Rethinking Sampling Strategy in Link Prediction
Pith reviewed 2026-06-26 15:30 UTC · model grok-4.3
The pith
The structural features of missing links, set by how probe sets are sampled, control link prediction accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
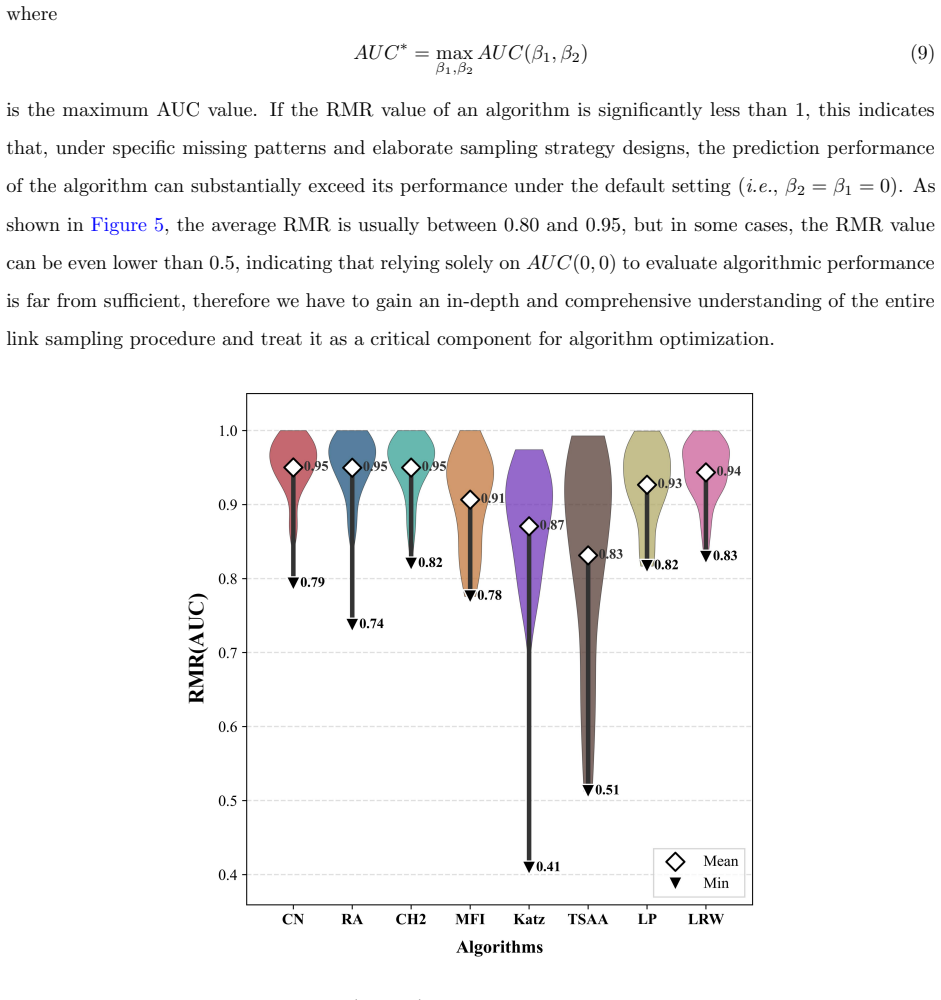
Using β-sampling to vary the probe set shows that prediction accuracy rises when missing links preferentially connect high-degree nodes. Even with a fixed probe set, different second-stage sampling strategies for the validation set produce measurably different accuracies, and the strategy that works best is neither random sampling nor consistent sampling that matches structural traits.
What carries the argument
β-sampling, a scheme that draws each observed link into the probe set with probability proportional to (degree_u × degree_v)^β, which tunes the degree bias of the simulated missing links.
If this is right
- Prediction performance improves when missing links tend to join high-degree nodes.
- Even a fixed probe set leaves room for second-stage sampling to shift measured accuracy.
- The best validation-set sampling rule is not the same as random selection or consistent structural matching.
- Evaluation protocols must account for both sampling stages rather than treating them as neutral.
