
2025.Set Up a gRPC Service — Ray Serve gRPC Guide.https://docs .ray.io/en/latest/serve/advanced-guides/grpc- guide.htmlAccessed: 7 Feb 2026
Ray Documentation. 2025.Set Up a gRPC Service — Ray Serve gRPC Guide.https://docs .ray.io/en/latest/serve/advanced-guides/grpc- guide.htmlAccessed: 7 Feb 2026
2025
-
[17]
Meta Engineering. 2023. Arcadia: An end-to-end AI system performance simulator.https://engineering .fb.com/2023/09/07/ data-infrastructure/arcadia-end-to-end-ai-system-performance- simulator/Meta Engineering Blog Accessed: 2026-02-06
2023
-
[18]
Yicheng Feng, Yuetao Chen, Kaiwen Chen, Jingzong Li, Tianyuan Wu, Peng Cheng, Chuan Wu, Wei Wang, Tsung-Yi Ho, and Hong Xu
- [19]
-
[20]
Adithya Gangidi, Rui Miao, Shengbao Zheng, Sai Jayesh Bondu, Guilherme Goes, Hany Morsy, Rohit Puri, Mohammad Riftadi, Ashmitha Jeevaraj Shetty, Jingyi Yang, et al . 2024. Rdma over eth- ernet for distributed training at meta scale. InProceedings of the ACM SIGCOMM 2024 Conference. 57–70
2024
-
[21]
Amir Gholami, Zhewei Yao, Sehoon Kim, Coleman Hooper, Michael W Mahoney, and Kurt Keutzer. 2024. AI and memory wall.IEEE Micro (2024)
2024
-
[22]
aliyun/aicb at d9b4f5cd7d9d34a80cfbb0389831a16c7fe3ed7b.https://github .com/ aliyun/aicb/tree/d9b4f5cd7d9d34a80cfbb0389831a16c7fe3ed7b Accessed: 2026-02-06
Alibaba Group. aliyun/aicb at d9b4f5cd7d9d34a80cfbb0389831a16c7fe3ed7b.https://github .com/ aliyun/aicb/tree/d9b4f5cd7d9d34a80cfbb0389831a16c7fe3ed7b Accessed: 2026-02-06
2026
-
[23]
Fei Gui, Kaihui Gao, Li Chen, Dan Li, Vincent Liu, Ran Zhang, Hong- bing Yang, and Dian Xiong. 2025. Accelerating Design Space Explo- ration for {LLM} Training Systems with Multi-experiment Parallel Simulation. In22nd USENIX Symposium on Networked Systems Design and Implementation (NSDI 25). 473–488
2025
- [24]
-
[25]
supercomputer- scale
Tom’s Hardware. 2025.Microsoft deploys world’s first “supercomputer- scale” GB300 NVL72 Azure cluster — 4,608 GB300 GPUs linked together to form a single, unified accelerator capable of 1.44 PFLOPS of inference.https://www .tomshardware.com/tech-industry/artificial- intelligence/microsoft-deploys-worlds-first-supercomputer-scale- gb300-nvl72-azure-cluster...
2025
-
[26]
Aaron Harlap, Deepak Narayanan, Amar Phanishayee, Vivek Seshadri, Nikhil Devanur, Greg Ganger, and Phil Gibbons. 2018. Pipedream: Fast and efficient pipeline parallel dnn training.arXiv preprint arXiv:1806.03377(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[27]
Chenyang Hei, Jiayi Li, Jiamin Cao, Chengxi Gao, Xiuzhu Sha, Tongrui Liu, Dengke Zhang, Ennan Zhai, and Xingwei Wang. 2026. HeteCCL: Synthesizing Near-Optimal Collective Communication Schedules for Heterogeneous GPU Clusters. In23rd USENIX Symposium on Net- worked Systems Design and Implementation (NSDI 26). USENIX Associ- ation, Renton, WA, 2533–2551.htt...