Where Pith is reading between the lines
- Real missing links in networks may follow particular degree patterns, so results could differ when those patterns are known.
- Algorithms might be tuned or selected according to the expected β value of the missing data.
- Benchmark suites could usefully include multiple probe sets generated at different β values.
Load-bearing premise
Changing the single parameter β cleanly alters only the structural properties of the probe set without introducing other confounding differences across the 45 networks.
What would settle it
If prediction accuracy shows no systematic change when β is varied across a fresh collection of networks, or if second-stage sampling effects disappear under controlled tests that hold all other factors fixed.
Figures
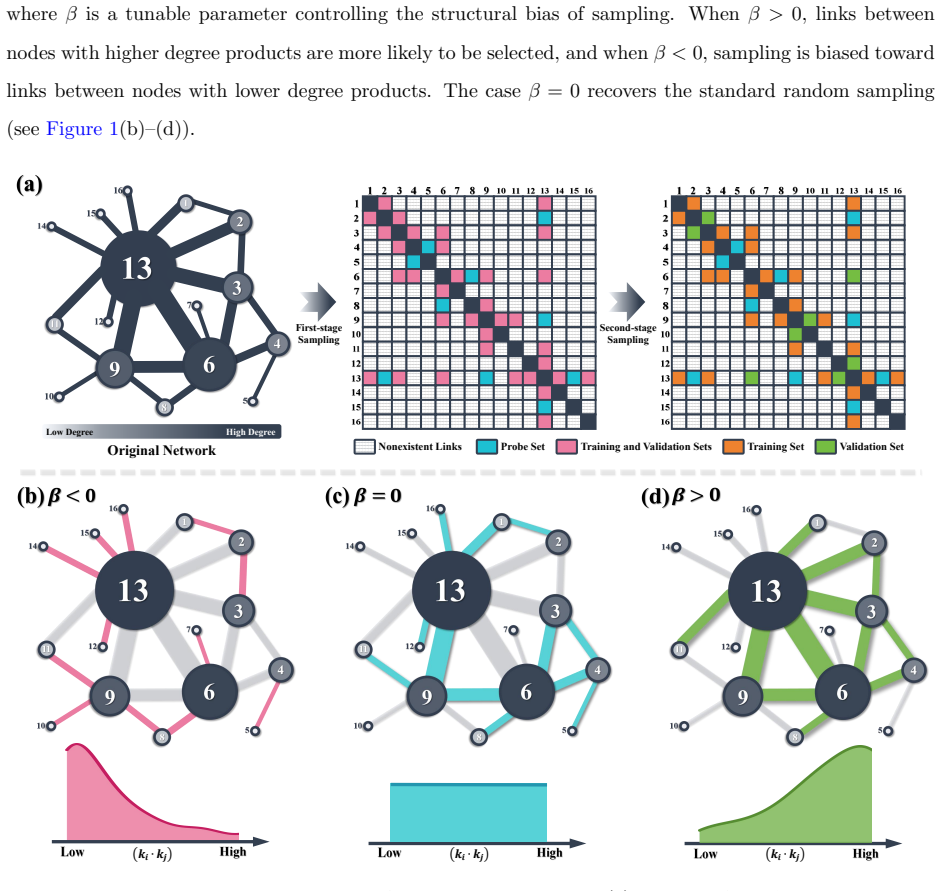
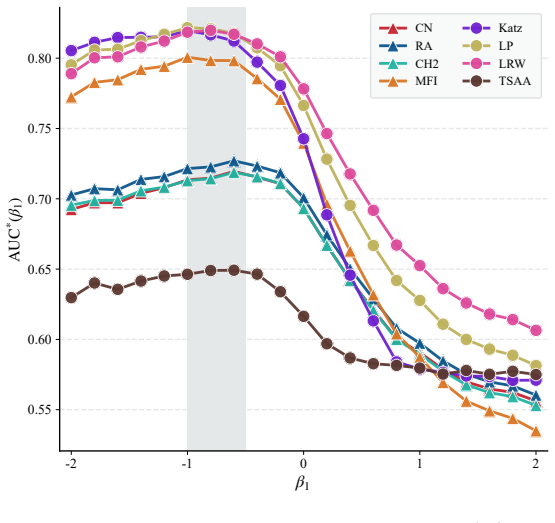
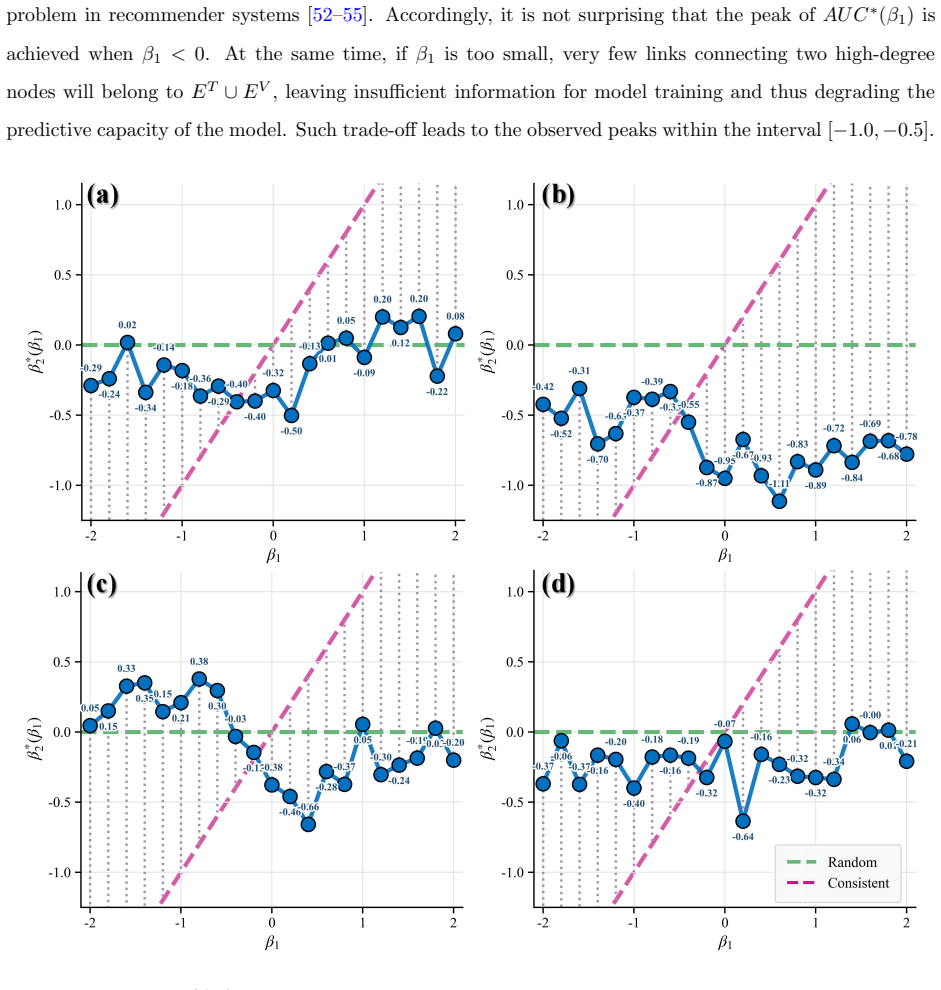
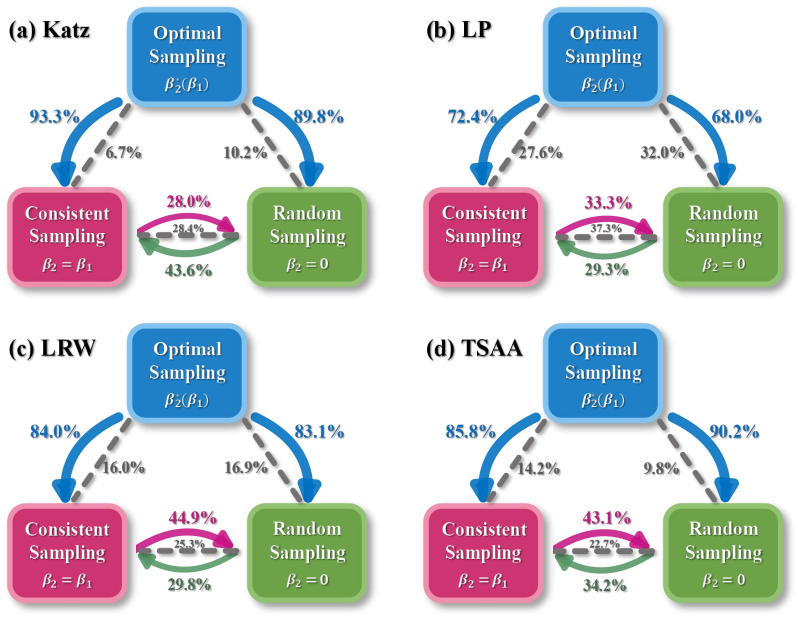
read the original abstract
Many real-world networks are incomplete, making link prediction a fundamental challenge in network science. To train parameters and evaluate algorithms, observed links are usually divided into three subsets, namely training, validation, and probe sets. This division implicitly involves two sampling processes: first-stage sampling yields the probe set and second-stage sampling obtains the variation set. To date, our understanding of how these two sampling processes affect algorithm performance remains quite limited. To address this issue, we propose a sampling scheme called $\beta$-sampling, where the sampling probability of a link is proportional to the product of the degrees of its two endpoints raised to the power of $\beta$. Experiments on 45 real-world networks reveal that the structural characteristics of missing links, as