2026
-
[28]
Myeongjae Jeon, Shivaram Venkataraman, Amar Phanishayee, Junjie Qian, Wencong Xiao, and Fan Yang. 2019. Analysis of Large-Scale Multi-Tenant GPU Clusters for DNN Training Workloads. In2019 USENIX Annual Technical Conference (USENIX ATC 19). USENIX Asso- ciation, Renton, WA, 947–960.https://www .usenix.org/conference/ atc19/presentation/jeon
2019
-
[29]
Xianyan Jia, Le Jiang, Ang Wang, Wencong Xiao, Ziji Shi, Jie Zhang, Xinyuan Li, Langshi Chen, Yong Li, Zhen Zheng, et al. 2022. Whale: Efficient giant model training over heterogeneous {GPUs }. In2022 USENIX Annual Technical Conference (USENIX ATC 22). 673–688
2022
-
[30]
1994.Implementation of a Sweep Line Algorithm for the Straight Line Segment Intersection Problem
Stefan Näher Kurt Mehlhorn. 1994.Implementation of a Sweep Line Algorithm for the Straight Line Segment Intersection Problem. MAX- PLANCK-INSTITUT••FUR INFORMATIK.https://pure .mpg.de/rest/ items/item_1834220_3/component/file_2035159/content
1994
-
[31]
Seonho Lee, Amar Phanishayee, and Divya Mahajan. 2025. Forecast- ing GPU performance for deep learning training and inference. In Proceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1. 493–508
2025
-
[32]
Wenkai Li, Ran Shu, Peng Zhang, and Yongqiang Xiong. 2025. Nüwa: Efficient Generative Control Plane for AI Network Simulation. In Proceedings of the 9th Asia-Pacific Workshop on Networking. 121–127
2025
-
[33]
Ji Liu, Zhihua Wu, Danlei Feng, Minxu Zhang, Xinxuan Wu, Xuefeng Yao, Dianhai Yu, Yanjun Ma, Feng Zhao, and Dejing Dou. 2023. Heterps: Distributed deep learning with reinforcement learning based sched- uling in heterogeneous environments.Future Generation Computer Systems148 (2023), 106–117. 13
2023
- [34]
-
[35]
Yixuan Mei, Yonghao Zhuang, Xupeng Miao, Juncheng Yang, Zhihao Jia, and Rashmi Vinayak. 2025. Helix: Serving Large Language Models over Heterogeneous GPUs and Network via Max-Flow. InProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1. 586–602
2025
-
[36]
Meta’s Infrastructure Evolution and the Advent of AI.https://engineering .fb.com/2025/09/29/data-infrastructure/metas- infrastructure-evolution-and-the-advent-of-ai/
Meta. Meta’s Infrastructure Evolution and the Advent of AI.https://engineering .fb.com/2025/09/29/data-infrastructure/metas- infrastructure-evolution-and-the-advent-of-ai/. Accessed: 2026-02- 06
2025
-
[37]
Zizhao Mo, Huanle Xu, and Chengzhong Xu. 2024. Heet: Accelerating elastic training in heterogeneous deep learning clusters. InProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2. 499–513
2024
-
[38]
Deepak Narayanan, Mohammad Shoeybi, Jared Casper, Patrick LeGres- ley, Mostofa Patwary, Vijay Korthikanti, Dmitri Vainbrand, and Bryan Catanzaro. 2021.Scaling Language Model Training to a Trillion Pa- rameters Using Megatron.https://developer .nvidia.com/blog/scaling- language-model-training-to-a-trillion-parameters-using-megatron/ Accessed: 2026-02-06
2021
-
[39]
Deepak Narayanan, Mohammad Shoeybi, Jared Casper, Patrick LeGres- ley, Mostofa Patwary, Vijay Korthikanti, Dmitri Vainbrand, Prethvi Kashinkunti, Julie Bernauer, Bryan Catanzaro, et al. 2021. Efficient large-scale language model training on gpu clusters using megatron- lm. InProceedings of the international conference for high performance computing, netwo...
2021
-
[40]
RDMA over Converged Ethernet (RoCE) v2
NVIDIA Networking. RDMA over Converged Ethernet (RoCE) v2. https://docs.nvidia.com/doca/archive/2-10-0/rdma-over-converged- ethernet/index.htmlAccessed: 2026-02-06
2026
-
[41]
Chengyi Nie, Jessica Maghakian, and Zhenhua Liu. 2024. Cannikin: Optimal Adaptive Distributed DNN Training over Heterogeneous Clusters. InProceedings of the 25th International Middleware Conference. 299–312
2024
-
[42]
DGX SuperPOD Reference Architecture: DGX H100
NVIDIA. DGX SuperPOD Reference Architecture: DGX H100. https://docs.nvidia.com/https:/docs.nvidia.com/dgx-superpod- reference-architecture-dgx-h100.pdf. Accessed: 2026-02-06
2026
-
[43]
NVIDIA A100 TENSOR CORE GPU
Nvidia. NVIDIA A100 TENSOR CORE GPU. https://www.nvidia.com/content/dam/en-zz/Solutions/Data- Center/a100/pdf/nvidia-a100-datasheet-us-nvidia-1758950-r4- web.pdf. Accessed: 2026-02-06
2026
-
[44]
NVIDIA H100 Tensor Core GPU
NVIDIA. NVIDIA H100 Tensor Core GPU. https://www.nvidia.com/en- in/data-center/h100/. Accessed: 2026-02-06
2026
-
[45]
2020.{HetPipe}: Enabling large {DNN} training on (whimpy) heterogeneous {GPU } clusters through integration of pipelined model parallelism and data parallelism
Jay H Park, Gyeongchan Yun, M Yi Chang, Nguyen T Nguyen, Seung- min Lee, Jaesik Choi, Sam H Noh, and Young-ri Choi. 2020.{HetPipe}: Enabling large {DNN} training on (whimpy) heterogeneous {GPU } clusters through integration of pipelined model parallelism and data parallelism. In2020 USENIX Annual Technical Conference (USENIX ATC 20). 307–321
2020
-
[46]
Guicheng Qi, Junwei Su, Liqi Yang, Tao Li, Tingwen Xie, Yerui Sun, Yuchen Xie, and Chuan Wu. 2026. HetAuto: Cross-Cluster Auto- Parallelism for Heterogeneous Distributed Training. InProceedings of the 21st European Conference on Computer Systems. 759–779
2026
-
[47]
Yicheng Qian, Ran Shu, Rui Ma, Yang Wang, Derek Chiou, Nadeen Gebara, Luca Piccolboni, Miriam Leeser, and Yongqiang Xiong. 2025. Miniature: Fast AI Supercomputer Networks Simulation on FPGAs. In Proceedings of the 9th Asia-Pacific Workshop on Networking. 114–120
2025
-
[48]
Jianxing Qin, Jingrong Chen, Xinhao Kong, Yongji Wu, Tianjun Yuan, Liang Luo, Zhaodong Wang, Ying Zhang, Tingjun Chen, Alvin R Lebeck, et al. 2025. Phantora: Maximizing Code Reuse in Simulation- based Machine Learning System Performance Estimation.arXiv preprint arXiv:2505.01616(2025)
-
[49]
Jeff Rasley, Samyam Rajbhandari, Olatunji Ruwase, and Yuxiong He
-
[50]
InProceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining
Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters. InProceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining. 3505–3506
-
[51]
sagemaker.https://aws .amazon.com/blogs/machine- learning/improve-price-performance-of-your-model-training- using-amazon-sagemaker-heterogeneous-clusters/
sagemaker. sagemaker.https://aws .amazon.com/blogs/machine- learning/improve-price-performance-of-your-model-training- using-amazon-sagemaker-heterogeneous-clusters/. Accessed: 2026-02-06
2026
-
[52]
Amazon Web Services. 2025. Amazon Virtual Private Cloud (VPC) Overview.https://docs .aws.amazon.com/vpc/latest/userguide/what- is-amazon-vpc.htmlAccessed: 2026-02-06
2025
-
[53]
Siyuan Shen, Tommaso Bonato, Zhiyi Hu, Pasquale Jordan, Tiancheng Chen, and Torsten Hoefler. 2025. Atlahs: An application-centric net- work simulator toolchain for ai, hpc, and distributed storage. InPro- ceedings of the International Conference for High Performance Comput- ing, Networking, Storage and Analysis. 349–367
2025
-
[54]
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. 2019. Megatron-lm: Training multi- billion parameter language models using model parallelism.arXiv preprint arXiv:1909.08053(2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[55]
Min Si, Pavan Balaji, Yongzhou Chen, Ching-Hsiang Chu, Adi Gangidi, Saif Hasan, Subodh Iyengar, Dan Johnson, Bingzhe Liu, Regina Ren, Ashmitha Jeevaraj Shetty, Greg Steinbrecher, Yulun Wang, Bruce Wu, Xinfeng Xie, Jingyi Yang, Mingran Yang, Kenny Yu, Minlan Yu, Cen Zhao, Wes Bland, Denis Boyda, Suman Gumudavelli, Prashanth Kannan, Cristian Lumezanu, Rui M...