simulated via varying probe sets, substantially impact prediction accuracy. When missing links tend to connect high-degree nodes, such links can be predicted accurately with ease. Furthermore, even with a fixed probe set, second-stage sampling still exerts a significant influence on prediction accuracy. Notably, the optimal second-stage sampling strategy differs from \textit{random sampling} (which randomly selects links to form the validation set) and \textit{consistent sampling} (which guarantees that links in the validation and probe sets share identical structural characteristics).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a β-sampling scheme for dividing observed links into training, validation, and probe sets in link prediction, with sampling probability p ∝ (d_u d_v)^β. Experiments on 45 real-world networks are used to claim that structural characteristics of missing links (varied via probe sets) substantially affect prediction accuracy, that links between high-degree nodes are easier to predict, and that second-stage sampling for the validation set exerts significant influence even with fixed probe sets, with optimal strategies differing from random and consistent sampling.
Significance. If the empirical effects can be isolated from confounders, the work would demonstrate that standard evaluation practices in link prediction are sensitive to sampling choices and could motivate more careful benchmark design. The scale of 45 networks provides breadth, but the absence of statistical controls and the risk of entangled structural factors limit the strength of the conclusions.
major comments (3)
- [Abstract] Abstract: the claim that 'structural characteristics of missing links, as simulated via varying probe sets, substantially impact prediction accuracy' lacks any reported statistical details, error bars, dataset list, p-values, or controls for multiple testing across 45 networks, making the 'substantial impact' assertion unverifiable from the given evidence.
- [Method / Experimental Setup] β-sampling definition and experimental setup: varying the single parameter β in p ∝ (d_u d_v)^β does not demonstrably isolate the intended degree-product property, because high-(d_u d_v) links systematically co-vary with clustering, betweenness, and community structure in real networks; no matching, stratification, or regression controls are described to rule out these confounders.
- [Results] Results on second-stage sampling: the claim that 'even with a fixed probe set, second-stage sampling still exerts a significant influence on prediction accuracy' inherits the same isolation problem once the probe set itself is generated by β-sampling, and no explicit test is reported showing independence from the first-stage structural variation.
minor comments (1)
- [Abstract] Abstract: the definitions of 'random sampling' and 'consistent sampling' are given inline but would benefit from explicit mathematical notation when first introduced in the main text.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments, which help clarify the need for greater statistical transparency and discussion of potential confounders. We respond to each major comment below and indicate the revisions that will be incorporated.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'structural characteristics of missing links, as simulated via varying probe sets, substantially impact prediction accuracy' lacks any reported statistical details, error bars, dataset list, p-values, or controls for multiple testing across 45 networks, making the 'substantial impact' assertion unverifiable from the given evidence.