-
[56]
Arjun Singhvi, Nandita Dukkipati, Prashant Chandra, Hassan MG Wassel, Naveen Kr Sharma, Anthony Rebello, Henry Schuh, Praveen Kumar, Behnam Montazeri, Neelesh Bansod, et al . 2025. Falcon: A reliable, low latency hardware transport. InProceedings of the ACM SIGCOMM 2025 Conference. 248–263
2025
-
[57]
Srinivas Sridharan, Taekyung Heo, Louis Feng, Zhaodong Wang, Matt Bergeron, Wenyin Fu, Shengbao Zheng, Brian Coutinho, Saeed Rashidi, Changhai Man, et al. 2023. Chakra: Advancing performance bench- marking and co-design using standardized execution traces.arXiv preprint arXiv:2305.14516(2023)
-
[58]
Foteini Strati, Zhendong Zhang, George Manos, Ixeia Sánchez Périz, Qinghao Hu, Tiancheng Chen, Berk Buzcu, Song Han, Pamela Delgado, and Ana Klimovic. 2025. Sailor: Automating distributed training over dynamic, heterogeneous, and geo-distributed clusters. InProceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles. 204–220
2025
-
[59]
Yinan Tang, Tongtong Yuan, Fang Cao, Li Wang, Zhenhua Guo, Yaqian Zhao, and Rengang Li. 2024. Simulating llm training in cxl-based het- erogeneous computing cluster. InIEEE INFOCOM 2024-IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS). IEEE, 1–6
2024
-
[60]
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Alma- hairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[61]
Taegeon Um, Byungsoo Oh, Minyoung Kang, Woo-Yeon Lee, Goeun Kim, Dongseob Kim, Youngtaek Kim, Mohd Muzzammil, and Myeong- jae Jeon. 2024. Metis: Fast Automatic Distributed Training on Het- erogeneous {GPUs }. In2024 USENIX Annual Technical Conference (USENIX ATC 24). 563–578
2024
- [62]
-
[63]
Xizheng Wang, Qingxu Li, Yichi Xu, Gang Lu, Dan Li, Li Chen, Heyang Zhou, Linkang Zheng, Sen Zhang, Yikai Zhu, et al. 2025. {SimAI}: Uni- fying Architecture Design and Performance Tuning for {Large-Scale} Large Language Model Training with Scalability and Precision. In22nd USENIX Symposium on Networked Systems Design and Implementation (NSDI 25). 541–558
2025
-
[64]
Qizhen Weng, Wencong Xiao, Yinghao Yu, Wei Wang, Cheng Wang, Jian He, Yong Li, Liping Zhang, Wei Lin, and Yu Ding. 2022. MLaaS in the Wild: Workload Analysis and Scheduling in Large-Scale Het- erogeneous GPU Clusters. In19th USENIX Symposium on Networked Systems Design and Implementation (NSDI 22). USENIX Association, Renton, WA, 945–960.https://www .usen...
2022
-
[65]
William Won, Taekyung Heo, Saeed Rashidi, Srinivas Sridharan, Su- darshan Srinivasan, and Tushar Krishna. 2023. Astra-sim2. 0: Model- ing hierarchical networks and disaggregated systems for large-model training at scale. In2023 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS). IEEE, 283–294
2023
-
[66]
Ruilong Wu, Xinjiao Li, Yisu Wang, Xinyu Chen, and Dirk Kutscher
-
[67]
InProceedings of the 9th Asia-Pacific Workshop on Networking
Rethinking Dynamic Networks and Heterogeneous Computing with Automatic Parallelization. InProceedings of the 9th Asia-Pacific Workshop on Networking. 164–171
- [68]
-
[69]
Ran Yan, Youhe Jiang, Xiaonan Nie, Fangcheng Fu, Bin Cui, and Binhang Yuan. 2024. HexiScale: Accommodating Large Language Model Training over Heterogeneous Environment.arXiv preprint arXiv:2409.01143(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[70]
Ran Yan, Youhe Jiang, Wangcheng Tao, Xiaonan Nie, Bin Cui, and Binhang Yuan. 2024. Flashflex: Accommodating large language model training over heterogeneous environment.arXiv e-prints(2024), arXiv– 2409
2024
-
[71]
Shengyuan Ye, Liekang Zeng, Xiaowen Chu, Guoliang Xing, and Xu Chen. 2024. Asteroid: Resource-efficient hybrid pipeline parallelism for collaborative DNN training on heterogeneous edge devices. InProceed- ings of the 30th Annual International Conference on Mobile Computing and Networking. 312–326
2024
-
[72]
Xiaodong Yi, Shiwei Zhang, Ziyue Luo, Guoping Long, Lansong Diao, Chuan Wu, Zhen Zheng, Jun Yang, and Wei Lin. 2020. Optimizing distributed training deployment in heterogeneous GPU clusters. In Proceedings of the 16th International Conference on emerging Networking EXperiments and Technologies. 93–107
2020
-
[73]
Xiaofei Yue, Fangming Zhao, Fulun Ye, Jiongchi Yu, Zhaoxuan Li, Tingting Li, Ziming Zhao, and Jianwei Yin. 2026. HeteroSim: Towards High-Fidelity Heterogeneous LLM Training Simulation on GPUs. In Proceedings of the ACM Web Conference 2026. 5189–5197
2026
-
[74]
Jinghui Zhang, Geng Niu, Qiangsheng Dai, Haorui Li, Zhihua Wu, Fang Dong, and Zhiang Wu. 2023. PipePar: Enabling fast DNN pipeline parallel training in heterogeneous GPU clusters.Neurocomputing555 (2023), 126661
2023
-
[75]
Shiwei Zhang, Lansong Diao, Chuan Wu, Zongyan Cao, Siyu Wang, and Wei Lin. 2024. Hap: Spmd dnn training on heterogeneous gpu clusters with automated program synthesis. InProceedings of the Nine- teenth European Conference on Computer Systems. 524–541
2024
-
[76]
Zili Zhang, Yinmin Zhong, Yimin Jiang, Hanpeng Hu, Jianjian Sun, Zheng Ge, Yibo Zhu, Daxin Jiang, and Xin Jin. 2025. DistTrain: Ad- dressing Model and Data Heterogeneity with Disaggregated Training for Multimodal Large Language Models. InProceedings of the ACM SIGCOMM 2025 Conference. 24–38
2025
- [77]
-
[78]
Yanli Zhao, Andrew Gu, Rohan Varma, Liang Luo, Chien-Chin Huang, Min Xu, Less Wright, Hamid Shojanazeri, Myle Ott, Sam Shleifer, et al
-
[79]
PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel
Pytorch fsdp: experiences on scaling fully sharded data parallel. arXiv preprint arXiv:2304.11277(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[80]
How do we find all these subsets?
Yonghao Zhuang, Lianmin Zheng, Zhuohan Li, Eric Xing, Qirong Ho, Joseph Gonzalez, Ion Stoica, Hao Zhang, and Hexu Zhao. 2023. On optimizing the communication of model parallelism.Proceedings of Machine Learning and Systems5 (2023), 526–540. A Input Specification Sample The simulation framework mainly works with three input specifications which define our ...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.