Authors: We agree that the abstract would be strengthened by supporting statistical information. In the revised manuscript we will add error bars to all reported accuracy metrics, include a table summarizing the 45 networks, and report mean accuracy differences with standard deviations across networks to quantify the impact. We will also note the consistency of trends rather than relying on per-network p-values, thereby addressing multiple-testing concerns while keeping the focus on the observed empirical patterns. revision: yes
-
Referee: [Method / Experimental Setup] β-sampling definition and experimental setup: varying the single parameter β in p ∝ (d_u d_v)^β does not demonstrably isolate the intended degree-product property, because high-(d_u d_v) links systematically co-vary with clustering, betweenness, and community structure in real networks; no matching, stratification, or regression controls are described to rule out these confounders.
Authors: We acknowledge that degree-product correlates with other structural features in real networks and that β-sampling does not fully isolate the degree-product effect. Our contribution is empirical: systematically varying the degree-product distribution of missing links via β produces consistent changes in prediction accuracy across 45 networks. We will add an explicit discussion of potential confounders and note that future work could employ matching or regression controls. The current design prioritizes breadth over synthetic isolation. revision: partial
-
Referee: [Results] Results on second-stage sampling: the claim that 'even with a fixed probe set, second-stage sampling still exerts a significant influence on prediction accuracy' inherits the same isolation problem once the probe set itself is generated by β-sampling, and no explicit test is reported showing independence from the first-stage structural variation.
Authors: The second-stage experiments already hold the probe set fixed while varying only the validation-set sampling strategy. To further demonstrate robustness, we will add results for the same second-stage variations applied to probe sets generated under multiple distinct β values and report that the influence of second-stage sampling persists. This clarification and additional figures will be included in the revised results section. revision: yes
Circularity Check
No circularity; purely empirical study with no derivation chain
full rationale
The paper proposes a β-sampling scheme and reports experimental results on 45 networks showing effects of probe-set structure and second-stage sampling on link-prediction accuracy. All central claims rest on direct empirical comparisons of accuracy metrics across varied β values; no equations, predictions, or uniqueness theorems are presented that could reduce by construction to fitted inputs, self-citations, or ansatzes. The methodology is self-contained as an observational study and exhibits none of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (1)
- β
Reference graph
Works this paper leans on
-
[1]
Vega-Redondo F. 2007. Complex social networks.Cambridge University Press
2007
-
[2]
Gosak M, Markoviˇ c R, Dolenˇ sek J, Slak Rupnik M, Marhl M, Stoˇ zer A, Perc M. 2018. Network science of biological systems at different scales: A review.Physics of Life Reviews. 24: 118-135
2018
-
[3]
Strogatz SH. 2001. Exploring complex networks.Nature. 410(6825): 268-276
2001
-
[4]
Mitchell M. 2009. Complexity: A guided tour.Oxford University Press
2009
-
[5]
Barab´ asi AL. 2013. Network science.Cambridge University Press
2013
-
[6]
Newman MEJ. 2018. Networks.Oxford University Press
2018
-
[7]
Kossinets G. 2006. Effects of missing data in social networks.Social Networks. 28(3): 247-268
2006
-
[8]
L¨ u L, Zhou T. 2011. Link prediction in complex networks: A survey.Physica A: Statistical Mechanics and its Applications. 390(6): 1150-1170
2011
-
[9]
Wang P, Xu BW, Wu YR, Zhou XY. 2015. Link prediction in social networks: The state-of-the-art. Science China Information Sciences. 58(1): 1-38
2015
-
[10]
Mart´ ınez V, Berzal F, Cubero JC. 2016. A survey of link prediction in complex networks.ACM Computing Surveys. 49(4): 69
2016
-
[11]
Kumar A, Singh SS, Singh K, Biswas B. 2020. Link prediction techniques, applications, and perfor- mance: A survey.Physica A: Statistical Mechanics and its Applications. 553: 124289. 14
2020
-
[12]
Zhou T. 2021. Progresses and challenges in link prediction.iScience. 24(11): 103217
2021
-
[13]
Wu H, Song C, Ge Y, Ge T. 2022. Link prediction on complex networks: An experimental survey. Data Science and Engineering. 7(3): 253-278
2022
-
[14]
Xu E, Bi Y, Hu H, Chen X, Yu Z, Li Y, Hu Y, Zhou T. 2026. Predictability of complex systems. Physics Reports. 1166: 1-107
2026
-
[15]
Wang WQ, Zhang QM, Zhou T. 2012. Evaluating network models: A likelihood analysis.EPL. 98: 28004
2012
-
[16]
Zhang QM, Xu XK, Zhu YX, Zhou T. 2015. Measuring multiple evolution mechanisms of complex networks.Scientific Reports. 5: 10350
2015
-
[17]
L¨ u L, Medo M, Yeung CH, Zhang YC, Zhang ZK, Zhou T. 2012. Recommender systems.Physics Reports. 519(1): 1-49
2012
-
[18]
Bobadilla J, Ortega F, Hernando A, Guti´ errez A. 2013. Recommender systems survey.Knowledge- Based Systems. 46: 109-132
2013
-
[19]
Bi Y, Wang P. 2022. Exploring drought-responsive crucial genes inSorghum.iScience. 25(11): 105347
2022
-
[20]
Al Musawi AF, Roy S, Ghosh P. 2025. A review of link prediction applications in network biology. IEEE Access. 13: 54997-55016
2025
-
[21]
Liben-Nowell D, Kleinberg J. 2007. The link-prediction problem for social networks.Journal of the American Society for Information Science and Technology. 58(7): 1019-1031
2007
-
[22]
Adamic LA, Adar E. 2003. Friends and neighbors on the Web.Social Networks. 25(3): 211-230
2003
-
[23]
Ou Q, Jin YD, Zhou T, Wang BH, Yin BQ. 2007. Power-law strength-degree correlation from resource- allocation dynamics on weighted networks.Physical Review E. 75(2): 021102
2007
-
[24]
Zhou T, L¨ u L, Zhang YC. 2009. Predicting missing links via local information.The European Physical Journal B. 71(4): 623-630
2009
-
[25]
Clauset A, Moore C, Newman MEJ. 2008. Hierarchical structure and the prediction of missing links in networks.Nature. 453(7191): 98-101
2008
-
[26]
Guimer` a R, Sales-Pardo M. 2009. Missing and spurious interactions and the reconstruction of complex networks.Proceedings of the National Academy of Sciences of the United States of America. 106(52): 22073-22078
2009
-
[27]
Scarselli F, Gori M, Tsoi AC, Hagenbuchner M, Monfardini G. 2009. The graph neural network model. IEEE Transactions on Neural Networks. 20(1): 61-80. 15
2009
-
[28]
Hamilton WL, Ying R, Leskovec J. 2017. Inductive representation learning on large graphs. InPro- ceedings of the 31st International Conference on Neural Information Processing Systems. (Curran Associates, Inc.) pp. 1025-1035
2017
-
[29]
Veliˇ ckovi´ c P, Cucurull G, Casanova A, Romero A, Li` o P, Bengio Y. 2018. Graph attention networks. InProceedings of the International Conference on Learning Representations. (ICLR) pp. 1-12
2018
-
[30]
Kipf TN, Welling M. 2016. Variational graph auto-encoders. InProceedings of the NeurIPS Workshop on Bayesian Deep Learning. (PMLR) pp. 1-3
2016
-
[31]
Jiao X, Luo Y, Bi Y, Zhou T. 2026. Impacts of data splitting strategies on parameterized link prediction algorithms.Physica A: Statistical Mechanics and its Applications. 692: 131545
2026
-
[32]
He X, Ghasemian A, Lee E, Schwarze AC, Clauset A, Mucha PJ. 2024. Link prediction accuracy on real-world networks under non-uniform missing-edge patterns.PLoS ONE. 19(7): e0306883
2024
-
[33]
Zhu YX, L¨ u L, Zhang QM, Zhou T. 2012. Uncovering missing links with cold ends.Physica A: Statistical Mechanics and its Applications. 391(22): 5769-5778
2012
-
[34]
Ahmed N, Neville J, Kompella R. 2012. Network sampling designs for relational classification. In Proceedings of the International AAAI Conference on Web and Social Media. (AAAI) pp. 383-386
2012
-
[35]
Neville J, Gallagher B, Eliassi-Rad T. 2009. Evaluating statistical tests for within-network classifiers of relational data. Inthe Proceedings of the 9th IEEE International Conference on Data Mining. (IEEE) pp. 397-406
2009
-
[36]
Chebotarev P, Shamis E. 1997. The matrix-forest theorem and measuring relations in small social groups.Automation and Remote Control. 58(9): 1505-1514
1997
-
[37]
Stealing fire or stacking knowledge
Muscoloni A, Cannistraci CV. 2023. “Stealing fire or stacking knowledge” by machine intelligence to model link prediction in complex networks.iScience. 26(1): 105697
2023
-
[38]
L¨ u L, Jin CH, Zhou T. 2009. Similarity index based on local paths for link prediction of complex networks.Physical Review E. 80(4): 046122
2009
-
[39]
Liu W, L¨ u L. 2010. Link prediction based on local random walk.EPL. 89(5): 58007
2010
-
[40]
Katz L. 1953. A new status index derived from sociometric analysis.Psychometrika. 18(1): 39-43
1953
-
[41]
Sun D, Zhou T, Liu JG, Stanley HE, Zhang YC. 2009. Information filtering based on transferring similarity.Physical Review E. 80(1): 017101
2009
-
[42]
Zhou T. 2023. Discriminating abilities of threshold-free evaluation metrics in link prediction.Physica A: Statistical Mechanics and its Applications. 615: 128529. 16
2023
-
[43]
Jiao X, Wan S, Liu Q, Bi Y, Lee YL, Xu E, Hao D, Zhou T. 2024. Comparing discriminating abilities of evaluation metrics in link prediction.Journal of Physics: Complexity. 5(2): 025014
2024
-
[44]
Bi Y, Jiao X, Lee YL, Zhou T. 2024. Inconsistency among evaluation metrics in link prediction.PNAS Nexus. 3(11): pgae498
2024
-
[45]
Wan S, Bi Y, Jiao X, Zhou T. 2025. Quantifying discriminability of evaluation metrics in link prediction for real networks.Chaos, Solitons & Fractals. 199: 116864
2025
-
[46]
Hanley JA, McNeil BJ. 1982. The meaning and use of the area under a receiver operating characteristic (ROC) curve.Radiology. 143(1): 29-36
1982
-
[47]
Davis J, Goadrich M. 2006. The relationship between Precision-Recall and ROC curves. InProceedings of the 23rd International Conference on Machine Learning. (ACM) pp. 233-240
2006
-
[48]
J¨ arvelin K, Kek¨ al¨ ainen J. 2002. Cumulated gain-based evaluation of IR techniques.ACM Transactions on Information Systems. 20(4): 422-446
2002
-
[49]
Bi Y, Bian J, Wan S, Wang S, Zhou T. 2026. Domain matters: Towards domain-informed evaluation for link prediction.Physica A: Statistical Mechanics and its Applications. 693: 131551
2026
-
[50]
Watts DJ, Strogatz SH. 1998. Collective dynamics of ’small-world’ networks.Nature. 393(6684): 440- 442
1998
-
[51]
Newman MEJ. 2002. Assortative mixing in networks.Physical Review Letters. 89(20): 208701
2002
-
[52]
Schein AI, Popescul A, Ungar LH, Pennock DM. 2002. Methods and metrics for cold-start recommen- dations. InProceedings of the 25th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. (ACM) pp. 253-260
2002
-
[53]
Lam XN, Vu T, Le TD, Duong AD. 2008. Addressing cold-start problem in recommendation sys- tems. InProceedings of the 2nd International Conference on Ubiquitous Information Management and Communication. (ACM) pp. 208-211
2008
-
[54]
Zhang ZK, Liu C, Zhang YC, Zhou T. 2010. Solving the cold-start problem in recommender systems with social tags.EPL. 92(2): 28002
2010
-
[55]
Lika B, Kolomvatsos K, Hadjiefthymiades S. 2014. Facing the cold start problem in recommender systems.Expert Systems with Applications. 41(4): 2065-2073
2014
-
[56]
Rafiei D, Curial S. 2005. Effectively visualizing large networks through sampling. InIEEE Visualiza- tion. (IEEE) pp. 375-382. 17
2005
-
[57]
2005 Subnets of scale-free networks are not scale-free: Sampling prop- erties of networks.Proceedings of the National Academy of Sciences of the United States of America
Stumpf MPH, Wiuf C, May RM. 2005 Subnets of scale-free networks are not scale-free: Sampling prop- erties of networks.Proceedings of the National Academy of Sciences of the United States of America. 102(12): 4221-4224
2005
-
[58]
Leskovec J, Faloutsos C. 2006. Sampling from large graphs. InProceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. (ACM) pp. 631-636
2006
-
[59]
Gjoka M, Kurant M, Butts CT, Markopoulou A. 2010. Walking in Facebook: A case study of unbiased sampling of OSNs. In2010 Proceedings IEEE INFOCOM. (IEEE) pp. 1-9
2010
-
[60]
Maiya AS, Berger-Wolf TY. 2010. Sampling community structure. InProceedings of the 19th Inter- national Conference on World Wide Web. (ACM) pp. 701-710
2010
-
[61]
De Choudhury M, Lin YR, Sundaram H, Candan KS, Xie L, Kelliher A. 2010. How does the data sampling strategy impact the discovery of information diffusion in social media?. InProceedings of the International AAAI Conference on Web and Social Media. (AAAI) pp. 34-41
2010
-
[62]
Lichtenwalter RN, Chawla NV. 2012. Link prediction: Fair and effective evaluation. In2012 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining. (IEEE) pp. 376-383
2012
-
[63]
Mitchell S, Potash E, Barocas S, D’Amour A, Lum K. 2021. Algorithmic fairness: Choices, assump- tions, and definitions.Annual Review of Statistics and Its Application. 8: 141-163
2021
-
[64]
Murata T, Moriyasu S. 2007. Link prediction of social networks based on weighted proximity measures. InProceedings of the 2007 IEEE/WIC/ACM International Conference on Web Intelligence. (IEEE) pp. 85-88
2007
-
[65]
L¨ u L, Zhou T. 2010. Link prediction in weighted networks: The role of weak ties.EPL. 89: 18001
2010
-
[66]
Zhao J, Miao L, Yang J, Fang H, Zhang QM, Nie M, Holme P, Zhou T. 2015. Prediction of links and weights in networks by reliable routes.Scientific Reports. 5: 12261
2015
-
[67]
Dunlavy DM, Kolda TG, Acar E. 2011. Temporal link prediction using matrix and tensor factoriza- tions.ACM Transactions on Knowledge Discovery from Data. 5(2): 10
2011
-
[68]
Holme P, Saram¨ aki J. 2012. Temporal networks.Physics Reports. 519(3): 97-125
2012
-
[69]
Tang D. Du W. Shekhtman L. Wang Y. Havlin S. Cao X. Yan G. 2020. Predictability of real temporal networks.National Science Review. 7(5): 929-937
2020
-
[70]
Pujari M, Kanawati R. 2015. Link prediction in multiplex networks.Networks and Heterogeneous Media. 10(1): 17-35. 18
2015
-
[71]
Benson AR, Abebe R, Schaub MT, Jadbabaie A, Kleinberg J. 2018. Simplicial closure and higher- order link prediction.Proceedings of the National Academy of Sciences of the United States of America. 115(48): E11221-E11230
2018
-
[72]
Bian J, Zhou T, Bi Y. 2025. Unveiling the role of higher-order interactions via stepwise reduction. Communications Physics. 8(1): 228. 19
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.